
bash学习 -bash shell操作环境
bash shell操作环境
命令的运行顺序为
1、以相对路径或者绝对路径来执行,如"/bin/ls"
2、由 alias找到命令执行
3、由bash 内置的(builtin)命令来执行
4、通过$PATH这个变量的顺序找到的第一个命令来执行
1、bash的配置文件
在进入bash后一进入便取得了一堆变量,原因就在于打开bash shell后会默认读取一些配置文件,之前使用的别名和自定义变量在写入到配置文件才有效,即使是export /env环境变量也不例外。
1.1、首先区分login shell 和non-login shell:
login shell是指取得bash时需要完整的登陆流程的,就叫做login shell,如在登陆tty1-tty6登陆时需要输入账号和密码即为login shell。
non-login shell 是指在登陆bash时候不需要完整流程的,如图像界面(虽然输入了密码账号,但是这仅仅相当于使用在根进程,在登陆后使用bash相当于都是这个根进程的子进程,这也仅仅是相当)、某个进程的第二个bash(子进程)
1.2 /etc/profile(login shell 才会去读)
每个用户在登陆取得bash的时候都会读取这个文件,这是所有用户都起作用的环境配置文件,主要设置的变量有:
PATH:环境目录
MAIL:设置用户邮箱
USER:设置用户名
HOSTNAME:依据主机的hostname来设置这个变量
HISTSIZE:历史命令条数
同时该配置文件可以调用外部数据:/etc/inputrc(配置自定义的按键功能),/etc/profild.d/*.sh(这个目录下规定了用户的ll别名,which 别名,语系及颜色,如果需要自己设置某些配置可以设置保存为.sh在该文件夹下),/etc/sysconfig/i18n(在lang.sh中调用的)

1.3 ~/.bash_profile(login shell 才会读)
在读取完所有用户的所有配置后就会读取用户的个人配置文件,在其中所读取的个人设置文件主要有三个,依次是:~/.bash_profile、~/.bash_login、~/.profile,但是这三个文件不会同时存在,login shell仅仅会按照顺序读取这三个文件,当前者不存在才读取下一个。
我们的计算机上存在~/.bash_profile,因此不存在~/.bash_login和~/.profile.。bash_profile会读取文件~/.bashrc(会再读取/etc/.bashrc,而/etc/.bashrc会执行/etc/profile.d/目录下的所有文件)的配置。


在进行配置之后往往需要重新登陆用户才能够生效,因此使用source或者.来使得设置的文件生效。
1.4 ~/.bashrc
再来说明非login shell会执行的文件主要就是~/.bashrc,其在设置好用户特有的设置后依旧会执行/etc/bashrc的内容,接着执行/etc/profile.d/目录下的所有文件,为了测试X window 是否会执行~/.bash_profile,我重新开机试了一下,依旧是不会执行~/.bash_profile的,因此X window必然改变了执行路径。
还有一些配置文件:
~/.bash_history 记录bash的历史命令
~/.bash_logout :记录在bash注销时候系统能够帮用户所作的操作。
1.5 用户登陆欢迎界面
在本地进行登陆时在/etc/issue中即可进行欢迎信息的设置,可以使用转义字符进行特定信息的设置,但是在远程登陆的时候/etc/issue就不再起作用,相应的使用/etc/issue.net会起作用,这个不再介绍,这些都是登陆前提示信息。


在/etc/motd中可以在用户登陆成功后进行信息提示,这样就不用处理到底是否在本地登陆了,我的远程服务器没有/etc/motd,尴尬了
![]()
2、终端机的环境设置及数据流重定向
2.1 终端机的环境设置
使用stty可以进行设置终端机(tty)的快捷键设置查询与设置,使用set进行bash快捷键的设置

stty erase ^h 删除字符开始使用ctrl+h。
2.2 数据流重定向
之前已经说明过了输出流重定向,在次仅仅做总结:
1、标准输入(stdin):代码为0,使用<或者<<;
2、标准输入(stdout):代码为1,使用>或者>>
3、标准错误输出(stderr):代码为2,使用2>或者2>>;
4、单向的符号>表示对文件进行格式化后重写,>>表示继续写
5、command >file 2>file的确可以执行,相对于两次的io操作,更大的问题在于其顺序混乱,因此最好使用command>file 2>&1。
6、丢弃警告信息可以通过2>/dev/null进行。
7、;为两个不相关命令执行,cm1&&cm2只有cm1执行完成才执行cm2,cm1||cm2在cm1执行成功后不执行cm2,否则执行cm2。也就是说&&在回传码为0(紧邻执行成功)||在回传码不为0时执行,从左向右看。
3、管道命令
管道命令仅仅会处理标准输出命令,对于标准输出错误没有处理能力。下面列举常见的配合而管道命令使用的命令,由于管道命令仅仅能够处理标准输出,因此后面配合的命令应当仅仅能够处理文本信息才好。
3.1选取命令:cut,grep
cut是在字符列上进行切割
cut -d "分割字符" -f fields 将某一行按照分割字符分割,去除fuelds段作为选取输出。
cut -c 字符范围
-d:接分割字符
-f:去除段数
-c:以字符为单位取出固定字符区间
分别取12个字符之后的内容和12到16之间的字符。


按照':'字符进行分类后取出第3段
![]()
grep 取出一行,不会对行进行cut,grep配合cut即可完成精确定位,格式为:
grep [-acinv][--color=auto] '查找字符串' filename
-a:将binary文件以text文件的方式查找数据
-c:计算查到字符串的次数
-i:忽略大小写
-n:顺便输出行号
-v:显示除了查找到行的位置的其他行。
--color=auto :可以找到关键字的部分加上颜色。
显示用户登陆记录后查找包含yaoqinch的行,接着对选取出的行进行cut分割,分割字符串为‘ ’,取出除第二个列。

3.2 排序命令:sort,wc,uniq
sort可以对输出的内容进行排序,具体的用man sort 看,格式为:sort [-fbMnrtuk][file or stdin]
-f:忽略大小写
-b:忽略前面空格
-r:反向排序
-u:相同的数据仅仅出现一行
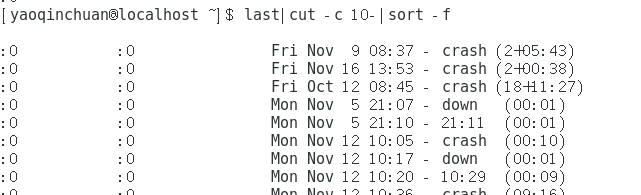
除了使用sort的 -u参数,也可以使用uniq进行去重 uniq [-ic]
-i:忽略大小写
-c:进行计数
使用last|cut -c 10-|sort -f|uniq -c|less的结果

也可以使用wc来进行行数字符数的统计
wc [-lwm] filename
-l:行数。
-w:列出多少个字
-m:多少个字符
![]()
4、双向重定向:tee
使用>可以将数据流整个传送给文件和设备,我们仅仅在该文件或者设备中读取才能获得数据,但是tee可以将数据在处理过程中就进行读取,或者处理,这对于格式化输出有些用,最有用的还是在于对中间数据的记录。
last|tee last.txt|cut -d " " -f 4:先将数据流存为last.txt,接着再对该数据流进行处理,也就是说tee将数据流分流成两个方向了,即标准输出与file,下图分别为文件与标准输出。


5、杂命令
5.1 tr
tr用于替换或者删除输出的文字,格式为tr [-ds] set1 ...
-d :删除信息中set1的字符串
-s:替换重复的字符串
last|tr 'yaoqinch' 'YAOQINCHUAN'

也可以使用last|tr [a-z] [A-Z]进行大小写替换。
5.2 col
对于特殊符号的替换可以使用col,col [-xb]
-x:将tab转成对等的空格
-b:在文字中存在反斜杠时候消除反斜杠
5.3 join
join主要是将具备相同的数据的一行数据加到一起(在两个文件中),join [-til2] file1 file2
-t :join默认使用空格来进行数据分割,并且对比第一个字段的数据,如果两个文件下相同,则将两个而数据连成一行,且第一个字段放在第一个;
-i:忽略大小写
-1 :表示第一个文件按照哪个字段分析
-2:表示第二个字段按照哪个字段分析
按照第一个字符串的分割位置3与第二个位置的分割位置4进行对比融合,鸟哥说要事先进行sort,未做测试。

5.4 paste
相对于join需要使用对比,paste不需要进行对比而直接进行拼接,这个里面有个很厉害的参数paste [-d]file1 file2
-d:后面接两个拼接间的分割字符,默认使用tab
-:如果file部分写成-,则表示输入为标准输入
如下所示-代表echo "this is a test1"
![]()
处理分隔符
![]()
读入标准输入
![]()
5.5 expand
将tab转成空格键,但是不会改变source file.
![]()
5.6split
用于将数据流分割成几个小的文件保存,有利于文件的分割,windows怎么方便的做?
split[-bl] file prefix
-b: 后面接大小,100k等
-l:按照行数进行分割,默认为1000
prefix:分割后的名字前导文字,分割后的文件的名字会成为prefixaa,prefixab,...prefixaaa...
在组合的时候借助标准输出
cat prefix*>>file
5.7xargs
用于将不支持管道命令的命令,通过xargs来提供命令引用之用。
-(减号)在代表文件的时候代表的是标准输入或者标准输出
------鸟哥私房菜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号