OO_第一单元总结
第一次作业
概述:单变量多项式的括号展开
思路:参考了讨论区的方法,将变量因子和常量因子放在一起。删除了多余的+-符号和空白项,并将"**"替换成"^"。为了toString方法和计算的方便,将正负号放在因子上,下图是计算(x+2)**2以及(x+2)**2*x**2时数据的存储方式。所以在我的最终结果不会出现某个Term里有多个Factor的情况,即Term里只有一个Factor(主要思路就是把大部分的事情都放在因子上处理)。得到最终结果后合并同类项,还可以判断第一个字符是否为+,如果是,则删除。
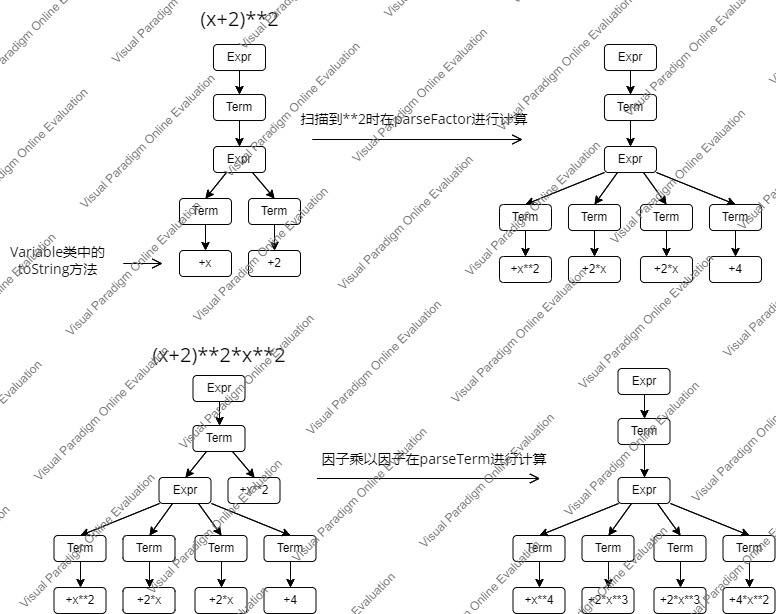
我的toString方法,
Expr类的toString方法如下:
public String toString() {
Iterator<Term> iter = terms.iterator();
StringBuilder sb = new StringBuilder();
while (iter.hasNext()) {
Term term = iter.next();
sb.append(term);
}
return sb.toString();
}
Term类的toString方法如下:
public String toString() {
Iterator<Factor> iter = factors.iterator();
StringBuilder sb = new StringBuilder();
sb.append(iter.next().toString());
return sb.toString();
}
Variable类的toString方法如下:
public String toString() {
StringBuilder sb = new StringBuilder();
if (coe.compareTo(BigInteger.ZERO) >= 0) {
sb.append("+");
}
if (this.pow.equals(BigInteger.ZERO)) { //常量
sb.append(coe);
} else if (this.pow.equals(BigInteger.ONE)) { //?x
if (coe.equals(BigInteger.ONE)) {
sb.append("x");
} else if (coe.equals(BigInteger.ONE.negate())) {
sb.append("-x");
} else {
sb.append(coe + "*x");
}
} else if (this.pow.equals(BigInteger.valueOf(2))) { //?x**2
......
}
else { //?x**?
......
}
return sb.toString();
}
程序结构分析
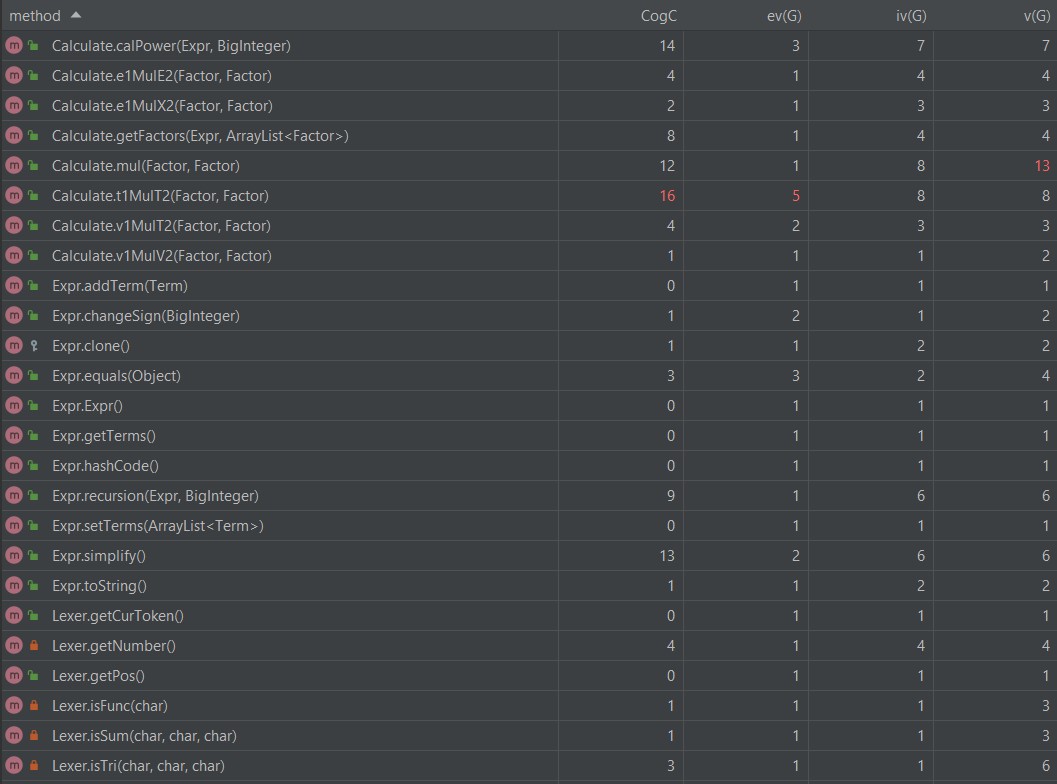
度量分析
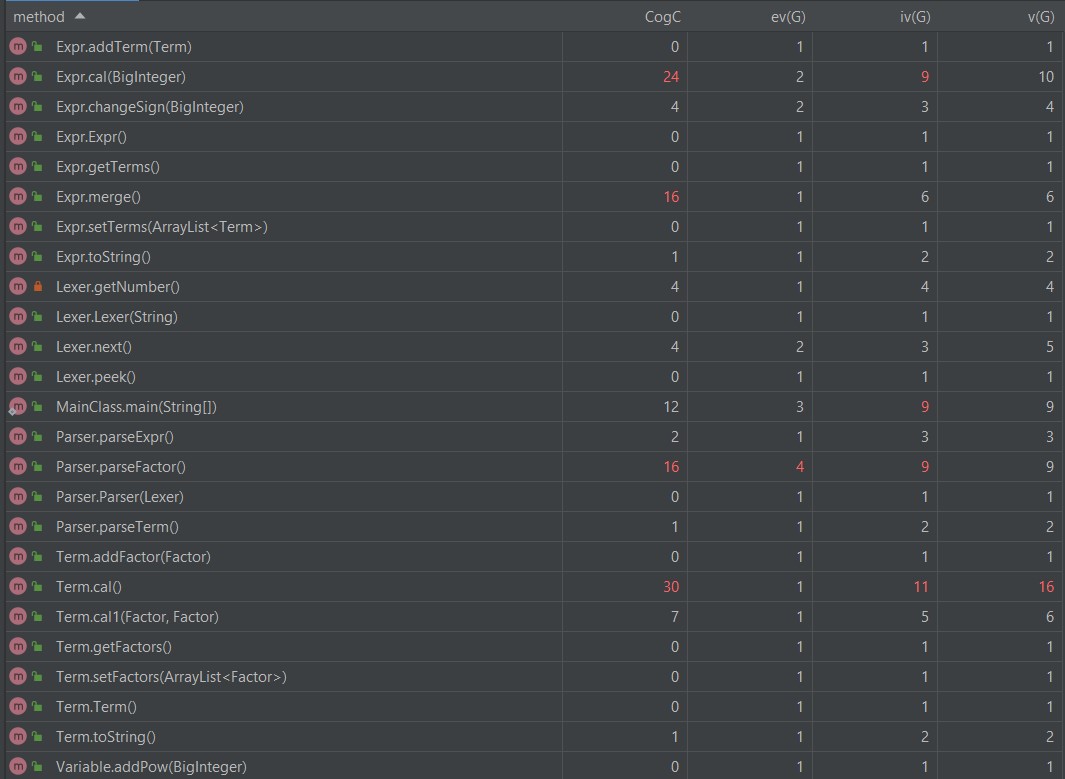
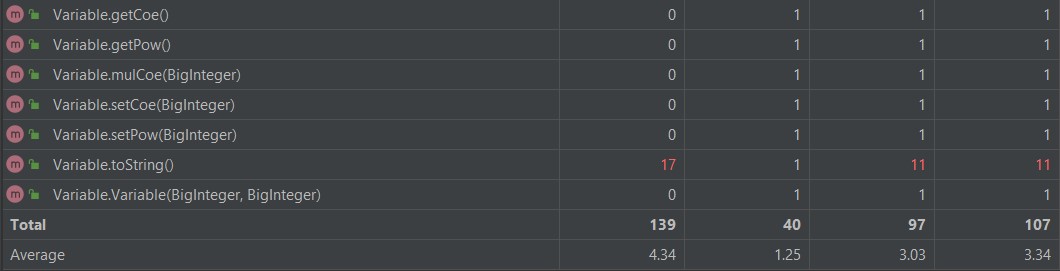
复杂度高的原因:
MainClass类中的main方法用了if,else处理+-符号。
Parser类的parseFactor方法用了if,else判断符号以及是哪一个因子。
Variable类的toString方法用了很多if,else判断系数和指数为多少时输出什么。
cal方法和merge方法复杂度高的原因会在下面缺点说出。
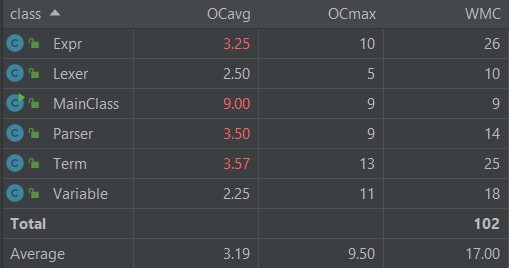
UML类图
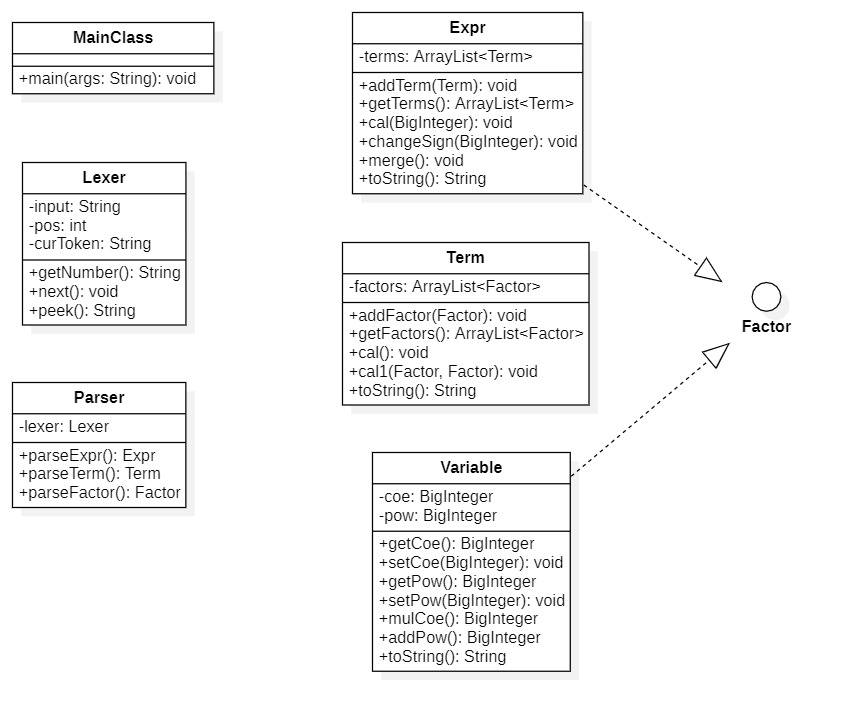
Expr类的cal方法是计算有指数的表达式因子。
Term类的cal方法是计算因子乘以因子。
优点
对我来说,就是toString方法和计算上方便了很多。
缺点
我的计算方法是将因子拿出来,做乘法了之后,再把结果放进一个新的因子,所以某些地方(表达式因子)用了很多for,使复杂度大大增加。
这也是我cal方法复杂度高的原因。merge方法类似。
自己程序的bug
在处理有前导零的整数时,不知道BigInteger是可以自动删前导零的,所以自己写了个删除前导零的方法写出bug了...
第二次作业
概述:多项式的括号展开与函数调用、化简。在第一次作业的基础上增加了三角函数因子,求和函数和自定义函数。
思路:沿用第一次作业的思路“最终结果不会出现某个Term里有多个Factor的情况,把大部分事情都放在因子上处理”。于是新建了一个TriFunc类,TriFunc类包含了Tri和Variable两个类,Tri类是以ArrayList的方式存储,下图可作为参考。

在我看来,这样存储是比较好使用第一次作业的思路去写toString和计算方法的。所以我的最终结果的叶结点只会是TriFunc类或Variable类。
自定义函数--使用了正则表达式将自定义函数定义划分为多个group,然后存进SelDefFunc类。在parse完自定义函数调用的因子后,也将该因子存进SelDefFunc类。会将它们都存进同一个SelDefFunc类,是觉得这样会比较容易实现带入参数并替换数据和解决f(x,y,z)=z+y+x的问题。
求和函数--通过lexer类的getCurToken方法和getPos方法获取当前位置,然后parse求和表达式。如果还需要再计算求和表达式,则通过setCurToken方法和setPos方法回到之前的位置,然后parse。
求和函数和自定义函数都是通过带入参数的方式替换数据。
我还将第一次作业的计算方法全都移去了Calculate类。
因为正负号是在因子上的,所以得到最终结果.toString()后可能会出现sin(+x)-sin(+2)的情况,可以将"(+"替换成"("。
程序结构分析
度量分析
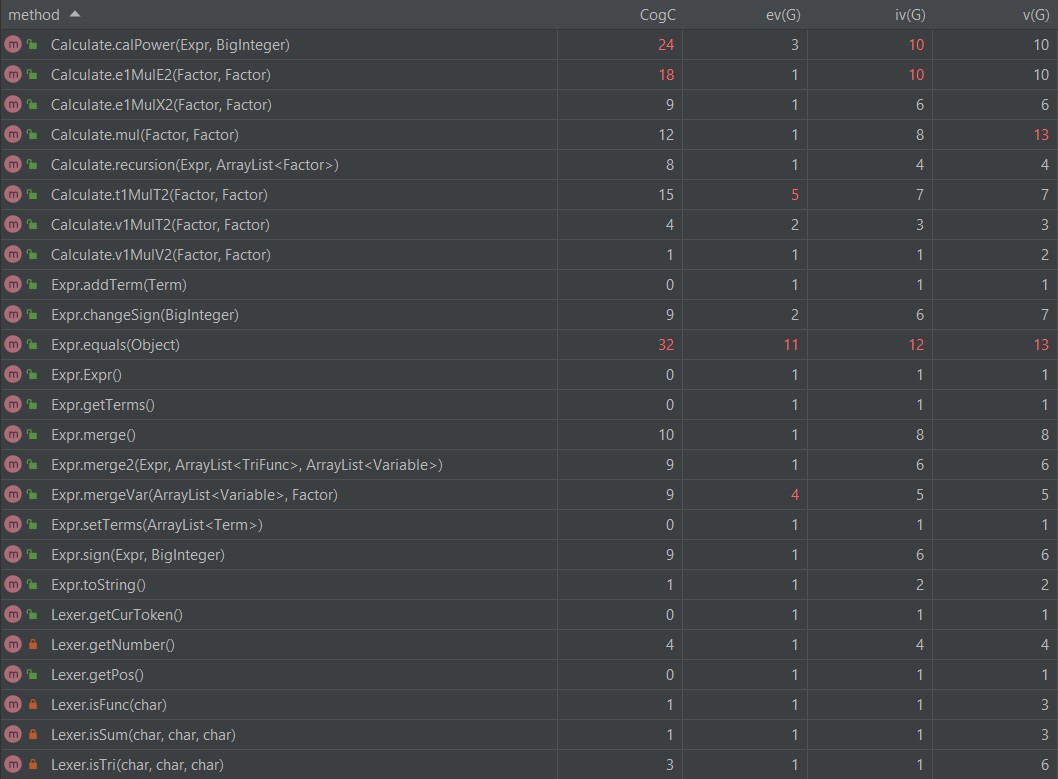


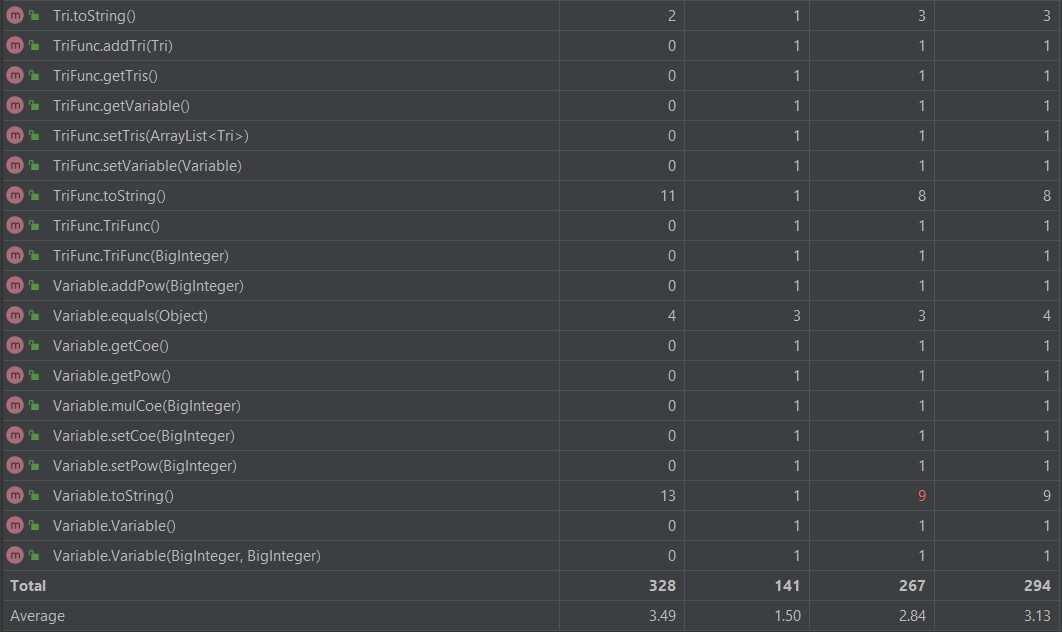
可以看到复杂度偏高的都是在Calculate类,这些都和第一次作业的原因一样的。
那个equals方法为了实现一点点的优化,胡乱地写了一些代码,写得挺差劲的,就不多说了。
其它的复杂度高是因为因子增加了,用if,else判断的次数也增加了。
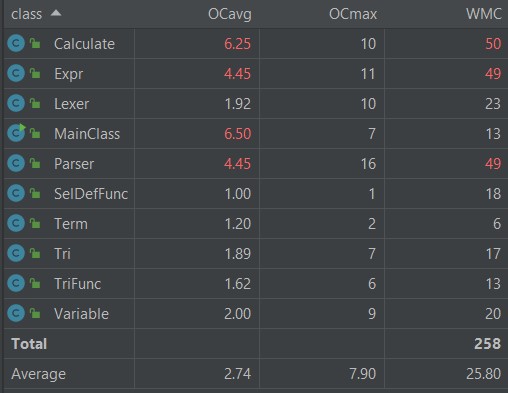
UML类图

优点
架构更改量较少,大多都是因为新增的因子增加了一些类。
缺点
使用TriFunc类这样的方式后,对于sin(x)*cos(2)+2*cos(2)*sin(x)这样的数据合并较困难,我的方式是没进行合并的因为顺序问题。
自己程序的bug
第一个bug是在sum(i,常数因子,常数因子,求和表达式)里,明明好像看到了写的是常数因子,但是写代码的时候写成了BigInteger num = new BigInteger(lexer.peek());(建议睡饱有精神了再写代码)
第二个bug是SelDefFunc类在替换数据时遇到的深拷贝问题,没拷到最底层,数据在做计算的时候被改了。
第三个bug是优化sin(0)的代码放错位置了,遇到sin(0)**2的时候会因为扫描到sin(0)就返回0,而后面的**2没有扫描到。还有忘记改变符号了。
第三次作业
概述:多层嵌套表达式和函数调用的括号展开与化简。😛
思路:实验课提供了很好的方法解决多层括号的问题,那当然是直接拿来用了。😄
第二次作业没怎么做到优化,所以第三次作业多做了一些优化。😦
把merge方法放去了MainClass类。😮
程序结构分析
度量分析
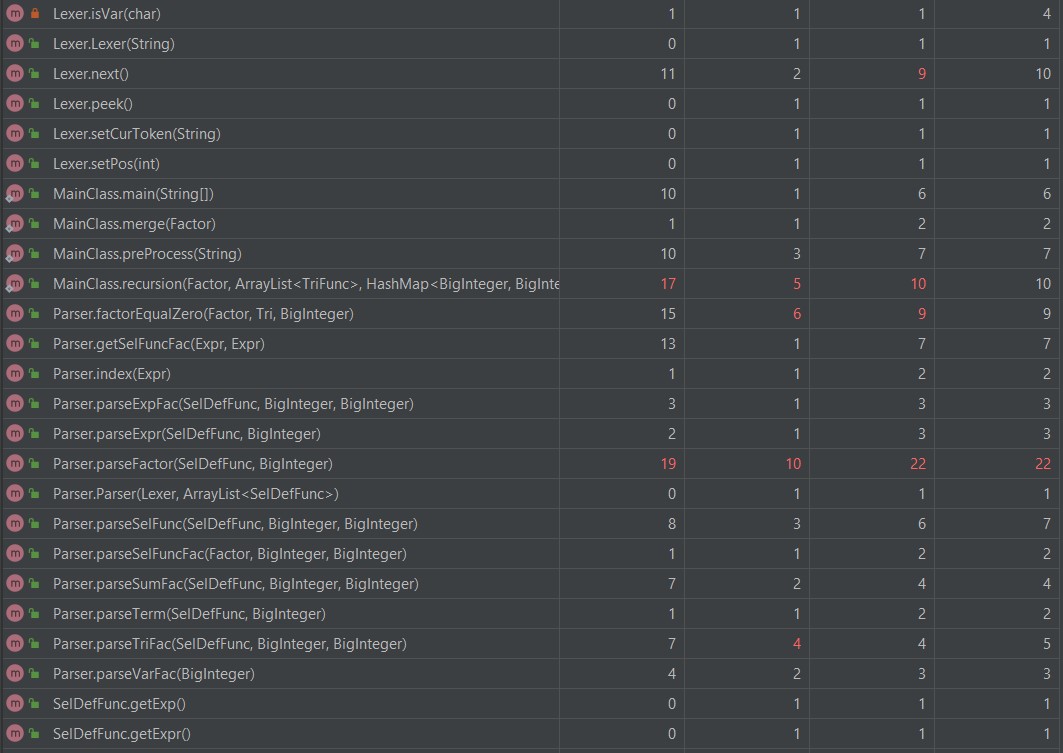
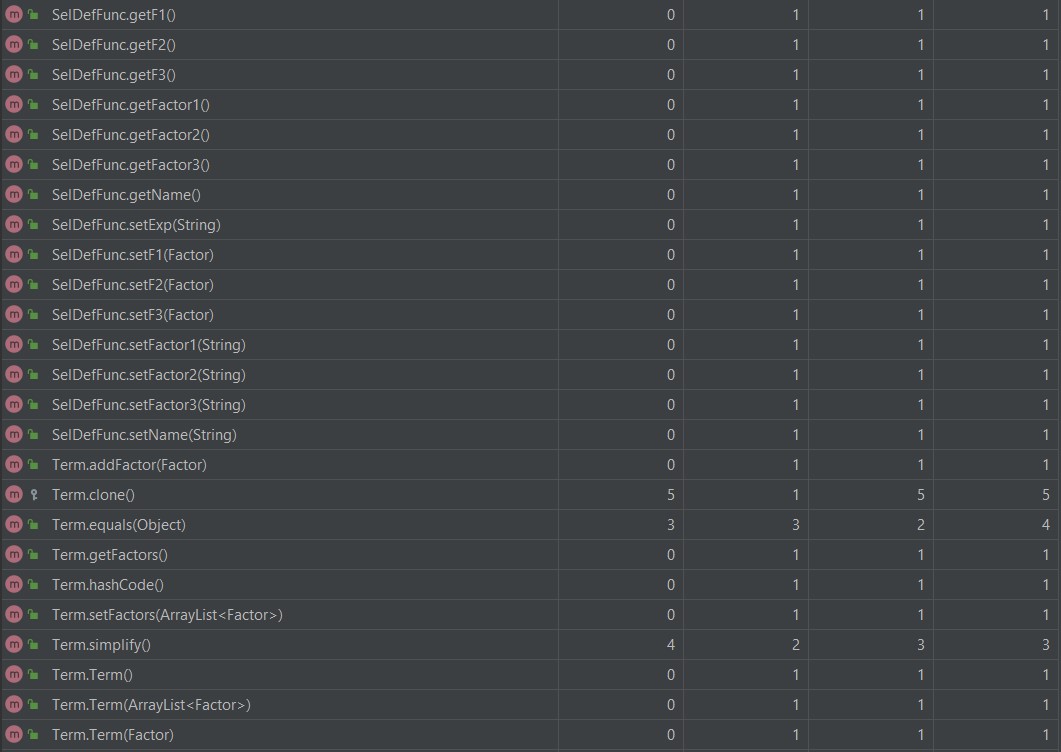
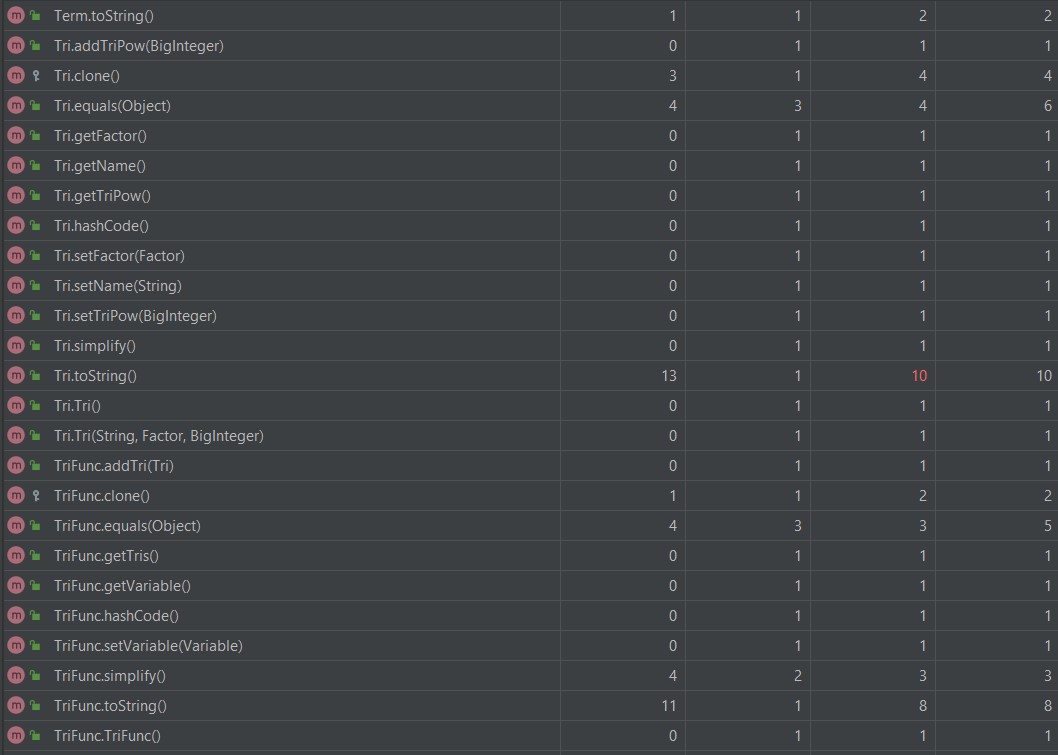
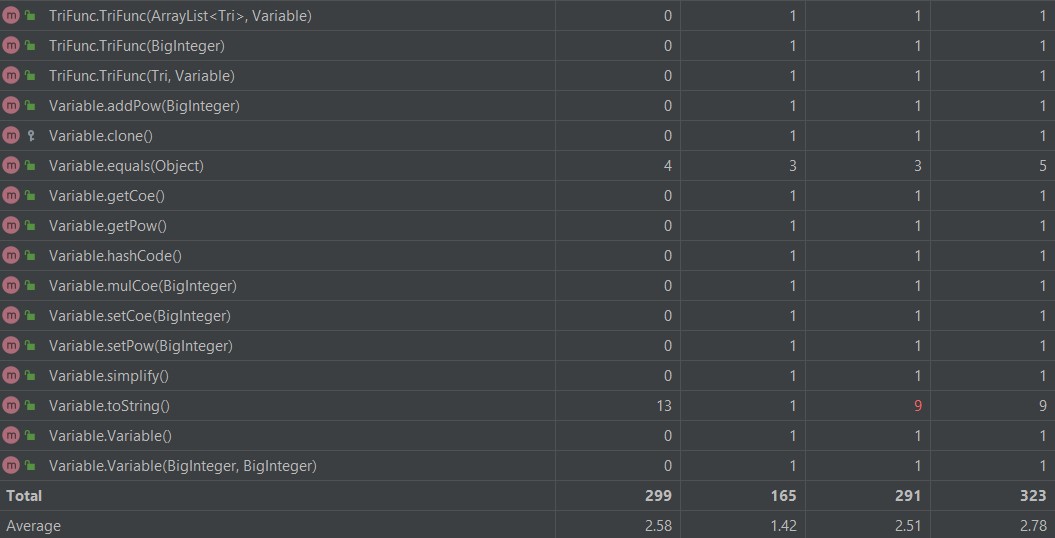
复杂度高的原因都和前两次作业差不多。
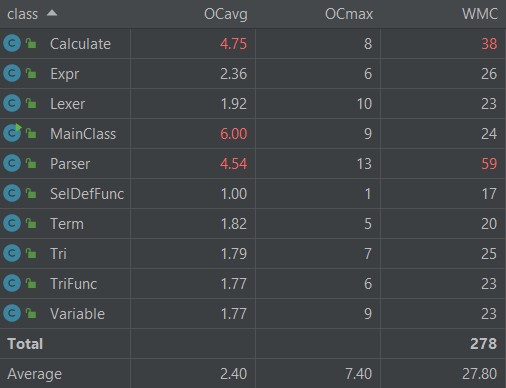
UML类图
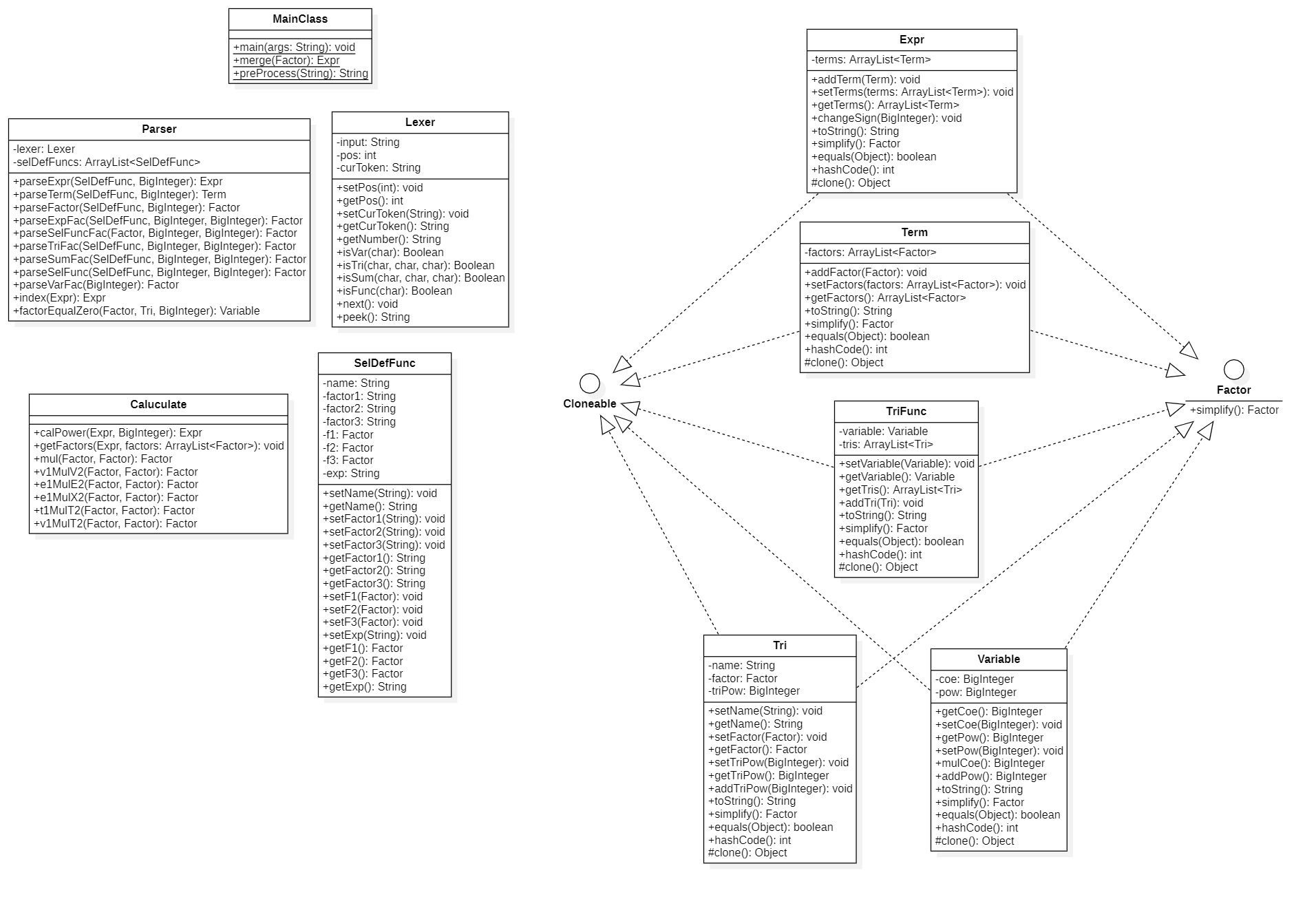
优点
使用了递归下降的方法,更容易实现多层嵌套。
缺点
缺点体现在优化的时候,因为我是得到了最终结果后才合并的,这个坏处在于合并同类项无法做到全面,会有一些地方没有合并到,如sin(x-x)。
自己程序的bug
第一个bug是在求和函数里,sum(i,s,e,t),在处理s>e函数结果为0时,
if (num1.compareTo(num2) > 0) {
while (!lexer.peek().equals(")")) {
lexer.next();
}
lexer.next(); //")"
return new Variable(BigInteger.ZERO, BigInteger.ZERO); //0
}
没有考虑到sum(i,3,2,(x+2))这种情况。
第二个bug是SelDefFunc类存储自定义函数调用的因子时是用set方法,所以在f(x**3,f(0,1))这种情况下,外层f函数的第一个因子会被内层f函数的第一个因子盖掉,第二个因子也一样。
这三次作业中出现bug的方法的圈复杂度在3-7之间,我觉得是能够接受的范围,只是测试做的太少了,导致了一些低级bug的出现。我认为可以在添加某些功能后,就对该功能进行测试,比如我第一次作业删除前导零的bug,第二次作业优化sin(0)的bug,第三次作业处理sum(i,s,e,t),s>e时的bug,可以减少一些低级bug的出现。
发现别人程序bug所采用的策略
第一次作业之后,大家的代码量都挺大的,所以要耐心看完一个人写的代码有点难。
所以我是手动写几个特殊的数据,比如边界,cos(0),指数为0,sum(i,s,e,t),s>e的情况等等,围绕着这个方向去写测试数据,似乎总能hack到几个。也可以根据大家的输出结果来决定要写什么测试数据,比如第三次作业中,我发现好几个人是没有做优化的,那么就可以省略对优化进行测试的数据。
我是觉得写功能性的测试数据比较难hack到人,因为大家都是通过好几个强测点的人,所以在功能性这方面应该不会有太大的问题,但是也会写一两个测试功能性的数据来确保。
心得体会
- 感觉到了测试的重要性,还是得学会写一写数据生成器和自动评测机,说实话自己手搓了几个测试数据后就深感疲惫了。
- 了解了初步架构的重要性,在第二次作业中也得跟着第一次作业的想法去设计(竟然不是先思考第一次作业架构的可扩展性再决定要不要跟,差评),如果跟着第一次作业的想法无法设计的话那可能就要重构了,得改好多好多的代码。
- 更了解递归了,这次作业自己也写了几个递归。
- 更了解深拷贝了(因为bug出现在深拷贝上),并从中学会了用clone方法去解决这个问题。
- 在第一次互测环节中,被人找出bug的紧张感后来变成坦然面对了。
总的来说,学到了很多知识,在6系的锻炼下感觉自己成长了好多(○´・д・)ノ,感谢老师,助教和同学们~
第一单元完结 😄 😄 😄
