7.Spark SQL
一、分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
因为关系数据库已经很流行,而且关系数据库在大数据时代已经不能满足要求。首先,用户需要从不同数据源执行各种操作,包括结构化、半结构化和非结构化数据。其次,用户需要执行高级分析,比如机器学习和图像处理。在实际大数据应用中,经常需要融合关系查询和复杂分析算法(比如机器学习或图像处理),但是,缺少这样的系统。
Spark SQL填补了这个鸿沟:首先,可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系型操作。其次,可以支持大数据中的大量数据源和数据分析算法Spark SQL可以融合:传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力。
二、简述RDD 和DataFrame的联系与区别。
区别:
RDD是分布式的java对象的集合,但是对象内部结构对于RDD而言却是不可知的。
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,相当于关系数据库中的一张表。
联系:
1.都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
2、都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action才会运算。
3.都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
4、三者都有partition的概念。
5.三者有许多共同的函数,如filter,排序等。
三、DataFrame的创建与保存
1. PySpark-DataFrame创建:
spark.read.text(url)
spark.read.json(url)
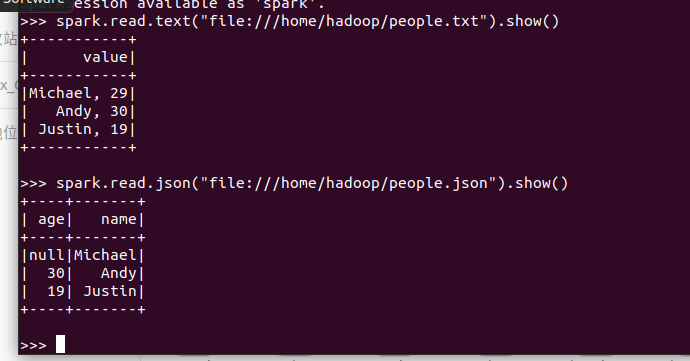
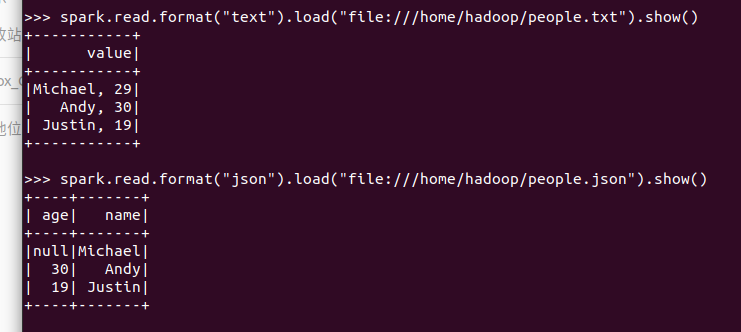
spark.read.format("text").load("people.txt")
spark.read.format("json").load("people.json")
描述从不同文件类型生成DataFrame的区别。
txt文件:创建的DataFrame数据没有结构
json文件:创建的DataFrame数据有结构
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
区别:
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可以获取更多的数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行了针对性的优化,最终达到大幅提升计算效率。
RDD是分布式的Java对象的集合,例如图4-3中的RDD[Person]数据集,虽然它以Person为类型参数,但是对象内部之间的结构相对于Spark框架本身是无法得知的,这样在转换数据形式时效率相对较低。

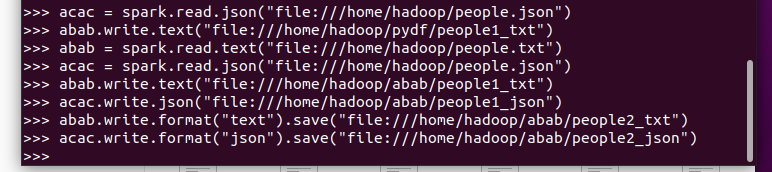
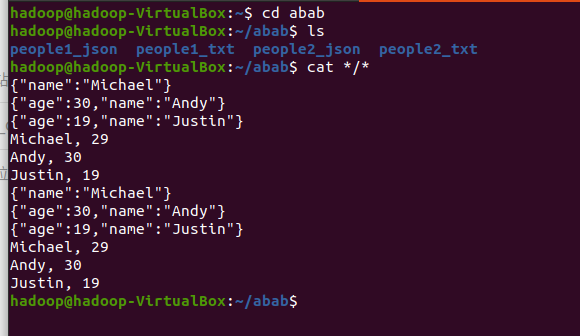
2. DataFrame的保存:
df.write.text(dir)
df.write.json(dri)
df.write.format("text").save(dir)
df.write.format("json").save(dir)
df.write.format("json").save(dir)
四、PySpark-DataFrame各种常用操作
1. 基于df的操作:
打印数据 df.show()默认打印前20条数据
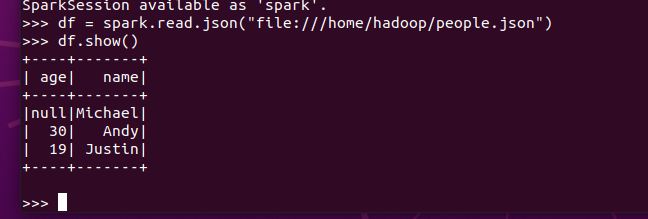
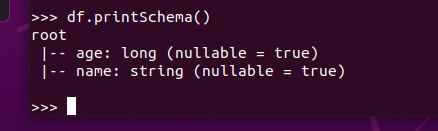
打印概要 df.printSchema()
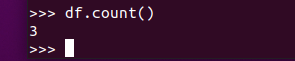
查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

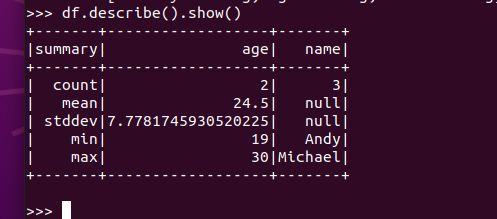
查询概况 df.describe().show()
取列 df[‘name’], df.name, df[1]
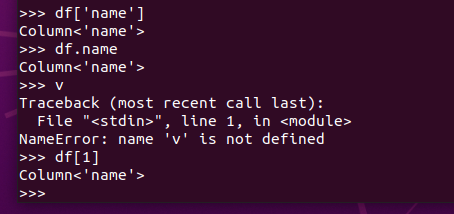
选择 df.select() 每个人的年龄+1
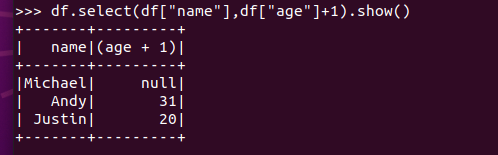
筛选 df.filter() 20岁以上的人员信息
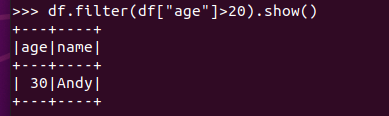
筛选年龄为空的人员信息
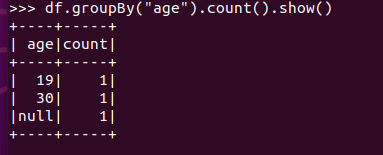
分组df.groupBy() 统计每个年龄的人数
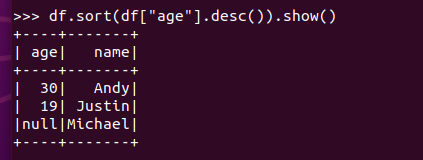
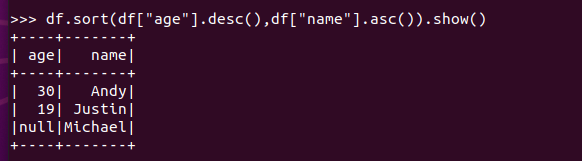
排序df.sortBy() 按年龄进行排序
2. 基于spark.sql的操作:
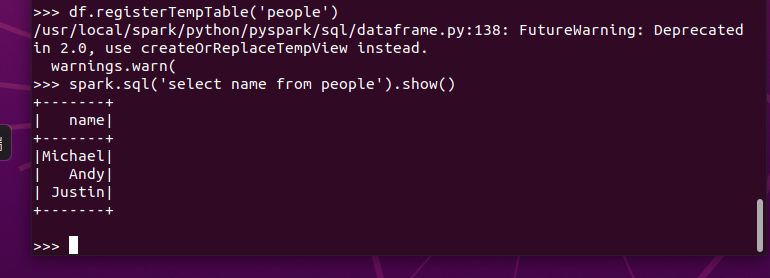
创建临时表虚拟表 df.registerTempTable('people')
spark.sql执行SQL语句 spark.sql('select name from people').show()
五、Pyspark中DataFrame与pandas中DataFrame
1. 分别从文件创建DataFrame:
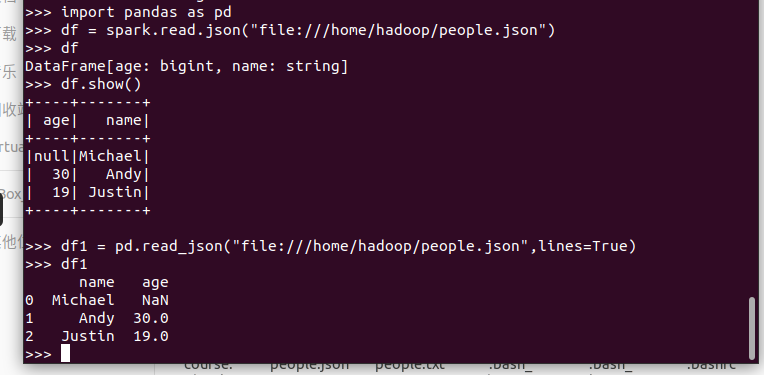
2. 比较两者的异同 :
1. pandas中DataFrame创建出来的DataFrame有index索引,而Pyspark中DataFrame创建出来的没有。
2. 行列结构不同,pyspark中用的是Pyspark.sql.Row和Pyspark.sql.Column,而pandas中用的是Pandas.Series
3. spark中rdd是不可变得,因此dataFrame也是不可变的。而pandas中是可变得
4. pandas没有树结构输出,而spark中有
3. pandas中DataFrame转换为Pyspark中DataFrame:

4. Pyspark中DataFrame转换为pandas中DataFrame:
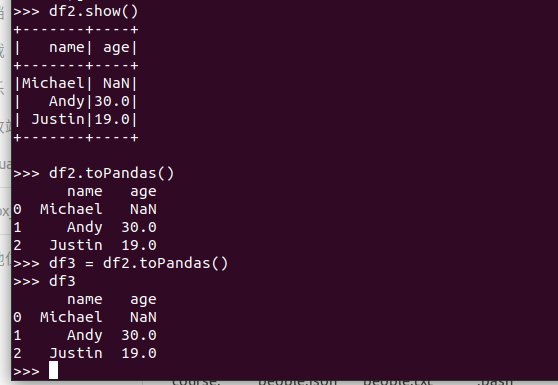
六、从RDD转换得到DataFrame
1. 利用反射机制推断RDD模式:
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame
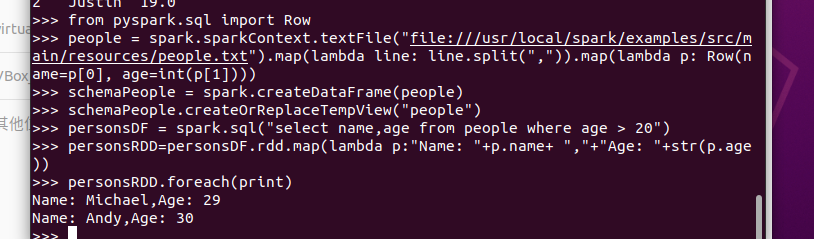
from pyspark.sql import Row
people = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").map(lambda line: line.split(",")).map(lambda p: Row(name=p[0], age=int(p[1])))
schemaPeople = spark.createDataFrame(people)#必须注册为临时表才能供下面的查询使用
schemaPeople.createOrReplaceTempView("people")
personsDF = spark.sql("select name,age from people where age > 20")
#DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用p.name和p.age来获取值
personsRDD=personsDF.rdd.map(lambda p:"Name: "+p.name+ ","+"Age: "+str(p.age))
personsRDD.foreach(print)
2. 使用编程方式定义RDD模式
下面生成“表头”
下面生成“表中的记录”
下面把“表头”和“表中的记录”拼装在一起
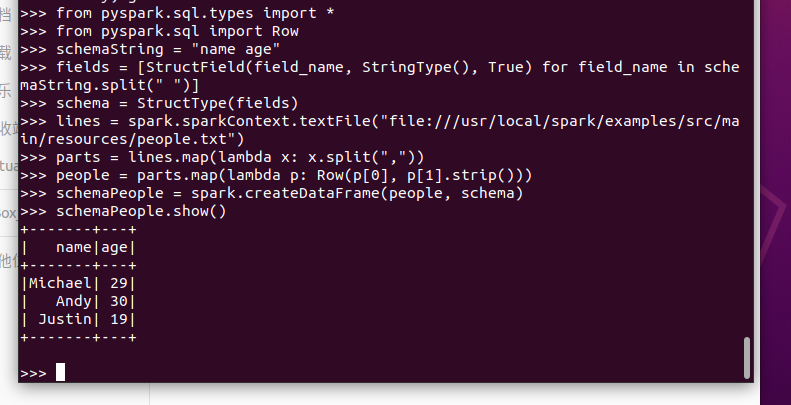
from pyspark.sql.types import *
from pyspark.sql import Row
#下面生成“表头”
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split(" ")]
schema = StructType(fields)
#下面生成“表中的记录”
lines = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
parts = lines.map(lambda x: x.split(","))
people = parts.map(lambda p: Row(p[0], p[1].strip()))
#下面把“表头”和“表中的记录”拼装在一起
schemaPeople = spark.createDataFrame(people, schema)
七、选择题
1. 单选(2分)关于Shark,下面描述正确的是:C
A.Shark提供了类似Pig的功能
B.Shark把SQL语句转换成MapReduce作业
C.Shark重用了Hive中的HiveQL解析、逻辑执行计划翻译、执行计划优化等逻辑
D.Shark的性能比Hive差很多
2. 单选(2分)下面关于Spark SQL架构的描述错误的是:D
A.在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题
B.Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据
C.Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
D.Spark SQL执行计划生成和优化需要依赖Hive来完成
3. 单选(2分)要把一个DataFrame保存到people.json文件中,下面语句哪个是正确的:A
A.df.write.json("people.json")
B.df.json("people.json")
C.df.write.format("csv").save("people.json")
D.df.write.csv("people.json")
4. 多选(3分)Shark的设计导致了两个问题:AC
A.执行计划优化完全依赖于Hive,不方便添加新的优化策略
B.执行计划优化不依赖于Hive,方便添加新的优化策略
C.Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
D.Spark是进程级并行,而MapReduce是线程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的、打了补丁的Hive源码分支
5. 多选(3分)下面关于为什么推出Spark SQL的原因的描述正确的是:AB
A.Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
B.可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
C.Spark SQL无法对各种不同的数据源进行整合
D.Spark SQL无法融合结构化数据管理能力和机器学习算法的数据处理能力
6. 多选(3分)下面关于DataFrame的描述正确的是:ABCD
A.DataFrame的推出,让Spark具备了处理大规模结构化数据的能力
B.DataFrame比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能
C.Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
D.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
7. 多选(3分)要读取people.json文件生成DataFrame,可以使用下面哪些命令:AC
A.spark.read.json("people.json")
B.spark.read.parquet("people.json")
C.spark.read.format("json").load("people.json")
D.spark.read.format("csv").load("people.json")
8. 单选(2分)以下操作中,哪个不是DataFrame的常用操作:D
A.printSchema()
B.select()
C.filter()
D.sendto()
9. 多选(3分)从RDD转换得到DataFrame包含两种典型方法,分别是:AB
A.利用反射机制推断RDD模式
B.使用编程方式定义RDD模式
C.利用投影机制推断RDD模式
D.利用互联机制推断RDD模式
10. 多选(3分)使用编程方式定义RDD模式时,主要包括哪三个步骤:ABD
A.制作“表头”
B.制作“表中的记录”
C.制作映射表
D.把“表头”和“表中的记录”拼装在一起

 浙公网安备 33010602011771号
浙公网安备 33010602011771号