


组合数据类型练习,英文词频统计实例
1.列表实例:由字符串创建一个作业评分列表,做增删改查询统计遍历操作。例如,查询第一个3分的下标,统计1分的同学有多少个,3分的同学有多少个等。
f=list('123223121321312') print('成绩表:',f) f.append('3') print('增加一个同学的分数后') print('成绩表:',f) f.pop(2) print('删除下标为2的同学的分数后') print('成绩表:',f) f[3] = 1 print('修改下标为3的同学的分数') print('成绩表:',f) x=f.index('3') print('查找第一个3分的下标:{}'.format(x)) y=f.count('1') print('1分的人数有{}个人'.format(y)) s=f.count('3') print('3分的人数有{}个人'.format(s))

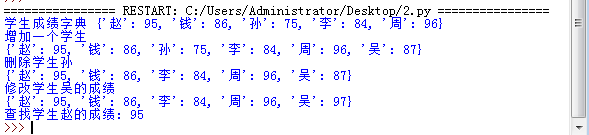
2.字典实例:建立学生学号成绩字典,做增删改查遍历操作。
d={'赵':95,'钱':86,'孙':75,'李':84,'周':96}
print('学生成绩字典',d)
d['吴']=87
print('增加一个学生')
print(d)
d.pop('孙')
print('删除学生孙')
print(d)
d['吴']=97
print('修改学生吴的成绩')
print(d)
print('查找学生赵的成绩:',d.get('赵'))
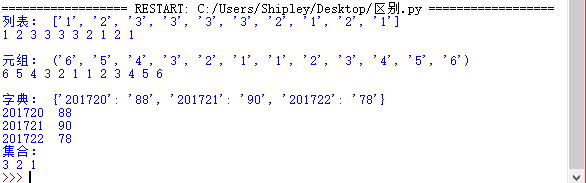
3.列表,元组,字典,集合的遍历。
总结列表,元组,字典,集合的联系与区别。
l=list('1233332121')#列表,用[]表示,可增删改查 t=tuple('654321123456')#元组,用()表示,与列表相似但是不能修改,只读 x={'201720':'88','201721':'90','201722':'78'}#字典,用{}表示,有"键-值"组,没有顺序 s=set('123321332122')#集合,可修改,没有顺序 print("列表:",l) for i in l: print(i,end=' ') print("\n") print("元组:",t) for i in t: print(i,end=' ') print("\n") print("字典:",x) for i in x: print(i,end='\t') print(x[i],end='\n') print("集合:",) for i in s: print(i,end=' ')
4.英文词频统计实例
待分析字符串分解提取单词
- 待分析字符串
- 分解提取单词
- 大小写 txt.lower()
- 分隔符'.,:;?!-_’
- 计数字典
-
排除语法型词汇,代词、冠词、连词
-
- 排序list.sort()
- 输出TOP(10)
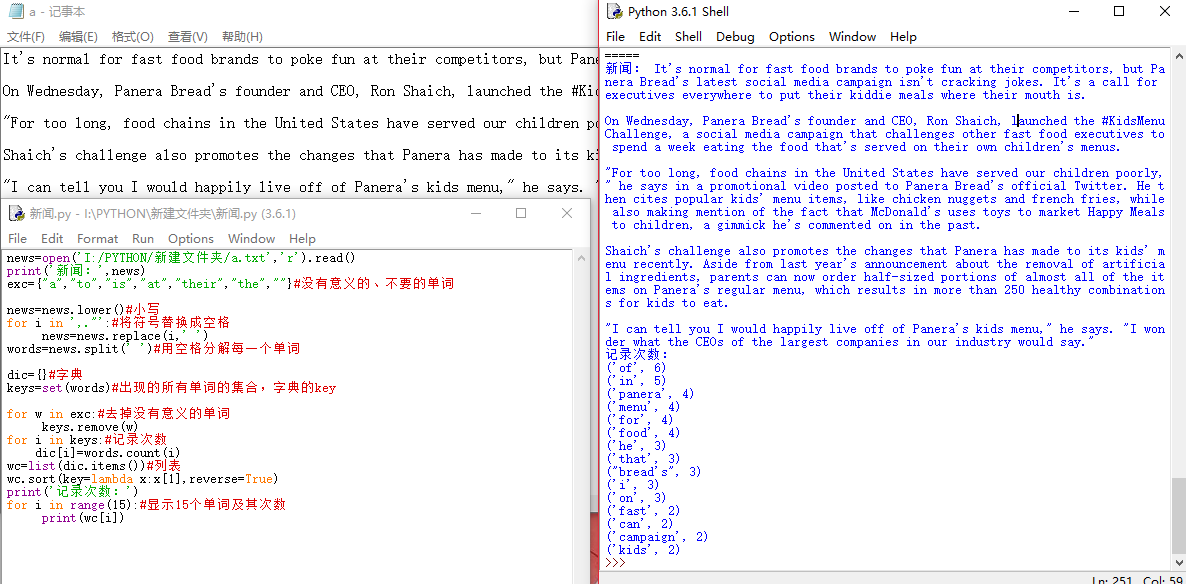
news='''It's normal for fast food brands to poke fun at their competitors, but Panera Bread's latest social media campaign isn't cracking jokes. It's a call for executives everywhere to put their kiddie meals where their mouth is. On Wednesday, Panera Bread's founder and CEO, Ron Shaich, launched the #KidsMenuChallenge, a social media campaign that challenges other fast food executives to spend a week eating the food that's served on their own children's menus.''' print('新闻:',news) news=news.lower()#小写 print('小写:',news) for i in ',.':#将符号替换成空格 news=news.replace(i,' ') print('符号换成空格:',news) words=news.split(' ')#用空格分解每一个单词 dic={}#字典 keys=set(words)#出现的所有单词的集合,字典的key exc={"a","to","is","at","the",''}#没有意义的、不要的单词 for w in exc:#去掉没有意义的单词 keys.remove(w) for i in keys:#记录次数 dic[i]=words.count(i) wc=list(dic.items())#列表 wc.sort(key=lambda x:x[1],reverse=True) print('记录次数:') for i in range(10):#显示10个单词及其次数 print(wc[i])
![]()

5.文件提取
news=open('I:/PYTHON/新建文件夹/a.txt','r').read() print('新闻:',news) exc={"a","to","is","at","their","the",""}#没有意义的、不要的单词 news=news.lower()#小写 for i in ',."':#将符号替换成空格 news=news.replace(i,' ') words=news.split(' ')#用空格分解每一个单词 dic={}#字典 keys=set(words)#出现的所有单词的集合,字典的key for w in exc:#去掉没有意义的单词 keys.remove(w) for i in keys:#记录次数 dic[i]=words.count(i) wc=list(dic.items())#列表 wc.sort(key=lambda x:x[1],reverse=True) print('记录次数:') for i in range(15):#显示15个单词及其次数 print(wc[i])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号