[ kvm ] 学习笔记 2:虚拟化基础
1. 虚拟化概念
什么是虚拟化
虚拟化是使用所谓虚拟机管理程序从一台物理机上创建若干个虚拟机的过程。虚拟机的行为和运转方式与物理机一样,但它们会使用物理机的计算资源,如 CPU 、内存和存储。虚拟机管理程序会根据需要将这些计算资源分配给每个虚拟机。
虚拟化有哪些优势
(1)提高硬件资源使用效率
一个服务器可以开多个虚拟机,给不同的应用使用。打破了一个应用一台服务器的限制。
(2)避免应用和服务直接的软件冲突
很多应用和服务不能安装在同一个系统下。
(3)提高稳定性
实现负载均衡、动态迁移、故障自动隔离,减少关机事件。在共享存储的前提下,可以动态的进行迁移,甚至不用关机。
(4)便于管理,降级管理成本
应用的隔离,每个应用使用独立的虚拟机,减少相互影响。
(5)更快的重新部署、更简单备份
可以使用如下功能:模板、克隆、快照
(6)通过动态资源的配置提高 IT 对业务的灵活适应力
业务重点变化时,可以更加灵活、更快的分配计算、存储资源
通过 cpu 虚拟化、内存虚拟化及 I/O虚拟化从根本上了解虚拟化的原理
2. CPU虚拟化
x86 操作系统是设计直接运行在物理硬件之上的,因此完全占有硬件资源。x86 架构提供了 四个特权级别给操作系统和应用程序来访问硬件。Ring 是指 CPU 的运行级别,Ring0 是最高级别,Ring 1-3 依次递减。
应用程序是运行在 Ring3上的,如果应用程序需要访问磁盘,比如写文件,那就需要通过执行系统调用(函数),执行系统调用的时候,CPU 运行级别将从 Ring 3 切换到 Ring 0,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备的访问,完成之后再从 Ring0 切换到 Ring3,这个过程称之为 用户态 和 内核态 的切换。
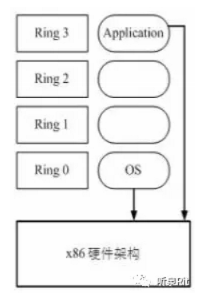
那么问题来了,因为宿主机(物理机)工作在 ring0 的,客户机(GuestOS)就不能工作在 ring0了,但是 客户机操作系统是不知道的,所以这时候就需要 虚拟机管理程序(VMM)来避免这件事的发生。虚拟机通过 VMM 实现 GuestOS CPU 对硬件的访问,根据其原理不同有三种实现技术:
(1)全虚拟化
(2)半虚拟化
(3)硬件辅助的虚拟化
2.1 基于二进制翻译的全虚拟化
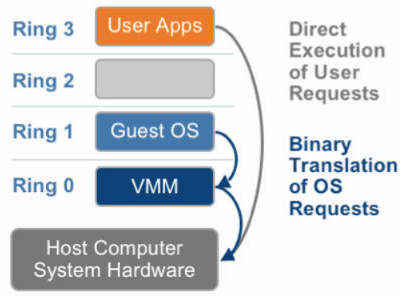
客户操作系统运行在 Ring 1, 它在执行特权指令时,会触发异常(CPU 的机制,没有权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
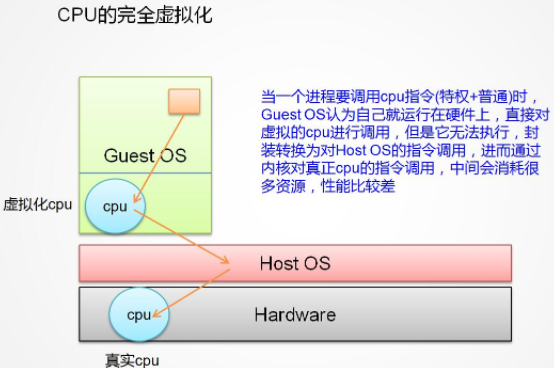
当一个进程要调用 cpu 指令(特权+普通)时,GuestOS认为自己就运行硬件之上,直接对虚拟的CPU进行调用,但是它没有权限执行,当GuestOS 执行特权指令时,会抛出异常,然后HostOS会捕获这个异常翻译,在HostOS中执行指令调用,进而通过内核对真正的cpu执行指令调用,这中间的异常捕获,翻译会消耗大量的资源,性能比较差。
2.2 半虚拟化
半虚拟化的思想就是,修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯,hypervisor同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持。
这种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
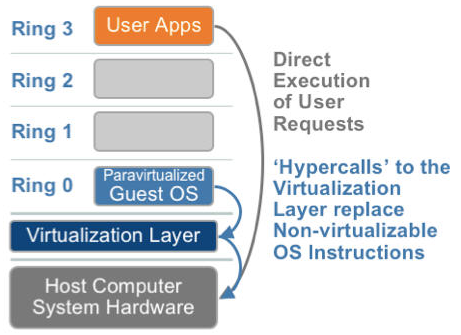
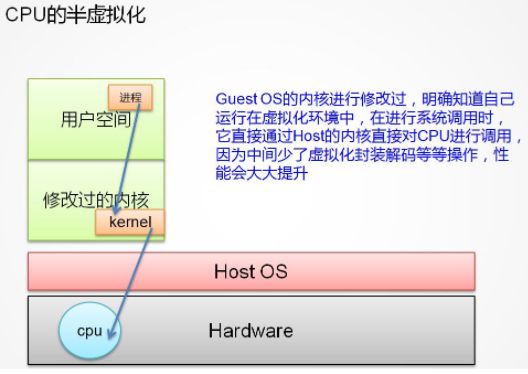
GuestOS 的内核进行修改过,明确知道自己运行在虚拟化环境中,在进行系统调用时,直接通过 Host 的内核对CPU进行调用,因为中间少了虚拟化捕获异常,翻译的过程,性能会大大的提升。代表之一:XEN
2.3 硬件辅助的虚拟化
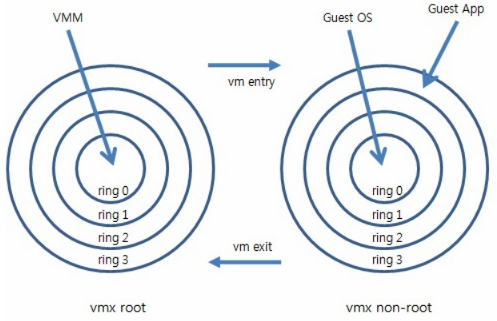
2005年后,CPU厂商Intel 和 AMD 开始支持虚拟化了。 Intel 引入了 Intel-VT (Virtualization Technology)技术。 这种 CPU,有 VMX root operation 和 VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3 共 4 个运行级别。这样,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下。
而且这两种操作模式可以相互转换。运行在 VMX root operation 模式下的 VMM 通过显式调用 VMLAUNCH 或 VMRESUME 指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。Guest OS 运行过程中遇到需要 VMM 处理的事件,例如外部中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务的时候(与系统调用类似),硬件自动挂起 Guest OS,切换到 VMX root operation 模式,恢复 VMM 的运行,这种转换称为 VM exit。VMX root operation 模式下软件的行为与在没有 VT-x 技术的处理器上的行为基本一致;而VMX non-root operation 模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生 VM exit。
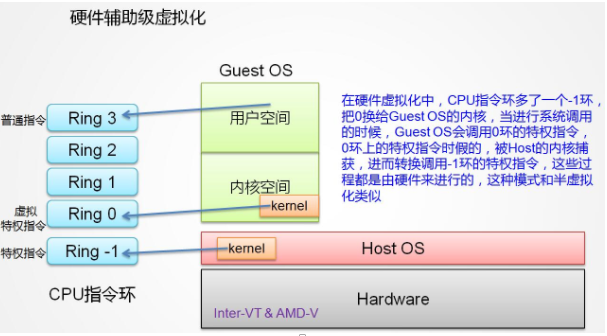
也就是,硬件这层就做了区分,这样全虚拟化下,那些靠“捕获异常 - 翻译 - 模拟” 的实现就不需要了。而且 CPU 厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上硬件辅助虚拟化不需要修改客户操作系统这一优势,硬件辅助虚拟化应该是未来的发展趋势。

区分三者的主要特点:
1. 全虚拟化:欺骗 GuestOS,让GuestOS以为自己是运行在物理机之上
2. 硬件辅助虚拟化:需要CPU硬件的支持
3. 半虚拟化:需要修改GuestOS 的操作系统,windows不支持
3. KVM CPU虚拟化
kvm 是基于 cpu 辅助的全虚拟化方案,它需要 CPU 虚拟化特性的支持。
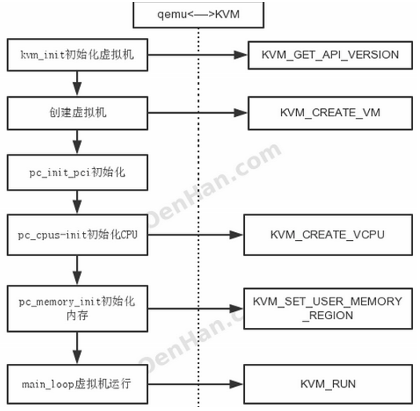
3.1 KVM 虚拟机创建过程

(1)qemu-kvm 通过对 /dev/kvm 的 一系列 ICOTL 命令控制虚机;
(2)一个 KVM 虚机即一个 Linux qemu-kvm 进程,与其他 Linux 进程一样被Linux 进程调度器调度;
(3)KVM 虚机包括虚拟内存、虚拟CPU和虚机 I/O设备,其中,内存和 CPU 的虚拟化由 KVM 内核模块负责实现,I/O 设备的虚拟化由 QEMU 负责实现;
(4)KVM虚机系统的内存是 qemu-kvm 进程的地址空间的一部分;
(5)KVM 虚机的 vCPU 作为 线程运行在 qemu-kvm 进程的上下文中。
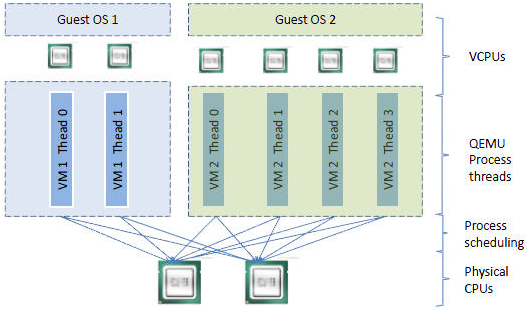
vCPU、QEMU 进程、Linux 进程调度和物理CPU之间的逻辑关系:
2.2 CPU 中虚拟化功能
因为 cpu 中虚拟化功能的支持,并不存在虚拟的 CPU ,KVM Guest 代码是运行在物理 CPU 之上。支持虚拟化的 CPU 中都增加了新的功能。以 Intel VT 技术为例,它增加了两种运行模式:VMX root 模式和 VMX nonroot 模式。通常来讲,主机操作系统和 VMM 运行在 VMX root 模式中,客户机操作系统及其应用运行在 VMX nonroot 模式中。
因为两个模式都支持所有的 ring,因此,客户机可以运行在它所需要的 ring 中(OS 运行在 ring 0 中,应用运行在 ring 3 中),VMM 也运行在其需要的 ring 中 (对 KVM 来说,QEMU 运行在 ring 3,KVM 运行在 ring 0)。CPU 在两种模式之间的切换称为 VMX 切换。从 root mode 进入 nonroot mode,称为 VM entry;从 nonroot mode 进入 root mode,称为 VM exit。可见,CPU 受控制地在两种模式之间切换,轮流执行 VMM 代码和 Guest OS 代码。
对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码,即 VM entry 过程;
在 Guest OS 需要退出该 mode 时,CPU 自动切换到 VMX Root mode,即 VM exit 过程。
可见,KVM 客户机代码是受 VMM 控制直接运行在物理 CPU 上的。QEMU 只是通过 KVM 控制虚机的代码被 CPU 执行,但是它们本身并不执行其代码。也就是说,CPU 并没有真正的被虚拟化成虚拟的 CPU 给客户机使用。
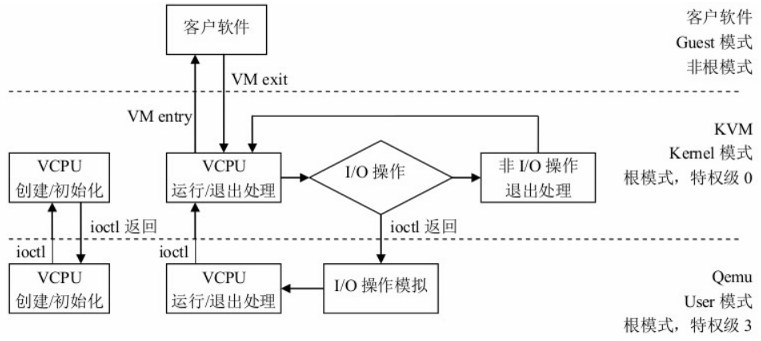
VMM 完成 Vcpu、内存的初始化后,通过 ioctl 调用KVM 接口,完成虚拟机的创建,并创建一个线程来运行 VM,由于VM在前期初始化的时候会设置各种寄存器来帮助KVM查找到需要加载的指令的入口(main函数)。所以线程在调用了KVM接口后,物理CPU的控制权就交给了VM。VM运行在VMX non-root模式,这是Intel-V或者AMD-V提供的一种特殊的CPU执行模式。然后当VM执行了特殊指令的时候,CPU将当前VM的上下文保存到VMCS寄存器(这个寄存器是一个指针,保存了实际的上下文地址),然后执行权切换到VMM。VMM 获取 VM 返回原因,并做处理。如果是IO请求,VMM 可以直接读取VM的内存并将IO操作模拟出来,然后再调用VMRESUME指令,VM继续执行,此时在VM看来,IO操作的指令被CPU执行了。
Intel-V 在 ring0~ring3 的基础上,增加了VMX模式,VMX分为root和non-root。这里的VMX root模式是给VMM(前面有提到VM monitor),在KVM体系中,就是qemu-kvm进程所运行的模式。VMX non-root模式就是运行的Guest,Guest也分ring0~ring3,不过他并不感知自己处于VMX non-root模式下。
Intel 的虚拟架构基本分为两个部分:
虚拟机监视器
客户机(GuestOS)
虚拟机监视器(Virtual-machine monitors - VMM)
虚拟机监视器在宿主机上表现为一个提供虚拟机CPU,内存以及一系列硬件虚拟的实体,这个实体在KVM体系中就是一个进程,如qemu-kvm。VMM负责管理虚拟机的资源,并拥有所有虚拟机资源的控制权,包括切换虚拟机的CPU上下文等。
Guest
这个Guest可能是一个操作系统(OS),也可能就是一个二进制程序,whatever,对于VMM来说,他就是一堆指令集,只需要知道入口(rip寄存器值)就可以加载。
Guest运行需要虚拟CPU,当Guest代码运行的时候,处于VMX non-root模式,此模式下,该用什么指令还是用什么指令,该用寄存器该用cache还是用cache,但是在执行到特殊指令的时候(比如Demo中的out指令),把CPU控制权交给VMM,由 VMM来处理特殊指令,完成硬件操作。
VMM 和 Guest 的切换
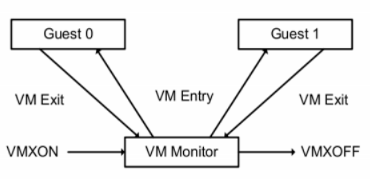
KVM的CPU虚拟化依托于Intel-V提供的虚拟化技术,将Guest运行于VMX模式,当执行了特殊操作的时候,将控制权返回给VMM。VMM处理完特殊操作后再把结果返回给Guest。
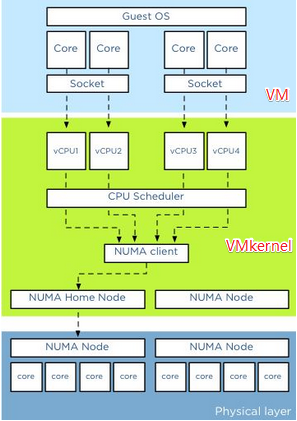
几个概念:socket(颗,cpu 的物理单位),core(核,每个cpu中的物理内核),thread(超线程,通常来说,一个 cpu core 只提供一个 thread,这时客户机就只看到一个cpu;但是,超线程技术实现了 cpu 核的虚拟化,一个核被虚拟化出多个逻辑 cpu,可以同时运行多个线程)。
上图分三层,他们分别是VM层,VMKernel层和物理层。对于物理服务器而言,所有的CPU资源都分配给单独的操作系统和上面运行的应用。应用将请求先发送给操作系统,然后操作系统调度物理的CPU资源。在虚拟化平台比如 KVM 中,在VM层和物理层之间加入了VMkernel层,从而允许所有的VM共享物理层的资源。VM上的应用将请求发送给VM上的操作系统,然后操纵系统调度Virtual CPU资源(操作系统认为Virtual CPU和物理 CPU是一样的),然后VMkernel层对多个物理CPU Core进行资源调度,从而满足Virtual CPU的需要。在虚拟化平台中OS CPU Scheduler和Hypervisor CPU Scheduler都在各自的领域内进行资源调度。
KVM 中,可以指定 socket,core 和 thread 的数目,比如:设置 -smp 5, sockets=5, cores=1, threads=1,则 vCPU 的数目为 5*1*1 = 5。客户机看到的是基于 KVM vCPU 的 CPU 核,而 vCPU 作为 QEMU 线程被 Linux 作为普通的线程/轻量级进程调度到物理的 CPU 核上。其结论是在 VMware ESXi 上,性能没什么区别,只是某些客户机操作系统会限制物理 CPU 的数目,这种情况下,可以使用少 socket 多 core。
2.3 客户机系统的代码是如何运行的
一个普通的 Linux 内核有两种执行模式:内核模式(Kernel)和用户模式 (User)。为了支持带有虚拟化功能的 CPU,KVM 向 Linux 内核增加了第三种模式即客户机模式(Guest),该模式对应于 CPU 的 VMX non-root mode。
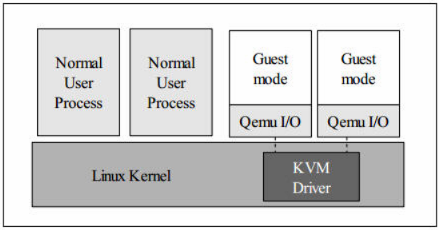
KVM 内核模块作为 User mode 和 Guest mode 之间的桥梁:
User mode 中的 QEMU-KVM 会通过 ICOTL 命令来运行虚拟机
KVM 内核模块收到该请求后,它先做一些准备工作,比如将vcpu 上下文加载到 VMCS(virtual machine control structure)等,然后驱动 CPU 进入 VMX non-root 模式,开始执行客户机代码。
三种模式的分工为:
Guest 模式:执行客户机系统非 I/O 代码,并在需要的时候驱动 CPU 退出该模式;
Kernel 模式:负责将 CPU 切换到 Guest mode 执行 Guest OS 代码,并在 CPU 退出 Guest mode 时回到 Kernel 模式
User 模式:代表客户机系统执行 I/O 操作
QEMU-KVM 相比原生 QEMU 的改动:
原生的 QEMU 通过指令翻译实现 CPU 的完全虚拟化,但是修改后的 QEMU-KVM 会调用 ICOTL 命令来调用 KVM 模块;
原生的 QEMU 是单线程实现,QEMU-KVM 是多线程实现。
主机 Linux 将一个虚拟机视作一个 QEMU 进程,该进程包括下面几种线程:
I/O 线程用于管理模拟设备;
vCPU 线程用于运行 Guest 代码;
其他线程,比如处理 event loop,offloaded tasks 等的线程。
kvm 是一个内核模块,它实现了一个 /dev/kvm 的字符设备来与用户交互,通过调用一系列 ioctl 函数可以实现 qemu 和 kvm 之间的切换。
qemu-kvm 进程工作过程:
1. 启动一个子线程,创建初始化 vcpu,主线程等待;
2. 子线程创建初始化vcpu完毕,子线程等待,并等候通知主线程运行;
3. 主线程继续初始化虚拟化工作,初始化完成,通知子线程继续运行;
4. 子线程继续启动虚拟机 kvm_run,主线程执行 select 交互处理。
kvm 进程分析:
Thread-1:主线程,这个线程loop循环,循环操作 select 实际就是查看有无读写文件描述符,有的话进行读写操作;
Thread-2:子线程,异步进行 I/O 操作,主要针对磁盘映射操作(block drive);
Thread-3:子线程,vcpu 线程,kvm_run启动和运行虚拟机。
示例:通过 qemu-kvm 开启一个 2 核心的虚拟机
# 通过 qemu-kvm 创建一个 2 核心的虚机 [root@localhost ~]# qemu-kvm -cpu host -smp 2 -m 512m -drive file=/root/cirros-0.3.5-i386-disk.img -daemonize VNC server running on `::1:5900' # 查看 qemu-kvm 主进程 [root@localhost ~]# ps -ef | egrep qemu root 24066 1 56 13:59 ? 00:00:10 qemu-kvm -cpu host -smp 2 -m 512m -drive file=/root/cirros-0.3.5-i386-disk.img -daemonize root 24077 24041 0 13:59 pts/0 00:00:00 grep -E --color=auto qemu # 查看 qemu-kvm 子线程 [root@localhost ~]# ps -Tp 24066 PID SPID TTY TIME CMD 24066 24066 ? 00:00:00 qemu-kvm 24066 24067 ? 00:00:00 qemu-kvm 24066 24070 ? 00:00:07 qemu-kvm 24066 24071 ? 00:00:02 qemu-kvm 24066 24073 ? 00:00:00 qemu-kvm # 通过 gdb 查看子线程的作用 (gdb) thread 1 [Switching to thread 1 (Thread 0x7fb830cb2ac0 (LWP 24066))] #0 0x00007fb829eaebcd in poll () from /lib64/libc.so.6 (gdb) thread 2 [Switching to thread 2 (Thread 0x7fb7fddff700 (LWP 24073))] #0 0x00007fb82de0e6d5 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 (gdb) thread 3 [Switching to thread 3 (Thread 0x7fb81fe6e700 (LWP 24071))] #0 0x00007fb829eb02a7 in ioctl () from /lib64/libc.so.6 (gdb) thread 4 [Switching to thread 4 (Thread 0x7fb82066f700 (LWP 24070))] #0 0x00007fb829eb02a7 in ioctl () from /lib64/libc.so.6
通过上面的数据得出:
1 个 2 核心的虚拟机,4个子线程:
(1)thread-1:主线程 loop 循环,循环操作 select 查看有无读写文件描述符,有的话进行读写操作;
(2)thread-2:子线程 异步 I/O 操作,主要针对磁盘映像操作(block drive);
(3)thread-3:子线程 vcpu 线程,kvm_run 启动和运行虚拟机;
(4)thread-4 同 thread-3
2.4 从客户机线程到物理 cpu 的两次调度
要将客户机中的线程调度到某个物理 cpu,需要经历两个过程:
(1)客户机线程调度到客户物理cpu 即 KVM vCPU,该调度由客户机操作系统负责,每个客户机操作系统的实现方式不同。在kvm上,vCPU 在客户机系统看起来就像物理 cpu,因此其调度方法也没有什么不同;
(2)vCPU 线程调度到物理 CPU 即主机物理 CPU,该调度由 Hypervisor 即 Linux 负责。
KVM 使用了标准的 Linux 进程调度方法来调度 vCPU进程。Linux系统中,线程和进程的区别是 进程有独立的内核空间,线程是代码的执行单位,也就是调度的基本单位。Linux中,线程是轻量级的进程,也就是共享了部分资源的进程,所以线程也按照进程的调度方式来进行调度。
2.5 客户机 VCPU 数目的分配方法
1. 不是客户机的 vcpu 越多,其性能越好,因为线程切换会消耗大量的时间;应该根据负载需要分配最少的 vcpu;
2. 主机上客户机的 vcpu 总数不应该超过 物理 cpu 内核总数。不超过的话,就不存在 cpu 竞争,每个 vcpu 线程在一个物理 cpu 核上被执行;超过的话,会出现部分线程等待 cpu 以及 一个 cpu 核上的线程之间的切换,这会 overhead;
3. 将负载分为 计算负载 和 I/O负载, 对计算负载,需要分配较多的 vcpu,甚至考虑 cpu 亲和性,将制定的物理 cpu 核分给这些客户机。
确定 Vcpu 数目的步骤。假如我们要创建一个VM,以下几步可以帮助确定合适的vCPU数目:
1. 了解应用并设置初始值
该应用是否是关键应用,是否有Service Level Agreement。一定要对运行在虚拟机上的应用是否支持多线程深入了解。咨询应用的提供商是否支持多线程和SMP(Symmetricmulti-processing)。参考该应用在物理服务器上运行时所需要的CPU个数。如果没有参照信息,可设置1vCPU作为初始值,然后密切观测资源使用情况。
2. 观测资源使用情况
确定一个时间段,观测该虚拟机的资源使用情况。时间段取决于应用的特点和要求,可以是数天,甚至数周。不仅观测该VM的CPU使用率,而且观测在操作系统内该应用对CPU的占用率。特别要区分CPU使用率平均值和CPU使用率峰值。假如分配有4个vCPU,如果在该VM上的应用的CPU:
(1)使用峰值等于 25%,也就是仅仅能最多使用 25% 的全部CPU资源,说明该应用是单线程,仅能够使用一个vCPU;
(2)平均值小于38%,而峰值小于45%,考虑减少 vCPU 数目;
(3)平均值大于75%,而峰值大于90%,考虑增加 vCPU 数目。
3. 更改 vCPU 数据并观测结果
每次的改动尽量少,如果可能需要 4vCPU,先设置 2vCPU 在观测性能是否可以接受。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号