
102302109_胡贝贝_作业1
作业①:
(1)实验内容及结果
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
代码链接:https://gitee.com/hu_beibei/data-collection-practice/blob/master/102302109_胡贝贝_作业1/blog1.py
运行截图:

(2)实验心得
通过本次实验,我学习了如何使用 requests 获取网页源码,并用 BeautifulSoup 解析结构化数据。掌握了标签定位与信息提取的方法,成功爬取了大学排名、学校名称、城市和总分等信息,进一步理解了网页数据采集的基本流程。
作业②:
(1)实验内容及结果
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码链接:https://gitee.com/hu_beibei/data-collection-practice/blob/master/102302109_胡贝贝_作业1/blog2.py
运行截图:

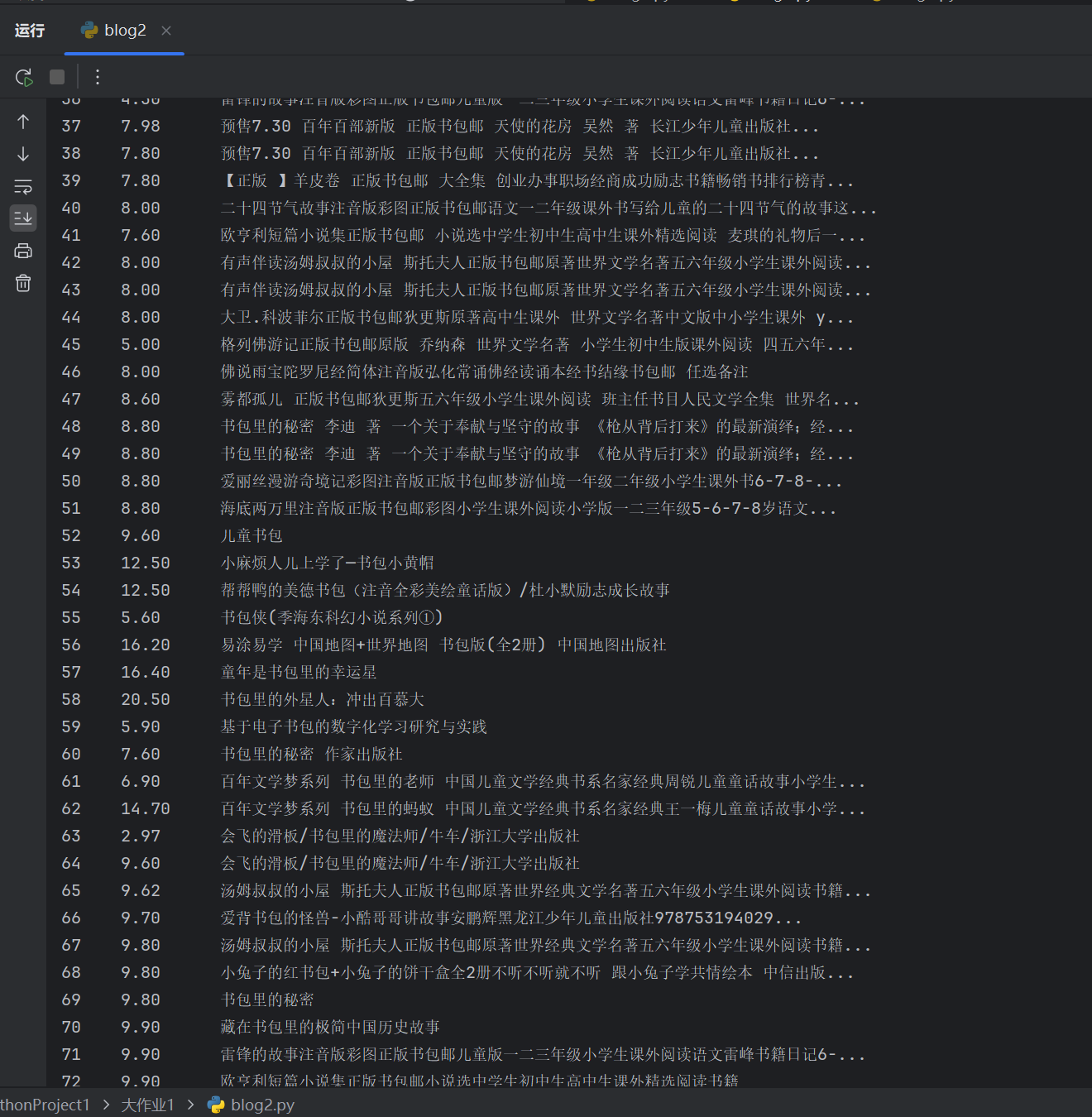
(2)实验心得
本次作业让我掌握了用 requests 和 re 库进行网页信息抓取的技巧。通过正则表达式提取商品名称和价格,加深了对网页文本结构和数据模式匹配的理解,也体会到处理动态网页时需要分析网页加载机制的重要性。
作业③:
(1)实验内容及结果
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
代码链接:https://gitee.com/hu_beibei/data-collection-practice/blob/master/102302109_胡贝贝_作业1/blog3.py
运行截图:


(2)实验心得
在本次图片爬取实验中,我学会了如何利用 requests 请求网页并用正则表达式筛选图片链接。通过批量下载并保存 JPG、JPEG、PNG 文件,掌握了网络文件的下载与本地保存方法,提升了综合编程与实践能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号