
102302109-胡贝贝-作业4
作业①:
(1)实验内容及结果
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
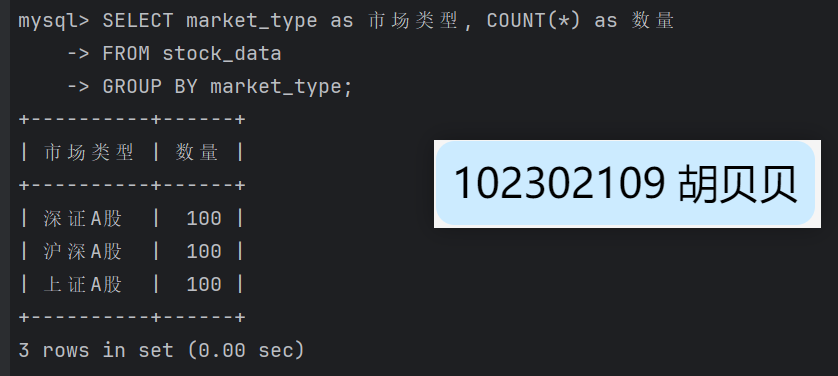
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
核心代码:
class StockDataSpider(scrapy.Spider):
name = 'stock_data'
allowed_domains = ['quote.eastmoney.com']
# 定义要爬取的市场及其API参数
markets = {
'沪深A股': {
'api_fs': 'm:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23',
'url_suffix': 'hs_a_board'
},
'上证A股': {
'api_fs': 'm:1+t:2',
'url_suffix': 'sh_a_board'
},
'深证A股': {
'api_fs': 'm:0+t:6',
'url_suffix': 'sz_a_board'
}
}
def start_requests(self):
self.logger.info(" 开始爬取东方财富网股票数据...")
for market_name, market_info in self.markets.items():
web_url = f"http://quote.eastmoney.com/center/gridlist.html#{market_info['url_suffix']}"
# API URL
api_url = self.construct_api_url(market_info['api_fs'])
yield scrapy.Request(
url=api_url,
callback=self.parse_api,
meta={
'market_name': market_name,
'web_url': web_url
},
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': web_url,
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Origin': 'http://quote.eastmoney.com'
},
dont_filter=True
)
def construct_api_url(self, fs_param):
"""构造API URL"""
base_url = "http://82.push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '5000',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': fs_param,
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': str(int(datetime.now().timestamp() * 1000))
}
param_str = '&'.join([f"{k}={v}" for k, v in params.items()])
return f"{base_url}?{param_str}"
def parse_api(self, response):
market_name = response.meta['market_name']
self.logger.info(f" 开始解析 {market_name} 数据...")
try:
data = json.loads(response.text)
stocks = data.get('data', {}).get('diff', [])
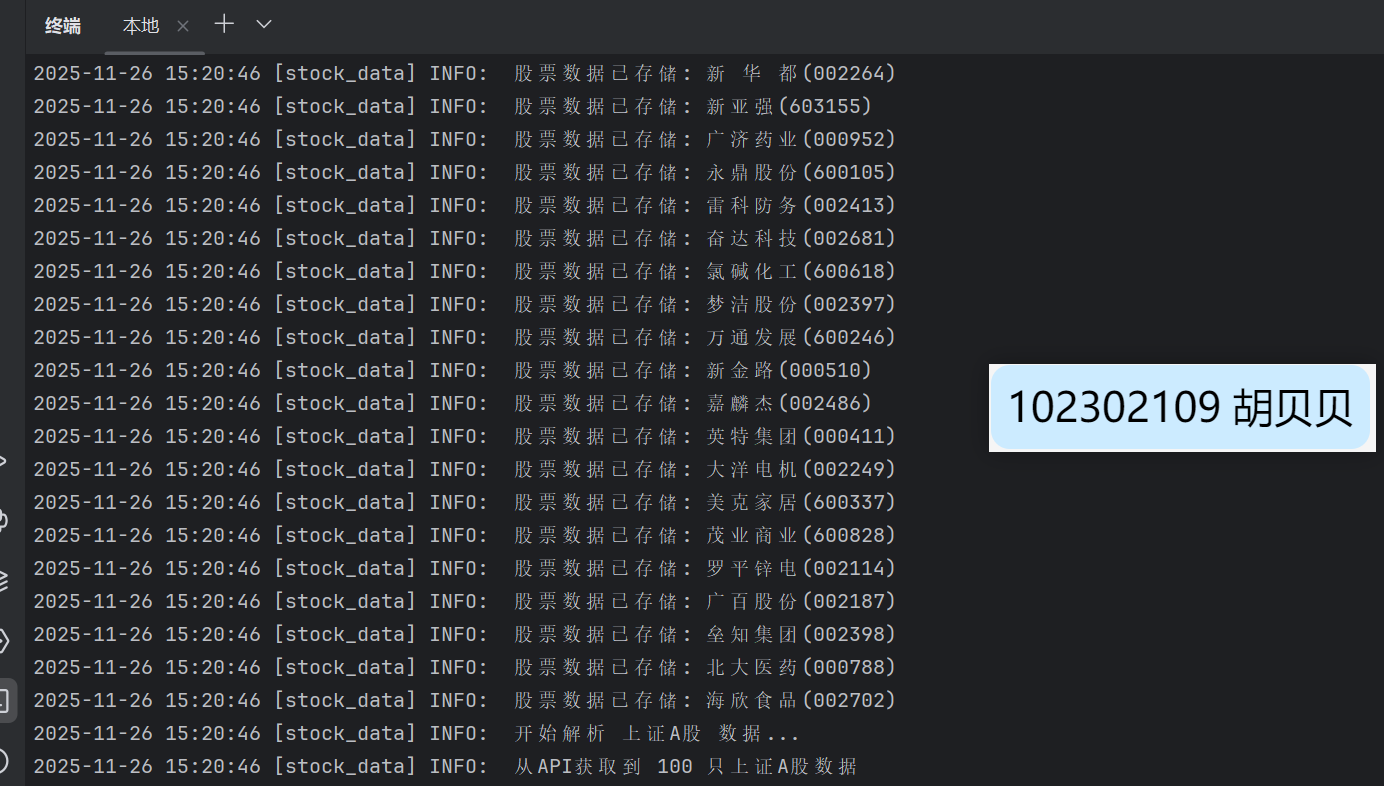
self.logger.info(f" 从API获取到 {len(stocks)} 只{market_name}数据")
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
processed_count = 0
for index, stock in enumerate(stocks):
item = StockItem()
item['id'] = index + 1
item['stock_code'] = stock.get('f12', '') # 股票代码
item['stock_name'] = stock.get('f14', '') # 股票名称
item['latest_price'] = stock.get('f2', 0) # 最新价
item['change_percent'] = stock.get('f3', 0) # 涨跌幅
item['change_amount'] = stock.get('f4', 0) # 涨跌额
item['volume'] = self.format_volume(stock.get('f5', 0)) # 成交量
item['turnover'] = self.format_turnover(stock.get('f6', 0)) # 成交额
item['amplitude'] = stock.get('f7', 0) # 振幅
item['high_price'] = stock.get('f15', 0) # 最高
item['low_price'] = stock.get('f16', 0) # 最低
item['open_price'] = stock.get('f17', 0) # 今开
item['previous_close'] = stock.get('f18', 0) # 昨收
item['market_type'] = market_name
item['crawl_time'] = current_time
if item['stock_code'] and item['stock_name']:
processed_count += 1
if processed_count <= 5:
self.logger.info(
f" 示例数据: {item['stock_name']}({item['stock_code']}) - 价格: {item['latest_price']}")
yield item
self.logger.info(f" {market_name} 数据处理完成,共处理 {processed_count} 条有效数据")
except Exception as e:
self.logger.error(f" 解析{market_name}数据失败: {e}")
self.logger.debug(f"响应内容: {response.text[:500]}")
def format_volume(self, volume):
"""格式化成交量"""
try:
volume = float(volume)
if volume >= 100000000:
return f"{volume / 100000000:.2f}亿"
elif volume >= 10000:
return f"{volume / 10000:.2f}万"
else:
return f"{volume:.0f}"
except (ValueError, TypeError):
return "0"
def format_turnover(self, turnover):
"""格式化成交额"""
try:
turnover = float(turnover)
if turnover >= 100000000:
return f"{turnover / 100000000:.2f}亿元"
elif turnover >= 10000:
return f"{turnover / 10000:.2f}万元"
else:
return f"{turnover:.2f}元"
except (ValueError, TypeError):
return "0"
输出信息:
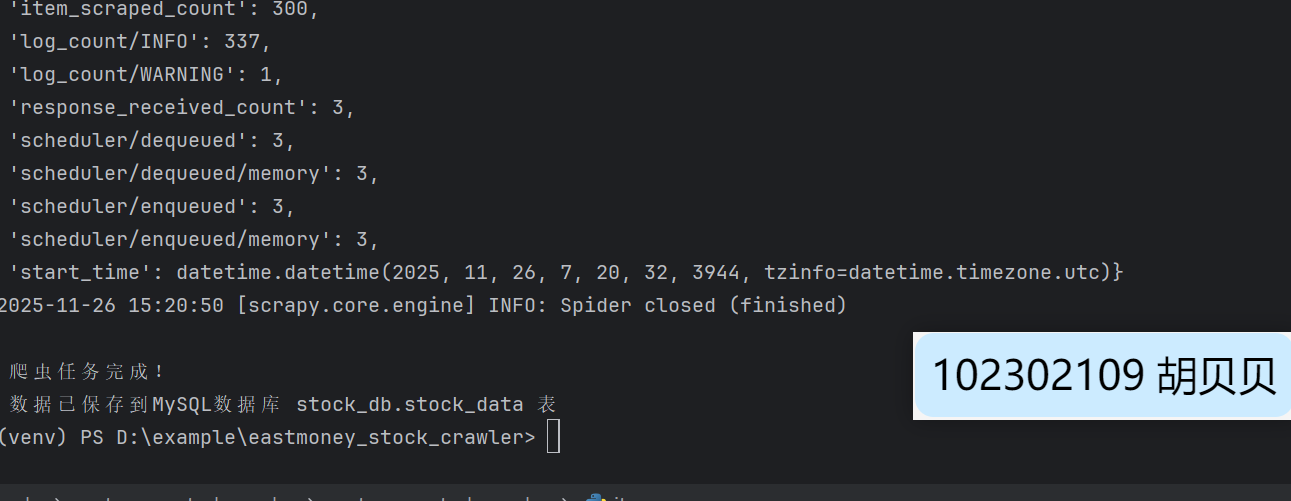
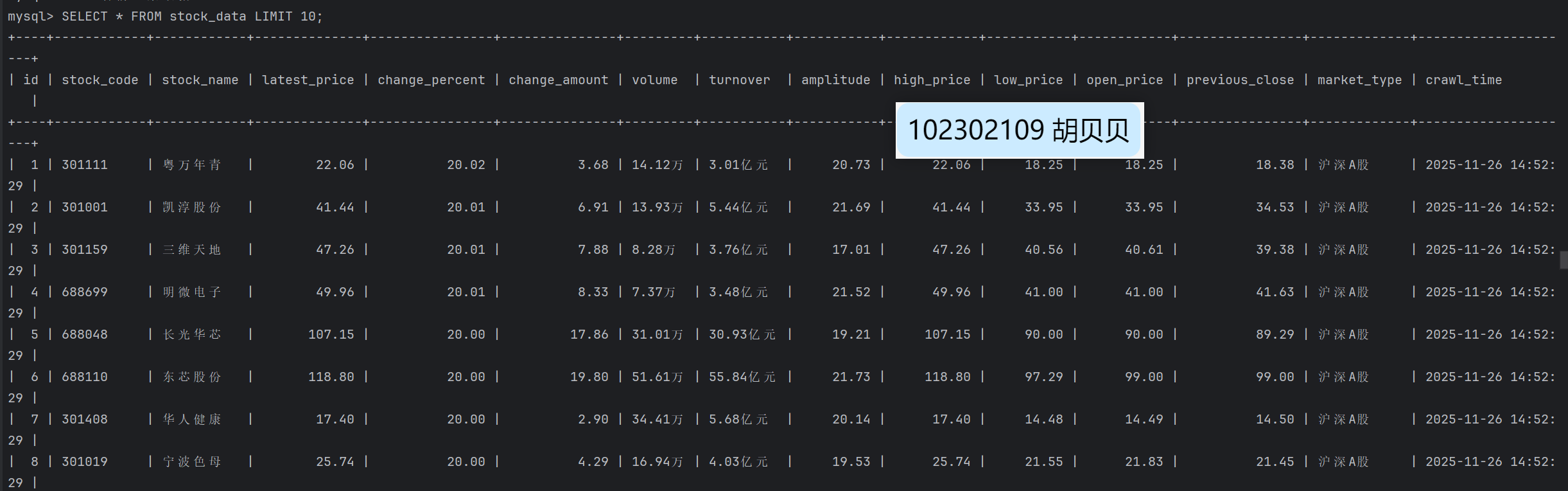
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/tree/master/102302109_胡贝贝_作业4/作业一
(2)实验心得
通过完成沪深A股数据爬取项目,我深入掌握了Selenium在动态网页数据抓取中的应用技巧,特别是对Ajax加载内容的处理和元素等待机制。在数据存储环节,通过设计合理的MySQL表结构和字段映射关系,不仅实现了数据的有效存储,还加深了对数据库设计与Python交互的理解。
作业②:
(1)实验内容及结果
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
核心代码:
def extract_course_info(self, url, expected_school, expected_name, expected_teacher):
"""提取课程信息"""
print(f"\n访问: {url}")
try:
self.driver.get(url)
time.sleep(3)
# 获取页面标题
title = self.driver.title
# 清理课程名称
if expected_name:
course_name = expected_name
else:
course_name = title.split('_')[0] if '_' in title else title
course_name = self.clean_text(course_name)
# 获取学校名称
school_name = expected_school
# 获取教师名称
teacher_name = expected_teacher
# 提取参与人数
participants = 0
try:
# 尝试多种方式查找参与人数
body_text = self.driver.find_element(By.TAG_NAME, 'body').text
# 多种人数匹配模式
patterns = [
r'(\d{1,3}(?:,\d{3})*)\s*人选课',
r'(\d+)\s*人参加',
r'已有\s*(\d+)\s*人',
r'(\d+)\s*位同学',
r'选课人数[::]\s*(\d+)',
r'(\d+)\s*人学习'
]
for pattern in patterns:
match = re.search(pattern, body_text)
if match:
num_str = match.group(1).replace(',', '')
try:
participants = int(num_str)
if participants > 0:
break
except:
continue
except:
participants = 0
# 提取课程简介
course_brief = "暂无简介"
try:
# 查找描述元素
selectors = [
'meta[name="description"]',
'.course-description',
'.m-course-desc',
'.course-summary'
]
for selector in selectors:
try:
if selector == 'meta[name="description"]':
element = self.driver.find_element(By.CSS_SELECTOR, selector)
text = element.get_attribute('content')
else:
element = self.driver.find_element(By.CSS_SELECTOR, selector)
text = element.text
if text and len(text) > 30:
course_brief = self.clean_text(text)[:300]
break
except:
continue
# 如果还没找到,从页面提取
if course_brief == "暂无简介":
body_text = self.driver.find_element(By.TAG_NAME, 'body').text[:1000]
# 找到相对较长的描述性段落
lines = body_text.split('\n')
for line in lines:
line_clean = self.clean_text(line)
if 50 < len(line_clean) < 200 and any(word in line_clean for word in ['课程', '学习', '教学', '简介']):
course_brief = line_clean[:300]
break
except:
course_brief = "暂无简介"
# 构建课程信息
course_info = {
'course_name': course_name,
'college_name': school_name,
'main_teacher': teacher_name,
'participants': participants,
'course_brief': course_brief,
'course_url': url,
'team_members': ''
}
print(f"课程名称: {course_name}")
print(f"学校名称: {school_name}")
print(f"主讲教师: {teacher_name}")
print(f"参与人数: {participants}")
print(f"课程简介: {course_brief[:50]}...")
return course_info
except Exception as e:
print(f"提取失败: {e}")
import traceback
traceback.print_exc()
return None
输出信息:
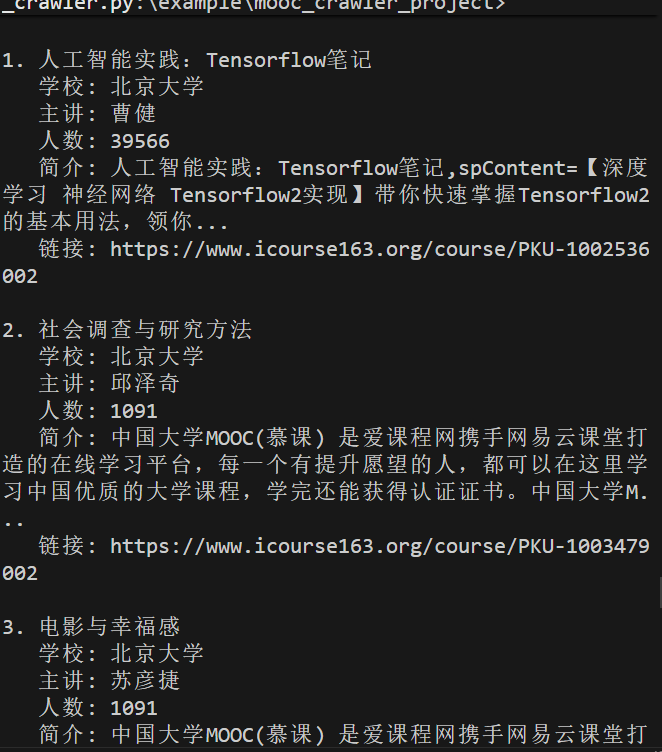
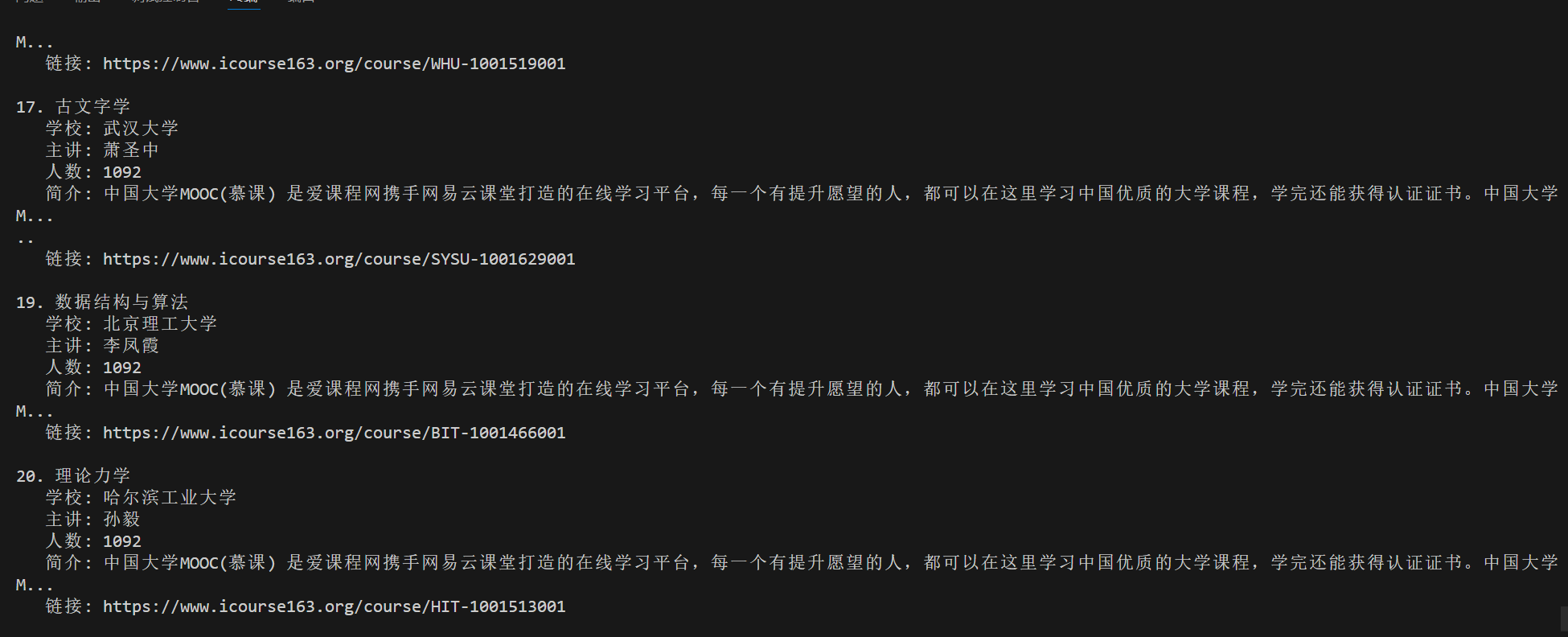
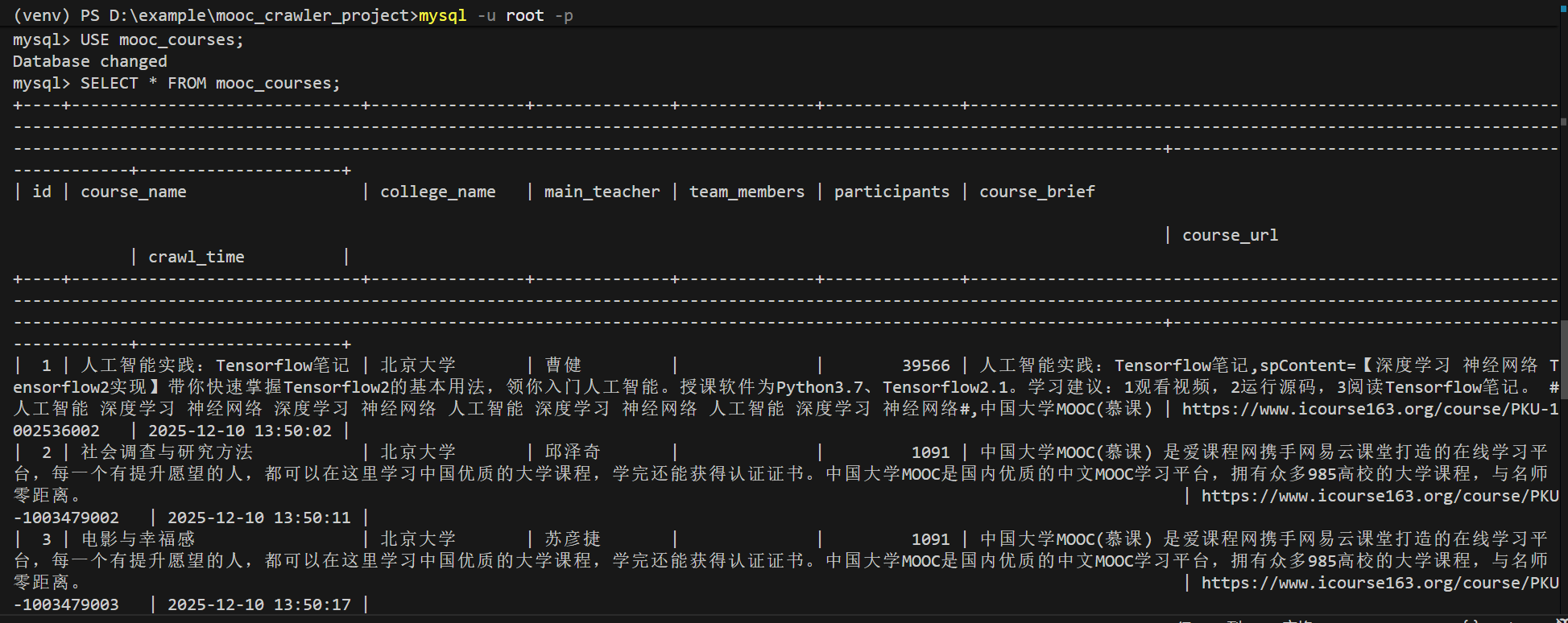
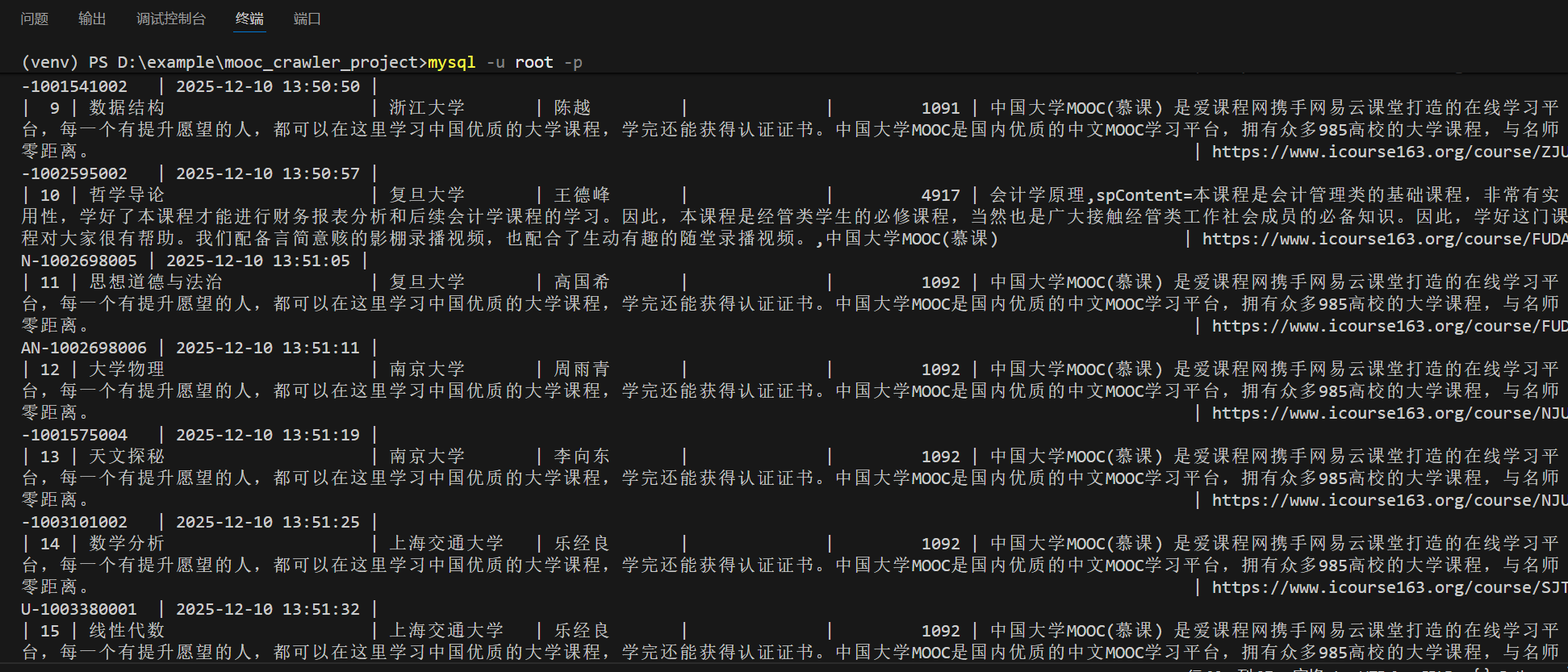
Gitee文件夹链接:https://gitee.com/hu_beibei/data-collection-practice/tree/master/102302109_胡贝贝_作业4/作业二
(2)实验心得
中国MOOC网爬取项目让我全面体验了模拟登录和复杂页面结构的处理过程。在应对动态加载课程信息时,我学会了如何通过多维度定位策略确保数据抓取的准确性。通过将非结构化网页数据转化为规范的数据库记录,我提升了数据清洗和格式转换的能力,也深刻体会到用户模拟技术在反爬策略应对中的重要性。
作业③:
(1)实验内容及结果
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
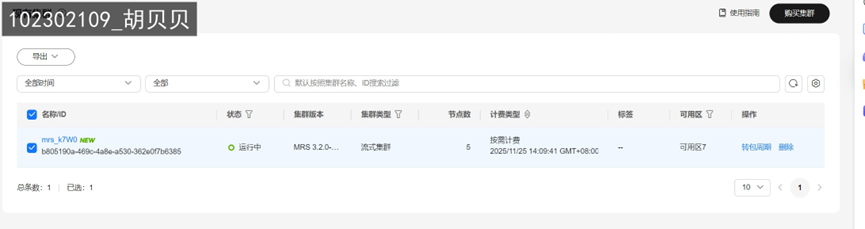
实时分析开发实战:
任务一:Python脚本生成测试数据
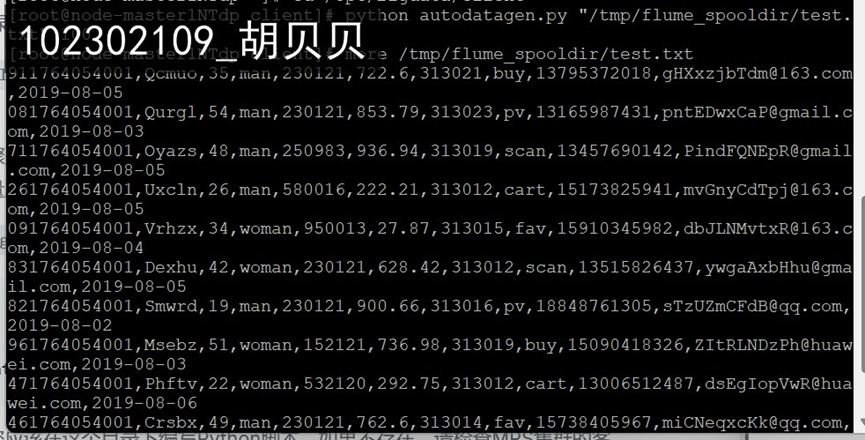
任务二:配置Kafka

任务三: 安装Flume客户端

任务四:配置Flume采集数据
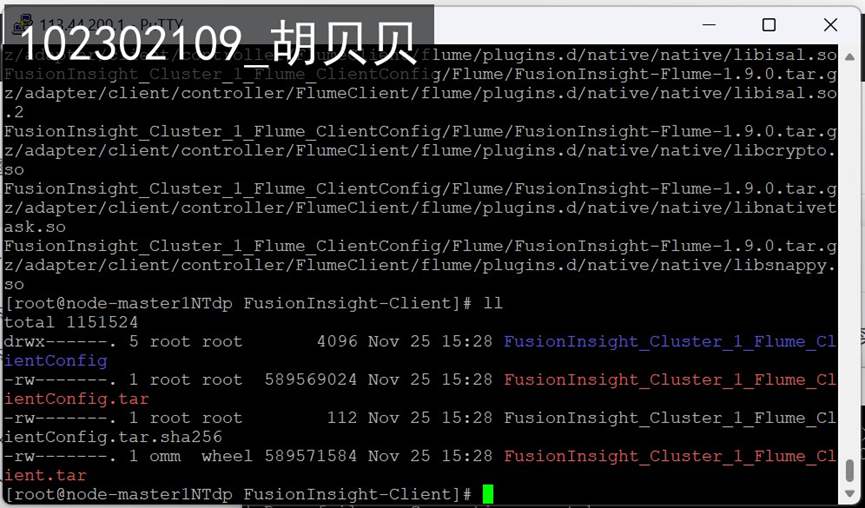
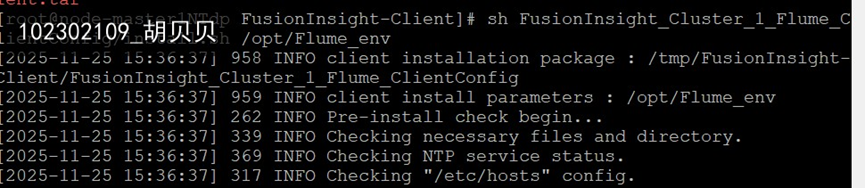
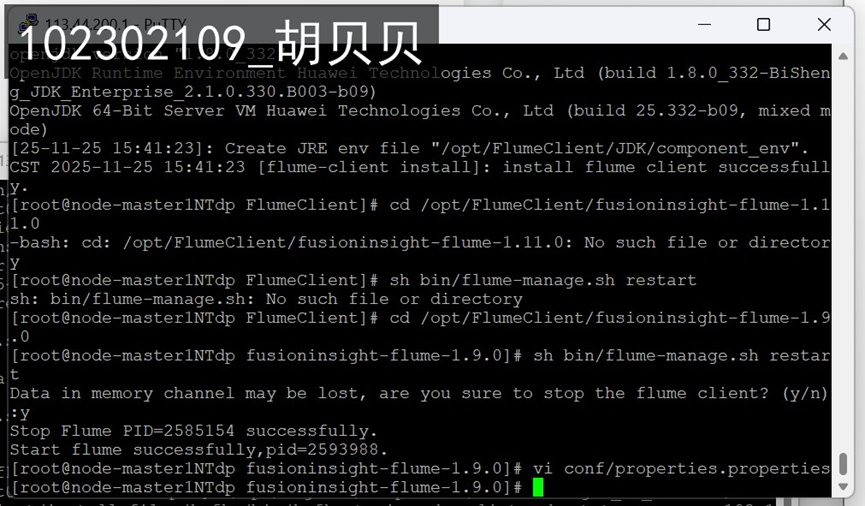
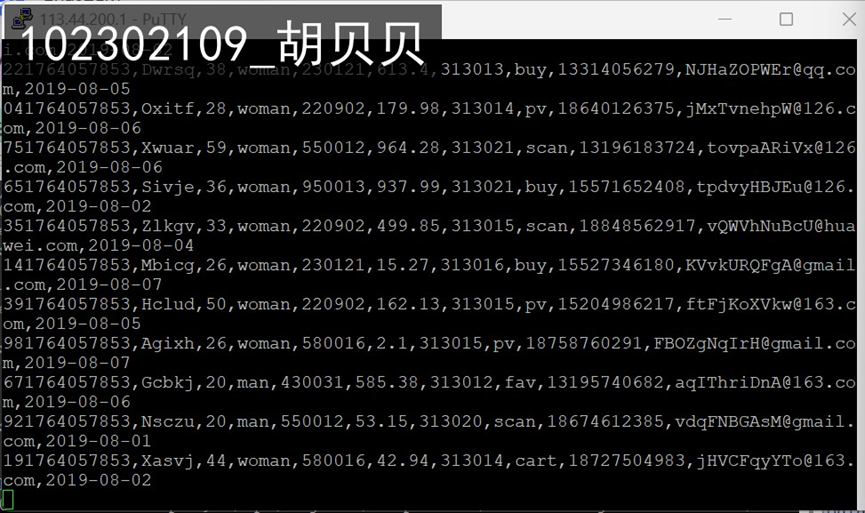
(2)实验心得
Flume日志采集实验让我首次接触完整的大数据采集流水线。从云端环境搭建到多组件协调配置,我理解了分布式系统中各服务组件的角色定位和协作原理。通过亲手部署数据生成、传输和采集的完整链路,我对实时数据处理架构有了直观认识,这种从编码到运维的全流程实践极大拓展了我的技术视野。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号