全文降AI率vs分段降AI率:哪种方式效果更好?三款工具实测对比
全文降AI率vs分段降AI率:哪种方式效果更好?三款工具实测对比
处理论文AI率的时候,有两种常见的操作方式:一种是把全文直接丢给工具处理(全文降AI率),另一种是把论文拆成几段分别处理再拼回去(分段降AI率)。
很多人问我哪种效果更好。说实话,我之前也没有确切的答案,因为这取决于太多因素。所以我干脆做了一次对照实验,用嘎嘎降AI、比话降AI、率零三款工具分别测试两种方式,用数据来回答这个问题。
全文降AI率和分段降AI率的区别
先厘清概念。
全文降AI率:把论文全文(含摘要、正文、结论等)作为一个整体提交给工具处理。工具会分析全文的语境和逻辑,统一进行改写优化。
分段降AI率:把论文按章节(比如绪论、文献综述、方法、结果、讨论、结论)拆分成多段,每段单独提交处理,最后把处理后的各段拼接成完整论文。
两种方式各有理论上的优劣:
| 维度 | 全文处理 | 分段处理 |
|---|---|---|
| 语境连贯性 | 好(工具能看到全文上下文) | 差(各段独立处理,缺乏上下文) |
| 处理精度 | 统一标准 | 可以针对不同章节调整策略 |
| 操作复杂度 | 低(一次提交) | 高(需要拆分和拼接) |
| 段落衔接 | 自然 | 可能出现风格不一致 |
| 适合场景 | 论文整体AI率高 | 只有部分章节AI率高 |
理论归理论,实际效果怎样还得看数据。
实验设计
测试材料
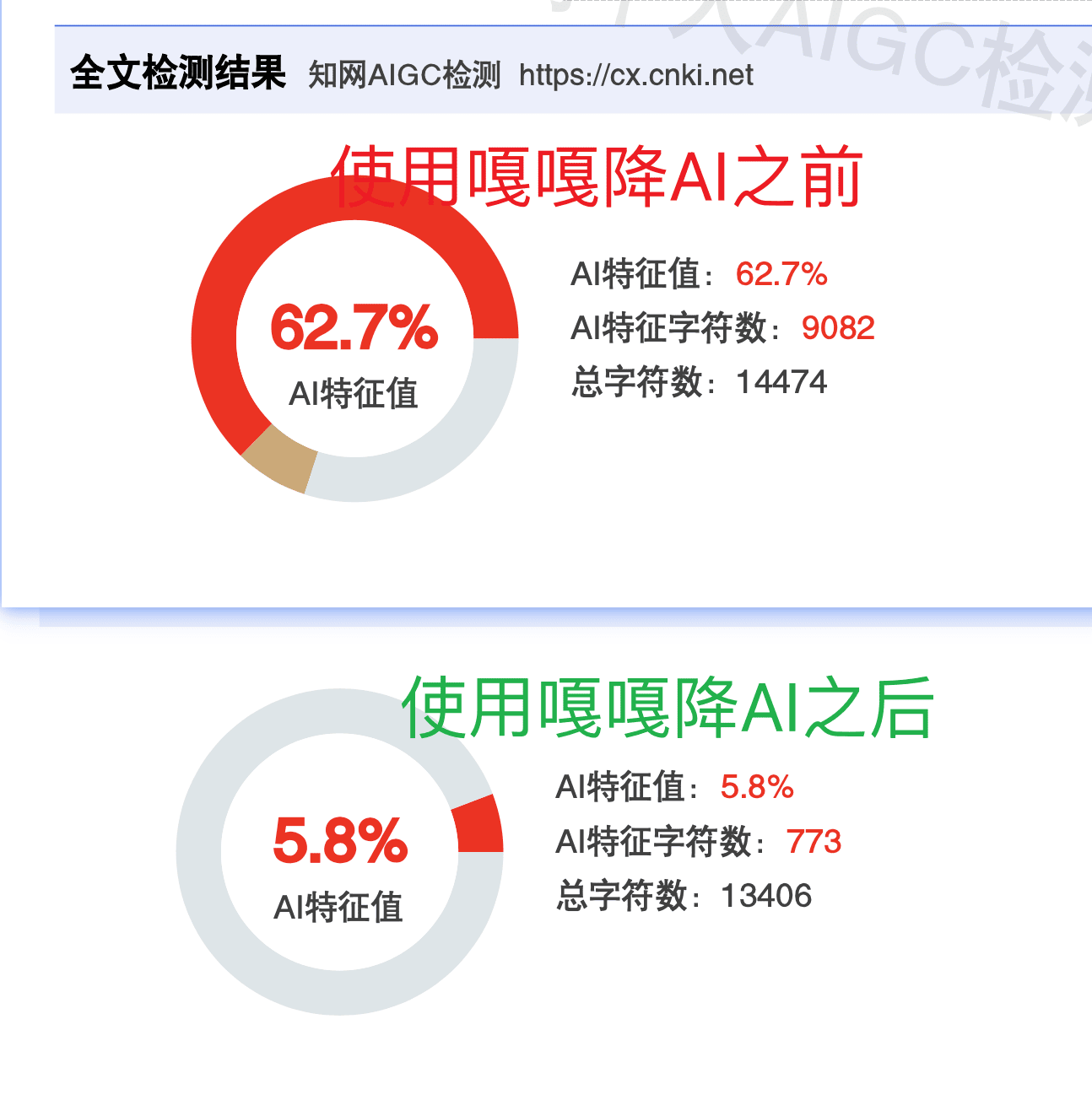
一篇管理学硕士论文节选,约6000字,用豆包生成。全文知网AIGC检测AI率:66.7%。
论文结构:
- 绪论:约800字
- 文献综述:约1500字
- 研究方法:约1200字
- 数据分析:约1300字
- 结论与展望:约1200字
测试方法
每款工具分别用两种方式处理:
- 方式A:全文一次性提交处理
- 方式B:按上述5个章节分段提交,每段单独处理后拼回
处理完后都用知网AIGC检测系统跑结果。
嘎嘎降AI测试结果
全文处理(方式A)
提交全文,选择知网平台,等待约5分钟。
| 章节 | 原文AI率 | 处理后AI率 |
|---|---|---|
| 绪论 | 58.3% | 4.2% |
| 文献综述 | 78.9% | 7.1% |
| 研究方法 | 61.5% | 5.8% |
| 数据分析 | 70.2% | 6.3% |
| 结论 | 55.1% | 3.9% |
| 全文 | 66.7% | 5.6% |
分段处理(方式B)
5个章节分别提交,每段处理约2-3分钟,总共约12分钟。
| 章节 | 原文AI率 | 处理后AI率 |
|---|---|---|
| 绪论 | 58.3% | 5.1% |
| 文献综述 | 78.9% | 8.4% |
| 研究方法 | 61.5% | 6.7% |
| 数据分析 | 70.2% | 7.8% |
| 结论 | 55.1% | 4.5% |
| 全文拼接后 | 66.7% | 6.8% |
对比分析
嘎嘎降AI的全文处理效果(5.6%)比分段处理(6.8%)好1.2个百分点。每个章节的处理结果也是全文模式略优。
原因可能是嘎嘎的双引擎在处理全文时,能利用上下文关系做更精准的改写。比如文献综述中提到的概念在绪论里已经出现过,全文模式下引擎能识别到这种关联,避免改写时出现前后矛盾。
分段处理还有一个明显的问题:拼接后各段之间的过渡会变得不太自然。我花了额外15分钟手动调整段落衔接。
比话降AI测试结果
全文处理(方式A)
| 章节 | 原文AI率 | 处理后AI率 |
|---|---|---|
| 绪论 | 58.3% | 5.5% |
| 文献综述 | 78.9% | 8.2% |
| 研究方法 | 61.5% | 4.9% |
| 数据分析 | 70.2% | 6.1% |
| 结论 | 55.1% | 4.3% |
| 全文 | 66.7% | 6.0% |
分段处理(方式B)
| 章节 | 原文AI率 | 处理后AI率 |
|---|---|---|
| 绪论 | 58.3% | 4.8% |
| 文献综述 | 78.9% | 7.6% |
| 研究方法 | 61.5% | 5.3% |
| 数据分析 | 70.2% | 7.2% |
| 结论 | 55.1% | 5.1% |
| 全文拼接后 | 66.7% | 6.2% |
对比分析
比话降AI的全文处理(6.0%)和分段处理(6.2%)差距只有0.2个百分点,比嘎嘎的差距(1.2pp)小很多。
这可能说明比话的Pallas NeuroClean 2.0引擎对上下文的依赖没那么强,即使分段处理也能保持较好的效果。不过全文模式仍然略优,而且操作更省事。
有意思的是,比话分段处理时,绪论部分的AI率(4.8%)反而比全文模式(5.5%)更低。这可能是因为绪论字数较少(800字),单独处理时引擎能更"集中火力"地优化。
率零测试结果
全文处理(方式A)
| 章节 | 原文AI率 | 处理后AI率 |
|---|---|---|
| 绪论 | 58.3% | 7.8% |
| 文献综述 | 78.9% | 12.1% |
| 研究方法 | 61.5% | 8.9% |
| 数据分析 | 70.2% | 10.4% |
| 结论 | 55.1% | 6.7% |
| 全文 | 66.7% | 9.4% |
分段处理(方式B)
| 章节 | 原文AI率 | 处理后AI率 |
|---|---|---|
| 绪论 | 58.3% | 8.3% |
| 文献综述 | 78.9% | 13.5% |
| 研究方法 | 61.5% | 9.4% |
| 数据分析 | 70.2% | 11.8% |
| 结论 | 55.1% | 7.1% |
| 全文拼接后 | 66.7% | 10.5% |

对比分析
率零的全文处理(9.4%)比分段处理(10.5%)好1.1个百分点,差距跟嘎嘎接近。不过不管哪种方式,率零的AI率都比另外两款工具高一些。
率零的优势还是在价格上:3.2元/千字,6000字的论文只需要19.2元。如果学校要求AI率低于20%,率零的结果完全够用。
综合数据汇总
| 工具 | 全文处理AI率 | 分段处理AI率 | 差距 | 全文更优? |
|---|---|---|---|---|
| 嘎嘎降AI | 5.6% | 6.8% | 1.2pp | 是 |
| 比话降AI | 6.0% | 6.2% | 0.2pp | 是(差距小) |
| 率零 | 9.4% | 10.5% | 1.1pp | 是 |
结论很明确:全文降AI率的效果普遍优于分段降AI率。
三款工具无一例外,全文处理的AI率都低于分段处理。嘎嘎和率零的差距在1个百分点以上,比话的差距最小。
为什么全文处理效果更好
分析下来有三个原因:
1. 上下文信息更完整
全文处理时,引擎能看到论文的完整上下文,知道前面说了什么、后面要说什么。这样在改写时可以做到前后呼应,改写策略更加精准。
分段处理时,引擎只能看到一个章节的内容,缺乏全局视角。就像你请人帮忙改一篇文章,给他看完整版本和只给他看其中一段,效果肯定不一样。
2. 拼接后的检测劣势
分段处理后拼接成全文,各段之间的"接缝"可能被AIGC检测系统捕捉到。因为每段是独立改写的,风格和用词习惯可能有细微差异,这种不一致性反而会被算法视为AI生成的特征。
3. 处理效率的差异
全文处理时引擎能做全局优化,比如统一调整全文的用词频率、句式分布。分段处理时每段各自为政,无法做到这种全局层面的优化。
分段降AI率就没有用武之地了吗
也不是。有两种情况下分段处理更合适:
情况一:只有部分章节AI率高
如果你的论文是半AI半手写的——比如文献综述是AI生成的(AI率80%),但方法和数据部分是你自己写的(AI率10%),那就没必要处理全文。只处理文献综述那一段就行,省钱。
情况二:论文太长,工具有字数限制
有些工具对单次处理的字数有上限。比如你的博士论文有8万字,可能需要分几次提交。这种情况下分段处理是无奈之举,建议每段尽量长一些(比如按章节而不是按段落拆分),减少接缝数量。
三款工具在全文降AI率场景下的选择
既然全文处理效果更好,那在全文降AI率的场景下,三款工具怎么选?
| 考虑因素 | 推荐工具 | 理由 |
|---|---|---|
| 效果最好 | 嘎嘎降AI | 全文模式AI率最低(5.6%),双引擎全局优化能力强 |
| 风格差异最小 | 比话降AI | 全文/分段差距最小(0.2pp),引擎稳定性好 |
| 价格最低 | 率零 | 3.2元/千字,全文处理9.4%也完全够用 |
| 学术质量保持 | 嘎嘎降AI | 处理后文本学术性强,术语保留率高 |
| 售后最强 | 比话降AI | 不达标全额退款 |
操作建议
基于这次测试,给几个实际操作的建议:
1. 优先选择全文处理
如果论文字数在工具的处理上限内(大部分工具支持万字以上),直接全文提交。效果更好、操作更简单、拼接问题也不用操心。
2. 不得不分段时的技巧
- 按完整章节拆分,不要在段落中间断开
- 每段开头加上前一段的最后1-2句话作为"上下文桥梁"(处理后再删除)
- 处理完后重点检查各段之间的过渡是否自然
- 统一调整全文的用词和风格
3. 先用免费额度试效果
嘎嘎和率零都有1000字免费额度,比话有500字。截取论文中AI率最高的段落先测一下,确认效果后再处理全文。
4. 处理后记得自检
不管用哪种方式,处理完都要自己通读一遍。全文处理虽然效果更好,但也不是完美的,个别地方可能需要微调。

总的来说,全文降AI率在效果上是明确优于分段降AI率的。如果条件允许,始终选择全文处理。三款工具中,嘎嘎降AI在全文模式下的效果最突出,比话降AI的稳定性最好,率零在预算有限时是可靠的选择。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号