从困惑度到GLTR:一文看懂主流AIGC检测算法的底层逻辑
从困惑度到GLTR:一文看懂主流AIGC检测算法的底层逻辑
"你的论文AI率37%。"
看到这个数字的时候,你有没有想过:检测系统到底是怎么算出这个37%的?它凭什么说我的论文有37%是AI写的?
大多数同学对AIGC检测的理解还停留在"黑箱"阶段——上传论文、等结果、看数字。但如果你能搞明白检测算法的底层逻辑,很多事情就豁然开朗了。你会知道为什么有些段落容易被标记,为什么某些改写方式有效而另一些无效,以及为什么不同平台的检测结果会不一样。
今天这篇文章,我就来做一次硬核但不枯燥的技术科普。不需要你有编程基础,大白话就能看懂。

核心概念:困惑度(Perplexity)
困惑度是AIGC检测领域最基础也最重要的概念,几乎所有检测方法都或多或少地用到了它。
先举个日常生活中的例子。你和朋友聊天,朋友说了一句"今天天气真不错,我们去——"。你大概率能猜到下面几个字是"公园""逛街""吃饭"之类的。这种"可预测性"就是低困惑度的体现。
但如果朋友说"今天天气真不错,我们去——冰岛学冰壶",你大概率猜不到。这种"意外感"就是高困惑度。
AI在生成文本的时候,本质上就是在不断地做"猜下一个词"的游戏。而且它总是倾向于选择概率最高的那个词。这就导致了一个结果:AI生成的文本困惑度偏低,因为每个词都太"可预测"了。
人类写作就不一样了。我们会在行文中加入一些"意外"——用一个不太常见的词、转一个出人意料的弯、插入一个看似无关但其实有深意的例子。这些"意外"让人类文本的困惑度天然偏高。
检测系统就是利用这个差异来做判断的。它用一个语言模型去"读"你的论文,计算每个词在上下文中出现的概率。如果大部分词的概率都很高(意味着困惑度低),那这段文字就很可能是AI生成的。
| 特征维度 | AI生成文本 | 人类写作文本 |
|---|---|---|
| 困惑度 | 低(太可预测) | 高(有意外感) |
| 用词概率分布 | 集中在高概率词 | 分散,包含低概率词 |
| 信息熵 | 偏低 | 偏高 |
| 句式多样性 | 较低,模式化 | 较高,灵活多变 |
| 逻辑连贯性 | 过度连贯 | 适度连贯,有跳跃 |

GLTR:把"AI痕迹"可视化
GLTR(Giant Language model Test Room)是麻省理工和哈佛联合开发的一个检测工具,它的核心思想非常巧妙——把困惑度这个抽象的数字变成直观的可视化结果。
GLTR是怎么做的呢?它用一个语言模型对文本中的每个词进行概率排名,然后用不同的颜色来标注:
- 绿色:这个词排名在概率最高的前10位(top-10),非常可预测
- 黄色:排名在前100位(top-100),比较可预测
- 红色:排名在前1000位(top-1000),有点意外
- 紫色:排名在1000位之后,非常意外
如果一段文字全是绿色和黄色,那它大概率是AI生成的,因为每个词都在"意料之中"。如果一段文字红色和紫色比较多,那它更可能是人类写的,因为有很多"意料之外"的词。
这个可视化方法的好处是让你一眼就能看出哪些段落"AI味重"、哪些段落"人味浓"。就像给论文做了一次彩色CT扫描。
GLTR的局限性在于,它是基于特定的语言模型来计算概率的。不同的模型对同一段文字的概率判断不完全一致。而且它更适合检测英文,对中文的支持需要额外的模型适配。
分类器方法:让AI来抓AI
困惑度和GLTR属于"统计分析"的路子,还有一类完全不同的方法——直接训练一个AI分类器,让AI来判断文字是不是AI写的。
这个思路有点像"以毒攻毒"。具体做法是:收集大量的人类文本和AI文本,把它们标注好,然后训练一个深度学习模型去学习区分这两者。
训练好的模型就像一个经验丰富的"老编辑",它见过太多的人类作品和AI作品,积累了一种"直觉"——虽然说不清具体是哪个特征在起作用,但就是能凭整体感觉判断出来。
目前知网、维普等平台的AIGC检测系统,主要用的就是这种方法。它们用海量的学术论文语料库训练分类器,让模型专门学习"学术写作"场景下的人类特征和AI特征。
分类器方法的优势是准确率通常比纯统计方法高,特别是面对经过简单修改的AI文本时。缺点是它像个"黑箱"——你很难知道它到底在看什么特征,也就难以有针对性地优化。

水印检测:从源头做标记
还有一种更"前沿"的检测思路,不是从文本特征入手,而是在AI生成文本的时候就埋下"水印"。
怎么理解呢?想象一下,如果ChatGPT在生成每段文字时,都悄悄地在词语选择中嵌入了一种不可见的规律——比如在特定位置倾向于选择某些词——那检测系统只需要检查这个规律是否存在,就能判断文字是不是来自ChatGPT。
这种方法的好处是检测精度极高,理论上可以接近100%。坏处是需要AI模型厂商的配合——模型本身要植入水印机制。目前OpenAI、Google等公司都在研究水印技术,但还没有大规模部署。
而且水印检测有个天然的限制:它只能检测嵌入了水印的模型生成的文本。如果用的是没有水印的开源模型,或者文本经过了大幅改写导致水印被破坏,这种方法就失效了。
不同检测方法的效果对比
把上面说的几种方法放在一起比较一下:
| 检测方法 | 技术原理 | 中文适配 | 对改写内容的检测 | 误判率 | 代表平台 |
|---|---|---|---|---|---|
| 困惑度分析 | 计算文本的可预测性 | 需适配 | 较弱 | 中等 | GPTZero |
| GLTR可视化 | 词概率排名+颜色标注 | 需适配 | 较弱 | 中等 | GLTR官网 |
| 深度分类器 | 训练模型区分人/AI | 优秀 | 较强 | 较低 | 知网、维普 |
| 水印检测 | 检测生成时嵌入的标记 | 取决于模型 | 不适用 | 极低 | 尚未广泛部署 |
| 混合方法 | 多种方法综合打分 | 优秀 | 较强 | 较低 | 知网3.0 |
从表格可以看出,目前效果最好的是混合方法,也就是把多种检测手段结合起来使用。知网3.0就是典型的混合方法——统计分析做初筛、深度模型做精判、对比检索做验证。
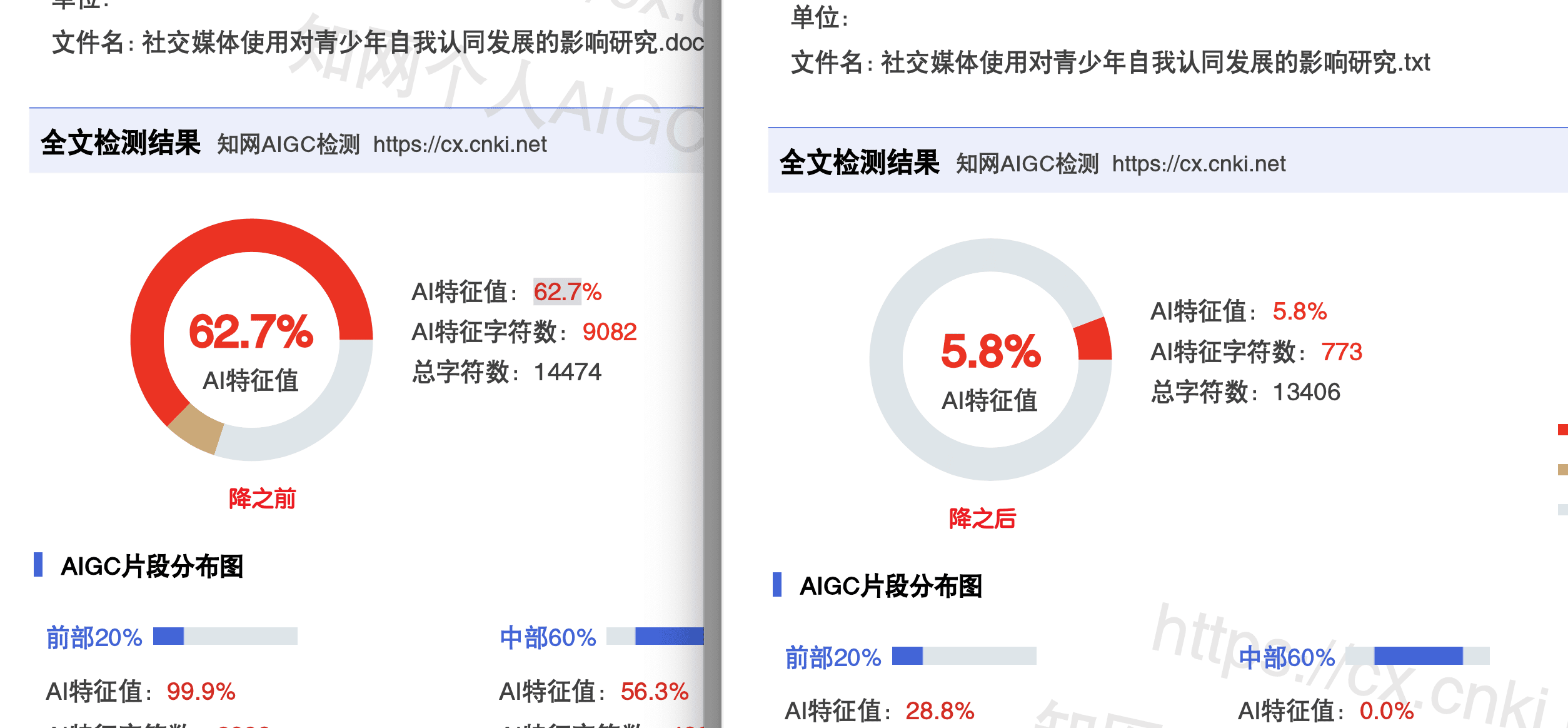
理解了原理,怎么应对
搞懂了检测算法的底层逻辑,应对策略也就水到渠成了。
既然检测系统主要在抓"困惑度低""用词可预测""句式模式化"这些特征,那核心的应对思路就是:让你的文本在这些维度上更像"人类写的"。
手动操作的话,你可以有意识地:增加用词的多样性、打破固定的句式模式、加入一些个性化的表达。但这需要你对检测算法有足够的理解,而且效率很低。
更高效的方式是用专业的降AI工具。这些工具本身就是基于对检测算法的深度研究开发的,它们知道该在哪些维度上做调整。
嘎嘎降AI(aigcleaner.com)的技术方案就是针对主流检测算法做的逆向优化。4.8元/千字,达标率99.26%,覆盖知网、维普、万方等9大平台。它的改写策略不是简单的同义词替换,而是从句式结构、信息分布、表达风格等多个维度重构文本,从根本上改变AI写作的特征模式。
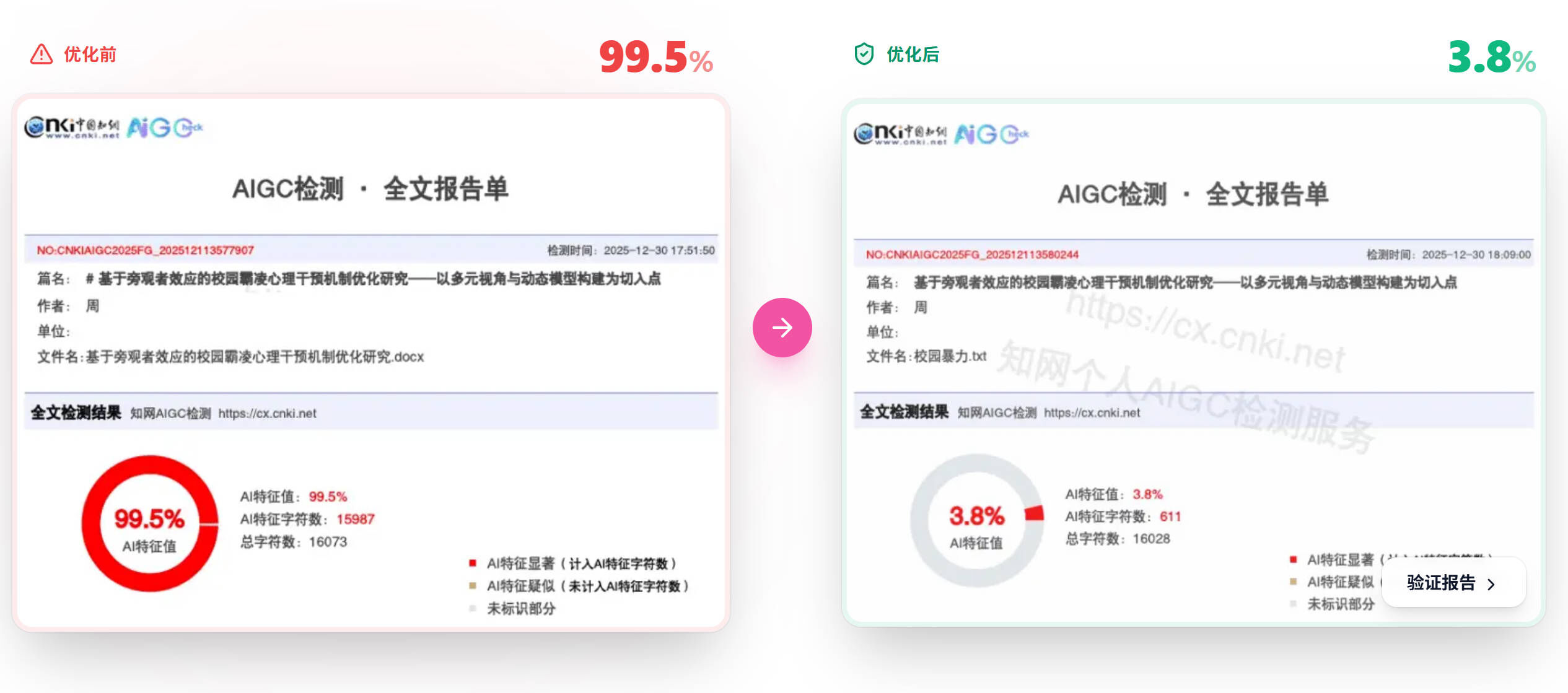
比话降AI(bihuapass.com)专门针对知网的检测算法做了深度适配,8元/千字,达标率99%。如果你只需要过知网这一关,比话的针对性是最强的。
率零(0ailv.com)在保持高效果的同时把价格压到了3.2元/千字,达标率98%,2分钟出结果。性价比在行业里算是天花板级别的。
常见问题解答
Q:检测算法会不会越来越厉害,以后降AI工具都不管用了?
A:检测和降AI之间本质上是一场"军备竞赛"。检测算法在进步,降AI技术也在进步。从目前的技术发展趋势来看,两者会保持一种动态平衡。只要降AI工具能跟上检测算法的更新速度,就不会"不管用"。嘎嘎降AI等主流工具都会持续更新策略来适配最新的检测算法。
Q:困惑度高就一定不是AI写的吗?
A:不一定。现在的AI模型可以通过调整参数(比如提高temperature)来生成困惑度较高的文本。所以单纯依赖困惑度来判断是不够准确的,这也是为什么现代检测系统都采用多种方法综合判断的原因。
Q:我故意在论文里加几个错别字,能骗过检测吗?
A:这个想法挺有创意的,但效果微乎其微。现在的检测系统在分析之前都会做文本预处理,包括纠正明显的错别字和标点错误。而且错别字只影响个别词的概率计算,对整体的特征判断影响很小。与其冒着被导师批评"错字连篇"的风险,不如用专业工具从根本上解决问题。
写在最后
AIGC检测算法没有那么神秘。从困惑度分析到GLTR可视化,再到深度分类器和水印技术,每一种方法都有其科学原理和适用边界。
理解这些原理的意义不在于"钻空子",而在于让你对检测结果有更理性的认知。知道它在看什么、怎么看的,你才能更有针对性地准备论文,或者在需要的时候做出合理的应对。
推荐工具汇总:
- 嘎嘎降AI:aigcleaner.com - 4.8元/千字,达标率99.26%
- 比话降AI:bihuapass.com - 8元/千字,达标率99%
- 率零:0ailv.com - 3.2元/千字,达标率98%
 浙公网安备 33010602011771号
浙公网安备 33010602011771号