1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
Hadoop生态系统中常见的组件有含有:HDFS(分布式存储系统),Mapreduce(分布式计算框架),HBase(分布式列存数据库),Hive(数据仓库),ZoopKer(分布式协作服务),Pig(数据流系统),Sqoop(数据同步工具),Flume(日志收集工具),Ambari(安装部署工具)等
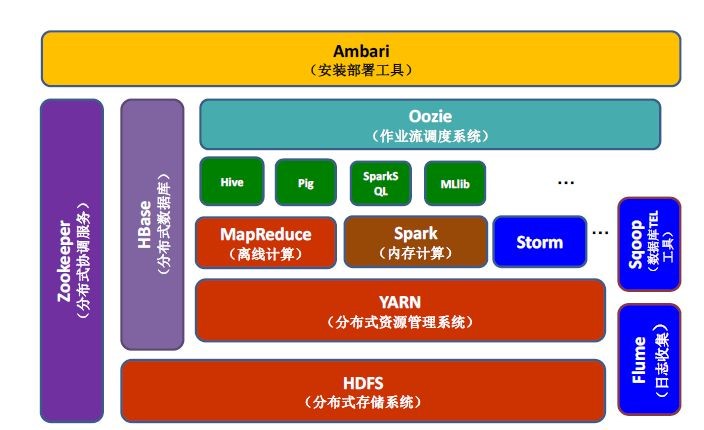
Hadoop 的基础是 HDFS 和 Yarn,也就是分布式存储系统和分布式资源管理系统。在这两个系统的基础上可以装载各种计算模型,例如MapReduce,Spark,HBase ;在这些计算模型的上层,有各种助理用的工具系统,如 Hive、Pig、Sqoop。之后在任务调度层Oozie的作用下, ZooKeeper(分布式协作工作)以及Flume(日志收集工具)才得以有序执行。生态圈最顶层是Ambari,可以为 Hadoop 以及相关大数据软件的使用提供了更多便利。
2. 对比Hadoop与Spark的优缺点。
①Hadoop
优点:资源独立,稳定性高,数据可备份恢复
缺点:任务启动时间长,不适合低延迟的任务
②Spark
优点:访问延迟低,编写程序简洁,可以避免大量数据IO
缺点:稳定性差,线性程序出错整个项目会崩溃
3. 如何实现Hadoop与Spark的统一部署?
可以利用资源管理框架:YARN完成统一部署
Hbase,MapReduce,Spark等主要的系统都可以在YARN上运行,因此,可以在YARN之上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号