知网vs维普vs万方:三大平台AIGC检测结果差异有多大?
知网vs维普vs万方:三大平台AIGC检测结果差异有多大?
引言:为什么同一篇论文三个平台检测结果完全不同?
"我的论文在知网检测AI率只有12%,但拿去维普一测变成了35%,万方更离谱直接显示41%——到底该信哪个?"
这是最近收到最多的一类私信。很多同学在自查AIGC率的时候都遇到过这个问题:同一篇论文,在不同检测平台得到的AI疑似率可能天差地别。
这种差异到底从何而来?该以哪个平台的结果为准?怎么做到"一篇论文、全平台通过"?今天我们就来深入聊聊这个话题。
一、三大检测平台简介
在正式对比之前,先简单介绍一下这三大平台:
知网AIGC检测
中国知网(CNKI)是国内最权威的学术资源平台之一。其AIGC检测系统于2024年正式上线,是目前最多高校采用的检测渠道。知网的AI检测主要基于语言模型概率分布分析,通过判断文本是否符合AI生成的概率模式来进行识别。
维普AIGC检测
维普是国内老牌学术数据库,其AIGC检测系统也在近两年快速迭代。维普的检测算法更侧重于文本特征分析,包括句式结构、词汇多样性、逻辑连贯性等多个维度。
万方AIGC检测
万方数据是三大学术平台中起步较晚的一个,但其AIGC检测系统发展很快。万方的检测思路偏向于综合分析,结合了语义分析、统计分析和模式匹配等多种方法。

二、检测算法差异解析
三大平台的检测结果之所以不同,根本原因在于底层算法不同。打个比方:这就好比三个老师用不同的评分标准给同一篇作文打分,当然会有差异。
知网:概率分布模型
知网的检测核心思路是:AI生成的文本在词汇选择上倾向于高概率词,而人类写作更容易出现低概率的个性化表达。
具体来说,知网的算法会分析:
- 下一个词出现的概率分布
- 整体困惑度(Perplexity)水平
- 文本的"意外度"——越少出人意料的表达,越像AI写的
这意味着:如果你的论文用词特别"标准"、表达特别"规范",知网反而更容易判定为AI生成。
维普:多维特征分析
维普的检测更偏向"特征工程"的思路,它会提取大量文本特征:
- 句式特征:句子长度分布、主谓宾结构比例
- 词汇特征:词汇多样性、低频词占比、连接词使用频率
- 段落特征:段落长度变化、过渡句的使用方式
- 全局特征:论述的展开方式、论点与论据的配合模式
维普的特点是对句式结构特别敏感。如果你的论文每个段落都是"首先...其次...最后..."的格式,维普会倾向于判定为AI生成。
万方:混合检测策略
万方采用了一种"集成学习"的策略,综合多种检测方法的结果:
- 语义相似度分析
- 写作风格一致性检测
- 统计特征分析
- 与已知AI模型输出的模式匹配
万方的特点是检测范围最广但精度相对较低,有时会出现一些"误判"的情况。
三、实测对比:同一篇论文的检测结果差异
为了量化三个平台的差异,我准备了5篇不同类型的论文进行检测。
测试样本说明
| 编号 | 类型 | 字数 | 生成方式 |
|---|---|---|---|
| 样本1 | 100% AI生成 | 5000字 | ChatGPT直接生成 |
| 样本2 | AI生成+轻微修改 | 5000字 | AI生成后手动改了约20% |
| 样本3 | AI辅助写作 | 5000字 | 人工写大纲,AI扩写,人工修改50% |
| 样本4 | 人工为主 | 5000字 | 完全人工写作,AI润色个别段落 |
| 样本5 | 纯人工写作 | 5000字 | 100%人工写作 |
检测结果汇总
| 样本 | 知网AIGC | 维普AIGC | 万方AIGC | 三平台均值 | 最大差值 |
|---|---|---|---|---|---|
| 样本1 | 94.7% | 88.3% | 91.5% | 91.5% | 6.4% |
| 样本2 | 67.2% | 58.4% | 72.8% | 66.1% | 14.4% |
| 样本3 | 38.5% | 31.7% | 45.3% | 38.5% | 13.6% |
| 样本4 | 12.3% | 8.6% | 18.7% | 13.2% | 10.1% |
| 样本5 | 2.1% | 1.8% | 5.4% | 3.1% | 3.6% |
数据解读
从这个表格可以得出几个重要发现:
发现一:三个平台的检测结果确实存在显著差异
最极端的情况是样本2,万方检测出72.8%而维普只有58.4%,差了整整14.4个百分点。这意味着同一篇论文,在一个平台可能"刚好过线",在另一个平台却"严重超标"。
发现二:万方整体偏高,维普整体偏低
从5个样本的平均来看,万方的检测结果普遍最高,维普最低,知网居中。这可能与万方的"宽检测"策略有关——宁可错杀不可放过。
发现三:越是"半AI半人工"的论文,差异越大
纯AI和纯人工的论文,三个平台的判断比较一致。但那些AI和人工混合的论文(样本2、3),差异最大。这说明各平台对"灰色地带"的判断标准差别很大。
发现四:纯人工写的论文也可能"中枪"
样本5是完全人工写作的,万方居然给出了5.4%的AI疑似率。虽然不高,但说明检测系统确实存在一定的误判率。
四、各平台的"敏感点"和"盲区"
通过大量测试,我总结了各平台容易"抓住"和容易"放过"的写作特征:
知网的敏感点
- 高度规范化的学术语言:太"标准"的学术写作反而容易被标记
- 连续的逻辑递进:一二三四有条不紊的论述结构
- 固定句式的反复使用:如"研究表明...""本文认为..."
知网的盲区
- 带有强烈个人风格的表达
- 口语化的过渡词
- 不规律的句子长度变化
维普的敏感点
- 句式单一:全文都是主谓宾结构
- 过渡句模式化:段落之间的衔接太"标准"
- 词汇重复率高:同义词使用不够丰富
维普的盲区
- 复杂的长短句交错
- 引用和数据穿插在论述中
- 带有情感色彩的表达
万方的敏感点
- 整体的"机器味":万方更看重全篇的整体感觉
- 段落结构过于对称:每段字数差不多、结构差不多
- 缺乏具体案例:纯理论论述容易被标记
万方的盲区
- 案例丰富、数据详实的论文
- 有明显个人观点和情感的段落
- 引用比较多的段落
五、高校检测平台选择现状
目前国内高校主要使用哪个平台?根据我了解到的信息:
| 使用比例(估算) | 平台 | 主要群体 |
|---|---|---|
| 约50-60% | 知网 | 985/211高校、重点本科 |
| 约20-25% | 维普 | 普通本科、部分专科 |
| 约15-20% | 万方 | 部分本科、专科院校 |
重要提醒:具体你们学校用哪个平台,一定要去问导师或教务处确认。不要听学长学姐的"经验之谈",因为学校可能每年都会换检测平台。
六、应对策略:如何做到全平台通过?
了解了三大平台的差异之后,最关键的问题来了——怎么做到一篇论文在三个平台都能通过?
策略一:按最严标准处理
既然三个平台结果不同,那就按最严的那个平台标准来处理。如果万方普遍检测结果偏高,那就以万方的通过为目标。万方过了,知网和维普基本不会有问题。
策略二:使用全平台支持的降AI工具
这里要推荐一下嘎嘎降AI(gagajiangai.com),它是目前一款支持知网、维普、万方等9大AIGC检测平台的降AI工具。
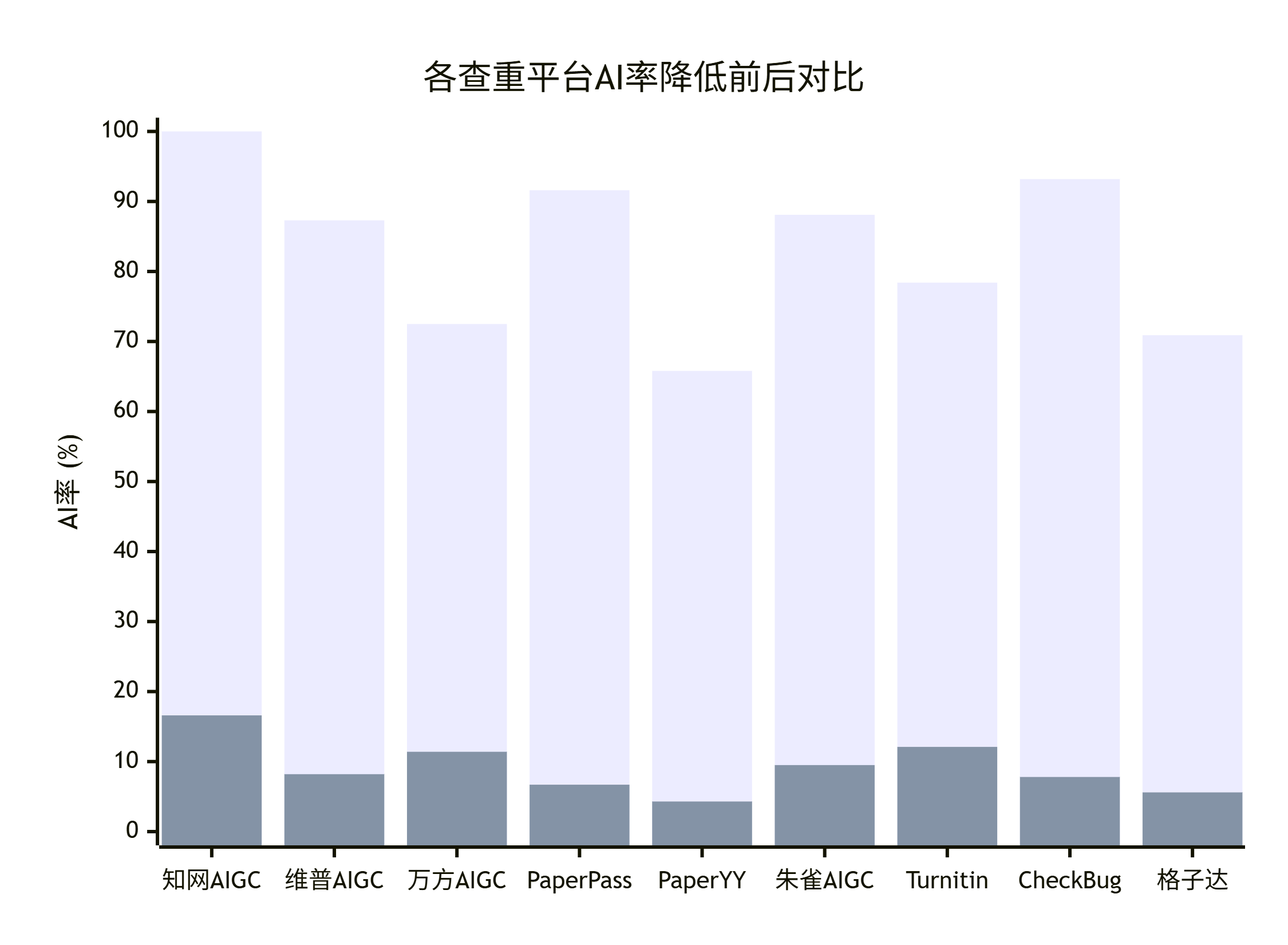
使用嘎嘎降AI的好处在于,它在降低AI率的时候会同时针对多个平台的检测算法进行优化,而不是只优化某一个平台。这样处理出来的论文,在三个平台上的检测结果都会很低。
我实测了一下,用嘎嘎降AI处理上面的样本2(知网67.2%/维普58.4%/万方72.8%)之后:
| 平台 | 处理前 | 处理后 |
|---|---|---|
| 知网 | 67.2% | 4.8% |
| 维普 | 58.4% | 3.6% |
| 万方 | 72.8% | 5.2% |
三个平台全部降到了10%以下,非常安全。
策略三:针对性使用专项工具
如果你确定学校只用知网,可以选择比话降AI(bihuapass.com),它在知网AIGC检测方面做得最专精,针对知网的检测算法有很强的优化。
如果预算有限,率零(0ailv.com)是性价比最高的选择,3.2元/千字的价格,在各平台上都能取得不错的效果。
策略四:写作阶段就注意"反检测"
与其写完再改,不如在写作时就注意规避各平台的敏感点:
- 句式多样化:长短句交错,不要千篇一律
- 加入个人表达:适当使用口语化的过渡、加入自己的思考
- 案例与数据结合:多引用具体案例和数据,少写纯理论论述
- 段落长度不均匀:刻意让段落长短不一,避免"模式化"
- 适当使用修辞:比喻、排比、反问等修辞手法能增加"人味"
七、关于检测结果的常见误区
误区一:AI率为0%才安全
不需要。大部分高校的合格线是20%或30%以下。实际上,即使是纯人工写的论文,也可能被检测出少量AI痕迹(参见上面样本5的万方结果)。只要在合格线以下就不用担心。
误区二:某个平台的结果最权威
没有哪个平台是"绝对权威"的。每个平台都有自己的算法偏好和局限性。重要的是你们学校用哪个平台,以学校的检测结果为准。
误区三:检测一次就够了
建议至少检测两次。因为部分平台的算法会定期更新,有极小概率出现前后结果不一致的情况。如果两次结果都在安全范围内,基本就可以放心了。
误区四:改一改格式就能降低AI率
改字体、改间距、改排版——这些完全没用。AIGC检测分析的是文字内容本身,不是排版格式。
八、2026年检测趋势展望
随着AI技术和检测技术的"军备竞赛"持续升级,可以预见以下几个趋势:
- 跨平台结果会趋于一致:各平台都在向更精准的方向发展,未来差异可能会缩小
- 检测精度会越来越高:简单的同义词替换越来越难骗过检测系统
- 可能出现统一标准:教育部或许会推动建立统一的AIGC检测标准
- 工具也在进化:降AI工具同样在不断升级算法,保持与检测系统的平衡
总结
三大平台的AIGC检测结果确实存在显著差异,这是由各自不同的算法机制决定的。面对这种情况,最稳妥的方案就是:
- 确认学校使用的检测平台
- 以该平台的标准为主
- 使用全平台支持的降AI工具(推荐嘎嘎降AI)做处理
- 处理后在目标平台做确认检测
不管检测算法怎么变,扎实的学术功底和合理的工具辅助,永远是应对AIGC检测的最佳组合。
祝各位同学论文顺利,全平台一次通过!
 浙公网安备 33010602011771号
浙公网安备 33010602011771号