论文AIGC检测报告怎么看?一文教你读懂每项指标
论文AIGC检测报告怎么看?一文教你读懂每项指标
做完AIGC检测,系统给你弹出一份报告。上面密密麻麻一堆数字和颜色标记,很多同学一脸懵——这都代表什么?哪些需要改?哪些可以不管?
读懂检测报告是降AI的前提。只有知道问题出在哪里、严重程度怎么样,才能有针对性地处理。这篇文章把报告中的每个指标都掰开了讲,看完之后你就知道该怎么应对了。

报告的整体结构
不管你用的是知网、维普还是万方的AIGC检测系统,报告的基本结构都差不多,主要包含以下几个部分:
- 基本信息区:论文标题、作者、检测时间、检测系统版本
- 总体结果区:AIGC疑似度的整体数值
- 分段详情区:每一段或每一句的检测结果和标注
- 统计分析区:各章节的疑似度分布
- 综合评价区:系统给出的整体判定
我们逐一来看每个部分。
核心指标一:AIGC总体疑似度
这是报告中最显眼的数字,通常在报告首页用大字标出。比如"AIGC疑似度:32.7%"。
这个数字代表什么? 它表示你的论文中,有多少比例的内容被系统判定为"疑似AI生成"。32.7%就意味着大约三分之一的文字被认为可能是AI写的。
合格标准是多少? 目前大部分高校的标准:
- 本科论文:AIGC疑似度低于30%
- 硕士论文:AIGC疑似度低于20%到25%
- 博士论文:AIGC疑似度低于15%到20%
- 部分严格院校:不论层次都要求低于20%
注意,这些只是常见标准,具体数字以你所在学校的通知为准。差一个百分点都可能影响结论。
数字的参考意义:
- 0%到10%:非常安全,不需要额外处理
- 10%到20%:比较安全,大部分学校都能通过
- 20%到30%:处于临界区域,建议适当修改
- 30%到50%:需要认真处理,降AI后再提交
- 50%以上:必须大幅修改,可能需要重写部分内容
核心指标二:段落级颜色标注
这是报告中信息量最大的部分。系统会对论文的每一段甚至每一句进行标注,用不同颜色表示AI疑似程度。
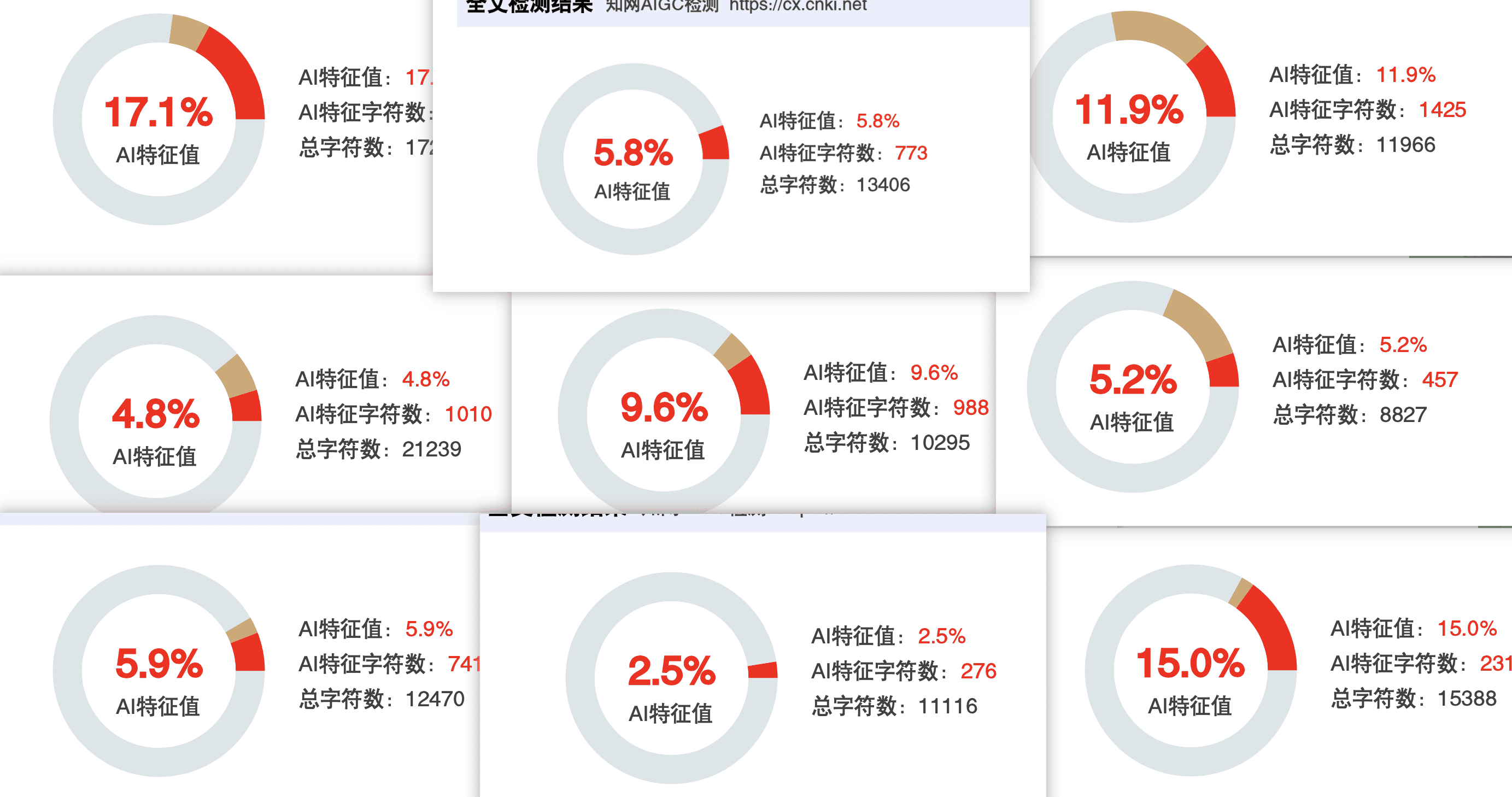
常见的颜色标注规则:
红色(高度疑似): 这些段落被系统判定为大概率是AI生成的。疑似度通常在70%以上。红色段落是需要重点处理的部分,如果不改,它们会严重拉高整体疑似度。
橙色/黄色(中度疑似): 这些段落存在一定的AI生成特征,疑似度通常在40%到70%之间。可能是AI生成后做了一定修改的内容,也可能是人写的但表达方式比较"AI化"。建议视情况处理。
绿色(低度疑似/人工撰写): 这些段落被判定为大概率是人工撰写的。疑似度通常在20%以下。绿色的部分基本不需要修改。
灰色(未检测): 某些内容(如参考文献、作者信息等)系统不纳入检测范围,会标注为灰色。
怎么利用颜色标注? 先快速扫一遍全文的颜色分布。如果大面积是绿色,只有零星几处红色,那问题不大,只需要处理红色段落就行。如果红色和橙色占了一大片,就需要系统性地处理了。
核心指标三:各章节疑似度分布
有些检测报告会按章节统计AIGC疑似度,用表格或柱状图的形式展示。比如:
- 摘要:15%
- 第一章 绑论:28%
- 第二章 文献综述:58%
- 第三章 研究方法:22%
- 第四章 实证分析:45%
- 第五章 结论与建议:35%
这个分布图非常有用,它能帮你快速定位哪些章节是"重灾区"。
规律总结:
文献综述通常疑似度最高。 因为文献综述的写作方式比较固定——总结前人的研究成果、概括理论框架——这种规范化的表达方式和AI生成的文本风格很接近,容易触发检测算法。即使是完全手写的文献综述,疑似度也可能偏高。
数据分析和实证部分的疑似度一般。 如果涉及具体数据描述和分析过程,AI特征会稍低一些。但如果分析讨论的部分写得太规范、太"教科书式",疑似度也会上去。
绪论和结论需要注意。 绪论中"研究背景、研究意义、研究内容"这种固定框架容易被检测算法标记;结论中"本文主要研究了……结果表明……"这种总结性的句式也容易被判为AI风格。
核心指标四:句级检测详情
部分检测系统(比如知网最新版)会提供句级检测详情,精确到每一句话的AI疑似程度。
这个信息对于精准修改非常有帮助。你可以看到具体是哪几句话被判为AI生成的,然后只修改这几句,而不用改整段。
句级检测中常被标记的句型:
- "值得注意的是……"类总结性起手式
- "首先……其次……最后……"类并列展开结构
- "研究表明……"类引用概括句
- "综上所述……"类总结过渡句
- 连续使用规范化学术表达的长段落
这些句型并不是说不能用,但如果一篇论文里密集出现,检测系统就会认为这是AI的典型输出模式。
如何根据报告制定降AI策略
读懂了报告,接下来就是制定修改策略。
情况一:总体疑似度略超标(30%到40%)
这种情况处理起来比较轻松。找到报告中标红的段落,重点处理就行。
具体做法:
- 列出所有红色段落的位置
- 优先处理疑似度最高的段落
- 每个红色段落重新用自己的话表述,或者用降AI工具处理
- 处理完这些段落,总体疑似度通常就能降到合格线以下
推荐用嘎嘎降AI(aigcleaner.com)处理标红段落,4.8元/千字,效果稳定。只处理问题段落的话,花费也不多。
情况二:总体疑似度严重超标(50%以上)
这种情况需要更系统地处理。
具体做法:
- 按章节的疑似度排序,从最高的章节开始处理
- 对于疑似度超过60%的章节,建议整章用降AI工具处理
- 对于疑似度在30%到60%之间的章节,处理其中的红色段落
- 处理完后做一次全文检测,看看效果
- 如果还不够,继续处理剩余的橙色段落
全文处理的话,可以考虑去AIGC(quaigc.com),3.5元/千字,性价比高,适合大量文本处理。
情况三:个别段落被误判
有时候完全自己写的段落也会被标红。这种情况不少见,特别是文献综述和理论分析部分。
判断是否误判的方法:
- 确认这段内容确实是自己手写的
- 看看这段的写作风格是不是太"规范"了
- 检查是否有大量标准化的学术表达
如果确认是误判,可以做适当的表达调整:
- 把一些书面化的表达改成更口语化的版本
- 调整句式结构,把长句拆短或者短句合并
- 增加一些自己的思考和评价性语句
- 适当加入例证和数据支撑
不同检测系统报告的差异
知网、维普、万方的AIGC检测报告在格式和指标上有一些差异,了解这些差异能帮你更准确地解读结果。
知网AMLC: 报告比较详细,提供段落级和句级标注,颜色分区明确。总体疑似度的计算相对严格,同一篇论文在知网的疑似度可能比维普稍高。
维普AIGC检测: 报告格式清晰,侧重段落级分析。维普的检测算法和知网有差异,某些论文在维普的疑似度可能更低或更高。如果你的学校用维普,就以维普的报告为准。
万方AIGC检测: 报告相对简洁,提供总体疑似度和段落标注。万方的检测标准和算法也有自己的特点。
关键点:不要混用不同系统的结果来判断。 比如在知网预检通过了30%,不代表在维普也能通过,反之亦然。一定要用学校指定的系统来做最终判断。
报告中容易被忽略的信息
检测时间戳。 报告上会标注检测时间。如果你的论文在检测之后又做了修改,这份报告就不再代表最新的状态,需要重新检测。
检测字数。 报告中会显示实际检测的文字数量。如果这个数字和你论文的实际字数差距很大,说明可能有部分内容没有被纳入检测(比如图片中的文字、特殊格式的内容)。
系统版本号。 检测算法在持续更新,不同版本的结果可能有差异。如果两次检测结果差距较大,看看是不是系统版本更新了。
实用建议总结
- 拿到报告先看总体疑似度,快速判断是否达标
- 如果不达标,通过颜色标注找到具体的问题段落
- 参考章节分布,了解哪些章节问题最严重
- 根据超标程度选择处理方式:略超标就处理标红段落,严重超标就全章处理
- 处理完一定要复检,不要想当然地认为改了就能过
- 使用降AI工具的话,嘎嘎降AI(aigcleaner.com)和去AIGC(quaigc.com)都是靠谱的选择
- 对于硕博论文这种要求更高的场景,可以考虑比话降AI(bihuapass.com),8元/千字,处理精度更高
读懂了检测报告,降AI就不再是盲目操作了。每一分钱和每一分精力都花在刀刃上,这才是正确的应对方式。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号