Redis系列(五)--主从复制
单机环境存在的问题:
1、机器故障,直接凉凉
2、容量瓶颈
3、QPS瓶颈
主从复制
对于可拓展平台来说,复制(replication)是必不可少的。replication可以让其他服务器slave拥有一个不断更新的数据副本,slave可以用
来处理客户端的读请求。
1.1、特点
1、一个master可以有多个slave,slave下层也可以有slave
2、一个slave只能有一个master
3、数据流是单向的,只能从master到slave
1.2、主从复制实现方式
命令方式(异步):
slaveof host port就会将当前Redis数据复制过去,slaveof no one就会断开复制,不会将已复制的数据清除,一个节点被设置成slave,数
据就会被清除
配置方式:
slaveof 127.0.0.1 6379 slave-read-only yes //从节点只能做读操作,如果slave进行写操作,而master是不知道的,无法进行数据同步
对比:
命令配置不需要重启Redis,但是不方便统一管理,一般在第一次使用Redis的时候,就统一配置,重启Redis的可能不多
run_id:
Redis启动就会产生一个run_id作为唯一标识符
[root@iZ2zecuwoxm5hmeaqo33dfZ redis-4.0.2_2]# redis-cli -p 6379 info server | grep run run_id:58f6366dec43291630996fae04bd6face91e894d [root@iZ2zecuwoxm5hmeaqo33dfZ redis-4.0.2_2]# redis-cli -p 6379 info server # Server redis_version:4.0.2 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:f2cb6376684139ef redis_mode:standalone os:Linux 3.10.0-693.2.2.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll atomicvar_api:atomic-builtin gcc_version:4.8.5 process_id:23689 run_id:58f6366dec43291630996fae04bd6face91e894d tcp_port:6379 uptime_in_seconds:10300775 uptime_in_days:119 hz:10 lru_clock:14904472 executable:/usr/local/redis/redis-4.0.2_1/redis-server config_file:/usr/local/redis/redis-4.0.2_1/./redis_6379.conf
run_id发生变动,或者master节点启动,就会发生全量复制
偏移量:
在写数据的时候,偏移量就会发生变化
[root@iZ2zecuwoxm5hmeaqo33dfZ redis-4.0.2_2]# redis-cli -p 6379 info replication # Replication role:master connected_slaves:0 master_replid:ce82c6b4c71e606ccded8486c5f72e2b04be5dea master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
master_repl_offset就是偏移量,只不过我这里没开启master-slave
全量复制
将master之前的数据,和同步过程产生的数据,都会同步到slave
过程:
首先将RDB文件同步给slave,在同步的过程中发生的写命令记录下来,然后对比master和slave的偏移量,将这期间写入的数据也同步到slave,
最终完成全量复制

全量复制开销:
1、bgsave时间
2、RDB文件传输时间
3、从节点数据清空时间
4、从节点加载RDB文件的时间
5、可能存在的AOF重写:load RDB之后,如果AOF开启,就会进行AOF重写保证是最新状态
全量复制存在的问题:
如果master和slave之间发生网络波动,就会丢失数据,在Redis V2.8版本之前,只能再进行一次全量复制,这样开销很大,V2.8版本,出现
部分复制
部分复制V2.8

主从复制常见问题:
1、读写分离:将读流量分摊在slave上
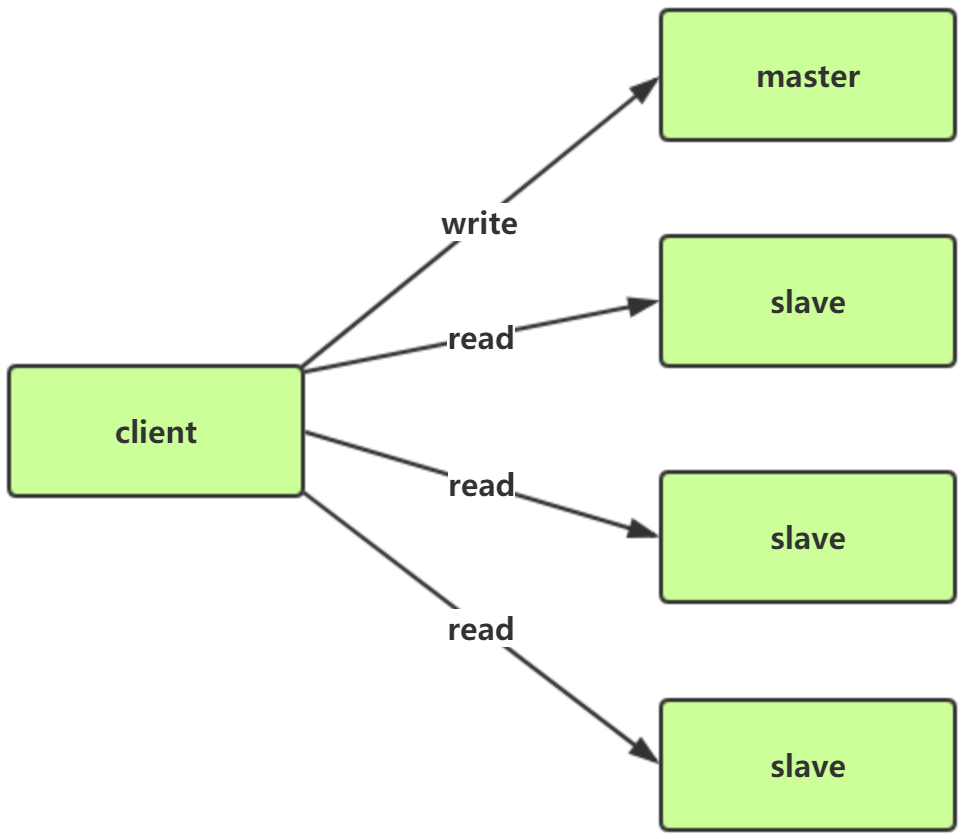
读写分离的问题:
1).复制数据延迟,如果节点发生阻塞,可能出现数据不一致,但是一般不考虑这个
2).读到过期数据,和处理过期数据策略有关
3).slave故障
2、主从配置不一致
master和slave的maxmemory配置不一致,全量复制过大,slave maxmemory不够,就会触发删除规则(优先删除过期数据),就会发生
数据丢失,master发生故障,slave升为master,就会有问题
3、规避全量复制
1).第一次全量复制无法避免,可以使用小分片将maxmemory设置小一点,或者在低峰(夜间)进行处理
2).节点run_id不匹配,master重启,run_id发生改变,可以使用故障转移
3).repl_back_buffer不足,实际上是个队列,通过rel_backlog_size将缓冲区设置大一点,默认1M,可设置10M,以实际需求为准

 浙公网安备 33010602011771号
浙公网安备 33010602011771号