摘要:  继我们使用 Claude Code 训练开源模型的项目之后,现在我们更进一步,将 Codex 引入这一流程。这里的重点不是“Codex 自己开源模型”,而是让 Codex 作为编码代理,参与并自动化开源模型的训练、评估与发布全流程。为此,我们为 Codex 接入了 Hugging Face Skil 阅读全文
继我们使用 Claude Code 训练开源模型的项目之后,现在我们更进一步,将 Codex 引入这一流程。这里的重点不是“Codex 自己开源模型”,而是让 Codex 作为编码代理,参与并自动化开源模型的训练、评估与发布全流程。为此,我们为 Codex 接入了 Hugging Face Skil 阅读全文
继我们使用 Claude Code 训练开源模型的项目之后,现在我们更进一步,将 Codex 引入这一流程。这里的重点不是“Codex 自己开源模型”,而是让 Codex 作为编码代理,参与并自动化开源模型的训练、评估与发布全流程。为此,我们为 Codex 接入了 Hugging Face Skil 阅读全文
posted @ 2025-12-22 16:06
HuggingFace
阅读(158)
评论(0)
推荐(0)
摘要:  在这篇博客文章中,我们介绍了“语音同意验证机制 (voice consent gate)”的概念,支持通过明确同意来进行语音克隆。我们还提供了一个 示例 Space 应用 和 相关代码,帮助大家快速上手这一想法。 近年来,逼真的语音生成技术已经达到了令人惊讶的水平。在某些情况下,生成出来的合成语音几 阅读全文
在这篇博客文章中,我们介绍了“语音同意验证机制 (voice consent gate)”的概念,支持通过明确同意来进行语音克隆。我们还提供了一个 示例 Space 应用 和 相关代码,帮助大家快速上手这一想法。 近年来,逼真的语音生成技术已经达到了令人惊讶的水平。在某些情况下,生成出来的合成语音几 阅读全文
在这篇博客文章中,我们介绍了“语音同意验证机制 (voice consent gate)”的概念,支持通过明确同意来进行语音克隆。我们还提供了一个 示例 Space 应用 和 相关代码,帮助大家快速上手这一想法。 近年来,逼真的语音生成技术已经达到了令人惊讶的水平。在某些情况下,生成出来的合成语音几 阅读全文
posted @ 2025-12-22 15:58
HuggingFace
阅读(86)
评论(0)
推荐(0)
摘要:  快速了解(TLDR) 现在只需一行代码,就能通过 load_dataset('dataset', streaming=True) 以流式方式加载数据集,无需下载! 无需复杂配置、不占磁盘空间、不再担心 “磁盘已满” 或 429 请求过多错误,立即开始训练 TB 级数据集! 性能非常强劲:在 64×H 阅读全文
快速了解(TLDR) 现在只需一行代码,就能通过 load_dataset('dataset', streaming=True) 以流式方式加载数据集,无需下载! 无需复杂配置、不占磁盘空间、不再担心 “磁盘已满” 或 429 请求过多错误,立即开始训练 TB 级数据集! 性能非常强劲:在 64×H 阅读全文
快速了解(TLDR) 现在只需一行代码,就能通过 load_dataset('dataset', streaming=True) 以流式方式加载数据集,无需下载! 无需复杂配置、不占磁盘空间、不再担心 “磁盘已满” 或 429 请求过多错误,立即开始训练 TB 级数据集! 性能非常强劲:在 64×H 阅读全文
posted @ 2025-12-22 15:17
HuggingFace
阅读(1024)
评论(0)
推荐(0)
 简要总结: 经过五年的持续开发,huggingface_hub 发布 v1.0 正式版!这一里程碑标志着这个库的成熟与稳定。它已成为 Python 生态中支撑 20 万个依赖库 的核心组件,并提供访问超过 200 万公开模型、50 万公开数据集 和 100 万 Space 应用 的基础能力。本次更新
简要总结: 经过五年的持续开发,huggingface_hub 发布 v1.0 正式版!这一里程碑标志着这个库的成熟与稳定。它已成为 Python 生态中支撑 20 万个依赖库 的核心组件,并提供访问超过 200 万公开模型、50 万公开数据集 和 100 万 Space 应用 的基础能力。本次更新  在飞速变化的研究世界中,紧跟最新进展至关重要。为帮助开发者与研究人员把握 人工智能 前沿动态,我们推出了 Daily Papers 页面。自上线以来,Daily Papers 已收录超过 1 万 篇由 AK 与社区研究者精选的高质量论文。 不过,许多朋友可能还没有充分体验 Daily Papers
在飞速变化的研究世界中,紧跟最新进展至关重要。为帮助开发者与研究人员把握 人工智能 前沿动态,我们推出了 Daily Papers 页面。自上线以来,Daily Papers 已收录超过 1 万 篇由 AK 与社区研究者精选的高质量论文。 不过,许多朋友可能还没有充分体验 Daily Papers 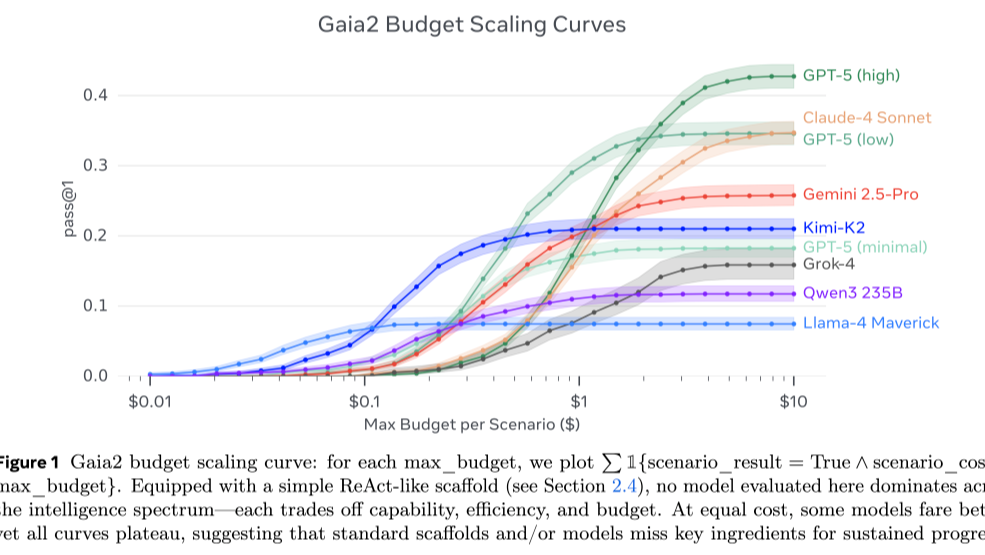 在理想情况下,AI 智能体应当是可靠的助手。当接收到任务时,它们能够轻松处理指令中的歧义,构建逐步执行的计划,正确识别所需资源,按计划执行而不被干扰,并在突发事件中灵活适应,同时保持准确性,避免幻觉。 然而,开发智能体并测试这些行为并非易事:如果你曾尝试过调试自己的智能体,可能会体会到其中的繁琐和挫
在理想情况下,AI 智能体应当是可靠的助手。当接收到任务时,它们能够轻松处理指令中的歧义,构建逐步执行的计划,正确识别所需资源,按计划执行而不被干扰,并在突发事件中灵活适应,同时保持准确性,避免幻觉。 然而,开发智能体并测试这些行为并非易事:如果你曾尝试过调试自己的智能体,可能会体会到其中的繁琐和挫  浙公网安备 33010602011771号
浙公网安备 33010602011771号