
102302109_胡贝贝_综合实践
1、筛选并评估适用于菜谱管理、食材推荐的开源项目,加速开发进程
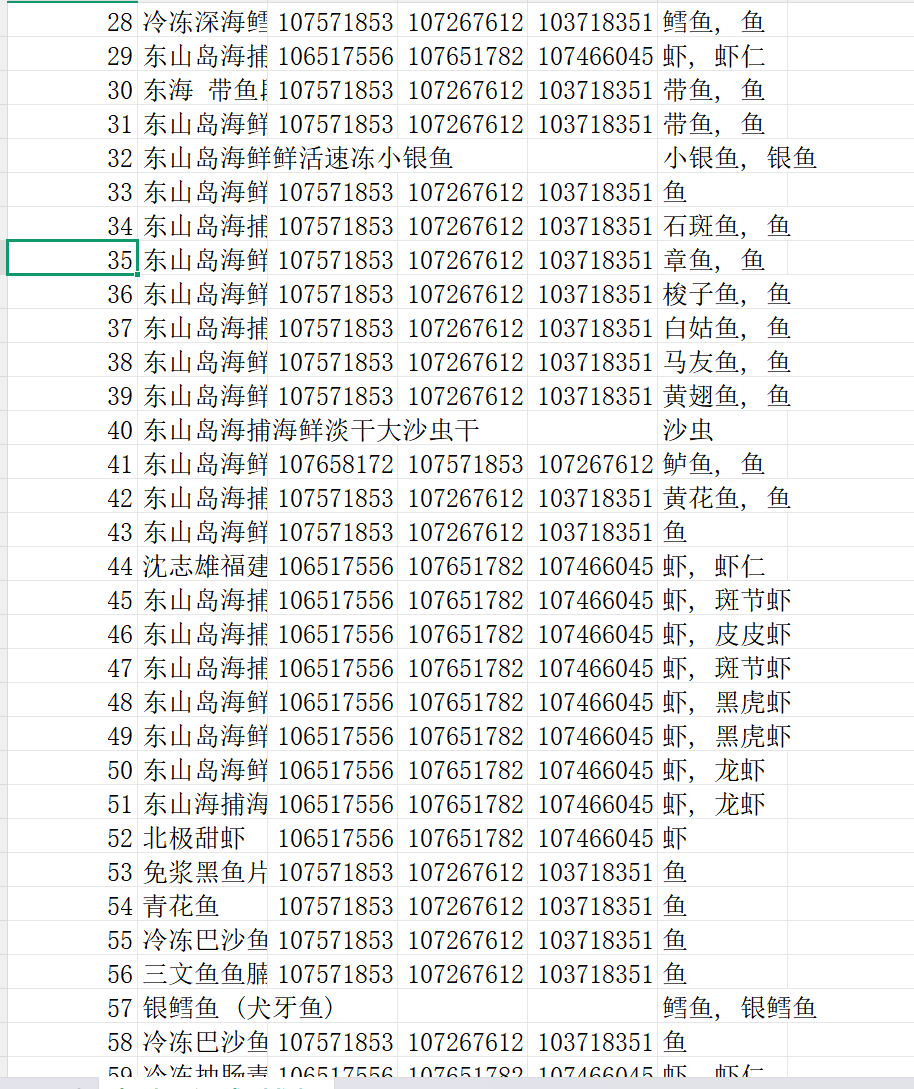
2、系统化收集、清洗并关联食材与菜谱数据,创建可查询、可扩展的结构化“食材-菜谱”数据库,确保每个食材对应3个优质菜谱,让后续推荐菜谱更简单高效。

点击查看代码
import os
import re
import time
import zipfile
import pandas as pd
from io import BytesIO
from collections import defaultdict
# -------------------- 配置 --------------------
DEFAULT_DATA_DIR_NAME = "food_recipe_data"
FOOD_FILENAME = "商品最终.xlsx"
RECIPE_FILES = ["大鱼大肉.csv", "家常菜.csv", "下饭菜.csv", "素菜.csv", "快手菜.csv"]
OUTPUT_FILE = "food_recipe_final_links.csv"
# -------------------- 品牌排除列表 --------------------
BRAND_EXCLUSIONS = ['金龙鱼', '鲁花', '福临门', '中粮', '海天', '李锦记', '厨邦', '老干妈', '香飚王', '苏鲜生']
# -------------------- 零食类食品识别规则 --------------------
SNACK_KEYWORDS = [
# 饼干类
'饼干', '苏打饼干', '曲奇', '威化', '梅尼耶',
# 薯片类
'薯片', '薯条', '呀土豆', '可比克', '乐事',
# 虾条类
'虾条', '虾片',
# 瓜子类
'瓜子', '香瓜子', '南瓜子', '葵花籽',
# 坚果类
'坚果', '松子', '杏仁', '腰果', '巴旦木', '每日坚果', '混合坚果',
# 糖果类
'糖果', '奶糖', '水果糖', '软糖', '硬糖', '大白兔', '酥糖', '米花酥', '花生酥', '芝麻酥', '核桃酥',
# 巧克力类
'巧克力', '巧克力味', '榛子巧克力',
# 糕点类
'糕点', '蛋糕', '面包', '月饼', '派', '蛋黄派', '铜锣烧', '瑞士卷', '软面包', '菠萝包',
# 肉脯类
'猪肉脯', '肉脯', '牛肉脯',
# 蛋类零食
'卤蛋', '盐焗鸡蛋', '即食蛋',
# 米饼类
'米饼', '雪饼', '仙贝',
# 其他零食
'魔芋爽', '素毛肚',
# 通用零食
'零食', '休闲零食', '零食礼盒', '大礼包', '小吃', '解馋',
]
# -------------------- 特殊食品处理 --------------------
SPECIAL_FOOD_RULES = {
# 食品名称中的词 -> 应该匹配的关键词
'冰糖橙': ['橙子', '柑橘'],
'蟹稻共生': ['大米', '米'],
'蟹田大米': ['大米', '米'],
'阿胶蜜枣': ['红枣', '枣'],
'雪梅': ['梅子', '话梅'],
'西梅': ['梅子', '西梅'],
'杨梅': ['梅子', '杨梅'],
'芒果干': ['芒果', '果干'],
'草莓干': ['草莓', '果干'],
'葡萄干': ['葡萄', '果干'],
'提子干': ['提子', '果干'],
'话梅条': ['梅子', '话梅'],
# 油类
'稻米油': ['油', '稻米油'],
'玉米胚芽油': ['油', '玉米油', '玉米胚芽油'],
'玉米油': ['油', '玉米油'],
'花生油': ['油', '花生油'],
'菜籽油': ['油', '菜籽油'],
'橄榄油': ['油', '橄榄油'],
'芝麻油': ['油', '芝麻油'],
'葵花油': ['油', '葵花油'],
'大豆油': ['油', '大豆油'],
'调和油': ['油', '调和油'],
'葵花籽油': ['油', '葵花籽油'],
'亚麻籽油': ['油', '亚麻籽油'],
'山茶油': ['油', '山茶油'],
'香油': ['油', '香油'],
'芝麻香油': ['油', '芝麻香油'],
'小磨香油': ['油', '小磨香油'],
# 肉制品
'香肠': ['香肠', '肠类', '肉制品'],
'火腿肠': ['香肠', '肠类', '肉制品'],
'腊肠': ['香肠', '肠类', '肉制品'],
# 梅子类
'乌梅': ['乌梅', '梅子', '果干'],
'话梅': ['话梅', '梅子', '果干'],
'雪梅': ['雪梅', '梅子', '果干'],
'西梅': ['西梅', '梅子', '果干'],
'杨梅': ['杨梅', '梅子', '果干'],
'梅子': ['梅子', '果干'],
# 防止错误匹配的规则
'玉米味': [], # 玉米味香肠,不匹配玉米
'葵花籽': ['油'], # 葵花籽油,只匹配油
'调和油': ['油', '调和油'], # 明确是油
}
# -------------------- 需要排除的错误匹配规则 --------------------
EXCLUDE_RULES = {
# 食品名称包含 -> 排除的关键词
'香肠': ['米', '大米', '玉米', '花生', '芝麻'], # 香肠不匹配谷物
'油': ['瓜子', '零食', '米', '大米', '玉米', '花生', '芝麻', '葵花'], # 油不匹配零食和原料
'梅': ['糖', '油', '盐', '酱油', '醋'], # 梅子类不匹配调味品
'肠': ['米', '大米', '玉米'], # 肠类不匹配谷物
}
# -------------------- 默认关键词规则 --------------------
DEFAULT_KEYWORD_RULES = [
# 油类(优先)
(['油', '花生油', '菜籽油', '玉米油', '橄榄油', '芝麻油', '葵花油', '大豆油', '稻米油', '调和油', '葵花籽油', '玉米胚芽油'], ['油']),
# 零食类
(['饼干', '苏打饼干', '曲奇', '威化'], ['饼干', '零食']),
(['薯片', '薯条', '呀土豆', '可比克', '乐事'], ['薯片', '零食']),
(['虾条', '虾片'], ['虾条', '零食']),
(['瓜子', '香瓜子', '南瓜子', '葵花籽'], ['瓜子', '零食']),
(['坚果', '松子', '杏仁', '腰果', '巴旦木', '每日坚果', '混合坚果'], ['坚果', '零食']),
(['糖果', '奶糖', '水果糖', '软糖', '硬糖', '大白兔'], ['糖果', '零食']),
(['酥糖', '米花酥', '花生酥', '芝麻酥', '核桃酥'], ['酥糖', '零食']),
(['巧克力', '巧克力味', '榛子巧克力'], ['巧克力', '零食']),
(['派', '蛋黄派', '巧克力派', '好丽友派'], ['糕点', '零食']),
(['铜锣烧', '瑞士卷', '月饼', '面包', '软面包', '菠萝包'], ['糕点', '零食']),
(['猪肉脯', '肉脯', '牛肉脯'], ['肉脯', '零食']),
(['卤蛋', '盐焗鸡蛋', '即食蛋'], ['卤蛋', '零食']),
(['米饼', '雪饼', '仙贝'], ['米饼', '零食']),
(['魔芋爽', '素毛肚'], ['零食', '素毛肚']),
# 肉制品
(['香肠', '火腿肠', '腊肠', '烤肠'], ['香肠', '肠类', '肉制品']),
# 梅子类
(['乌梅', '话梅', '雪梅', '西梅', '杨梅', '青梅', '梅子'], ['梅子', '果干']),
# 其他食品类别
(['粉', '面粉', '麦粉', '淀粉'], ['面粉', '粉']),
(['面条', '挂面', '拉面', '刀削面'], ['面条', '面食']),
(['方便面', '速食面'], ['方便面', '速食']),
(['调味料', '盐', '酱油', '醋', '料酒', '味精', '鸡精', '蚝油', '豆瓣酱'], ['调味料', '调料']),
(['干货', '木耳', '银耳', '腐竹', '粉丝', '紫菜', '海带', '香菇', '茶树菇'], ['干货', '干菜']),
(['杂粮', '绿豆', '红豆', '黑豆', '薏米', '燕麦', '荞麦', '藜麦'], ['杂粮', '豆类']),
(['饮料', '果汁', '牛奶', '酸奶', '豆浆', '咖啡', '茶', '可乐'], ['饮料', '饮品']),
(['酒', '白酒', '啤酒', '红酒', '葡萄酒', '黄酒'], ['酒', '饮品']),
(['罐头', '鱼罐头', '肉罐头', '水果罐头', '午餐肉'], ['罐头', '方便食品']),
(['速冻食品', '水饺', '饺子', '馄饨', '汤圆', '包子', '馒头', '花卷'], ['速冻食品', '面食']),
(['早餐食品', '麦片', '燕麦片', '冲调'], ['早餐食品', '冲饮品']),
(['酱料', '番茄酱', '沙拉酱', '辣椒酱', '黄豆酱', '甜面酱'], ['酱料', '调味酱']),
(['豆制品', '豆腐', '豆干', '豆皮', '腐乳', '豆奶'], ['豆制品']),
(['乳制品', '奶酪', '芝士', '黄油', '奶油'], ['乳制品', '奶制品']),
(['海产品', '海参', '鲍鱼', '鱼翅', '瑶柱', '干贝'], ['海产品', '海鲜干货']),
(['方便食品', '速食', '自热', '预制菜'], ['方便食品', '速食']),
(['烘焙原料', '酵母', '泡打粉', '小苏打', '可可粉', '抹茶粉'], ['烘焙原料', '烘焙']),
(['罐头水果', '黄桃罐头', '橘子罐头', '菠萝罐头', '荔枝罐头'], ['罐头水果', '水果罐头']),
(['汤料', '高汤', '浓汤宝'], ['汤料', '调味品']),
(['丸类', '鱼丸', '肉丸', '虾丸', '牛肉丸'], ['丸类', '火锅食材']),
(['肠类', '香肠', '腊肠', '火腿肠'], ['肠类', '肉制品']),
]
# -------------------- 文件查找工具 --------------------
def find_file(filename, candidate_dirs=None):
"""
在若干候选目录中查找文件,返回第一个存在的绝对路径或 None。
"""
script_dir = os.path.dirname(os.path.abspath(__file__))
cwd = os.getcwd()
if candidate_dirs is None:
candidate_dirs = [
script_dir,
os.path.join(script_dir, DEFAULT_DATA_DIR_NAME),
cwd,
os.path.join(cwd, DEFAULT_DATA_DIR_NAME),
]
for d in candidate_dirs:
path = os.path.join(d, filename)
if os.path.exists(path):
return os.path.abspath(path)
return None
# -------------------- 读取 CSV(多编码 + zip) --------------------
def read_csv_smart(path):
encodings = ["utf-8", "utf-8-sig", "gb18030", "gbk", "gb2312"]
for enc in encodings:
try:
df = pd.read_csv(path, dtype=str, encoding=enc)
return df
except Exception:
continue
# 尝试作为 zip 打开
try:
if zipfile.is_zipfile(path):
with zipfile.ZipFile(path, "r") as z:
for name in z.namelist():
if name.lower().endswith(".csv"):
with z.open(name) as fh:
content = fh.read()
for enc in encodings:
try:
return pd.read_csv(BytesIO(content), dtype=str, encoding=enc)
except Exception:
continue
print(f" ❌ {os.path.basename(path)} 是 ZIP,但内部没有 CSV")
return None
except Exception:
pass
print(f" ❌ 无法读取 {os.path.basename(path)}(编码/格式不可识别)")
return None
# -------------------- 列名标准化 --------------------
def standardize_columns(df):
mapping = {}
for col in df.columns:
key = str(col).strip().lower()
if key in ("id", "rid", "recipe_id"):
mapping[col] = "id"
elif "title" in key or key in ("标题", "名称", "菜名", "name"):
mapping[col] = "title"
elif "食材" in key or "分量" in key or "ingredient" in key:
mapping[col] = "食材分量"
elif "desc" in key or "描述" in key:
mapping[col] = "desc"
elif "step" in key or "步骤" in key:
mapping[col] = "steps"
if mapping:
df = df.rename(columns=mapping)
return df
# -------------------- 提取数字ID --------------------
def extract_pure_number_id(id_value):
"""
提取有效的菜谱ID
"""
if id_value is None:
return None
s = str(id_value).strip()
s = s.strip("'\"")
if not s or s.lower() in ("nan", "none", "null"):
return None
# 如果已经是合理的数字ID(8-10位)
if s.isdigit():
if 10000000 <= int(s) <= 9999999999:
return s
# 从字符串中提取所有数字
nums = re.findall(r"\d+", s)
if not nums:
return None
# 优先选择8-10位的数字
valid_nums = []
for n in nums:
if len(n) >= 8 and len(n) <= 10:
valid_nums.append(n)
if valid_nums:
return valid_nums[0]
return None
# -------------------- 扩展的食品关键词 --------------------
def get_extended_food_keywords():
"""扩展的食品关键词,覆盖更多食品类型"""
food_keywords = {
# 油类(优先级高)
'油类': ['油', '花生油', '菜籽油', '玉米油', '橄榄油', '芝麻油', '葵花油', '色拉油',
'大豆油', '稻米油', '调和油', '葵花籽油', '玉米胚芽油', '亚麻籽油', '山茶油',
'香油', '芝麻香油', '小磨香油'],
# 零食类
'零食类': ['零食', '休闲零食', '零食礼盒', '大礼包', '小吃', '解馋'],
'饼干类': ['饼干', '苏打饼干', '曲奇', '威化'],
'薯片类': ['薯片', '薯条'],
'虾条类': ['虾条', '虾片'],
'瓜子类': ['瓜子', '香瓜子', '南瓜子'],
'坚果类': ['坚果', '松子', '杏仁', '腰果', '巴旦木'],
'糖果类': ['糖果', '奶糖', '水果糖', '软糖', '硬糖'],
'酥糖类': ['酥糖', '米花酥', '花生酥', '芝麻酥', '核桃酥'],
'巧克力类': ['巧克力'],
'糕点类': ['糕点', '蛋糕', '面包', '月饼', '派', '铜锣烧', '瑞士卷'],
'肉脯类': ['猪肉脯', '肉脯', '牛肉脯'],
'卤蛋类': ['卤蛋'],
'米饼类': ['米饼', '雪饼', '仙贝'],
'其他零食': ['魔芋爽', '素毛肚'],
# 肉制品
'肠类': ['香肠', '火腿肠', '腊肠', '烤肠'],
'肉制品': ['猪肉松', '猪肉条', '烤肠', '火腿肠', '香肠', '腊肠', '火山石烤肠'],
# 梅子类
'梅子类': ['乌梅', '话梅', '雪梅', '西梅', '杨梅', '青梅', '梅子'],
# 粮油类
'米类': ['大米', '米', '五常大米', '盘锦大米', '丝苗米', '珍珠米', '糯米', '小米', '黑米',
'香米', '长粒香', '金丝苗', '东北大米', '蟹稻大米', '蟹田大米'],
# 基础食材
'玉米类': ['玉米', '玉米粒', '甜玉米'],
'花生类': ['花生', '炒花生', '煮花生'],
'芝麻类': ['芝麻', '炒芝麻'],
'大豆类': ['大豆', '黄豆', '毛豆'],
'葵花类': ['葵花籽'],
# 海鲜类
'带鱼类': ['带鱼'],
'鳕鱼类': ['鳕鱼', '银鳕鱼'],
'鲈鱼类': ['鲈鱼'],
'石斑鱼类': ['石斑鱼', '东星斑'],
'黄花鱼类': ['黄花鱼'],
'鲳鱼类': ['鲳鱼', '白鲳鱼', '中华鲳'],
'虾类': ['虾', '黑虎虾', '斑节虾', '皮皮虾', '虾仁'],
'蟹类': ['蟹'],
'其他鱼': ['白姑鱼', '马友鱼', '黄翅鱼', '梭子鱼', '小银鱼', '银鱼', '章鱼', '臭鳜鱼'],
'鱼类': ['鱼'],
'其他海鲜': ['白贝', '龙虾', '沙虫', '贝类'],
# 水果类
'柑橘类': ['橙子', '柑橘', '桔子', '沃柑', '脐橙', '冰糖橙', '金桔', '蜜桔', '小金桔', '青柠檬', '果冻橙', '爱媛橙'],
'苹果类': ['苹果', '红富士', '富士苹果'],
'芒果类': ['芒果', '凯特芒', '金煌芒'],
'热带水果': ['火龙果', '木瓜', '菠萝', '菠萝蜜', '椰子', '柠檬', '椰青'],
'梨类': ['梨', '秋月梨', '雪花梨'],
'莓果类': ['草莓', '葡萄', '提子', '红提', '桑葚', '山楂', '蓝莓', '树莓', '蔓越莓'],
# 坚果干果类
'干果类': ['葡萄干', '提子干', '芒果干', '草莓干', '果干', '蜜饯', '蓝莓干', '梅干'],
'枣类': ['红枣', '大红枣', '蜜枣', '枣夹核桃', '枣仁', '枣圈', '枣干'],
# 肉类(原料)
'牛肉类': ['牛肉', '牛腩', '安格斯', '雪花牛肉', '牛肉粒', '牛排', '肥牛', '牛筋'],
'羊肉类': ['羊肉', '羊排', '羊腿'],
'牛羊肉类': ['牛羊肉'],
'猪肉类': ['猪肉', '黑猪肉'],
'猪肉部位': ['五花肉', '里脊', '猪蹄', '猪排', '猪骨'],
# 禽蛋类(原料)
'鸡肉类': ['鸡肉', '鸡腿', '鸡翅', '鸡爪', '鸡胸肉'],
'蛋类': ['鸡蛋', '土鸡蛋', '鸭蛋', '鹅蛋'],
# 蔬菜类(原料)
'豆制品': ['豆腐', '豆干', '豆皮'],
'菌菇类': ['香菇', '木耳', '蘑菇', '金针菇'],
'根茎类': ['萝卜', '土豆', '山药', '胡萝卜', '红薯', '紫薯', '芋头', '莲藕'],
'果菜类': ['番茄', '西红柿', '茄子', '黄瓜', '南瓜', '秋葵', '辣椒'],
'叶菜类': ['青菜', '芹菜', '豆角', '洋葱', '花菜', '西兰花', '白菜'],
# 调味品类
'糖类': ['糖', '冰糖', '红糖'],
'调味品类': ['盐', '酱油', '醋', '料酒', '味精', '鸡精', '蚝油', '豆瓣酱'],
'酱料类': ['酱料', '调味酱', '番茄酱', '沙拉酱', '辣椒酱', '黄豆酱', '甜面酱'],
}
# 按优先级排序(油类优先)
priority_order = [
# 油类(优先级最高)
'油类',
# 肉制品
'肠类', '肉制品',
# 梅子类
'梅子类',
# 零食类
'零食类', '饼干类', '薯片类', '虾条类', '瓜子类', '坚果类', '糖果类',
'酥糖类', '巧克力类', '糕点类', '肉脯类', '卤蛋类', '米饼类', '其他零食',
# 粮油类
'米类',
# 基础食材
'玉米类', '花生类', '芝麻类', '大豆类', '葵花类',
# 海鲜
'带鱼类', '鳕鱼类', '鲈鱼类', '石斑鱼类', '黄花鱼类', '鲳鱼类',
'虾类', '其他鱼',
# 水果
'柑橘类', '苹果类', '芒果类', '热带水果', '梨类', '莓果类',
# 坚果干果
'干果类', '枣类',
# 肉类
'牛肉类', '羊肉类', '牛羊肉类', '猪肉类', '猪肉部位',
# 其他
'鸡肉类', '蛋类', '蔬菜类',
# 调味品(最后)
'糖类', '调味品类', '酱料类',
# 通用关键词(最后)
'鱼类', '蟹类', '其他海鲜'
]
all_keywords = []
for category in priority_order:
if category in food_keywords:
all_keywords.extend(food_keywords[category])
return food_keywords, all_keywords
def is_snack_food(food_name):
"""判断是否为零食类食品"""
food_name_lower = food_name.lower()
for keyword in SNACK_KEYWORDS:
if keyword in food_name_lower:
return True
return False
def should_exclude_keyword(food_name, keyword):
"""根据排除规则判断是否应该排除某个关键词"""
food_name_lower = food_name.lower()
# 检查排除规则
for pattern, exclude_keywords in EXCLUDE_RULES.items():
if pattern in food_name_lower:
if keyword in exclude_keywords:
return True
# 特殊规则:梅子类不应该匹配调味品
if any(term in food_name_lower for term in ['乌梅', '话梅', '雪梅', '西梅', '杨梅', '梅子']):
if keyword in ['糖', '油', '盐', '酱油', '醋']:
return True
# 特殊规则:香肠不应该匹配谷物
if any(term in food_name_lower for term in ['香肠', '火腿肠', '腊肠', '肠']):
if keyword in ['米', '大米', '玉米', '花生', '芝麻']:
return True
# 特殊规则:油不应该匹配零食和原料
if any(term in food_name_lower for term in ['油', '花生油', '菜籽油', '玉米油', '葵花油', '大豆油', '调和油']):
if keyword in ['瓜子', '零食', '米', '大米', '玉米', '花生', '芝麻', '葵花']:
return True
return False
def get_food_keywords(food_name, all_keywords):
"""为食品获取关键词,考虑排除规则"""
matched_keywords = []
food_name_lower = food_name.lower()
# 首先检查特殊规则(最高优先级)
for special_term, target_keywords in SPECIAL_FOOD_RULES.items():
if special_term in food_name:
for kw in target_keywords:
if kw in all_keywords and kw not in matched_keywords:
if not should_exclude_keyword(food_name, kw):
matched_keywords.append(kw)
# 如果找到了特殊规则匹配,跳过普通匹配
if matched_keywords:
return matched_keywords
# 检查默认关键词规则
for pattern_list, keywords in DEFAULT_KEYWORD_RULES:
for pattern in pattern_list:
if pattern in food_name_lower:
for kw in keywords:
if kw in all_keywords and kw not in matched_keywords:
if not should_exclude_keyword(food_name, kw):
matched_keywords.append(kw)
if matched_keywords:
return matched_keywords
# 如果没有匹配到,使用通用匹配
for kw in all_keywords:
if kw in food_name and kw not in matched_keywords:
if not should_exclude_keyword(food_name, kw):
matched_keywords.append(kw)
if len(matched_keywords) >= 2: # 最多2个关键词
break
return matched_keywords
def generate_default_keywords(food_name, all_keywords):
"""
为没有匹配到关键词的食品生成默认关键词
"""
# 首先尝试获取关键词
matched_keywords = get_food_keywords(food_name, all_keywords)
if matched_keywords:
return matched_keywords
# 如果没有匹配到,根据食品类型生成默认关键词
food_name_lower = food_name.lower()
# 判断食品类型
if any(term in food_name_lower for term in ['油', '花生油', '菜籽油', '玉米油', '葵花油']):
return ['油']
elif any(term in food_name_lower for term in ['香肠', '火腿肠', '腊肠', '肠']):
return ['香肠', '肉制品']
elif any(term in food_name_lower for term in ['乌梅', '话梅', '雪梅', '西梅', '杨梅', '梅子']):
return ['梅子', '果干']
elif is_snack_food(food_name):
return ['零食']
else:
# 尝试提取食品名称中的名词
clean_name = re.sub(r'[0-9\.\*\+\-\/LkgmlML克千克升毫升]', ' ', food_name)
clean_name = re.sub(r'[\(\)()]', ' ', clean_name)
# 提取可能的名词(至少2个字符)
words = re.findall(r'[\u4e00-\u9fff]{2,}', clean_name)
if words:
# 取前2个词作为关键词
keywords = []
for word in words[:2]:
if word not in keywords and len(word) >= 2:
keywords.append(word)
return keywords
# 如果还是没有,使用通用标签
return ['预包装食品', '加工食品']
# -------------------- 智能关键词提取 --------------------
def extract_keywords_for_food(food_name, all_keywords):
"""
为食品名称提取关键词
"""
return generate_default_keywords(food_name, all_keywords)[:3] # 最多返回3个
# -------------------- 智能菜谱匹配函数 --------------------
def find_best_matching_recipes(food_name, recipes_df, ingredient_index, all_keywords):
"""
为食品寻找最佳匹配的菜谱
"""
matched = []
# 提取关键词
matched_keywords = extract_keywords_for_food(food_name, all_keywords)
# 分阶段匹配
stages = [
("精确匹配", 0, 30),
("宽松匹配", -10, 20),
("通用匹配", -20, 10),
]
used_recipe_ids = set()
for stage_name, base_score, max_per_stage in stages:
if len(matched) >= 3:
break
stage_matches = []
for kw in matched_keywords:
if kw not in ingredient_index:
continue
for recipe_id in ingredient_index[kw]:
if recipe_id in used_recipe_ids:
continue
recipe_row = recipes_df[recipes_df['recipe_id'] == recipe_id]
if recipe_row.empty:
continue
recipe_title = str(recipe_row.iloc[0]['title'])
recipe_ingredients = str(recipe_row.iloc[0]['ingredients'])
# 计算匹配分数
score = base_score
# 阶段1:精确匹配
if stage_name == "精确匹配":
if kw.lower() in recipe_title.lower():
score += 50
# 阶段2:宽松匹配
elif stage_name == "宽松匹配":
if kw.lower() in recipe_ingredients.lower():
score += 30
# 阶段3:通用匹配
elif stage_name == "通用匹配":
if kw.lower() in recipe_title.lower():
score += 20
# 通用加分项
if kw in matched_keywords[:3]:
score += 10
# 避免明显不匹配
if should_exclude_recipe(kw, recipe_title, recipe_ingredients, matched_keywords, food_name):
score -= 100
if score > 0:
stage_matches.append((recipe_id, score, kw))
# 按分数排序并选择
stage_matches.sort(key=lambda x: x[1], reverse=True)
for recipe_id, score, kw in stage_matches[:max_per_stage]:
if recipe_id not in used_recipe_ids and len(matched) < 3:
matched.append(recipe_id)
used_recipe_ids.add(recipe_id)
return matched, matched_keywords
def should_exclude_recipe(keyword, recipe_title, recipe_ingredients, matched_keywords, food_name):
"""
检查是否应该排除这个菜谱
"""
text = (recipe_title + " " + recipe_ingredients).lower()
food_name_lower = food_name.lower()
# 零食类食品不应该匹配需要烹饪的菜谱
if is_snack_food(food_name):
if any(x in text for x in ['炒', '煮', '蒸', '炸', '烤', '煎', '炖', '烧']):
return True
if any(x in text for x in ['切', '剁', '腌', '泡', '发']):
return True
# 油类不应该匹配零食类菜谱
if any(term in food_name_lower for term in ['油', '花生油', '菜籽油', '玉米油', '葵花油']):
if any(x in text for x in ['零食', '小吃', '解馋']):
return True
# 梅子类不应该匹配油菜谱
if any(term in food_name_lower for term in ['乌梅', '话梅', '雪梅', '西梅', '杨梅']):
if '油' in text and '梅子' not in text:
return True
# 香肠不应该匹配谷物菜谱
if any(term in food_name_lower for term in ['香肠', '火腿肠', '腊肠']):
if any(x in text for x in ['米饭', '粥', '米线', '米粉']):
return True
return False
# -------------------- 主流程 --------------------
def create_food_recipe_links():
print("\n" + "=" * 60)
print("食物-菜谱关联表生成器(最终优化版)")
print("=" * 60 + "\n")
# --- 找食品文件 ---
food_path = find_file(FOOD_FILENAME)
if not food_path:
print(f" ❌ 找不到食品文件:{FOOD_FILENAME}")
return
print(f"1. 读取食品数据: {food_path}")
try:
food_df = pd.read_excel(food_path, engine="openpyxl")
except Exception as e:
print(f" ❌ 读取食品数据失败: {e}")
return
# 重命名列
if "Column1" in food_df.columns and "Column3" in food_df.columns:
food_df = food_df.rename(columns={"Column1": "food_id", "Column3": "food_name"})
if "food_id" not in food_df.columns:
for c in food_df.columns:
if str(c).strip().lower() in ("id", "food_id", "编号", "序号"):
food_df = food_df.rename(columns={c: "food_id"})
break
if "food_name" not in food_df.columns:
for c in food_df.columns:
if str(c).strip().lower() in ("food_name", "名称", "商品名称", "gtitle", "title", "name"):
food_df = food_df.rename(columns={c: "food_name"})
break
if "food_id" not in food_df.columns or "food_name" not in food_df.columns:
print(" ❌ 食品表缺少 food_id 或 food_name 列")
return
food_df = food_df[["food_id", "food_name"]].copy()
food_df["food_name"] = food_df["food_name"].astype(str).str.strip()
print(f" ✔ 食品数量: {len(food_df)}")
# --- 读取菜谱文件 ---
print("\n2. 读取菜谱数据...")
all_recipes = []
for fname in RECIPE_FILES:
candidate = find_file(fname)
if not candidate:
continue
print(f"\n 读取文件: {candidate}")
df = read_csv_smart(candidate)
if df is None:
continue
print(f" 成功读取,行数: {len(df)}")
df = standardize_columns(df)
df["source_file"] = os.path.basename(candidate)
all_recipes.append(df)
if not all_recipes:
print(" ❌ 没有读取到任何菜谱数据")
return
# --- 合并菜谱数据 ---
print("\n3. 合并并清洗菜谱数据...")
recipes_data = []
for df_idx, df in enumerate(all_recipes):
src = df["source_file"].iloc[0] if "source_file" in df.columns else f"source_{df_idx}"
print(f" 处理来源: {src}, 行数: {len(df)}")
# 保证有 id 列
if "id" not in df.columns:
potential = [c for c in df.columns if "id" in str(c).lower()]
if potential:
df = df.rename(columns={potential[0]: "id"})
else:
first_col = df.columns[0]
df = df.rename(columns={first_col: "id"})
if "title" not in df.columns:
for c in df.columns:
if any(k in str(c).lower() for k in ("title", "标题", "name", "菜名")):
df = df.rename(columns={c: "title"})
break
if "食材分量" not in df.columns and "ingredients" in df.columns:
df = df.rename(columns={"ingredients": "食材分量"})
df = df.reset_index(drop=True)
valid_count = 0
for idx in range(len(df)):
try:
raw_id = df.at[idx, "id"] if "id" in df.columns else ""
rid = extract_pure_number_id(raw_id)
if not rid or not (8 <= len(rid) <= 10):
continue
title = df.at[idx, "title"] if "title" in df.columns and pd.notna(df.at[idx, "title"]) else f"菜谱_{rid}"
ing = df.at[idx, "食材分量"] if "食材分量" in df.columns and pd.notna(df.at[idx, "食材分量"]) else ""
recipes_data.append({
"recipe_id": rid,
"title": str(title),
"ingredients": str(ing),
"category": src.replace(".csv", "")
})
valid_count += 1
except Exception:
continue
print(f" 有效菜谱数: {valid_count}")
if not recipes_data:
print(" ❌ 合并后没有有效菜谱记录")
return
recipes_df = pd.DataFrame(recipes_data).drop_duplicates(subset=["recipe_id"])
print(f"\n ✔ 总菜谱数: {len(recipes_df)}")
# --- 构建索引 ---
print("\n4. 构建食材倒排索引...")
food_keywords, all_keywords = get_extended_food_keywords()
print(f" 关键词总数: {len(all_keywords)}")
ingredient_index = {}
for _, row in recipes_df.iterrows():
full_text = (str(row["title"]) + " " + str(row["ingredients"])).lower()
rid = row["recipe_id"]
for kw in all_keywords:
if kw.lower() in full_text:
ingredient_index.setdefault(kw, set()).add(rid)
print(f" ✔ 构建完成, 索引关键词数: {len(ingredient_index)}")
# --- 智能匹配 ---
print("\n5. 建立食物-菜谱关联...")
links = []
problem_foods = [] # 记录有问题的食品
for _, frow in food_df.iterrows():
fid = frow["food_id"]
fname = str(frow["food_name"])
matched, matched_keywords = find_best_matching_recipes(fname, recipes_df, ingredient_index, all_keywords)
# 检查是否有问题的匹配
food_name_lower = fname.lower()
# 检查油类食品是否匹配了零食关键词
if any(term in food_name_lower for term in ['油', '花生油', '菜籽油', '玉米油', '葵花油', '大豆油', '调和油']):
if any(kw in matched_keywords for kw in ['瓜子', '零食']):
problem_foods.append((fid, fname, "油类匹配了零食关键词", matched_keywords))
# 检查香肠是否匹配了谷物关键词
if any(term in food_name_lower for term in ['香肠', '火腿肠', '腊肠', '肠']):
if any(kw in matched_keywords for kw in ['米', '大米', '玉米']):
problem_foods.append((fid, fname, "香肠匹配了谷物关键词", matched_keywords))
# 检查梅子类是否匹配了调味品关键词
if any(term in food_name_lower for term in ['乌梅', '话梅', '雪梅', '西梅', '杨梅', '梅子']):
if any(kw in matched_keywords for kw in ['糖', '油', '盐', '酱油', '醋']):
problem_foods.append((fid, fname, "梅子类匹配了调味品关键词", matched_keywords))
links.append({
"food_id": fid,
"food_name": fname,
"recipe_id_1": matched[0] if len(matched) > 0 else "",
"recipe_id_2": matched[1] if len(matched) > 1 else "",
"recipe_id_3": matched[2] if len(matched) > 2 else "",
"matched_keywords": ", ".join(matched_keywords[:3]) if matched_keywords else "无"
})
links_df = pd.DataFrame(links).drop_duplicates(subset=["food_id"])
# --- 保存结果 ---
final_output = OUTPUT_FILE
try:
links_df.to_csv(final_output, index=False, encoding="utf-8-sig")
print(f"\n ✔ 成功保存到: {final_output}")
except PermissionError:
ts = time.strftime("%Y%m%d_%H%M%S")
alt = f"food_recipe_final_links_{ts}.csv"
links_df.to_csv(alt, index=False, encoding="utf-8-sig")
final_output = alt
print(f"\n ⚠ 权限不足,已另存为: {alt}")
# 菜谱参考表
try:
recipes_ref = recipes_df[["recipe_id", "title", "category"]].drop_duplicates(subset=["recipe_id"])
recipes_ref.to_csv("recipes_reference.csv", index=False, encoding="utf-8-sig")
print(" ✔ 菜谱参考表已保存: recipes_reference.csv")
except Exception:
pass
# --- 输出结果 ---
print("\n" + "=" * 60)
print("✅ 食物-菜谱关联表生成完成!")
print("=" * 60)
print(f"\n📊 统计信息:")
print(f" 食品总数: {len(food_df)}")
print(f" 菜谱总数: {len(recipes_df)}")
associated = links_df[links_df["recipe_id_1"] != ""]
no_match = links_df[links_df["recipe_id_1"] == ""]
print(f" 有关联菜谱的食品: {len(associated)}")
print(f" 无关联菜谱的食品: {len(no_match)}")
# 显示有问题的食品
if problem_foods:
print(f"\n⚠️ 检测到{len(problem_foods)}个有问题的匹配:")
for fid, fname, issue, keywords in problem_foods[:10]:
print(f" {fid}. {fname[:40]}... - {issue}")
print(f" 当前关键词: {keywords}")
# 显示示例食品的匹配结果
print(f"\n📋 示例食品匹配结果:")
sample_foods = [
(124, "玉米味香肠20根"),
(247, "葵花籽食用调和油5升/桶"),
(261, "多力葵花籽油4L"),
(366, "浙梅苏式话梅酸甜奶油话梅"),
(380, "浙梅糖渍乌梅"),
(551, "上海特产大白兔奶糖*2"),
]
for food_id, food_name in sample_foods:
for idx in range(len(links_df)):
row = links_df.iloc[idx]
if str(row['food_id']) == str(food_id) or food_name in row['food_name']:
print(f"\n {row['food_id']}. {row['food_name']}")
print(f" 匹配关键词: {row['matched_keywords']}")
if row['recipe_id_1']:
for i, rid in enumerate([row['recipe_id_1'], row['recipe_id_2'], row['recipe_id_3']]):
if rid:
recipe_info = recipes_df[recipes_df['recipe_id'] == rid]
if not recipe_info.empty:
title = recipe_info.iloc[0]['title']
print(f" 菜谱{i+1}: {rid} - {title[:50]}...")
break
print(f"\n📁 输出文件: {final_output}")
if __name__ == "__main__":
create_food_recipe_links()
3、所有新鲜水果的相关菜谱推荐和菜谱相关食材(如鸭爪,白醋,蜂蜜)的添加,让人们能更直观的看到有什么菜谱,怎么做菜,还能一键加购菜谱其他相应食材。

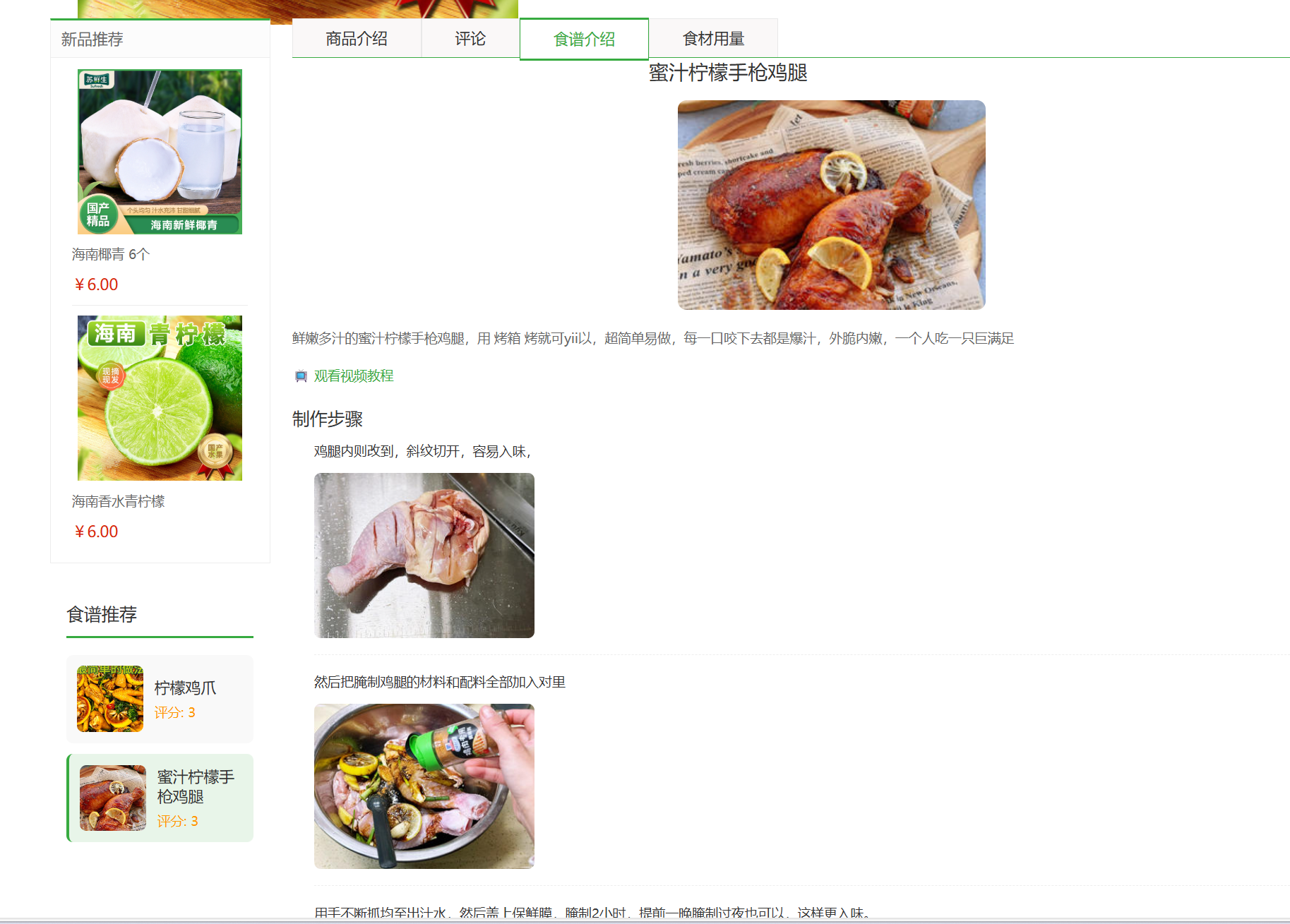
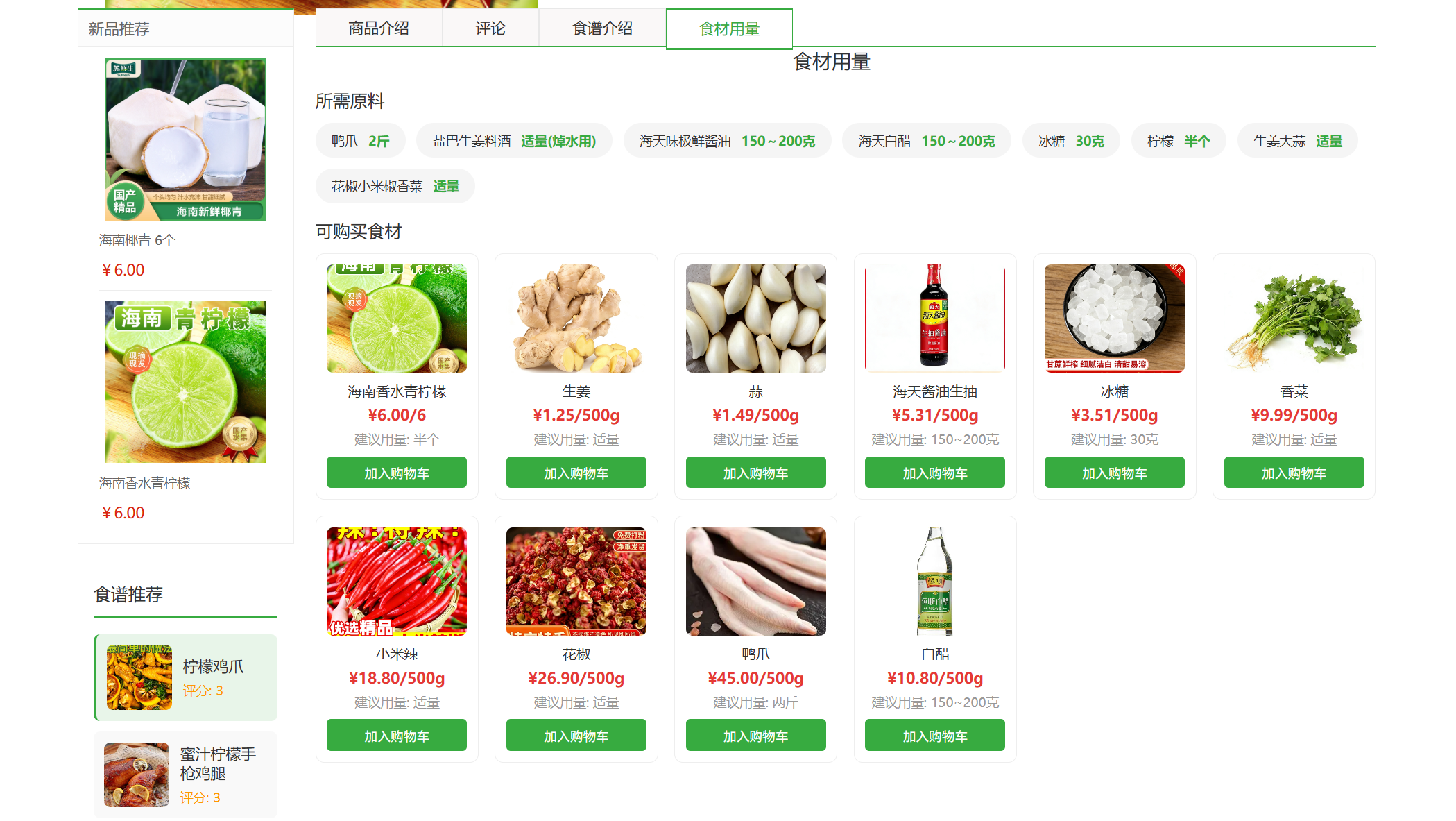
4、编写完整的项目说明文档(README),包含项目概述、功能简介、在线样例和安装部署,用于吸引用户、协作开发者及项目宣传。
Gitee链接:https://gitee.com/ding41/buy-menu/blob/master/README.md
Buy-Menu
食鲜配·智厨 (FreshFood Smart Kitchen)
食鲜配·智厨是一个基于Python 3.7+和Django 2.0.7的智能电商菜谱一体化平台,实现了"购物-菜谱-健康"的完整闭环,为用户提供"买什么-怎么做-吃得健康"一站式解决方案。
项目特色
核心功能
- 智能购物车与菜谱联动:打通购物车与菜谱系统,实现食材与菜谱的无缝衔接
- AI营养分析:结合AI算法分析食材搭配,提供健康建议和个性化推荐
- 智能购物助手:在购物车页面内置AI分析功能,评估食材搭配合理性
- 全流程覆盖:从食材选购到烹饪指导,再到营养分析的全链路服务
- 一键结算系统:支持多种支付方式,实时计算商品小计和运费
主要模块
- 用户管理:注册、登录、个人信息管理、收货地址管理
- 商品浏览:分类展示、搜索功能、热门推荐、新品展示
- 购物车系统:商品添加/修改、临时保存、登录同步、AI智能分析
- 订单管理:订单生成、状态跟踪、支付结算、多方式支付
- 菜谱系统:菜谱浏览、详情查看、烹饪步骤指导、食材关联
- 个性化设置:饮食偏好设置、AI助手咨询
在线样例:
预览:
首页

登录

商品详情

推荐菜谱

一键加购

购物车

智能助手

安装步骤
- 克隆项目
git clone <项目地址> cd buy-menu - 创建虚拟环境 (推荐)
python -m venv .venv # Windows .venv\Scripts\activate # Linux/Mac source .venv/bin/activate - 安装依赖包
pip install -Ur requirements.txt - 创建超级用户
python manage.py createsuperuser # 按照提示输入用户名、邮箱和密码 - 运行开发服务器
python manage.py runserver - 访问应用
使用指南
用户功能
- 注册登录: 填写基本信息完成注册,支持记住登录状态
- 商品浏览: 按分类查看商品,支持关键词搜索
- 购物车操作:
- 添加商品:商品详情页选择分量、处理方式和数量后加入购物车
- 修改商品:购物车内可修改数量、删除商品,实时计算总价
- 智能分析:内置AI食材分析功能,提供营养搭配建议
- 同步功能:未登录用户支持临时保存,登录后自动同步
- 菜谱功能:
- 浏览各类菜谱,查看详细烹饪步骤
- 菜谱与商品关联,可一键购买所需食材
- 支持视频教学链接,提升学习体验
- 订单管理:
- 订单生成:购物车点击结算进入订单确认页面
- 地址管理:选择或编辑收货地址
- 支付方式:支持货到付款、微信支付、支付宝、银行卡支付
- 费用计算:系统自动计算商品总价及运费
- 订单跟踪:查看待支付、待发货、已完成等订单状态
管理员功能
- 商品管理: 添加/编辑商品信息、设置库存、上传图片
- 分类管理: 管理商品分类和菜谱分类
- 菜谱管理: 管理菜谱内容、关联食材、设置烹饪步骤
- 订单管理: 查看和处理用户订单、修改订单状态、取消超时未支付订单
数据模型
主要模型说明
- TypeInfo - 商品分类
- GoodsInfo - 商品信息
- Recipe - 菜谱信息
- RecipeGoods - 菜谱与商品关联表
- CartInfo - 购物车信息
- GoodsBrowser - 商品浏览记录
技术架构
后端技术栈
- Web框架: Django 2.0.7
- 数据库: SQLite3(开发)/ MySQL(生产)
- 富文本编辑器: django-tinymce
- 图像处理: Pillow
- 时区处理: pytz
- 模板引擎: Django Templates
- 会话管理: Django Session
- ORM: Django ORM
前端技术栈
- 基础技术: HTML5, CSS3, JavaScript
- UI框架: 自定义CSS样式
- JavaScript库: jQuery 1.12.4
- 交互: AJAX异步请求
- 图标: Font Awesome / 自定义图标
- 动画: CSS3动画 + jQuery动画
贡献指南
- Fork项目
- 创建功能分支 (
git checkout -b feature/AmazingFeature) - 提交更改 (
git commit -m 'Add some AmazingFeature') - 推送到分支 (
git push origin feature/AmazingFeature) - 开启Pull Request

 浙公网安备 33010602011771号
浙公网安备 33010602011771号