解读嘎嘎降AI双引擎技术:为什么免费体验就能见效
解读嘎嘎降AI双引擎技术:为什么免费体验就能见效
在降AI率工具的赛道上,嘎嘎降AI凭借"双引擎"技术架构吸引了大量关注。不少用户反馈:仅用1000字的免费体验额度,就能直观感受到AI痕迹的显著降低。
这引发了一个值得深入探讨的问题:这套双引擎技术到底是什么?它的工作原理是怎样的?为什么仅凭免费体验的文本量就能看到明显效果?
本文将从技术视角出发,对嘎嘎降AI的核心引擎进行一次尽可能深入的解读。
一、双引擎架构总览
嘎嘎降AI(aigcleaner.com)的技术核心由两个协同工作的引擎组成:
- 引擎一:语义同位素分析(Semantic Isotope Analysis)
- 引擎二:风格迁移网络(Style Transfer Network)
这两个引擎并非简单叠加,而是以串联+并行的混合模式协作。通俗地说,第一个引擎负责"理解和拆解",第二个引擎负责"重构和伪装",两者共同完成从AI文本到人类文本的转化过程。
要理解这套架构为什么有效,我们需要分别深入每个引擎的工作机制。
二、引擎一:语义同位素分析
2.1 什么是"语义同位素"?
这个概念借鉴了化学中"同位素"的思想。在化学中,同位素是指质子数相同但中子数不同的元素——它们具有相同的化学性质,但物理属性有所差异。
类比到语言领域,"语义同位素"指的是那些表达了相同核心语义,但在文本特征上存在差异的不同表达方式。
举一个简单的例子:
- 表达A:"这项研究的结果表明,该方法在处理大规模数据集时具有显著的优势。"
- 表达B:"从实验数据来看,这个方案在面对海量数据的场景下,展现出了比较突出的处理能力。"
两个表达的核心语义完全相同,但在词汇选择、句式结构、语气风格上存在明显差异。更重要的是,它们在AIGC检测模型中的困惑度、爆发度等指标也会有所不同。
2.2 分析过程
语义同位素分析引擎的工作流程大致如下:
第一步:语义解析。 对输入文本进行深层语义分析,提取每个句子和段落的核心含义,构建语义图谱。这一步的目的是确保后续的改写不会偏离原意。
第二步:同位素库匹配。 基于语义图谱,在预训练的大规模"语义同位素库"中检索可替换的表达方式。这个库不是简单的同义词词典,而是包含了句式级、段落级甚至论证逻辑级的替换方案。
第三步:特征预评估。 对每个候选的替换方案进行AIGC检测特征的预估计算。也就是说,在实际替换之前,系统就会预判这种替换能在多大程度上降低AI检测指标。
第四步:最优选择。 综合考虑语义保持度、检测特征改善幅度、行文自然度等多个因素,选择每个位置上的最优替换方案。
这个过程的关键在于:它不是随机替换,而是有明确优化目标的智能选择。每一处改动都经过了多维度的权衡,这就解释了为什么即使是1000字的处理量,也能看到显著效果——因为每个字的改动都是"精准打击"。
三、引擎二:风格迁移网络
3.1 从"AI式"到"人类式"
如果说语义同位素分析解决的是"换个说法"的问题,那么风格迁移网络解决的是"换个风格"的问题。
AI生成的文本有一些整体性的风格特征,这些特征不是通过局部改写就能消除的。比如:
- 过度的逻辑连贯性:每段之间的过渡太过顺滑,缺乏人类思维中自然的跳跃和发散。
- 均匀的信息密度:每段的信息量分布过于均匀,而人类写作中某些段落可能"话多",某些段落可能"惜字如金"。
- 标准化的学术腔调:AI生成的学术文本往往有一种"教科书式"的统一口吻,缺乏个人化的表达习惯。
风格迁移网络的作用就是在保持语义的前提下,将这些全局性的AI风格特征替换为人类写作的风格特征。
3.2 风格迁移的技术实现
风格迁移的核心思路来源于计算机视觉领域的"神经风格迁移"技术——如果你见过那些把照片变成梵高风格画作的应用,背后就是类似的技术。只不过嘎嘎降AI把这套思路应用到了文本领域。
具体来说,风格迁移网络会:
提取风格特征向量。 分析输入文本的全局风格特征(句子长度分布、词汇多样性指标、连接词使用模式、段落结构等),生成一个"风格向量"。
计算目标风格向量。 基于大量真实人类写作样本训练得到的"人类写作风格空间",计算一个合适的目标风格向量。这个目标不是一个固定模板,而是会根据输入文本的学科领域、文体类型等进行适配。
执行风格变换。 在语义同位素分析完成局部优化之后,风格迁移网络会进行全局层面的调整——可能在某些段落增加一个口语化的转折,在某处插入一个不那么完美的过渡句,或者故意让某段的论述稍微"跑偏"一点再拉回来。这些都是人类写作中常见的特征。
四、双引擎协同:1+1 > 2
两个引擎的协同效果远大于单独使用的加总。原因在于:
语义同位素分析优化了局部特征,风格迁移网络优化了全局特征。 AIGC检测系统同时关注局部和全局两个层面的特征,单独优化任何一个层面都会留下破绽。双引擎协同则实现了"全覆盖"。
两个引擎互相补偿。 语义同位素替换有时会引入一些不够自然的表达,风格迁移网络会在全局调整中将其"消化"掉;反过来,风格迁移有时会对局部语义造成微小偏移,而语义同位素分析的语义保持机制会将其校正。
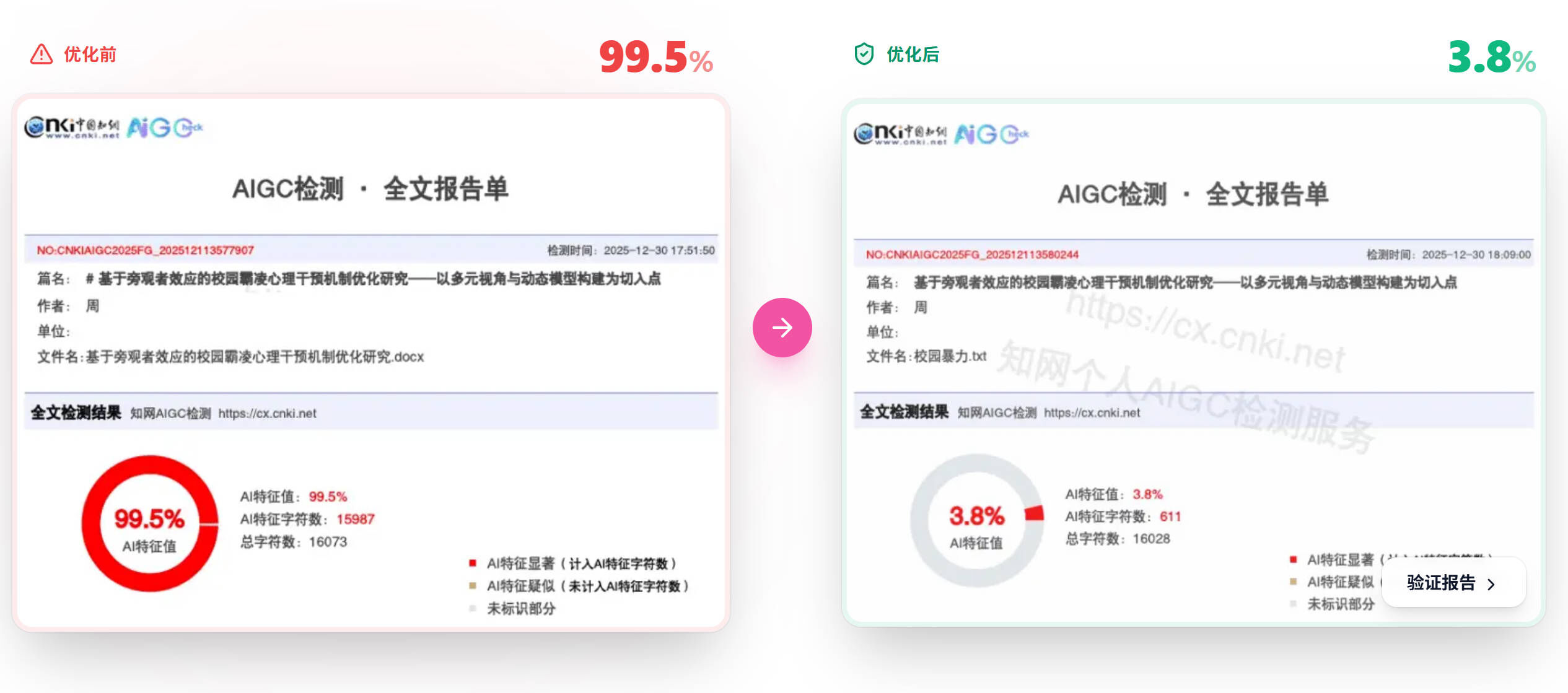
这种协同机制解释了嘎嘎降AI在知网检测中62.7%→5.8%这一显著降幅。单引擎方案很难在不损害语义的前提下实现如此大的降幅。
五、为什么免费体验就能见效?
回到文章标题的问题。嘎嘎降AI提供1000字的免费体验额度,为什么这么少的文本量就能看到效果?
原因一:双引擎对每一处文本的处理都是"全力以赴"的。 免费版和付费版使用的是同一套引擎,同样的算法复杂度,同样的优化深度。不存在"免费版用简化算法"的情况。
原因二:1000字足以构成一个完整的语义单元。 对于学术论文来说,1000字大约相当于一到两个完整段落,这个体量已经足够双引擎充分发挥作用——语义同位素分析能完成多轮局部优化,风格迁移网络也有足够的文本长度来执行有效的全局风格调整。
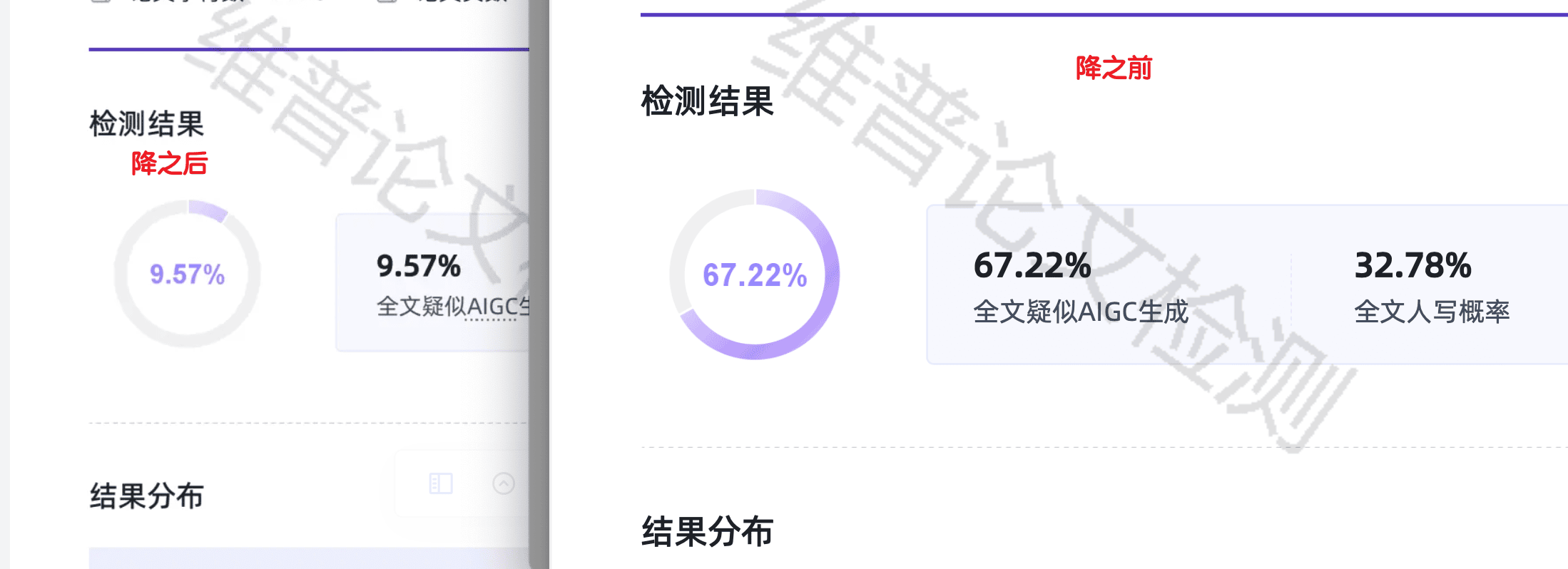
原因三:效果可以被直观量化。 用户可以直接把处理后的1000字拿去跑AIGC检测,得到一个具体的数字。这个数字不会说谎——如果原文AI率是60%+,处理后降到个位数,效果不言自明。
原因四:这是一种技术自信的展示。 从产品策略的角度看,敢于提供1000字免费体验,说明嘎嘎降AI对自己的技术效果有充分信心。如果效果不好,免费试用只会"赶跑"潜在用户。
六、9大平台验证意味着什么?
嘎嘎降AI宣称支持知网、维普、万方等9大检测平台的验证,99.26%的达标率。这个数据背后值得深入分析。
不同的AIGC检测平台使用的检测模型和算法并不完全相同。知网侧重于困惑度分析,维普可能更关注词汇分布特征,万方则有自己独特的检测维度。一款工具如果只针对某一个平台做优化,在其他平台上的效果可能会大打折扣。
嘎嘎降AI能做到9平台通吃,本质上是因为它的双引擎架构从"文本根本特征"层面进行了改造,而不是针对某个特定检测算法做"对症下药"式的hack。这种底层优化的方式,天然具备跨平台的泛化能力。
七、与其他方案的技术对比
为了更全面地理解嘎嘎降AI的技术定位,有必要将其与其他方案做一个简要对比:
vs. 比话降AI(Pallas NeuroClean 2.0): 比话降AI(bihuapass.com)采用的是专攻知网的精准策略,自研引擎针对知网检测模型进行了深度优化。两者的技术路线差异在于"广度vs深度"——嘎嘎降AI追求全平台适配,比话降AI追求单平台极致。比话降AI提供500字免费试用,8元/千字,目标AI率<15%,不达标全额退款。对于确定使用知网检测的用户来说,比话降AI的定向优化是一个有吸引力的选项。
vs. 率零(DeepHelix引擎): 率零(0ailv.com)的DeepHelix深度语义重构引擎同样属于深度语义理解的技术路线,知网实测95.7%→3.7%的数据也很出色。率零提供1000字免费试用,定价3.2元/千字,处理速度约2分钟,在性价比和速度上有明显优势。
vs. 手动改写: 手动改写理论上效果最好(毕竟是真正的人类写作),但时间成本极高。一篇一万字的论文,手动降AI可能需要数天时间。而嘎嘎降AI等工具可以在分钟级别完成处理。
八、使用建议
基于对嘎嘎降AI技术原理的理解,给出以下使用建议:
-
先用免费额度测试最"危险"的段落。 选择你论文中最可能被判定为AI生成的段落(通常是理论分析或文献综述部分),用1000字的免费额度进行测试。
-
处理后务必去检测平台验证。 不要仅凭主观感受判断效果,拿处理后的文本去你学校使用的检测平台跑一遍,用数据说话。
-
利用7天无限修改的政策。 如果第一次处理的结果不够理想(这种情况在99.26%达标率下概率很低),可以在7天内要求重新处理。
-
分段处理,保持上下文连贯。 如果全文较长,建议按照论文的自然分节进行分段处理,这样双引擎在进行风格迁移时能更好地保持段落间的逻辑连贯性。
九、结语
嘎嘎降AI的双引擎技术架构——语义同位素分析与风格迁移网络的协同——代表了当前降AI领域的一个先进技术方向。它不是简单的文本替换,而是对文本从局部到全局的深度重构。
1000字的免费体验足以让你验证这套技术的真实效果。在AIGC检测日益严格的2026年,找到一个靠谱的技术方案,远比在焦虑中反复手动修改要高效得多。
本文基于公开的技术信息和产品数据进行分析,旨在帮助读者理解降AI技术原理。学术论文的核心竞争力在于原创思想,工具只是辅助手段。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号