降AI工具的原理是什么?为什么能骗过检测系统
降AI工具的原理是什么?为什么能骗过检测系统
当你把一段AI率85%的文字丢进降AI工具,几分钟后拿回来一段AI率只有8%的文字,你有没有好奇过:这几分钟里到底发生了什么?
降AI工具不是魔法,也不是简单的"换词器"。它们背后有一套完整的技术体系,本质上是对AIGC检测算法的"逆向工程"。本文将深入解析降AI工具的技术原理,带你搞懂它们到底是怎么"骗过"检测系统的。
一、先回顾:AIGC检测在检测什么
要理解降AI工具是怎么工作的,首先得知道AIGC检测在看什么。简单回顾一下,AIGC检测系统主要从以下几个维度分析文本:
- 困惑度(Perplexity):文本对语言模型来说有多"出乎意料"——AI文本困惑度低,人类文本困惑度高
- 信息熵分布:信息在文本中的分布是否均匀——AI分布均匀,人类分布不均
- 词汇多样性:用词是否丰富多变——AI用词相对单一,人类用词更多样
- 句法结构:句式是否模式化——AI句式固定,人类句式灵活
- 语义连贯方式:句子间如何衔接——AI依赖逻辑连接词,人类方式更多元
- 水印检测:部分AI模型嵌入的隐形标记
降AI工具要做的,就是改变文本在这些维度上的表现,让处理后的文本不再符合"AI生成"的统计模式。
二、降AI工具的核心技术原理
2.1 深层语义改写(不是简单换词)
这是降AI工具最核心的技术。
简单换词为什么没用? 因为把"重要"换成"关键"、把"此外"换成"另外",不会改变文本的困惑度、信息分布和句法结构。检测系统看的是深层特征,不是表面词汇。
深层语义改写是什么? 它是在理解原文语义的基础上,用完全不同的句式和表达方式重新组织内容。不仅词汇变了,句子的结构、信息的排列顺序、论述的展开方式都会发生变化——但核心意思保持不变。
举一个具体的例子:
原文(AI味重):
在当前数字化转型的背景下,企业数据治理的重要性日益凸显。有效的数据治理不仅能够提升数据质量,还能为企业的战略决策提供可靠的数据支撑。因此,构建完善的数据治理体系已成为企业数字化建设的关键任务。
深层改写后:
最近几年做数字化的企业越来越多,但很多公司花了大价钱做系统,最后发现数据一团糟——重复的、缺失的、口径不一致的比比皆是。说到底还是数据治理没做好。把这块理顺了,后面不管是做BI看板还是跑AI模型,数据基础才算扎实。所以现在不少CIO都把数据治理提到了很靠前的优先级。
可以看到,改写后的文本:
- 句式从"学术腔"变成了更自然的叙述
- 信息排列从"总分"变成了"具体现象 → 原因分析 → 结论"
- 加入了口语化表达("一团糟""说到底")
- 词汇从标准学术用语变成了更接地气的表达
这种改写从根本上改变了文本的统计特征,自然就能通过检测。
2.2 困惑度注入技术
这是降AI工具的一个关键技术手段——有意识地提高文本的困惑度。
具体做法包括:
- 低概率词汇替换:在不影响语义的前提下,将AI高频使用的"安全词"替换为使用频率更低的同义表达。例如"进行分析"改为"拆解来看","取得了显著成效"改为"效果相当亮眼"。
- 句式扰动:打乱AI惯用的句式模式。例如将"由于A导致了B,因此C"改为"B的出现并不意外,追溯一下就会发现A才是源头,C便顺理成章了"。
- 信息重排:改变信息在句子和段落中的出现顺序,打破AI"从一般到特殊"的标准论述模式。
这些操作的共同目的是让文本变得更"出乎意料",从而提高困惑度,使其不再落入AI文本的低困惑度区间。
2.3 句法结构重构
AI的句法结构有几个非常固定的模式,降AI工具需要打破这些模式:
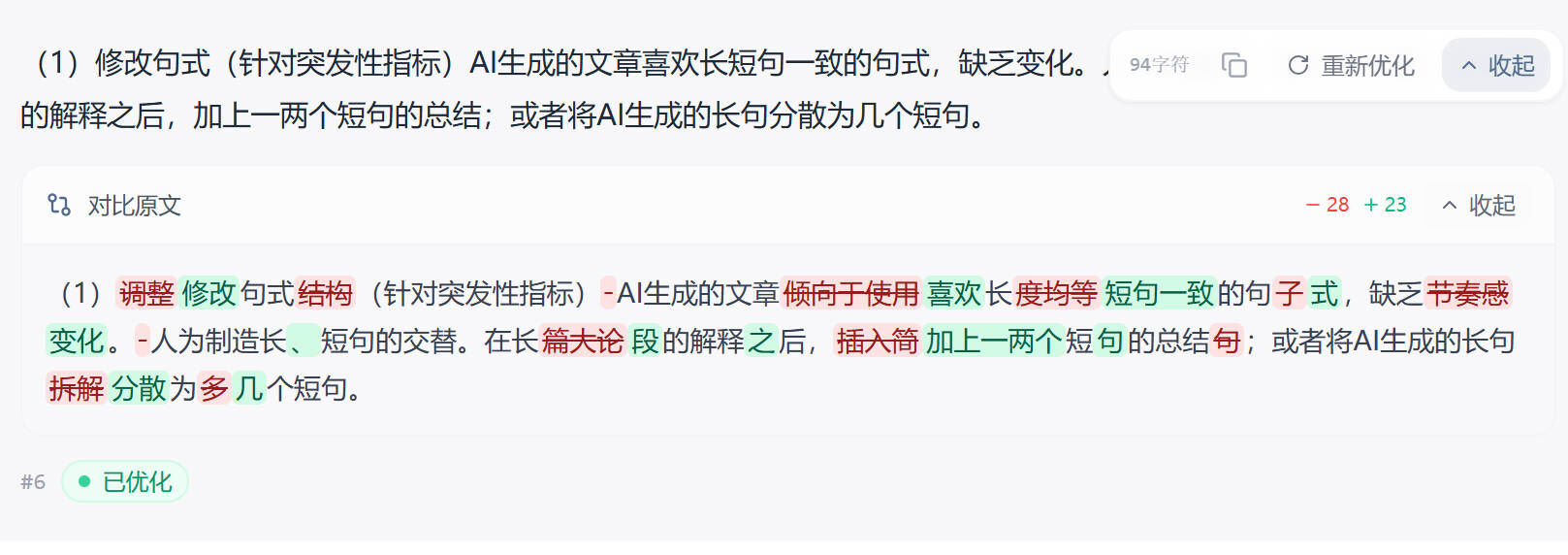
打破均匀的句子长度分布:AI倾向于生成长度相近的句子,降AI工具会有意识地制造句子长度的差异——有时候用一个简短有力的断句,有时候用一个信息量丰富的长句。
消除模板化段落结构:AI几乎每段都是"主题句 + 展开 + 小结"的三段式,降AI工具会重新设计段落的内部组织,有些段落以例子开头,有些段落以反问引入,有些段落直接是一连串的分析推理。
多样化过渡方式:AI依赖"首先、其次、最后"这类显式连接词来组织文本,降AI工具会用更自然的方式实现段落过渡——回指、承接、转折、设问等多种手法交替使用。
2.4 信息分布重整
前面提到,AI文本的信息分布非常均匀,这是一个重要的AI特征。降AI工具通过以下方式制造信息分布的不均匀:
- 在某些段落中增加细节描述和例证,使信息密度升高
- 在某些段落中保持简洁概述,使信息密度降低
- 在论述中穿插"闲笔"——评论性内容、经验性表达、过渡性语句——这些内容的信息密度很低,但恰恰是人类写作的典型特征
2.5 模型对抗技术
这是更高级的技术层面。一些先进的降AI工具使用了类似"对抗样本"的技术——训练一个模型来专门"欺骗"检测模型。
原理类似于图像领域的"对抗样本":通过微小的、人类不可察觉的修改,使得AI分类器的判断发生翻转。在文本领域,这意味着在不影响人类阅读体验的前提下,对文本进行精确的微调,使得检测模型的AI概率判断大幅下降。
这种技术需要大量的训练数据和计算资源,因此通常只有实力较强的工具提供商才能实现。
三、主流降AI工具的技术路线分析
了解了基本原理之后,我们来看看市面上几款主流工具各自采用了什么技术路线。
3.1 嘎嘎降AI(aigcleaner.com)——双引擎并行
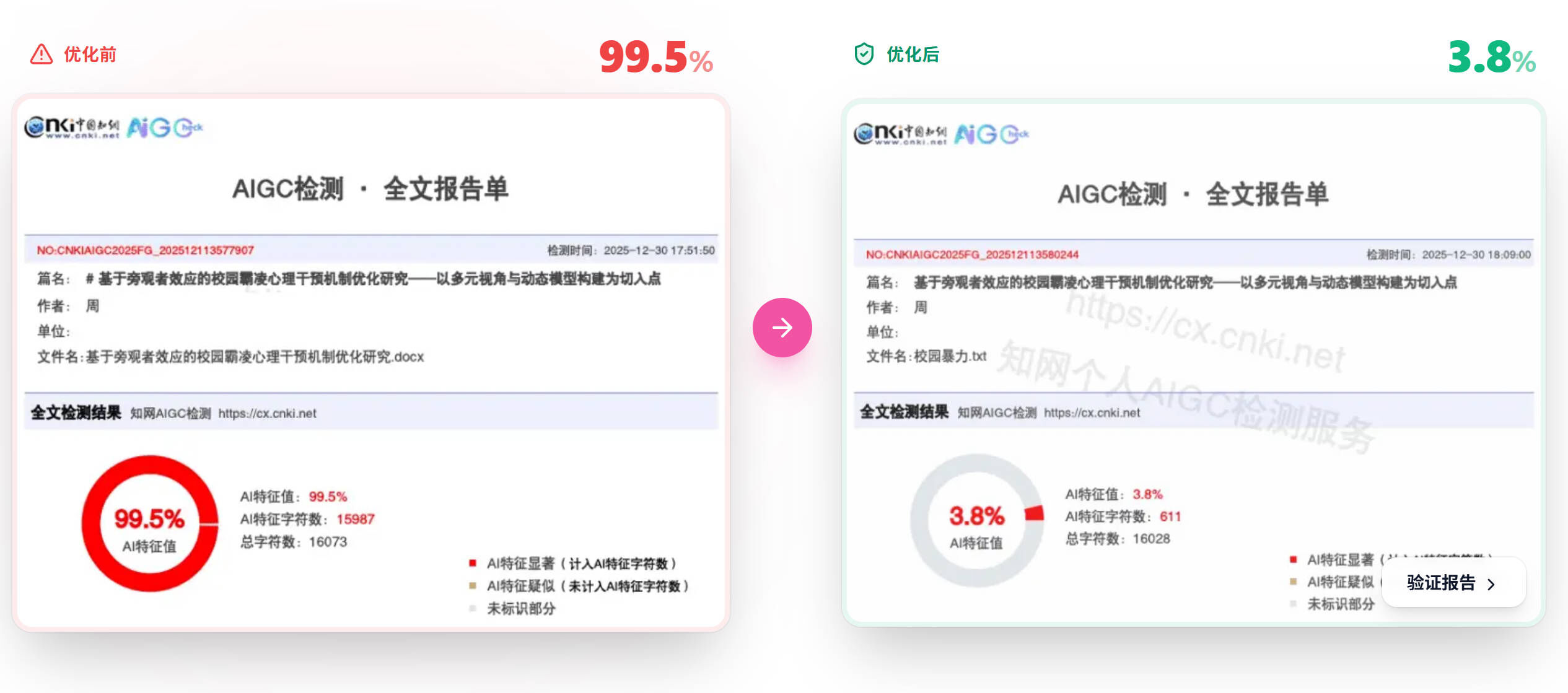
嘎嘎降AI最大的技术特色是双引擎技术。所谓"双引擎",是指它同时运行两套改写模型:
- 引擎A:侧重于语义层面的深度改写,负责重构表达方式和论述逻辑
- 引擎B:侧重于统计特征层面的调整,负责优化困惑度、词汇多样性等指标
两个引擎的输出经过融合和优化,最终生成既语义准确又统计特征达标的文本。
为什么双引擎比单引擎效果好? 因为单引擎往往难以在"语义保真"和"特征调整"之间取得平衡——偏向语义保真则AI特征消除不彻底,偏向特征调整则语义可能偏移。双引擎各司其职,最终融合出两者兼顾的结果。
这也是嘎嘎降AI能够实现99.26%成功率的技术基础。加上它支持知网、维普、万方等9大检测平台的定向优化,能够根据不同平台的检测算法特点进行针对性调整。
适用场景:不确定学校使用什么检测平台、或需要同时通过多个平台检测的用户。价格4.8元/千字,提供1000字免费试用。
3.2 比话降AI(bihuapass.com)——知网专项深度优化
比话降AI采用了一种不同的策略:与其做全平台通用,不如把一个平台做到极致。
它的Pallas NeuroClean 2.0引擎是专门针对知网AIGC检测算法训练的。具体来说,比话降AI的团队对知网的检测模型进行了深入的逆向分析,摸清了知网在困惑度阈值设定、句法特征权重、词汇多样性评分等方面的具体参数和偏好,然后据此训练改写模型。
这种专项优化的优势在于:对知网的检测效果特别好,能够精确地调整那些会触发知网高AI判定的特征。目标是将AI率控制在15%以下,从用户反馈来看这个目标基本能够达成。
不足之处在于:专项优化意味着对其他平台(如维普、万方)的效果可能不如通用型工具。
适用场景:确认学校使用知网进行AIGC检测,且对AI率要求较严格(如需要降到15%以下)的用户。价格8元/千字,提供500字免费试用。
3.3 率零(0ailv.com)——轻量高效的DeepHelix引擎
率零的技术路线可以用"精简高效"来概括。它的DeepHelix引擎在模型规模和复杂度上可能不如前两款,但在关键的几个维度上做到了足够好:
- 困惑度调整:有效提高文本困惑度至人类写作的正常区间
- 句式重构:打破AI的模板化句式,引入更自然的表达变化
- 语义保真:在改写过程中较好地保持了原文核心含义
率零的策略是"把最重要的几件事做好",而不是追求全面覆盖所有技术维度。这使得它的运算成本更低,最终体现为更低的用户价格——3.2元/千字,这是三款工具中最低的。
适用场景:预算有限、AI率不是特别高(如40%-60%需要降到30%以下)、或者作为其他工具的补充手段。提供1000字免费试用。
三款工具技术路线对比
| 维度 | 嘎嘎降AI | 比话降AI | 率零 |
|---|---|---|---|
| 核心技术 | 双引擎融合 | 知网专项逆向优化 | 轻量高效改写 |
| 平台覆盖 | 9大平台 | 主攻知网 | 多平台通用 |
| 成功率 | 99.26% | 目标<15%(知网) | 较高 |
| 改写深度 | 深度改写+特征优化 | 知网算法定向调整 | 关键维度优化 |
| 价格 | 4.8元/千字 | 8元/千字 | 3.2元/千字 |
| 免费额度 | 1000字 | 500字 | 1000字 |
四、降AI工具不是万能的:局限性分析
在了解了降AI工具的原理和优势后,也需要认识到它们的局限性。
局限一:语义偏移的可能性
任何改写都存在语义偏移的风险。虽然现在的工具已经做得相当好了,但在处理高度专业化的内容(如医学、法律、金融等领域的专业论述)时,偶尔可能出现专业术语被替换或含义微妙变化的情况。
应对建议:工具处理后一定要通读全文,重点检查专业术语和核心论点是否准确。
局限二:格式和结构的影响
降AI工具主要处理文本内容,对于表格、公式、图表说明等特殊格式的内容,处理效果可能不理想。
应对建议:将这类内容排除在外,只对纯文本段落进行工具处理。
局限三:不能替代原创写作
降AI工具可以帮助你优化文本的检测结果,但它不能替代你自己的思考和写作。论文的核心价值在于研究内容和学术贡献,而不在于文字表达。如果论文的研究设计、数据分析、论证逻辑存在问题,即使AI率为0%也无法掩盖。
局限四:检测技术在不断进化
AIGC检测系统也在持续升级。今天有效的降AI策略,明天可能就不够用了。因此,不能过度依赖工具,还是应该在写作阶段就注意控制AI的使用程度。
五、"骗过检测"这个说法准确吗?
文章标题用了"骗过检测系统"这个表述,但严格来说这个说法不太准确。更准确的理解应该是:
降AI工具并不是在"欺骗"检测系统,而是在"优化"文本质量。
AIGC检测系统判断的是文本是否符合AI生成的统计模式。降AI工具将文本改写为更接近人类写作风格的版本——用词更个性化、句式更灵活、信息分布更自然。这些改变不仅让文本通过了检测,也确实提高了文本的可读性和自然度。
从另一个角度看,很多人类手写的高质量文本天然就不会被AIGC检测标记。降AI工具做的事情,某种程度上就是把文本的质量"提升"到了人类优质写作的水平。
当然,这并不是说降AI工具可以替代真正的写作能力。最理想的状态是:你自己写的论文本身就不会被检测标记,降AI工具只是在极端情况下的一种保障措施。
六、实用建议:如何最大化降AI工具的效果
建议一:先手动修改核心部分,再用工具处理
如果全文都交给工具处理,不仅费用较高,效果也可能不如"手动+工具"组合方案。建议先手动修改核心论点、研究创新点等关键段落(这些段落最应该体现你自己的思考),再用工具处理AI率较高的辅助性内容(如文献综述的部分段落、背景介绍等)。
建议二:根据学校检测系统选择工具
这一点非常重要。如果学校用知网,优先考虑比话降AI(bihuapass.com),其知网专项优化效果最佳。如果不确定或需要多平台达标,选嘎嘎降AI(aigcleaner.com)的9平台覆盖方案。预算有限时,率零(0ailv.com)是不错的选择。
建议三:利用免费试用验证效果
三款工具都提供免费试用额度(嘎嘎降AI和率零1000字,比话降AI 500字)。建议先用免费额度处理一小段高AI率文本,然后重新检测确认效果,再决定是否大批量使用。
建议四:处理后必须人工校对
这一步不能省略。工具处理后的文本需要通读检查,确保:
- 专业术语没有被错误替换
- 核心论点没有发生偏移
- 前后文的逻辑衔接自然流畅
- 引用格式和数据没有被误改
建议五:保留原文备份
在使用工具之前,务必保存好论文的原始版本。万一工具处理后出现问题,可以随时回退。
七、总结
降AI工具的原理并不神秘,归纳起来就是:通过深层语义改写、困惑度注入、句法结构重构、信息分布重整等技术手段,改变文本的深层统计特征,使其从"AI模式"转变为"人类模式"。
三款主流工具各有技术路线:
- 嘎嘎降AI的双引擎技术在效果和覆盖面上最为全面
- 比话降AI的Pallas NeuroClean 2.0在知网场景下精准度最高
- 率零的DeepHelix引擎在性价比上最具优势
理解这些原理,不仅能帮助你更好地使用这些工具,也能帮助你在日常写作中有意识地避免"AI味"过重的表达方式。毕竟,写出真正属于自己的好论文,才是最终的目标。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号