
小白一个,今天第一次写博客,主要是开始接触kafka的工作,最近读了coordinator模块,阅读的是开源版本0.10.2.1,废话不多说,直接上菜吧。
本文主要介绍coordinator的基本作用以及相关rebalance的具体过程(由于是源码走读,篇幅会有些长,需要耐心,哈哈)。首先从概念上简单认识下相关的关键字:
1. consumer group:
- Consumer Group用group.id(String)作为全局唯一标识符
- 每个Group可以有零个、一个或多个Consumer Client
- 每个Group可以管理零个、一个或多个Topic
- Group下每个Consumer Client可同时订阅Topic的一个或多个Partition
- Group下同一个Partition只能被一个Client订阅,多Group下的Client订阅不受影响;因为如果一个Partition有多个Consumer,那么每个Consumer在该Partition上的Offset很可能会不一致,这样会导致在Rebalance后赋值处理的Client的消费起点发生混乱;与此同时,这种场景也不符合Kafka中Partition消息消费的一致性;因此在同一Group下一个Partition只能对应一个Consumer Client。
2. rebalance:
它本质上是一种协议,规定了一个 Consumer Group 下的所有 consumer 如何达成一致,来分配订阅 Topic 的每个分区。例如:某 Group 下有 20 个 consumer 实例,它订阅了一个具有 100 个 partition 的 Topic 。正常情况下,kafka 会为每个 Consumer 平均的分配 5 个分区。这个分配的过程就是 Rebalance。
需要注意的是,rebalance过程中group内的所有consumer会停止消费,非常影响kafka的消费性能,所以需要尽量避免rebalance的发生。
rebalance是本文的重点:先引用gaoyanliang的博客中的图,比较生动贴切,首先是join和sync过程:
1、Join 顾名思义就是加入组。这一步中,所有成员都向coordinator发送JoinGroup请求,请求加入消费组。一旦所有成员都发送了JoinGroup请求,coordinator会从中选择一个consumer担任leader的角色,并把组成员信息以及订阅信息发给leader
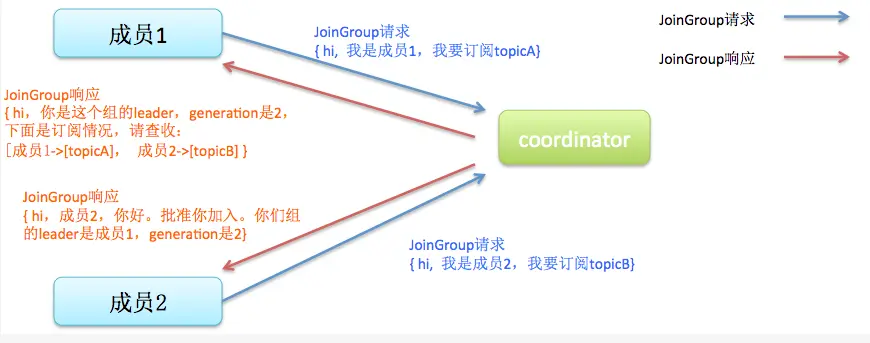
2、Sync,这一步leader开始分配消费方案,即哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer。这样组内的所有成员就都知道自己应该消费哪些分区了。

然后是rebalance的场景分析:
1、新成员加入组
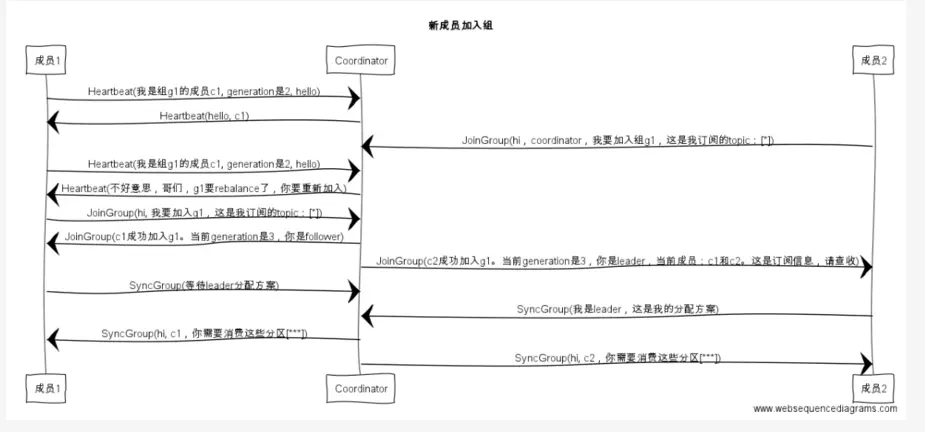
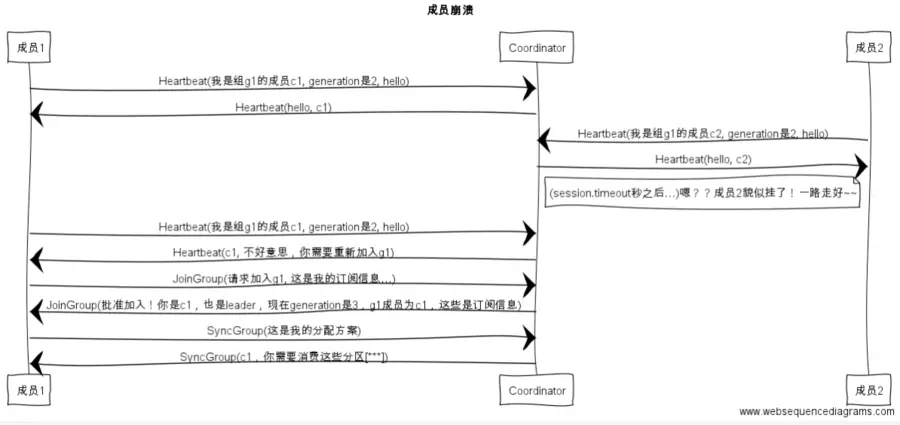
2、组成员崩溃
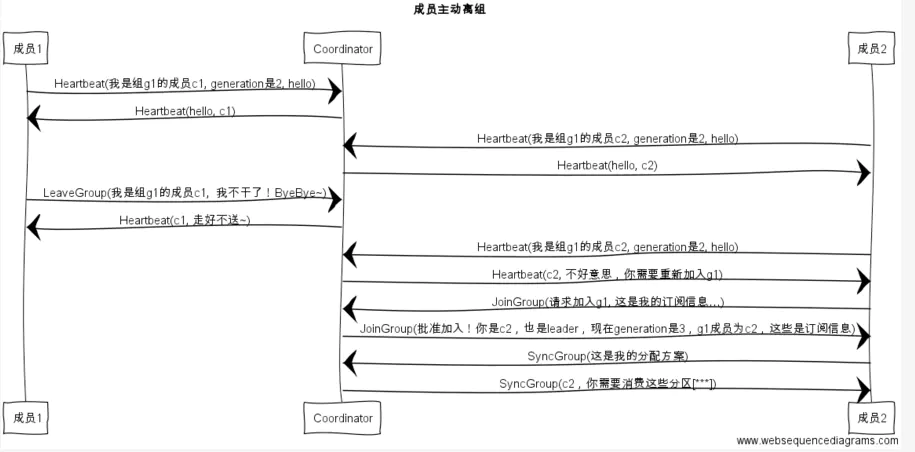
3、组成员主动离开组
4、提交offset(这个不是引发rebalance的条件,可以看看这种场景下的流程分析)
其中,还包括group订阅的topic发生变化;以及订阅的partition数发生变化(例如扩容),这些都会触发rebalance。以上就是发生rebalance的场景,图示非常生动形象,为了进一步细致的理解,就需要看代码的具体实现了。
3. 代码走读
coordinator服务主要分为client端和server端两部分,接下来我们直接上代码吧。


1 /** 2 * Do one round of polling. In addition to checking for new data, this does any needed offset commits 3 * (if auto-commit is enabled), and offset resets (if an offset reset policy is defined). 4 * @param timeout The maximum time to block in the underlying call to {@link ConsumerNetworkClient#poll(long)}. 5 * @return The fetched records (may be empty) 6 */ 7 private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) { 8 coordinator.poll(time.milliseconds()); 9 10 // fetch positions if we have partitions we're subscribed to that we 11 // don't know the offset for 12 if (!subscriptions.hasAllFetchPositions()) 13 updateFetchPositions(this.subscriptions.missingFetchPositions()); 14 15 // if data is available already, return it immediately 16 Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); 17 if (!records.isEmpty()) 18 return records; 19 20 // send any new fetches (won't resend pending fetches) 21 fetcher.sendFetches(); 22 23 long now = time.milliseconds(); 24 long pollTimeout = Math.min(coordinator.timeToNextPoll(now), timeout); 25 26 client.poll(pollTimeout, now, new PollCondition() { 27 @Override 28 public boolean shouldBlock() { 29 // since a fetch might be completed by the background thread, we need this poll condition 30 // to ensure that we do not block unnecessarily in poll() 31 return !fetcher.hasCompletedFetches(); 32 } 33 }); 34 35 // after the long poll, we should check whether the group needs to rebalance 36 // prior to returning data so that the group can stabilize faster 37 if (coordinator.needRejoin()) 38 return Collections.emptyMap(); 39 40 return fetcher.fetchedRecords(); 41 }
可以看到consumer在fetch数据之前首先调用了coordinator.poll(time.milliseconds()),这个就是coordinator的开始,进去看看做了什么吧。
1 /** 2 * Poll for coordinator events. This ensures that the coordinator is known and that the consumer 3 * has joined the group (if it is using group management). This also handles periodic(定期的) offset commits 4 * if they are enabled. 5 * 6 * @param now current time in milliseconds 7 */ 8 public void poll(long now) { 9 // 先完成已提交offset的回调 10 invokeCompletedOffsetCommitCallbacks(); 11 12 if (subscriptions.partitionsAutoAssigned() && coordinatorUnknown()) { 13 // 自动分配partition模式要首先找到对应的coordinator,并建立连接 14 ensureCoordinatorReady(); 15 now = time.milliseconds(); 16 } 17 18 // 首先判断是否有需要rejoin group的情况发生,如果订阅的 partition 变化或则分配的 partition 变化时,需要 rejoin 19 if (needRejoin()) { 20 // due to a race condition between the initial metadata fetch and the initial rebalance, 21 // we need to ensure that the metadata is fresh before joining initially. This ensures 22 // that we have matched the pattern against the cluster's topics at least once before joining. 23 // rejoin group 之前先刷新一下 metadata(对于 AUTO_PATTERN 而言) 24 if (subscriptions.hasPatternSubscription()) 25 client.ensureFreshMetadata(); 26 27 // 确保 group 是 active; 加入 group; 分配订阅的 partition 28 ensureActiveGroup(); 29 now = time.milliseconds(); 30 } 31 32 // consumer poll心跳一次,用来记录两次poll之间的间隔 33 pollHeartbeat(now); 34 // ensureActiveGroup中成功结束时定了auto commit offset的时间,接下来完成commit offset 35 maybeAutoCommitOffsetsAsync(now); 36 }
从我的中文注释可以看到,首先完成已提交offset的回调,如果是自动分配partition的模式(注意,只有auto mode才需要接下来的coordinator服务以及needRejoin过程)要首先找到对应的coordinator,并建立连接。然后判断当前consumer是否有需要rejoin group,如果需要,确保 group 是 active,然后重新加入 group,分配得到订阅的partitions。然后consumer poll心跳一次,用来记录两次poll之间的间隔(为什么需要这个间隔,接下来再看,先记作mark1),最后由于在ensureActiveGroup中成功结束时定了auto commit offset的时间,到点完成commit offset。
首先是完成已提交offset的回调:
1 void invokeCompletedOffsetCommitCallbacks() { 2 while (true) { 3 OffsetCommitCompletion completion = completedOffsetCommits.poll(); 4 if (completion == null) 5 break; 6 completion.invoke(); 7 } 8 }
进入invokeCompletedOffsetCommitCallbacks可以看到,是从一个线程安全的队列completedOffsetCommits中不断出队完成成功commit offset的回调,回调具体干了什么事,接下来看,记作mark2。
然后是确保coordinator服务处于ready状态:
1 /** 2 * Block until the coordinator for this group is known and is ready to receive requests. 3 */ 4 public synchronized void ensureCoordinatorReady() { 5 // Using zero as current time since timeout is effectively infinite 6 ensureCoordinatorReady(0, Long.MAX_VALUE); 7 }
1 /** 2 * Ensure that the coordinator is ready to receive requests. 3 * @param startTimeMs Current time in milliseconds 4 * @param timeoutMs Maximum time to wait to discover the coordinator 5 * @return true If coordinator discovery and initial connection succeeded, false otherwise 6 */ 7 protected synchronized boolean ensureCoordinatorReady(long startTimeMs, long timeoutMs) { 8 long remainingMs = timeoutMs; 9 10 while (coordinatorUnknown()) { 11 // 找到coordinator 12 RequestFuture<Void> future = lookupCoordinator(); 13 client.poll(future, remainingMs); 14 15 if (future.failed()) { 16 if (future.isRetriable()) { 17 remainingMs = timeoutMs - (time.milliseconds() - startTimeMs); 18 if (remainingMs <= 0) 19 break; 20 21 log.debug("Coordinator discovery failed for group {}, refreshing metadata", groupId); 22 client.awaitMetadataUpdate(remainingMs); 23 } else 24 throw future.exception(); 25 } else if (coordinator != null && client.connectionFailed(coordinator)) { 26 // we found the coordinator, but the connection has failed, so mark 27 // it dead and backoff before retrying discovery 28 coordinatorDead(); 29 time.sleep(retryBackoffMs); 30 } 31 32 remainingMs = timeoutMs - (time.milliseconds() - startTimeMs); 33 if (remainingMs <= 0) 34 break; 35 } 36 37 return !coordinatorUnknown(); 38 }
进去看到就是要确保找到该consumer group对应的coordinator服务,否则会一直block住,其中最主要的部分就是lookupCoordinator(),进去看看怎么找的。
1 protected synchronized RequestFuture<Void> lookupCoordinator() { 2 if (findCoordinatorFuture == null) { 3 // find a node to ask about the coordinator 4 // 找负载最低的机器 5 Node node = this.client.leastLoadedNode(); 6 if (node == null) { 7 // TODO: If there are no brokers left, perhaps we should use the bootstrap set 8 // from configuration? 9 log.debug("No broker available to send GroupCoordinator request for group {}", groupId); 10 return RequestFuture.noBrokersAvailable(); 11 } else 12 // 给找到的机器发送获取该group的coordinator的request,回调成功赋给coordinator 13 findCoordinatorFuture = sendGroupCoordinatorRequest(node); 14 } 15 return findCoordinatorFuture; 16 }
1 /** 2 * Discover the current coordinator for the group. Sends a GroupMetadata request to 3 * one of the brokers. The returned future should be polled to get the result of the request. 4 * @return A request future which indicates the completion of the metadata request 5 */ 6 private RequestFuture<Void> sendGroupCoordinatorRequest(Node node) { 7 // initiate the group metadata request 8 log.debug("Sending GroupCoordinator request for group {} to broker {}", groupId, node); 9 GroupCoordinatorRequest.Builder requestBuilder = 10 new GroupCoordinatorRequest.Builder(this.groupId); 11 return client.send(node, requestBuilder) 12 .compose(new GroupCoordinatorResponseHandler()); 13 }
可以看出,为了尽可能小的影响kafka的线上服务,它会先找一台负载最小的机器,然后在上面根据groupId给server端发送找该group coordinator的请求,我们去server端看看具体是怎么处理的。
1 def handleGroupCoordinatorRequest(request: RequestChannel.Request) { 2 val groupCoordinatorRequest = request.body.asInstanceOf[GroupCoordinatorRequest] 3 4 if (!authorize(request.session, Describe, new Resource(Group, groupCoordinatorRequest.groupId))) { 5 val responseBody = new GroupCoordinatorResponse(Errors.GROUP_AUTHORIZATION_FAILED.code, Node.noNode) 6 requestChannel.sendResponse(new RequestChannel.Response(request, responseBody)) 7 } else { 8 // 根绝groupId找到对应的coordinator所在的partitionId 9 val partition = coordinator.partitionFor(groupCoordinatorRequest.groupId) 10 11 // get metadata (and create the topic if necessary) 12 val offsetsTopicMetadata = getOrCreateGroupMetadataTopic(request.listenerName) 13 14 val responseBody = if (offsetsTopicMetadata.error != Errors.NONE) { 15 new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode) 16 } else { 17 18 // 根据找到的partitionId找到其leader所在的broker,该broker就是该group的coordinator所在的节点 19 val coordinatorEndpoint = offsetsTopicMetadata.partitionMetadata().asScala 20 .find(_.partition == partition) 21 .map(_.leader()) 22 23 coordinatorEndpoint match { 24 case Some(endpoint) if !endpoint.isEmpty => 25 new GroupCoordinatorResponse(Errors.NONE.code, endpoint) 26 case _ => 27 new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode) 28 } 29 } 30 31 debug("Sending consumer metadata %s for correlation id %d to client %s connectionId=%s ." 32 .format(responseBody, request.header.correlationId, request.header.clientId, request.connectionId)) 33 requestChannel.sendResponse(new RequestChannel.Response(request, responseBody)) 34 } 35 }
它首先根绝groupId找到对应的coordinator所在的partitionId,然后根据找到的partitionId找到其leader所在的broker,该broker就是该group的coordinator所在的节点,那么「groupId找到对应的coordinator所在的partitionId」这一步是怎么算出来的呢?看代码:
def partitionFor(groupId: String): Int = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
原来是根据groupId的hashcode对「__consumer_offsets」这个topic的partition数求模,至于「__consumer_offsets」这个特殊的topic可以自行了解,不是本文的重点。然后server将GroupCoordinatorRequest的处理结果返回给client端,视线回到sendGroupCoordinatorRequest里,看看对返回结果怎么处理的:
1 private class GroupCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> { 2 3 @Override 4 public void onSuccess(ClientResponse resp, RequestFuture<Void> future) { 5 log.debug("Received GroupCoordinator response {} for group {}", resp, groupId); 6 7 GroupCoordinatorResponse groupCoordinatorResponse = (GroupCoordinatorResponse) resp.responseBody(); 8 // use MAX_VALUE - node.id as the coordinator id to mimic separate connections 9 // for the coordinator in the underlying network client layer 10 // TODO: this needs to be better handled in KAFKA-1935 11 Errors error = Errors.forCode(groupCoordinatorResponse.errorCode()); 12 clearFindCoordinatorFuture(); 13 if (error == Errors.NONE) { 14 synchronized (AbstractCoordinator.this) { 15 AbstractCoordinator.this.coordinator = new Node( 16 Integer.MAX_VALUE - groupCoordinatorResponse.node().id(), 17 groupCoordinatorResponse.node().host(), 18 groupCoordinatorResponse.node().port()); 19 log.info("Discovered coordinator {} for group {}.", coordinator, groupId); 20 client.tryConnect(coordinator); 21 heartbeat.resetTimeouts(time.milliseconds()); 22 } 23 future.complete(null); 24 } else if (error == Errors.GROUP_AUTHORIZATION_FAILED) { 25 future.raise(new GroupAuthorizationException(groupId)); 26 } else { 27 log.debug("Group coordinator lookup for group {} failed: {}", groupId, error.message()); 28 future.raise(error); 29 } 30 } 31 32 @Override 33 public void onFailure(RuntimeException e, RequestFuture<Void> future) { 34 clearFindCoordinatorFuture(); 35 super.onFailure(e, future); 36 } 37 }
可以看到client端拿到coordinator所在的机器信息,然后consumer network client去连接该机器,然后client端记录最近与server端连接session的时间。
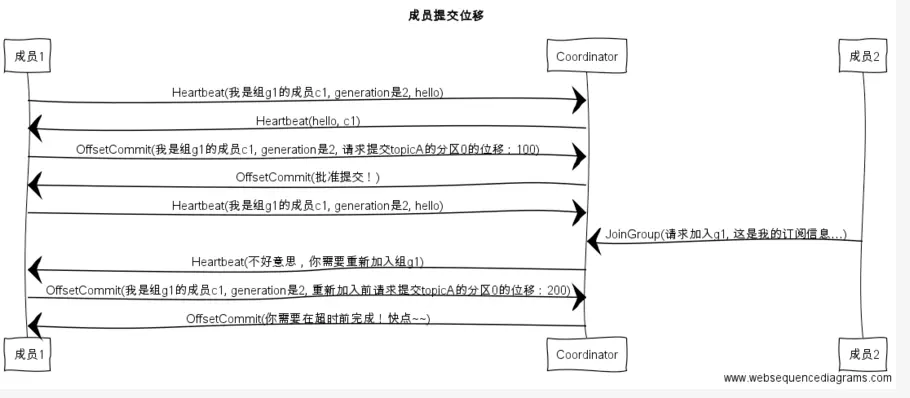
rebalance过程
然后视线回到coordinator poll里,前两步走完了,该判断是否rejoin group了。
1 public boolean needRejoin() { 2 if (!subscriptions.partitionsAutoAssigned()) 3 return false; 4 5 // we need to rejoin if we performed the assignment and metadata has changed 6 if (assignmentSnapshot != null && !assignmentSnapshot.equals(metadataSnapshot)) 7 return true; 8 9 // we need to join if our subscription has changed since the last join 10 if (joinedSubscription != null && !joinedSubscription.equals(subscriptions.subscription())) 11 return true; 12 13 return super.needRejoin(); 14 }
可以看出,只有auto assign模式的才可能需要,如果订阅的topic list发生变化、订阅的topic的partition发生变化,就需要rejoin,也就是要进行rebalance过程,其实还有个条件会触发,就是当group里有新的consumer加入或者有consumer主动退出或挂掉,这种情况接下来会遇到,暂定mark3吧。
如果需要rejoin,对于 AUTO_PATTERN 而言,需要先刷新一下metadata,然后就进入最重要的ensureActiveGroup(),它会确保group是active,然后完成rebalance过程中的两个重点:rejoin和sync,接下来重点介绍。
1 /** 2 * Ensure that the group is active (i.e. joined and synced) 3 */ 4 public void ensureActiveGroup() { 5 // always ensure that the coordinator is ready because we may have been disconnected 6 // when sending heartbeats and does not necessarily require us to rejoin the group. 7 log.warn("starting ensureActiveGroup with coordinator {} for group {}", coordinator, groupId); 8 long tsEnsureCoordinatorReady = System.currentTimeMillis(); 9 ensureCoordinatorReady(); 10 long tsStartHeartbeatThreadIfNeeded = System.currentTimeMillis(); 11 log.warn("ensureActiveGroup#ensureCoordinatorReady cost: {} with coordinator {} for group {}", 12 tsStartHeartbeatThreadIfNeeded - tsEnsureCoordinatorReady, coordinator, groupId); 13 startHeartbeatThreadIfNeeded(); 14 long tsJoinGroupIfNeeded = System.currentTimeMillis(); 15 log.warn("ensureActiveGroup#startHeartbeatThreadIfNeeded cost: {} with coordinator {} for group {}", 16 tsJoinGroupIfNeeded - tsStartHeartbeatThreadIfNeeded, coordinator, groupId); 17 joinGroupIfNeeded(); 18 log.warn("ensureActiveGroup#joinGroupIfNeeded cost: {} with coordinator {} for group {}", 19 System.currentTimeMillis() - tsJoinGroupIfNeeded, coordinator, groupId); 20 log.warn("finish ensureActiveGroup with coordinator {} for group {}", coordinator, groupId); 21 }
可以看到之前还是需要确认coordinator已经处于ready状态,如果心跳线程没有起来则先起一个心跳线程,然后就进行join group的过程了。
1 void joinGroupIfNeeded() { 2 long ts = System.currentTimeMillis(); 3 int loops = 0; 4 while (needRejoin() || rejoinIncomplete()) { 5 loops++; 6 ensureCoordinatorReady(); 7 8 // call onJoinPrepare if needed. We set a flag to make sure that we do not call it a second 9 // time if the client is woken up before a pending rebalance completes. This must be called 10 // on each iteration of the loop because an event requiring a rebalance (such as a metadata 11 // refresh which changes the matched subscription set) can occur while another rebalance is 12 // still in progress. 13 if (needsJoinPrepare) { 14 long tsOnJoinPrepare = System.currentTimeMillis(); 15 onJoinPrepare(generation.generationId, generation.memberId); 16 log.warn("onJoinPrepare cost: {} with coordinator {} for group {}", 17 System.currentTimeMillis() - tsOnJoinPrepare, coordinator, groupId); 18 needsJoinPrepare = false; 19 } 20 21 22 // join group,future.value是分配结果,完成从client端发送join group请求到收到server端发来的assignment 23 RequestFuture<ByteBuffer> future = initiateJoinGroup(); 24 long tsPoll = System.currentTimeMillis(); 25 client.poll(future); 26 log.warn("client.poll cost: {} with coordinator {} for group {}", 27 System.currentTimeMillis() - tsPoll, coordinator, groupId); 28 resetJoinGroupFuture(); 29 30 if (future.succeeded()) { 31 needsJoinPrepare = true; 32 long tsOnJoinComplete = System.currentTimeMillis(); 33 // 更新metadata,并设定下次auto commit offset的时间 34 onJoinComplete(generation.generationId, generation.memberId, generation.protocol, future.value()); 35 log.warn("onJoinComplete cost: {} with coordinator {} for group {}", 36 System.currentTimeMillis() - tsOnJoinComplete, coordinator, groupId); 37 } else { 38 RuntimeException exception = future.exception(); 39 if (exception instanceof UnknownMemberIdException || 40 exception instanceof RebalanceInProgressException || 41 exception instanceof IllegalGenerationException) { 42 log.warn("generation.memberId={} UnknownMemberIdException={} " 43 + "RebalanceInProgressException={} " 44 + "IllegalGenerationException={} with coordinator {} for group {}", 45 generation.memberId, exception instanceof UnknownMemberIdException, 46 exception instanceof RebalanceInProgressException, 47 exception instanceof IllegalGenerationException, coordinator, groupId); 48 continue; 49 } else if (!future.isRetriable()) 50 throw exception; 51 time.sleep(retryBackoffMs); 52 } 53 } 54 log.warn("joinGroupIfNeeded cost: {}, loops: {}, with coordinator {} for group {}" 55 , System.currentTimeMillis() - ts, loops, coordinator, groupId); 56 }
看了下,还是需要确认coordinator已经处于ready状态,然后要经过一次join之前的准备过程,进去JoinPrepare(generation.generationId, generation.memberId)里,看看在join之前做什么准备工作(擦屁股)?
1 protected void onJoinPrepare(int generation, String memberId) { // join之前先同步commit offset 2 // commit offsets prior to rebalance if auto-commit enabled 3 // 发送给server端commit offset 4 maybeAutoCommitOffsetsSync(rebalanceTimeoutMs); 5 6 // execute the user's callback before rebalance 7 ConsumerRebalanceListener listener = subscriptions.listener(); 8 log.info("Revoking(吊销) previously assigned partitions {} for group {}", subscriptions.assignedPartitions(), groupId); 9 try { 10 Set<TopicPartition> revoked = new HashSet<>(subscriptions.assignedPartitions()); 11 listener.onPartitionsRevoked(revoked); 12 } catch (WakeupException | InterruptException e) { 13 throw e; 14 } catch (Exception e) { 15 log.error("User provided listener {} for group {} failed on partition revocation", 16 listener.getClass().getName(), groupId, e); 17 } 18 19 // join之前先全部归零,都不是leader,等待server端回复join group中包含谁是leader的信息 20 isLeader = false; 21 subscriptions.resetGroupSubscription(); 22 }
整体来看就是在join之前,要把该consumer之前的offset同步提交了,然后添加listener,用来在别处监听保存join之前的consumer的订阅状态。然后置为非leader(最终是不是group内里的consumer leader,需要稍后分析,记为mark4),最后将group的订阅topic list置为当前consumer订阅的topic list。可以先看下是怎么提交offset的。
1 private void maybeAutoCommitOffsetsSync(long timeoutMs) { 2 if (autoCommitEnabled) { 3 Map<TopicPartition, OffsetAndMetadata> allConsumedOffsets = subscriptions.allConsumed(); 4 try { 5 log.debug("Sending synchronous auto-commit of offsets {} for group {}", allConsumedOffsets, groupId); 6 if (!commitOffsetsSync(allConsumedOffsets, timeoutMs)) // 发送给server端commit offset 7 log.debug("Auto-commit of offsets {} for group {} timed out before completion", 8 allConsumedOffsets, groupId); 9 } catch (WakeupException | InterruptException e) { 10 log.debug("Auto-commit of offsets {} for group {} was interrupted before completion", 11 allConsumedOffsets, groupId); 12 // rethrow wakeups since they are triggered by the user 13 throw e; 14 } catch (Exception e) { 15 // consistent with async auto-commit failures, we do not propagate the exception 16 log.warn("Auto-commit of offsets {} failed for group {}: {}", allConsumedOffsets, groupId, 17 e.getMessage()); 18 } 19 } 20 }
可以看到先取得该consumer消费所有partition的offset,然后发给server端commitOffsetsSync提交,去server端看看是怎么实现commit offset的。
1 public boolean commitOffsetsSync(Map<TopicPartition, OffsetAndMetadata> offsets, long timeoutMs) { 2 invokeCompletedOffsetCommitCallbacks(); 3 4 if (offsets.isEmpty()) 5 return true; 6 7 long now = time.milliseconds(); 8 long startMs = now; 9 long remainingMs = timeoutMs; 10 do { 11 if (coordinatorUnknown()) { 12 if (!ensureCoordinatorReady(now, remainingMs)) 13 return false; 14 15 remainingMs = timeoutMs - (time.milliseconds() - startMs); 16 } 17 18 // 构造OffsetCommitRequest请求,发送给服务端GroupCoordinator 19 RequestFuture<Void> future = sendOffsetCommitRequest(offsets); 20 // 等待请求完成 21 client.poll(future, remainingMs); 22 23 if (future.succeeded()) { 24 if (interceptors != null) 25 interceptors.onCommit(offsets); 26 return true; 27 } 28 29 if (!future.isRetriable()) 30 throw future.exception(); 31 32 time.sleep(retryBackoffMs); 33 34 now = time.milliseconds(); 35 remainingMs = timeoutMs - (now - startMs); 36 } while (remainingMs > 0); 37 38 return false; 39 }
1 /** 2 * Commit offsets for the specified list of topics and partitions. This is a non-blocking call 3 * which returns a request future that can be polled in the case of a synchronous commit or ignored in the 4 * asynchronous case. 5 * 6 * @param offsets The list of offsets per partition that should be committed. 7 * @return A request future whose value indicates whether the commit was successful or not 8 */ 9 private RequestFuture<Void> sendOffsetCommitRequest(final Map<TopicPartition, OffsetAndMetadata> offsets) { 10 if (offsets.isEmpty()) 11 return RequestFuture.voidSuccess(); 12 13 Node coordinator = coordinator(); 14 if (coordinator == null) 15 return RequestFuture.coordinatorNotAvailable(); 16 17 // create the offset commit request 18 Map<TopicPartition, OffsetCommitRequest.PartitionData> offsetData = new HashMap<>(offsets.size()); 19 for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) { 20 OffsetAndMetadata offsetAndMetadata = entry.getValue(); 21 if (offsetAndMetadata.offset() < 0) { 22 return RequestFuture.failure(new IllegalArgumentException("Invalid offset: " + offsetAndMetadata.offset())); 23 } 24 offsetData.put(entry.getKey(), new OffsetCommitRequest.PartitionData( 25 offsetAndMetadata.offset(), offsetAndMetadata.metadata())); 26 } 27 28 final Generation generation; 29 if (subscriptions.partitionsAutoAssigned()) 30 generation = generation(); 31 else 32 generation = Generation.NO_GENERATION; 33 34 // if the generation is null, we are not part of an active group (and we expect to be). 35 // the only thing we can do is fail the commit and let the user rejoin the group in poll() 36 // 不是stable状态,已经脱离group,需重置generation 37 if (generation == null) { 38 log.warn("sendOffsetCommitRequest generation is null. with {} to coordinator {} for group {}", offsets, coordinator, groupId); 39 resetGeneration(); 40 return RequestFuture.failure(new CommitFailedException()); 41 } 42 43 OffsetCommitRequest.Builder builder = 44 new OffsetCommitRequest.Builder(this.groupId, offsetData). 45 setGenerationId(generation.generationId). 46 setMemberId(generation.memberId). 47 setRetentionTime(OffsetCommitRequest.DEFAULT_RETENTION_TIME); 48 49 log.trace("Sending OffsetCommit request with {} to coordinator {} for group {}", offsets, coordinator, groupId); 50 51 return client.send(coordinator, builder) 52 .compose(new OffsetCommitResponseHandler(offsets)); 53 }
1 /** 2 * Handle an offset commit request 3 */ 4 def handleOffsetCommitRequest(request: RequestChannel.Request) { 5 val header = request.header 6 val offsetCommitRequest = request.body.asInstanceOf[OffsetCommitRequest] 7 8 // reject the request if not authorized to the group 9 if (!authorize(request.session, Read, new Resource(Group, offsetCommitRequest.groupId))) { 10 val errorCode = new JShort(Errors.GROUP_AUTHORIZATION_FAILED.code) 11 val results = offsetCommitRequest.offsetData.keySet.asScala.map { topicPartition => 12 (topicPartition, errorCode) 13 }.toMap 14 val response = new OffsetCommitResponse(results.asJava) 15 requestChannel.sendResponse(new RequestChannel.Response(request, response)) 16 } else { 17 val (existingAndAuthorizedForDescribeTopics, nonExistingOrUnauthorizedForDescribeTopics) = offsetCommitRequest.offsetData.asScala.toMap.partition { 18 case (topicPartition, _) => { 19 val authorizedForDescribe = authorize(request.session, Describe, new Resource(auth.Topic, topicPartition.topic)) 20 val exists = metadataCache.contains(topicPartition.topic) 21 if (!authorizedForDescribe && exists) 22 debug(s"Offset commit request with correlation id ${header.correlationId} from client ${header.clientId} " + 23 s"on partition $topicPartition failing due to user not having DESCRIBE authorization, but returning UNKNOWN_TOPIC_OR_PARTITION") 24 authorizedForDescribe && exists 25 } 26 } 27 28 val (authorizedTopics, unauthorizedForReadTopics) = existingAndAuthorizedForDescribeTopics.partition { 29 case (topicPartition, _) => authorize(request.session, Read, new Resource(auth.Topic, topicPartition.topic)) 30 } 31 32 // the callback for sending an offset commit response 33 def sendResponseCallback(commitStatus: immutable.Map[TopicPartition, Short]) { 34 val combinedCommitStatus = commitStatus.mapValues(new JShort(_)) ++ 35 unauthorizedForReadTopics.mapValues(_ => new JShort(Errors.TOPIC_AUTHORIZATION_FAILED.code)) ++ 36 nonExistingOrUnauthorizedForDescribeTopics.mapValues(_ => new JShort(Errors.UNKNOWN_TOPIC_OR_PARTITION.code)) 37 38 if (isDebugEnabled) 39 combinedCommitStatus.foreach { case (topicPartition, errorCode) => 40 if (errorCode != Errors.NONE.code) { 41 debug(s"Offset commit request with correlation id ${header.correlationId} from client ${header.clientId} " + 42 s"on partition $topicPartition failed due to ${Errors.forCode(errorCode).exceptionName}") 43 } 44 } 45 val response = new OffsetCommitResponse(combinedCommitStatus.asJava) 46 requestChannel.sendResponse(new RequestChannel.Response(request, response)) 47 } 48 49 if (authorizedTopics.isEmpty) 50 sendResponseCallback(Map.empty) 51 else if (header.apiVersion == 0) { 52 // for version 0 always store offsets to ZK 53 val responseInfo = authorizedTopics.map { 54 case (topicPartition, partitionData) => 55 val topicDirs = new ZKGroupTopicDirs(offsetCommitRequest.groupId, topicPartition.topic) 56 try { 57 if (partitionData.metadata != null && partitionData.metadata.length > config.offsetMetadataMaxSize) 58 (topicPartition, Errors.OFFSET_METADATA_TOO_LARGE.code) 59 else { 60 zkUtils.updatePersistentPath(s"${topicDirs.consumerOffsetDir}/${topicPartition.partition}", partitionData.offset.toString) 61 (topicPartition, Errors.NONE.code) 62 } 63 } catch { 64 case e: Throwable => (topicPartition, Errors.forException(e).code) 65 } 66 } 67 sendResponseCallback(responseInfo) 68 } else { 69 // for version 1 and beyond store offsets in offset manager 70 71 // compute the retention time based on the request version: 72 // if it is v1 or not specified by user, we can use the default retention 73 val offsetRetention = 74 if (header.apiVersion <= 1 || 75 offsetCommitRequest.retentionTime == OffsetCommitRequest.DEFAULT_RETENTION_TIME) 76 coordinator.offsetConfig.offsetsRetentionMs 77 else 78 offsetCommitRequest.retentionTime 79 80 // commit timestamp is always set to now. 81 // "default" expiration timestamp is now + retention (and retention may be overridden if v2) 82 // expire timestamp is computed differently for v1 and v2. 83 // - If v1 and no explicit commit timestamp is provided we use default expiration timestamp. 84 // - If v1 and explicit commit timestamp is provided we calculate retention from that explicit commit timestamp 85 // - If v2 we use the default expiration timestamp 86 val currentTimestamp = time.milliseconds 87 val defaultExpireTimestamp = offsetRetention + currentTimestamp 88 val partitionData = authorizedTopics.mapValues { partitionData => 89 val metadata = if (partitionData.metadata == null) OffsetMetadata.NoMetadata else partitionData.metadata 90 new OffsetAndMetadata( 91 offsetMetadata = OffsetMetadata(partitionData.offset, metadata), 92 commitTimestamp = currentTimestamp, 93 expireTimestamp = { 94 if (partitionData.timestamp == OffsetCommitRequest.DEFAULT_TIMESTAMP) 95 defaultExpireTimestamp 96 else 97 offsetRetention + partitionData.timestamp 98 } 99 ) 100 } 101 102 // call coordinator to handle commit offset 103 coordinator.handleCommitOffsets( 104 offsetCommitRequest.groupId, 105 offsetCommitRequest.memberId, 106 offsetCommitRequest.generationId, 107 partitionData, 108 sendResponseCallback) 109 } 110 } 111 }
代码很长,在server端的前面部分可以简单的理解为request数据的处理,关键看后面的coordinator.handleCommitOffsets的实现。
1 def handleCommitOffsets(groupId: String, 2 memberId: String, 3 generationId: Int, 4 offsetMetadata: immutable.Map[TopicPartition, OffsetAndMetadata], 5 responseCallback: immutable.Map[TopicPartition, Short] => Unit) { 6 if (!isActive.get) { 7 responseCallback(offsetMetadata.mapValues(_ => Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code)) 8 } else if (!isCoordinatorForGroup(groupId)) { 9 responseCallback(offsetMetadata.mapValues(_ => Errors.NOT_COORDINATOR_FOR_GROUP.code)) 10 } else if (isCoordinatorLoadingInProgress(groupId)) { 11 responseCallback(offsetMetadata.mapValues(_ => Errors.GROUP_LOAD_IN_PROGRESS.code)) 12 } else { 13 groupManager.getGroup(groupId) match { 14 case None => 15 if (generationId < 0) { 16 // the group is not relying on Kafka for group management, so allow the commit 17 val group = groupManager.addGroup(new GroupMetadata(groupId)) 18 doCommitOffsets(group, memberId, generationId, offsetMetadata, responseCallback) 19 } else { 20 // or this is a request coming from an older generation. either way, reject the commit 21 responseCallback(offsetMetadata.mapValues(_ => Errors.ILLEGAL_GENERATION.code)) 22 } 23 24 case Some(group) => 25 doCommitOffsets(group, memberId, generationId, offsetMetadata, responseCallback) 26 } 27 } 28 }
简而言之,就是如果group在server端不存在,groupmanager会创建一个,然后doCommitOffsets真正实现提交。
1 private def doCommitOffsets(group: GroupMetadata, 2 memberId: String, 3 generationId: Int, 4 offsetMetadata: immutable.Map[TopicPartition, OffsetAndMetadata], 5 responseCallback: immutable.Map[TopicPartition, Short] => Unit) { 6 var delayedOffsetStore: Option[DelayedStore] = None 7 8 group synchronized { 9 if (group.is(Dead)) { 10 responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID.code)) 11 } else if (generationId < 0 && group.is(Empty)) { 12 // the group is only using Kafka to store offsets 13 delayedOffsetStore = groupManager.prepareStoreOffsets(group, memberId, generationId, 14 offsetMetadata, responseCallback) 15 } else if (group.is(AwaitingSync)) { 16 responseCallback(offsetMetadata.mapValues(_ => Errors.REBALANCE_IN_PROGRESS.code)) 17 } else if (!group.has(memberId)) { 18 responseCallback(offsetMetadata.mapValues(_ => Errors.UNKNOWN_MEMBER_ID.code)) 19 } else if (generationId != group.generationId) { 20 responseCallback(offsetMetadata.mapValues(_ => Errors.ILLEGAL_GENERATION.code)) 21 } else { 22 val member = group.get(memberId) 23 completeAndScheduleNextHeartbeatExpiration(group, member) 24 delayedOffsetStore = groupManager.prepareStoreOffsets(group, memberId, generationId, 25 offsetMetadata, responseCallback) 26 } 27 } 28 29 // store the offsets without holding the group lock 30 delayedOffsetStore.foreach(groupManager.store) 31 }
主要干了两件事,completeAndScheduleNextHeartbeatExpiration(group, member)和groupManager.prepareStoreOffsets,分别看看具体实现:
1 /** 2 * Complete existing DelayedHeartbeats for the given member and schedule the next one 3 */ 4 private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) { 5 // complete current heartbeat expectation 6 // 先完成这次heartbeat 7 member.latestHeartbeat = time.milliseconds() 8 val memberKey = MemberKey(member.groupId, member.memberId) 9 heartbeatPurgatory.checkAndComplete(memberKey) 10 11 // reschedule the next heartbeat expiration deadline 12 val newHeartbeatDeadline = member.latestHeartbeat + member.sessionTimeoutMs 13 val delayedHeartbeat = new DelayedHeartbeat(this, group, member, newHeartbeatDeadline, member.sessionTimeoutMs) 14 // 尝试完成heartbeat,否则就添加到watcher 15 heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey)) 16 }
可以看到server端先完成了本次心跳,可以理解为这是client端consumer发来commit offset请求,server感知了这件事,收到新的一次心跳,认为发来request的这个consumer还活着。完成本地心跳后,会设置下次consumer发来心跳的deadline时间,并watch这个consumer member。此时,completeAndScheduleNextHeartbeatExpiration这件事干完了,接下来prepareStoreOffsets以及之后的delayedOffsetStore.foreach(groupManager.store)可以理解为将offset值存到metadata topic【__consumer_offsets】中。
然后视线回到join prepare,准备工作完成了,就该进入最最核心的一行代码:RequestFuture<ByteBuffer> future = initiateJoinGroup();在里面,完成了client端请求join group、coordinator server端选leader,leader计算tp分配方案assignment发给coordinator server,server再将assignment发送给group内的所有consumer。来看看具体实现吧:
1 private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() { 2 long ts = System.currentTimeMillis(); 3 // we store the join future in case we are woken up by the user after beginning the 4 // rebalance in the call to poll below. This ensures that we do not mistakenly attempt 5 // to rejoin before the pending rebalance has completed. 6 // 不会在pending的rebalance完成之前错误的再次rejoin 7 if (joinFuture == null) { 8 // fence off the heartbeat thread explicitly so that it cannot interfere with the join group. 9 // Note that this must come after the call to onJoinPrepare since we must be able to continue 10 // sending heartbeats if that callback takes some time. 11 long tsDisableHeartbeatThread = System.currentTimeMillis(); 12 // 加入组的过程停掉心跳 13 disableHeartbeatThread(); 14 log.warn("disableHeartbeatThread cost: {} with coordinator {} for group {}", 15 System.currentTimeMillis() - tsDisableHeartbeatThread, coordinator, groupId); 16 17 state = MemberState.REBALANCING; 18 // 发送join group请求给服务端,中间包括server端回复join,然后leader consumer分配tp,和其它 19 // consumer再往server端发送sync请求,并收到assignment回复 20 joinFuture = sendJoinGroupRequest(); 21 joinFuture.addListener(new RequestFutureListener<ByteBuffer>() { 22 @Override 23 public void onSuccess(ByteBuffer value) { 24 // handle join completion in the callback so that the callback will be invoked 25 // even if the consumer is woken up before finishing the rebalance 26 synchronized (AbstractCoordinator.this) { 27 log.warn("Successfully joined group {} with generation {}", groupId, 28 generation.generationId); 29 state = MemberState.STABLE; 30 AbstractCoordinator.this.rejoinNeeded = false; 31 32 if (heartbeatThread != null) 33 // 加入组成功后再次启动心跳 34 heartbeatThread.enable(); 35 } 36 } 37 38 @Override 39 public void onFailure(RuntimeException e) { 40 // we handle failures below after the request finishes. if the join completes 41 // after having been woken up, the exception is ignored and we will rejoin 42 synchronized (AbstractCoordinator.this) { 43 state = MemberState.UNJOINED; 44 } 45 } 46 }); 47 } 48 log.warn("initiateJoinGroup cost: {} with coordinator {} for group {}", 49 System.currentTimeMillis() - ts, coordinator, groupId); 50 return joinFuture; 51 }
具体做了这几件事:先停掉consumer端的心跳,将client置为rebalancing的状态,然后发送join group请求给服务端,中间包括server端回复join,然后leader consumer分配tp,和其它consumer再往server端发送sync请求,并收到assignment回复,并给这个过程加上监听,成功就将client置为stable状态,启动心跳线程。
好吧,核心还在下一层代码,😓
1 /** 2 * Join the group and return the assignment for the next generation. This function handles both 3 * JoinGroup and SyncGroup, delegating to {@link #performAssignment(String, String, Map)} if 4 * elected leader by the coordinator. 5 * @return A request future which wraps the assignment returned from the group leader 6 */ 7 private RequestFuture<ByteBuffer> sendJoinGroupRequest() { 8 if (coordinatorUnknown()) 9 return RequestFuture.coordinatorNotAvailable(); 10 11 // send a join group request to the coordinator 12 log.info("(Re-)joining group {}", groupId); 13 JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder( 14 groupId, 15 this.sessionTimeoutMs, 16 this.generation.memberId, 17 protocolType(), 18 metadata()).setRebalanceTimeout(this.rebalanceTimeoutMs); 19 20 log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator); 21 long ts = System.currentTimeMillis(); 22 return client.send(coordinator, requestBuilder) 23 .compose(new JoinGroupResponseHandler(ts)); 24 }
1 def handleJoinGroupRequest(request: RequestChannel.Request) { 2 val joinGroupRequest = request.body.asInstanceOf[JoinGroupRequest] 3 4 // the callback for sending a join-group response 5 def sendResponseCallback(joinResult: JoinGroupResult) { 6 val members = joinResult.members map { case (memberId, metadataArray) => (memberId, ByteBuffer.wrap(metadataArray)) } 7 val responseBody = new JoinGroupResponse(request.header.apiVersion, joinResult.errorCode, joinResult.generationId, 8 joinResult.subProtocol, joinResult.memberId, joinResult.leaderId, members.asJava) 9 10 debug("Sending join group response %s for correlation id %d to client %s connectionId=%s ." 11 .format(responseBody, request.header.correlationId, request.header.clientId, request.connectionId)) 12 requestChannel.sendResponse(new RequestChannel.Response(request, responseBody)) 13 } 14 15 // the callback for limit group no response 16 def noOperationCallback(): Unit = { 17 requestChannel.noOperation(request.processor, request) 18 } 19 20 if (!authorize(request.session, Read, new Resource(Group, joinGroupRequest.groupId()))) { 21 val responseBody = new JoinGroupResponse( 22 request.header.apiVersion, 23 Errors.GROUP_AUTHORIZATION_FAILED.code, 24 JoinGroupResponse.UNKNOWN_GENERATION_ID, 25 JoinGroupResponse.UNKNOWN_PROTOCOL, 26 JoinGroupResponse.UNKNOWN_MEMBER_ID, // memberId 27 JoinGroupResponse.UNKNOWN_MEMBER_ID, // leaderId 28 Collections.emptyMap()) 29 requestChannel.sendResponse(new RequestChannel.Response(request, responseBody)) 30 } else { 31 // let the coordinator to handle join-group 32 val protocols = joinGroupRequest.groupProtocols().asScala.map(protocol => 33 (protocol.name, Utils.toArray(protocol.metadata))).toList 34 coordinator.handleJoinGroup( 35 joinGroupRequest.groupId, 36 joinGroupRequest.memberId, 37 request.header.clientId, 38 request.session.clientAddress.toString, 39 joinGroupRequest.rebalanceTimeout, 40 joinGroupRequest.sessionTimeout, 41 joinGroupRequest.protocolType, 42 protocols, 43 sendResponseCallback, 44 noOperationCallback) 45 } 46 }
1 def handleJoinGroup(groupId: String, 2 memberId: String, 3 clientId: String, 4 clientHost: String, 5 rebalanceTimeoutMs: Int, 6 sessionTimeoutMs: Int, 7 protocolType: String, 8 protocols: List[(String, Array[Byte])], 9 responseCallback: JoinCallback, 10 noOperationCallback: NoOpCallback) { 11 if (!groupManager.isGroupBan(groupId)) { 12 13 if (!isActive.get) { 14 responseCallback(joinError(memberId, Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code)) 15 } else if (!validGroupId(groupId)) { 16 responseCallback(joinError(memberId, Errors.INVALID_GROUP_ID.code)) 17 } else if (!isCoordinatorForGroup(groupId)) { 18 responseCallback(joinError(memberId, Errors.NOT_COORDINATOR_FOR_GROUP.code)) 19 } else if (isCoordinatorLoadingInProgress(groupId)) { 20 responseCallback(joinError(memberId, Errors.GROUP_LOAD_IN_PROGRESS.code)) 21 } else if (sessionTimeoutMs < groupConfig.groupMinSessionTimeoutMs || 22 sessionTimeoutMs > groupConfig.groupMaxSessionTimeoutMs) { 23 responseCallback(joinError(memberId, Errors.INVALID_SESSION_TIMEOUT.code)) 24 } else { 25 // only try to create the group if the group is not unknown AND 26 // the member id is UNKNOWN, if member is specified but group does not 27 // exist we should reject the request 28 groupManager.getGroup(groupId) match { 29 case None => 30 if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) { 31 responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code)) 32 } else { 33 val group = groupManager.addGroup(new GroupMetadata(groupId)) 34 doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback) 35 } 36 37 case Some(group) => 38 doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback) 39 } 40 } 41 } else { 42 noOperationCallback() 43 } 44 }
先重点看最后server端怎么处理join group request的吧。同样还是没有group先创建group的元信息,然后do join group:
1 private def doJoinGroup(group: GroupMetadata, 2 memberId: String, 3 clientId: String, 4 clientHost: String, 5 rebalanceTimeoutMs: Int, 6 sessionTimeoutMs: Int, 7 protocolType: String, 8 protocols: List[(String, Array[Byte])], 9 responseCallback: JoinCallback) { 10 group synchronized { 11 if (!group.is(Empty) && (group.protocolType != Some(protocolType) || !group.supportsProtocols(protocols.map(_._1).toSet))) { 12 // if the new member does not support the group protocol, reject it 13 responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL.code)) 14 } else if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID && !group.has(memberId)) { 15 // if the member trying to register with a un-recognized id, send the response to let 16 // it reset its member id and retry 17 responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code)) 18 } else { 19 group.currentState match { 20 case Dead => 21 // if the group is marked as dead, it means some other thread has just removed the group 22 // from the coordinator metadata; this is likely that the group has migrated to some other 23 // coordinator OR the group is in a transient unstable phase. Let the member retry 24 // joining without the specified member id, 25 responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code)) 26 27 case PreparingRebalance => 28 if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { 29 addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback) 30 } else { 31 val member = group.get(memberId) 32 updateMemberAndRebalance(group, member, protocols, responseCallback) 33 } 34 35 case AwaitingSync => 36 if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { 37 addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback) 38 } else { 39 val member = group.get(memberId) 40 if (member.matches(protocols)) { 41 // member is joining with the same metadata (which could be because it failed to 42 // receive the initial JoinGroup response), so just return current group information 43 // for the current generation. 44 responseCallback(JoinGroupResult( 45 members = if (memberId == group.leaderId) { 46 group.currentMemberMetadata 47 } else { 48 Map.empty 49 }, 50 memberId = memberId, 51 generationId = group.generationId, 52 subProtocol = group.protocol, 53 leaderId = group.leaderId, 54 errorCode = Errors.NONE.code)) 55 } else { 56 // member has changed metadata, so force a rebalance 57 group.metrics.memberMetadataChange.mark() 58 updateMemberAndRebalance(group, member, protocols, responseCallback) 59 } 60 } 61 62 case Empty | Stable => { 63 if(group.currentState == Empty){ 64 group.continueMetric() 65 } 66 if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) { 67 // if the member id is unknown, register the member to the group 68 addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback) 69 } else { 70 val member = group.get(memberId) 71 if (memberId == group.leaderId || !member.matches(protocols)) { 72 // force a rebalance if a member has changed metadata or if the leader sends JoinGroup. 73 // The latter allows the leader to trigger rebalances for changes affecting assignment 74 // which do not affect the member metadata (such as topic metadata changes for the consumer) 75 group.metrics.memberMetadataChange.mark() 76 updateMemberAndRebalance(group, member, protocols, responseCallback) 77 } else { 78 // for followers with no actual change to their metadata, just return group information 79 // for the current generation which will allow them to issue SyncGroup 80 responseCallback(JoinGroupResult( 81 members = Map.empty, 82 memberId = memberId, 83 generationId = group.generationId, 84 subProtocol = group.protocol, 85 leaderId = group.leaderId, 86 errorCode = Errors.NONE.code)) 87 } 88 } 89 } 90 } 91 92 if (group.is(PreparingRebalance)) 93 joinPurgatory.checkAndComplete(GroupKey(group.groupId)) 94 } 95 } 96 }
可以看到正如文章开始的server端group的状态机一样,do join group只能在group为empty、preparing rebalancing、awaiting sync状态时做。addMemberAndRebalance和updateMemberAndRebalance几乎一样,以addMemberAndRebalance为例分析一下具体过程:
1 private def addMemberAndRebalance(rebalanceTimeoutMs: Int, 2 sessionTimeoutMs: Int, 3 clientId: String, 4 clientHost: String, 5 protocolType: String, 6 protocols: List[(String, Array[Byte])], 7 group: GroupMetadata, 8 callback: JoinCallback) = { 9 // use the client-id with a random id suffix as the member-id 10 val memberId = clientId + "-" + group.generateMemberIdSuffix 11 val member = new MemberMetadata(memberId, group.groupId, clientId, clientHost, rebalanceTimeoutMs, 12 sessionTimeoutMs, protocolType, protocols) 13 member.awaitingJoinCallback = callback 14 if (groupConfig.configWhiteList.containsKey(group.groupId) || 15 group.allMembers.size <= groupConfig.groupMaxMemberNum) { 16 // 已经选好leader,如果开始group的member是空,第一个member就是leader 17 group.add(member) 18 group.metrics.memberAdd.mark() 19 // 构建好memberid并判断group的member数是否符合要求后,就可以进行rebalance了 20 maybePrepareRebalance(group) 21 } else { 22 // 加入黑名单 23 groupManager.markGroupMemberTooMuch(group.groupId,joinPurgatory) 24 } 25 //这里如果使用了这个返回值则会出现问题。 26 member 27 }
注意看group.add(member)这一行,其实leader consumer的选择策略就在这一行(此处回应mark4),如果group为空,新加入的第一个就是leader,否则,server端的coordinator记忆的还是之前的那个leader,或者如果之前的leader离开group了,coordinator也会很简单的选择剩下consumer中memberId最开头的。这在group.add和group.remove里有实现。然后就是maybePrepareRebalance了,可以进去看看:
1 private def maybePrepareRebalance(group: GroupMetadata) { 2 group synchronized { 3 if (group.canRebalance) 4 prepareRebalance(group) 5 } 6 } 7 8 private def prepareRebalance(group: GroupMetadata) { 9 // if any members are awaiting sync, cancel their request and have them rejoin 10 // preparerebalance之前可能是AwaitingSync、stable、empty,这是AwaitingSync的情况 11 if (group.is(AwaitingSync)) 12 //完成assinment的重置和心跳完成并调度下次 13 resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS) 14 15 group.transitionTo(PreparingRebalance) 16 group.metrics.groupRebalanced.mark() 17 info("Preparing to restabilize group %s with old generation %s".format(group.groupId, group.generationId)) 18 19 val rebalanceTimeout = group.rebalanceTimeoutMs 20 val delayedRebalance = new DelayedJoin(this, group, rebalanceTimeout) 21 val groupKey = GroupKey(group.groupId) 22 // 在rebalanceTimeout之前完成rebalance,并向members发送谁是leader的response 23 joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey)) 24 }
可以看到,如果当前group的state是awaiting syn的状态,现在又有join group,那么consumer们等待同步之前assignment的过程肯定要被中断,所以需要重置下上轮leader算的assignment,并且group内的所有members完成心跳,设定下次心跳时间。然后正式将group的state转为preparing rebalance的状态,最后设定一个delayjoin,它的具体含义就是:如果group内的members都报道了就开始执行join group操作,如果在deadline内还有未报道的member,coordinator会认为这个member死掉了,踢出group,将前来报道的members进行join group操作。具体join group的结果就是谁是leader,给leader发送的就是该group的metadata,非leader发送的就是空包!
很啰嗦?上代码吧!首先看resetAndPropagateAssignmentError的具体实现:
1 private def resetAndPropagateAssignmentError(group: GroupMetadata, error: Errors) { 2 assert(group.is(AwaitingSync)) 3 // 需要rejoin,之前要清空各个member的assignment 4 group.allMemberMetadata.foreach(_.assignment = Array.empty[Byte]) 5 // 发送给client,说明正在处于rebalance中,并完成心跳调度下一次心跳 6 propagateAssignment(group, error) 7 } 8 9 private def propagateAssignment(group: GroupMetadata, error: Errors) { 10 for (member <- group.allMemberMetadata) { 11 if (member.awaitingSyncCallback != null) { 12 // error是none时,发送给client的是assignment 13 member.awaitingSyncCallback(member.assignment, error.code) 14 member.awaitingSyncCallback = null 15 16 // reset the session timeout for members after propagating the member's assignment. 17 // This is because if any member's session expired while we were still awaiting either 18 // the leader sync group or the storage callback, its expiration will be ignored and no 19 // future heartbeat expectations will not be scheduled. 20 completeAndScheduleNextHeartbeatExpiration(group, member) 21 } 22 } 23 }
1 /** 2 * Complete existing DelayedHeartbeats for the given member and schedule the next one 3 */ 4 private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) { 5 // complete current heartbeat expectation 6 // 先完成这次heartbeat 7 member.latestHeartbeat = time.milliseconds() 8 val memberKey = MemberKey(member.groupId, member.memberId) 9 heartbeatPurgatory.checkAndComplete(memberKey) 10 11 // reschedule the next heartbeat expiration deadline 12 val newHeartbeatDeadline = member.latestHeartbeat + member.sessionTimeoutMs 13 val delayedHeartbeat = new DelayedHeartbeat(this, group, member, newHeartbeatDeadline, member.sessionTimeoutMs) 14 // 尝试完成heartbeat,否则就添加到watcher 15 heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey)) 16 }
然后是delay operation的实现,
1 def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean) = { 2 group synchronized { 3 if (group.notYetRejoinedMembers.isEmpty) 4 forceComplete() 5 else false 6 } 7 }
在deadline时间内,会有两次tryCompleteJoin,如果members都已经rejoin了或超时,就会执行forceComplete,里面包含了join的处理细节:
1 def forceComplete(): Boolean = { 2 if (completed.compareAndSet(false, true)) { 3 // cancel the timeout timer 4 cancel() 5 onComplete() 6 true 7 } else { 8 false 9 } 10 }
1 def onCompleteJoin(group: GroupMetadata) { 2 var delayedStore: Option[DelayedStore] = None 3 group synchronized { 4 // remove any members who haven't joined the group yet 5 val notYetRejoinedMembers = group.notYetRejoinedMembers 6 group.metrics.memberNotSendJoinBeforeJoinComplete.mark(notYetRejoinedMembers.size) 7 8 // 对于那些还没rejoin的member,从group中移出 9 notYetRejoinedMembers.foreach { failedMember => 10 group.remove(failedMember.memberId) 11 // TODO: cut the socket connection to the client 12 } 13 14 if (group.notYetRejoinedMembers.nonEmpty) { 15 warn("onCompleteJoin group=" + group.groupId + " notYetRejoinedMembers=" + group.notYetRejoinedMembers.mkString(",")) 16 } 17 18 if (!group.is(Dead)) { 19 // generation加1,根据members有无转换group state到awatingsync或empty 20 group.initNextGeneration() 21 if (group.is(Empty)) { 22 info(s"Group ${group.groupId} with generation ${group.generationId} is now empty") 23 24 delayedStore = groupManager.prepareStoreGroup(group, Map.empty, error => { 25 if (error != Errors.NONE) { 26 // we failed to write the empty group metadata. If the broker fails before another rebalance, 27 // the previous generation written to the log will become active again (and most likely timeout). 28 // This should be safe since there are no active members in an empty generation, so we just warn. 29 warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}") 30 } 31 }) 32 } else { 33 info(s"Stabilized group ${group.groupId}. generation ${group.generationId}. member size ${group.allMembers.size}. group leader info ${group.get(group.leaderId).toString}") 34 35 // trigger the awaiting join group response callback for all the members after rebalancing 36 for (member <- group.allMemberMetadata) { 37 assert(member.awaitingJoinCallback != null) 38 // 给group中的members发送join-group的response 39 val joinResult = JoinGroupResult( 40 members=if (member.memberId == group.leaderId) { group.currentMemberMetadata } else { Map.empty }, 41 memberId=member.memberId, 42 generationId=group.generationId, 43 subProtocol=group.protocol, 44 leaderId=group.leaderId, 45 errorCode=Errors.NONE.code) 46 47 member.awaitingJoinCallback(joinResult) 48 member.awaitingJoinCallback = null 49 // 完成这次心跳并调度下次心跳 50 completeAndScheduleNextHeartbeatExpiration(group, member) 51 } 52 } 53 } 54 } 55 56 // call without holding the group lock 57 delayedStore.foreach(groupManager.store) 58 }
可以看到,会先算出group内有哪些还没join的member,把他们从group内踢出去,更新generation,将leaderId发送给所有members,将group的metadata发送给leader,每个member都会心跳一次,并更新下次心跳时间。
---------------这是join和sync的分界线----------------
至此,server端对于join group的请求处理完毕,client端会有join group response的处理,再回到client端看收到response是怎么处理的?
1 private class JoinGroupResponseHandler extends CoordinatorResponseHandler<JoinGroupResponse, ByteBuffer> { 2 3 private final long tsBegin; 4 5 JoinGroupResponseHandler(long tsBegin) { 6 this.tsBegin = tsBegin; 7 } 8 9 @Override 10 public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) { 11 Errors error = Errors.forCode(joinResponse.errorCode()); 12 if (error == Errors.NONE) { 13 log.debug("Received successful JoinGroup response for group {}: {}", groupId, joinResponse); 14 sensors.joinLatency.record(response.requestLatencyMs()); 15 16 synchronized (AbstractCoordinator.this) { 17 if (state != MemberState.REBALANCING) { 18 // if the consumer was woken up before a rebalance completes, we may have already left 19 // the group. In this case, we do not want to continue with the sync group. 20 future.raise(new UnjoinedGroupException()); 21 } else { 22 AbstractCoordinator.this.generation = new Generation(joinResponse.generationId(), 23 joinResponse.memberId(), joinResponse.groupProtocol()); 24 if (joinResponse.isLeader()) { 25 // leader consumer具体的分配过程,并将assignment发送sync请求给server,server将 26 // assignment再回复回来 27 onJoinLeader(joinResponse).chain(future); 28 } else { 29 // 非leader的consumer包装个空集合发送sync请求给server,server将assignment再回复回来 30 onJoinFollower().chain(future); 31 } 32 log.warn("JoinGroup cost: {} with coordinator {} for group {}", 33 System.currentTimeMillis() - tsBegin, coordinator, groupId); 34 } 35 } 36 } else if (error == Errors.GROUP_LOAD_IN_PROGRESS) { 37 log.warn("Attempt to join group {} rejected since coordinator {} is loading the group.", groupId, 38 coordinator()); 39 // backoff and retry 40 future.raise(error); 41 } else if (error == Errors.UNKNOWN_MEMBER_ID) { 42 // reset the member id and retry immediately 43 resetGeneration(); 44 log.warn("Attempt to join group {} failed due to unknown member id.", groupId); 45 future.raise(Errors.UNKNOWN_MEMBER_ID); 46 } else if (error == Errors.GROUP_COORDINATOR_NOT_AVAILABLE 47 || error == Errors.NOT_COORDINATOR_FOR_GROUP) { 48 // re-discover the coordinator and retry with backoff 49 coordinatorDead(); 50 log.warn("Attempt to join group {} failed due to obsolete coordinator information: {}", groupId, error.message()); 51 future.raise(error); 52 } else if (error == Errors.INCONSISTENT_GROUP_PROTOCOL 53 || error == Errors.INVALID_SESSION_TIMEOUT 54 || error == Errors.INVALID_GROUP_ID) { 55 // log the error and re-throw the exception 56 log.error("Attempt to join group {} failed due to fatal error: {}", groupId, error.message()); 57 future.raise(error); 58 } else if (error == Errors.GROUP_AUTHORIZATION_FAILED) { 59 future.raise(new GroupAuthorizationException(groupId)); 60 } else { 61 // unexpected error, throw the exception 62 future.raise(new KafkaException("Unexpected error in join group response: " + error.message())); 63 } 64 } 65 }
可以看到consumer收到response后会判断自己是不是leader,如果是,它会根据收到的group metadata计算出partition具体怎么分配的(assignment),然后将assignment发送给server端,server端再将这个assignment同步给所有consumer,这样所有consumer就知道自己负责消费哪些partition,如果自己不是leader的话,也同样会给server端发sync请求,只不过是个空请求。
先看下非leader干的什么事:
private RequestFuture<ByteBuffer> onJoinFollower() { // send follower's sync group with an empty assignment SyncGroupRequest.Builder requestBuilder = new SyncGroupRequest.Builder(groupId, generation.generationId, generation.memberId, Collections.<String, ByteBuffer>emptyMap()); log.debug("Sending follower SyncGroup for group {} to coordinator {}: {}", groupId, this.coordinator, requestBuilder); return sendSyncGroupRequest(requestBuilder); }
像上面说的一样,发送个空map给server端,由于leader计算完assignment也会往server端发sync请求,所以这里先不展示sync的处理过程,马上就会解释。
然后就是leader consumer的处理过程:
1 private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) { 2 try { 3 // perform the leader synchronization and send back the assignment for the group 4 // consumer leader执行tp的assignment策略 5 Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.leaderId(), joinResponse.groupProtocol(), 6 joinResponse.members()); 7 8 // 带着assignment发给server端sync请求 9 SyncGroupRequest.Builder requestBuilder = 10 new SyncGroupRequest.Builder(groupId, generation.generationId, generation.memberId, groupAssignment); 11 log.debug("Sending leader SyncGroup for group {} to coordinator {}: {}", 12 groupId, this.coordinator, requestBuilder); 13 // sync请求的回复,包含着assignment 14 return sendSyncGroupRequest(requestBuilder); 15 } catch (RuntimeException e) { 16 return RequestFuture.failure(e); 17 } 18 }
他首先会计算assignment,具体的分配策略有三种:MockPartitionAssignor、RangePartitionAssignor、RoundRobinAssignor,具体可以自己搜索学习下,不是本文的重点。然后就是给server端发sync请求。
1 private RequestFuture<ByteBuffer> sendSyncGroupRequest(SyncGroupRequest.Builder requestBuilder) { 2 if (coordinatorUnknown()) 3 return RequestFuture.coordinatorNotAvailable(); 4 long ts = System.currentTimeMillis(); 5 return client.send(coordinator, requestBuilder) 6 .compose(new SyncGroupResponseHandler(ts)); 7 }
再跳到server端看怎么处理sync请求的吧:
1 def handleSyncGroupRequest(request: RequestChannel.Request) { 2 val syncGroupRequest = request.body.asInstanceOf[SyncGroupRequest] 3 4 def sendResponseCallback(memberState: Array[Byte], errorCode: Short) { 5 val responseBody = new SyncGroupResponse(errorCode, ByteBuffer.wrap(memberState)) 6 debug("Sending sync group response %s for correlation id %d to client %s connectionId=%s ." 7 .format(responseBody, request.header.correlationId, request.header.clientId, request.connectionId)) 8 9 requestChannel.sendResponse(new Response(request, responseBody)) 10 } 11 12 // the callback for limit group no response 13 def noOperationCallback(): Unit = { 14 requestChannel.noOperation(request.processor, request) 15 } 16 17 if (!authorize(request.session, Read, new Resource(Group, syncGroupRequest.groupId()))) { 18 sendResponseCallback(Array[Byte](), Errors.GROUP_AUTHORIZATION_FAILED.code) 19 } else { 20 coordinator.handleSyncGroup( 21 syncGroupRequest.groupId(), 22 syncGroupRequest.generationId(), 23 syncGroupRequest.memberId(), 24 syncGroupRequest.groupAssignment().asScala.mapValues(Utils.toArray), 25 sendResponseCallback, 26 noOperationCallback 27 ) 28 } 29 }
1 def handleSyncGroup(groupId: String, 2 generation: Int, 3 memberId: String, 4 groupAssignment: Map[String, Array[Byte]], 5 responseCallback: SyncCallback, 6 noOperationCallback: NoOpCallback) { 7 if (!groupManager.isGroupBan(groupId)) { 8 9 if (!isActive.get) { 10 responseCallback(Array.empty, Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code) 11 } else if (!isCoordinatorForGroup(groupId)) { 12 responseCallback(Array.empty, Errors.NOT_COORDINATOR_FOR_GROUP.code) 13 } else { 14 groupManager.getGroup(groupId) match { 15 case None => responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code) 16 case Some(group) => doSyncGroup(group, generation, memberId, groupAssignment, responseCallback) 17 } 18 } 19 } else { 20 noOperationCallback() 21 } 22 }
1 private def doSyncGroup(group: GroupMetadata, 2 generationId: Int, 3 memberId: String, 4 groupAssignment: Map[String, Array[Byte]], 5 responseCallback: SyncCallback) { 6 var delayedGroupStore: Option[DelayedStore] = None 7 8 group synchronized { 9 if (!group.has(memberId)) { 10 responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code) 11 } else if (generationId != group.generationId) { 12 responseCallback(Array.empty, Errors.ILLEGAL_GENERATION.code) 13 } else { 14 group.currentState match { 15 case Empty | Dead => 16 responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code) 17 18 case PreparingRebalance => 19 responseCallback(Array.empty, Errors.REBALANCE_IN_PROGRESS.code) 20 21 case AwaitingSync => 22 group.get(memberId).awaitingSyncCallback = responseCallback 23 24 // if this is the leader, then we can attempt to persist state and transition to stable 25 if (memberId == group.leaderId) { 26 info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}") 27 28 // fill any missing members with an empty assignment 29 val missing = group.allMembers -- groupAssignment.keySet 30 val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap 31 32 // 将相关group metadata的信息做成消息形式,在后面会存到__consumer_offset中 33 delayedGroupStore = groupManager.prepareStoreGroup(group, assignment, (error: Errors) => { 34 group synchronized { 35 // another member may have joined the group while we were awaiting this callback, 36 // so we must ensure we are still in the AwaitingSync state and the same generation 37 // when it gets invoked. if we have transitioned to another state, then do nothing 38 // 不是AwaitingSync状态什么也不干 39 if (group.is(AwaitingSync) && generationId == group.generationId) { 40 if (error != Errors.NONE) { 41 // AwaitingSync时如果有其它member进来,要转为preparerebalance 42 resetAndPropagateAssignmentError(group, error) 43 maybePrepareRebalance(group) 44 } else { 45 // 给每个member分配leader计算的assignment,回复给client,并完成心跳,同时调度下次 46 setAndPropagateAssignment(group, assignment) 47 group.transitionTo(Stable) 48 group.latestStableTime.set(System.currentTimeMillis()) 49 } 50 } 51 } 52 }) 53 } 54 55 case Stable => 56 // if the group is stable, we just return the current assignment 57 val memberMetadata = group.get(memberId) 58 // 回复给client,并完成心跳,同时调度下次 59 responseCallback(memberMetadata.assignment, Errors.NONE.code) 60 completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId)) 61 } 62 } 63 } 64 65 // store the group metadata without holding the group lock to avoid the potential 66 // for deadlock if the callback is invoked holding other locks (e.g. the replica 67 // state change lock) 68 delayedGroupStore.foreach(groupManager.store) 69 }
可以直接看server端的处理逻辑:
如果不是leader consumer发来的什么也不做,是leader的话,则将assignment做成消息的形式,在后面会存到__consumer_offset中,在这个过程中,如果有其他member中途进来,就需要再次清空assignment,重新调度心跳线程并prepare rebalance,如果过程顺利执行,就给每个member分配leader计算的assignment,回复给client,将group state转为stable,并心跳一次,同时调度下次心跳时间,这个将assignment回复给client的过程需要具体看下:
1 // 给每个member分配leader计算的assignment,并完成心跳,同时调度下次 2 private def setAndPropagateAssignment(group: GroupMetadata, assignment: Map[String, Array[Byte]]) { 3 assert(group.is(AwaitingSync)) 4 group.allMemberMetadata.foreach(member => member.assignment = assignment(member.memberId)) 5 // 发送给client的是assignment,并完成心跳调度下一次心跳 6 propagateAssignment(group, Errors.NONE) 7 } 8 9 private def propagateAssignment(group: GroupMetadata, error: Errors) { 10 for (member <- group.allMemberMetadata) { 11 if (member.awaitingSyncCallback != null) { 12 member.awaitingSyncCallback(member.assignment, error.code) 13 member.awaitingSyncCallback = null 14 15 // reset the session timeout for members after propagating the member's assignment. 16 // This is because if any member's session expired while we were still awaiting either 17 // the leader sync group or the storage callback, its expiration will be ignored and no 18 // future heartbeat expectations will not be scheduled. 19 completeAndScheduleNextHeartbeatExpiration(group, member) 20 } 21 } 22 }
其中,member.awaitingSyncCallback(member.assignment, error.code)就将每个member对应的assignment回调到client端了,为什么这么说呢?可以在doSyncGroup中找到group.get(memberId).awaitingSyncCallback = responseCallback这行代码,回调方法就是responseCallback,它从何而来呢?向前追溯到server端最开始的地方:
1 def handleSyncGroupRequest(request: RequestChannel.Request) { 2 val syncGroupRequest = request.body.asInstanceOf[SyncGroupRequest] 3 4 def sendResponseCallback(memberState: Array[Byte], errorCode: Short) { 5 val responseBody = new SyncGroupResponse(errorCode, ByteBuffer.wrap(memberState)) 6 debug("Sending sync group response %s for correlation id %d to client %s connectionId=%s ." 7 .format(responseBody, request.header.correlationId, request.header.clientId, request.connectionId)) 8 9 requestChannel.sendResponse(new Response(request, responseBody)) 10 } 11 12 // the callback for limit group no response 13 def noOperationCallback(): Unit = { 14 requestChannel.noOperation(request.processor, request) 15 } 16 17 if (!authorize(request.session, Read, new Resource(Group, syncGroupRequest.groupId()))) { 18 sendResponseCallback(Array[Byte](), Errors.GROUP_AUTHORIZATION_FAILED.code) 19 } else { 20 coordinator.handleSyncGroup( 21 syncGroupRequest.groupId(), 22 syncGroupRequest.generationId(), 23 syncGroupRequest.memberId(), 24 syncGroupRequest.groupAssignment().asScala.mapValues(Utils.toArray), 25 sendResponseCallback, 26 noOperationCallback 27 ) 28 } 29 }
就是这个sendResponseCallback,它会将member state,也就是该member的assignment装进去,作为response返回给client。那么client收到该response怎么做呢?视线再拉回到client端初始发送sync request的地方吧:
1 private RequestFuture<ByteBuffer> sendSyncGroupRequest(SyncGroupRequest.Builder requestBuilder) { 2 if (coordinatorUnknown()) 3 return RequestFuture.coordinatorNotAvailable(); 4 long ts = System.currentTimeMillis(); 5 return client.send(coordinator, requestBuilder) 6 .compose(new SyncGroupResponseHandler(ts)); 7 } 8 9 private class SyncGroupResponseHandler extends CoordinatorResponseHandler<SyncGroupResponse, ByteBuffer> { 10 11 private final long tsBegin; 12 13 SyncGroupResponseHandler(long tsBegin) { 14 this.tsBegin = tsBegin; 15 } 16 17 @Override 18 public void handle(SyncGroupResponse syncResponse, 19 RequestFuture<ByteBuffer> future) { 20 Errors error = Errors.forCode(syncResponse.errorCode()); 21 if (error == Errors.NONE) { 22 sensors.syncLatency.record(response.requestLatencyMs()); 23 future.complete(syncResponse.memberAssignment()); 24 log.warn("SyncGroup cost: {} with coordinator {} for group {}", 25 System.currentTimeMillis() - tsBegin, coordinator, groupId); 26 } else { 27 requestRejoin(); 28 29 if (error == Errors.GROUP_AUTHORIZATION_FAILED) { 30 future.raise(new GroupAuthorizationException(groupId)); 31 } else if (error == Errors.REBALANCE_IN_PROGRESS) { 32 log.warn("SyncGroup for group {} failed due to coordinator rebalance", groupId); 33 future.raise(error); 34 } else if (error == Errors.UNKNOWN_MEMBER_ID 35 || error == Errors.ILLEGAL_GENERATION) { 36 log.warn("SyncGroup for group {} failed due to {}", groupId, error); 37 resetGeneration(); 38 future.raise(error); 39 } else if (error == Errors.GROUP_COORDINATOR_NOT_AVAILABLE 40 || error == Errors.NOT_COORDINATOR_FOR_GROUP) { 41 log.warn("SyncGroup for group {} failed due to {}", groupId, error); 42 coordinatorDead(); 43 future.raise(error); 44 } else { 45 future.raise(new KafkaException("Unexpected error from SyncGroup: " + error.message())); 46 } 47 } 48 } 49 }
一行代码:future.complete(syncResponse.memberAssignment()),表明这个future以该consumer的assignment的值返回的,再向上回溯到joinGroupIfNeeded:
1 void joinGroupIfNeeded() { 2 long ts = System.currentTimeMillis(); 3 int loops = 0; 4 while (needRejoin() || rejoinIncomplete()) { 5 loops++; 6 ensureCoordinatorReady(); 7 8 // call onJoinPrepare if needed. We set a flag to make sure that we do not call it a second 9 // time if the client is woken up before a pending rebalance completes. This must be called 10 // on each iteration of the loop because an event requiring a rebalance (such as a metadata 11 // refresh which changes the matched subscription set) can occur while another rebalance is 12 // still in progress. 13 if (needsJoinPrepare) { 14 long tsOnJoinPrepare = System.currentTimeMillis(); 15 onJoinPrepare(generation.generationId, generation.memberId); 16 log.warn("onJoinPrepare cost: {} with coordinator {} for group {}", 17 System.currentTimeMillis() - tsOnJoinPrepare, coordinator, groupId); 18 needsJoinPrepare = false; 19 } 20 21 22 // join group,future.value是分配结果,完成从client端发送join group请求到收到server端发来的assignment 23 RequestFuture<ByteBuffer> future = initiateJoinGroup(); 24 long tsPoll = System.currentTimeMillis(); 25 client.poll(future); 26 log.warn("client.poll cost: {} with coordinator {} for group {}", 27 System.currentTimeMillis() - tsPoll, coordinator, groupId); 28 resetJoinGroupFuture(); 29 30 if (future.succeeded()) { 31 needsJoinPrepare = true; 32 long tsOnJoinComplete = System.currentTimeMillis(); 33 // 更新metadata,并设定下次auto commit offset的时间 34 onJoinComplete(generation.generationId, generation.memberId, generation.protocol, future.value()); 35 log.warn("onJoinComplete cost: {} with coordinator {} for group {}", 36 System.currentTimeMillis() - tsOnJoinComplete, coordinator, groupId); 37 } else { 38 RuntimeException exception = future.exception(); 39 if (exception instanceof UnknownMemberIdException || 40 exception instanceof RebalanceInProgressException || 41 exception instanceof IllegalGenerationException) { 42 log.warn("generation.memberId={} UnknownMemberIdException={} " 43 + "RebalanceInProgressException={} " 44 + "IllegalGenerationException={} with coordinator {} for group {}", 45 generation.memberId, exception instanceof UnknownMemberIdException, 46 exception instanceof RebalanceInProgressException, 47 exception instanceof IllegalGenerationException, coordinator, groupId); 48 continue; 49 } else if (!future.isRetriable()) 50 throw exception; 51 time.sleep(retryBackoffMs); 52 } 53 } 54 log.warn("joinGroupIfNeeded cost: {}, loops: {}, with coordinator {} for group {}" 55 , System.currentTimeMillis() - ts, loops, coordinator, groupId); 56 }
onJoinComplete这个方法用到了future.value的值,也就是consumer的assignment值,进去看下干什么了:
1 protected void onJoinComplete(int generation, 2 String memberId, 3 String assignmentStrategy, 4 ByteBuffer assignmentBuffer) { 5 // only the leader is responsible for monitoring for metadata changes (i.e. partition changes) 6 if (!isLeader) { 7 log.warn("onJoinComplete is follower, generation=" + generation + " memberId=" + memberId + " group=" + groupId); 8 assignmentSnapshot = null; 9 } else { 10 log.warn("onJoinComplete is leader, generation=" + generation + " memberId=" + memberId + " group=" + groupId); 11 } 12 13 PartitionAssignor assignor = lookupAssignor(assignmentStrategy); 14 if (assignor == null) 15 throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy); 16 17 Assignment assignment = ConsumerProtocol.deserializeAssignment(assignmentBuffer); 18 19 // set the flag to refresh last committed offsets 20 // 允许从服务端获取最近一次提交的offset 21 subscriptions.needRefreshCommits(); 22 23 // update partition assignment 24 subscriptions.assignFromSubscribed(assignment.partitions()); 25 26 // check if the assignment contains some topics that were not in the original 27 // subscription, if yes we will obey what leader has decided and add these topics 28 // into the subscriptions as long as they still match the subscribed pattern 29 // 30 // TODO this part of the logic should be removed once we allow regex on leader assign 31 // 分配到tp中有新的topic,需要加到subscriptions里 32 Set<String> addedTopics = new HashSet<>(); 33 for (TopicPartition tp : subscriptions.assignedPartitions()) { 34 if (!joinedSubscription.contains(tp.topic())) 35 addedTopics.add(tp.topic()); 36 } 37 38 if (!addedTopics.isEmpty()) { 39 Set<String> newSubscription = new HashSet<>(subscriptions.subscription()); 40 Set<String> newJoinedSubscription = new HashSet<>(joinedSubscription); 41 newSubscription.addAll(addedTopics); 42 newJoinedSubscription.addAll(addedTopics); 43 44 this.subscriptions.subscribeFromPattern(newSubscription); 45 this.joinedSubscription = newJoinedSubscription; 46 } 47 48 // update the metadata and enforce a refresh to make sure the fetcher can start 49 // fetching data in the next iteration 50 // 更新metadata 51 this.metadata.setTopics(subscriptions.groupSubscription()); 52 client.ensureFreshMetadata(); 53 54 // give the assignor a chance to update internal state based on the received assignment 55 assignor.onAssignment(assignment); 56 57 // reschedule the auto commit starting from now 58 this.nextAutoCommitDeadline = time.milliseconds() + autoCommitIntervalMs; 59 60 // execute the user's callback after rebalance 61 ConsumerRebalanceListener listener = subscriptions.listener(); 62 log.info("Setting newly assigned partitions {} for group {}", subscriptions.assignedPartitions(), groupId); 63 try { 64 Set<TopicPartition> assigned = new HashSet<>(subscriptions.assignedPartitions()); 65 listener.onPartitionsAssigned(assigned); 66 } catch (WakeupException | InterruptException e) { 67 throw e; 68 } catch (Exception e) { 69 log.error("User provided listener {} for group {} failed on partition assignment", 70 listener.getClass().getName(), groupId, e); 71 } 72 }
可以看出,用assignment更新了consumer的subscriptions,同时可能订阅了新的topic,还更新了该consumer订阅的topic list,client端更新metadata值,重新计算下次auto commit offset。至此,needJoin的逻辑全部执行完毕,回到poll中,还剩下两步:
1 public void poll(long now) { 2 // 先完成已提交offset的回调 3 invokeCompletedOffsetCommitCallbacks(); 4 5 if (subscriptions.partitionsAutoAssigned() && coordinatorUnknown()) { 6 // 自动分配partition模式要首先找到对应的coordinator,并建立连接 7 ensureCoordinatorReady(); 8 now = time.milliseconds(); 9 } 10 11 // 首先判断是否有需要rejoin group的情况发生,如果订阅的 partition 变化或则分配的 partition 变化时,需要 rejoin 12 if (needRejoin()) { 13 // due to a race condition between the initial metadata fetch and the initial rebalance, 14 // we need to ensure that the metadata is fresh before joining initially. This ensures 15 // that we have matched the pattern against the cluster's topics at least once before joining. 16 // rejoin group 之前先刷新一下 metadata(对于 AUTO_PATTERN 而言) 17 if (subscriptions.hasPatternSubscription()) 18 client.ensureFreshMetadata(); 19 20 // 确保 group 是 active; 加入 group; 分配订阅的 partition 21 ensureActiveGroup(); 22 now = time.milliseconds(); 23 } 24 25 // consumer poll心跳一次,用来记录两次poll之间的间隔 26 pollHeartbeat(now); 27 // ensureActiveGroup中成功结束时定了auto commit offset的时间,接下来完成commit offset 28 maybeAutoCommitOffsetsAsync(now); 29 }
consumer 需要poll心跳一次,用来记录两次poll之间的间隔,这个还是mark1的问题,马上回应。然后就是由于在ensureActiveGroup中成功结束时定了auto commit offset的时间,接下来完成commit offset,具体看下怎么commit的:
1 private void maybeAutoCommitOffsetsAsync(long now) { 2 if (autoCommitEnabled) { 3 if (!subscriptions.partitionsAutoAssigned()) { 4 if (now >= nextAutoCommitDeadline) { 5 this.nextAutoCommitDeadline = now + autoCommitIntervalMs; 6 doAutoCommitOffsetsAsync(); 7 } 8 } else { 9 if (coordinatorUnknown()) { 10 this.nextAutoCommitDeadline = now + retryBackoffMs; 11 } else if (now >= nextAutoCommitDeadline) { 12 this.nextAutoCommitDeadline = now + autoCommitIntervalMs; 13 doAutoCommitOffsetsAsync(); 14 } 15 } 16 } 17 } 18 19 private void doAutoCommitOffsetsAsync() { 20 Map<TopicPartition, OffsetAndMetadata> allConsumedOffsets = subscriptions.allConsumed(); 21 log.debug("Sending asynchronous auto-commit of offsets {} for group {}", allConsumedOffsets, groupId); 22 23 commitOffsetsAsync(allConsumedOffsets, new OffsetCommitCallback() { 24 @Override 25 public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { 26 if (exception != null) { 27 log.warn("Auto-commit of offsets {} failed for group {}: {}, isLeader:{}", 28 offsets, groupId, isLeader, exception.getMessage()); 29 if (exception instanceof RetriableException) 30 nextAutoCommitDeadline = Math.min(time.milliseconds() + retryBackoffMs, nextAutoCommitDeadline); 31 } else { 32 log.debug("Completed auto-commit of offsets {} for group {}", offsets, groupId); 33 } 34 } 35 }); 36 } 37 38 public void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) { 39 // 所有tp commit offset完成回调 40 invokeCompletedOffsetCommitCallbacks(); 41 42 if (!coordinatorUnknown()) { 43 doCommitOffsetsAsync(offsets, callback); 44 } else { 45 // we don't know the current coordinator, so try to find it and then send the commit 46 // or fail (we don't want recursive retries which can cause offset commits to arrive 47 // out of order). Note that there may be multiple offset commits chained to the same 48 // coordinator lookup request. This is fine because the listeners will be invoked in 49 // the same order that they were added. Note also that AbstractCoordinator prevents 50 // multiple concurrent coordinator lookup requests. 51 // 一个coordinator可能会处理多个commit offset,按顺序处理 52 pendingAsyncCommits.incrementAndGet(); 53 lookupCoordinator().addListener(new RequestFutureListener<Void>() { 54 @Override 55 public void onSuccess(Void value) { 56 pendingAsyncCommits.decrementAndGet(); 57 doCommitOffsetsAsync(offsets, callback); 58 } 59 60 @Override 61 public void onFailure(RuntimeException e) { 62 pendingAsyncCommits.decrementAndGet(); 63 completedOffsetCommits.add(new OffsetCommitCompletion(callback, offsets, new RetriableCommitFailedException(e))); 64 } 65 }); 66 } 67 68 // ensure the commit has a chance to be transmitted (without blocking on its completion). 69 // Note that commits are treated as heartbeats by the coordinator, so there is no need to 70 // explicitly allow heartbeats through delayed task execution. 71 client.pollNoWakeup(); 72 }
可以在最后看到,这是个异步提交的过程,一个coordinator可能会处理多个commit offset,按顺序处理,具体的提交细节还是回到了doCommitOffsetsAsync,这个在上面提到过,在看一下:
1 private void doCommitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) { 2 this.subscriptions.needRefreshCommits(); 3 // 发送给server请求commit offset 4 RequestFuture<Void> future = sendOffsetCommitRequest(offsets); 5 final OffsetCommitCallback cb = callback == null ? defaultOffsetCommitCallback : callback; 6 // 成功/失败的回调 7 future.addListener(new RequestFutureListener<Void>() { 8 @Override 9 public void onSuccess(Void value) { 10 if (interceptors != null) 11 interceptors.onCommit(offsets); 12 13 completedOffsetCommits.add(new OffsetCommitCompletion(cb, offsets, null)); 14 } 15 16 @Override 17 public void onFailure(RuntimeException e) { 18 Exception commitException = e; 19 20 if (e instanceof RetriableException) 21 commitException = new RetriableCommitFailedException(e); 22 23 completedOffsetCommits.add(new OffsetCommitCompletion(cb, offsets, commitException)); 24 } 25 }); 26 }
还是会向Server端发提交offset的请求,最后将回调方法包装为一个OffsetCommitCompletion放到completedOffsetCommits里。回调方法的实现具体就是doAutoCommitOffsetsAsync里的new OffsetCommitCallback()的实现,看到了这里,completedOffsetCommits是不是很熟悉,它呼应了mark2。
最后再关注一下client端的heartbeat的run方法:
1 public void run() { 2 try { 3 log.debug("Heartbeat thread for group {} started", groupId); 4 while (true) { 5 synchronized (AbstractCoordinator.this) { 6 if (closed) 7 return; 8 9 if (!enabled) { 10 AbstractCoordinator.this.wait(); 11 continue; 12 } 13 14 if (state != MemberState.STABLE) { 15 // the group is not stable (perhaps because we left the group or because the coordinator 16 // kicked us out), so disable heartbeats and wait for the main thread to rejoin. 17 disable(); 18 continue; 19 } 20 21 client.pollNoWakeup(); 22 long now = time.milliseconds(); 23 24 if (coordinatorUnknown()) { 25 if (findCoordinatorFuture == null) 26 lookupCoordinator(); 27 else 28 AbstractCoordinator.this.wait(retryBackoffMs); 29 } else if (heartbeat.sessionTimeoutExpired(now)) { 30 // the session timeout has expired without seeing a successful heartbeat, so we should 31 // probably make sure the coordinator is still healthy. 32 // server端coordinator超时没有返回心跳 33 log.warn("(heartbeat.sessionTimeout,generation={}, groupId={}",generation,groupId); 34 coordinatorDead(); 35 } else if (heartbeat.pollTimeoutExpired(now)) { // consumer在poll间隔内超时没有poll了,估计leave group了 36 // the poll timeout has expired, which means that the foreground thread has stalled 37 // in between calls to poll(), so we explicitly leave the group. 38 log.warn("(heartbeat.pollTimeout,generation={}, groupId={}",generation,groupId); 39 maybeLeaveGroup(); 40 } else if (!heartbeat.shouldHeartbeat(now)) { 41 // poll again after waiting for the retry backoff in case the heartbeat failed or the 42 // coordinator disconnected 43 AbstractCoordinator.this.wait(retryBackoffMs); 44 } else { 45 heartbeat.sentHeartbeat(now); 46 47 // 向server端发心跳请求 48 sendHeartbeatRequest().addListener(new RequestFutureListener<Void>() { 49 @Override 50 public void onSuccess(Void value) { 51 synchronized (AbstractCoordinator.this) { 52 // server端收到心跳并回复 53 heartbeat.receiveHeartbeat(time.milliseconds()); 54 } 55 } 56 57 @Override 58 public void onFailure(RuntimeException e) { 59 synchronized (AbstractCoordinator.this) { 60 if (e instanceof RebalanceInProgressException) { 61 // it is valid to continue heartbeating while the group is rebalancing. This 62 // ensures that the coordinator keeps the member in the group for as long 63 // as the duration of the rebalance timeout. If we stop sending heartbeats, 64 // however, then the session timeout may expire before we can rejoin. 65 heartbeat.receiveHeartbeat(time.milliseconds()); 66 } else { 67 heartbeat.failHeartbeat(); 68 69 // wake up the thread if it's sleeping to reschedule the heartbeat 70 AbstractCoordinator.this.notify(); 71 } 72 } 73 } 74 }); 75 } 76 } 77 } 78 } catch (InterruptedException | InterruptException e) { 79 Thread.interrupted(); 80 log.error("Unexpected interrupt received in heartbeat thread for group {}", groupId, e); 81 this.failed.set(new RuntimeException(e)); 82 } catch (RuntimeException e) { 83 log.error("Heartbeat thread for group {} failed due to unexpected error" , groupId, e); 84 this.failed.set(e); 85 } finally { 86 log.debug("Heartbeat thread for group {} has closed", groupId); 87 } 88 } 89 90 }
可以看到heartbeat.sessionTimeoutExpired(now),这个表示的是现在距离上次与server端的coordinator的session连接时间,也就是coordinator返回心跳超时了,会认为coordinator挂掉,导致之后又需要lookup coordinator。而heartbeat.pollTimeoutExpired(now)呼应了mark1,如果client端两次poll心跳超时,coordinator会认为该consumer离开group了,做leave group的处理,同理由client端向server端发送leave group request,server端仍然做一个rebalance处理,这就呼应了mark3,正常情况下,client端心跳一次,并向server端发送心跳请求,server端做心跳处理,如果在心跳超时范围内,则成功返回给client端一个心跳。
作者写篇博客不容易,觉得有用的话赏点小钱请作者喝杯可乐吧:

