

带你读AI论文丨ACGAN-动漫头像生成
摘要:ACGAN-动漫头像生成是一个十分优秀的开源项目。
本文分享自华为云社区《【云驻共创】AI论文精读会:ACGAN-动漫头像生成》,作者:SpiderMan。
1.论文及算法介绍
1.1基本信息
• 论文题目:《Conditional Image Synthesis With Auxiliary Classifier GANs》
• 出处:ICML 2017
• 作者:Augustus Odena、Christopher Olah、Jonathon Shlens
1.2研究背景
GAN(Generative Adversarial Network)是由两个彼此对立训练的神经网络组成。生成器G以随机噪声向量z作为输入然后输出-张图像G(z),判别器D接收训练图像或者是来自生成器的合成图像作为输入,输出在可能数据源上的条件概率分布D(x),他需要分别出真实的数据来源或者是生成的数据来源。
使用标签的数据集应用于生成对抗网络可以增强现有的生成模型,并形成两种优化思路。
• cGAN使用了辅助的标签信息来增强原始GAN,对生成器和判别器都使用标签数据进行训练,从而实现模型具备产生特定条件数据的能力。
• SGAN的结构利用辅助标签信息(少量标签),利用判别器或者分类器的末端重建标签信息。
ACGAN则是结合以上两种思路对GAN进行优化。
1.3算法介绍
1.3.1 ACGAN模型结构
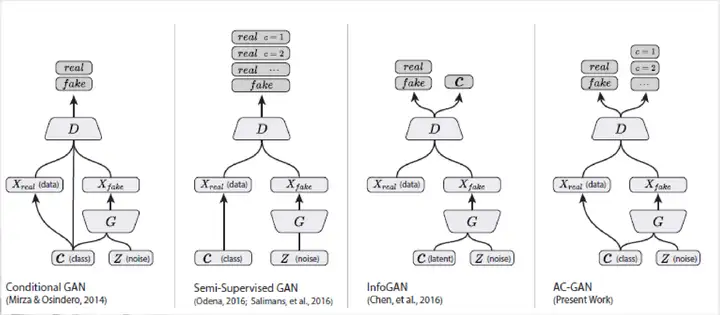
1.3.2损失函数
• Ls是面向数据真实与否的代价函数。
• Lc则是数据分类准确性的代价函数。
在优化过程中希望判别器D能否使得Ls+Lc尽可能最大,而生成器G使得Lc-Ls尽可能最大。
简而言之是希望判别器能够尽可能区分真实数据和生成数据并且能有效对数据进行分类,对生成器来说希望生成数据被尽可能认为是真实数据且数据都能够被有效分类。
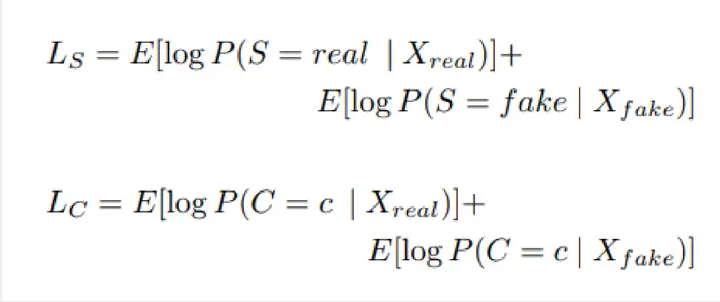
1.3.3高分辨率
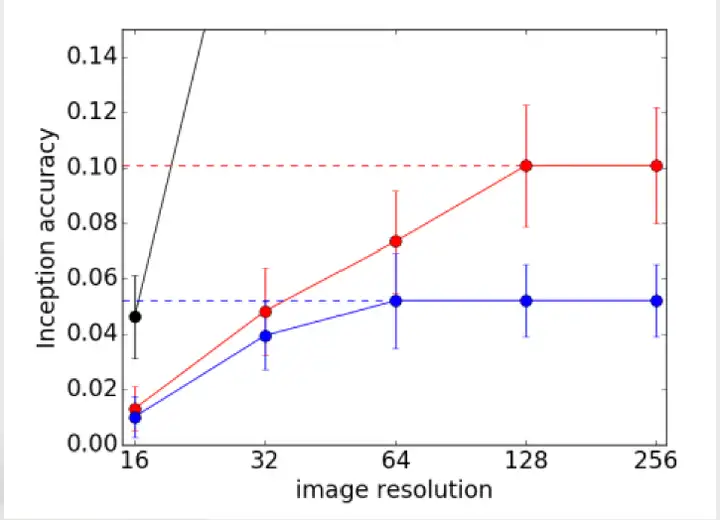
如何评价一个生成模型生成图片的分辨率,最简单的方法无非就是直观用眼睛来看,但这样显然无法量化一个图片的好坏,于是作者提出使用一个分类器,若生成的图片具有较高的分类正确率,就有理由认为生成的图片质量比较高,也即该图片具有较高的可分辨性,如上所述,生成高分辨率的图片,需要不是简单的将低分辨率的图片进行线性插值来生成,因而要量化的分析生成的图片的质量,可以从其分辨力。
从低分辨率通过插值生成的高分辨率图片,其本质上没有增加多余信息,只是低分辨率的模糊版。结合这样的思路,高分辨率的图片提供了更多的信息,这些信息结合到AC-GAN结构,每个生成图片都有其对应的标签,因而这个更多的信息,可以通过分类来表明,也就是说更多的信息,可以用于分类,也就是文中所说的分辨力。
因此,ACGAN提出Inception Accuracy,这种新的用于评判图像合成模型的标准,查看其被分类为正确类别的比率,以此来判定生成的图片质量。图中,最上面给出了真实图片和基于ACGAN生成图片,可以明显感觉图片高分辨率对应高可分辨性。

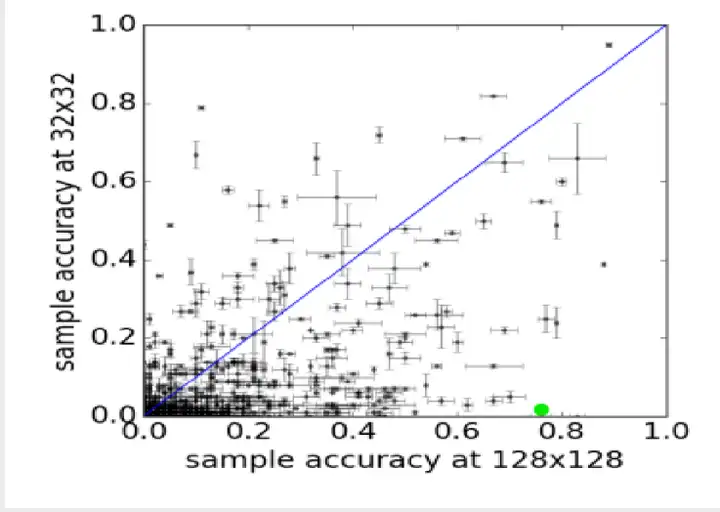
1.3.4图像多样性
GAN有个最常见的问题就是模式坍塌的问题,就是模型找到一种方式,无论输入的内容是什么,生成的图片都只有一种,然而这种图片能大概率欺骗过分辨器。因而,产生的图片具有多样性,也是可以评估GAN模型好坏的指标。
文中采用了图片的多尺度结构相似度来衡量图片与图片之间的相似度(multi-scale structural similarity,MS-SSIM),这个相似度在0和1之间取值,越大说明图片之间越相似;提及MS-SSIM的时候,往往也要提及SSIM,来看看它们具体是怎么计算的。
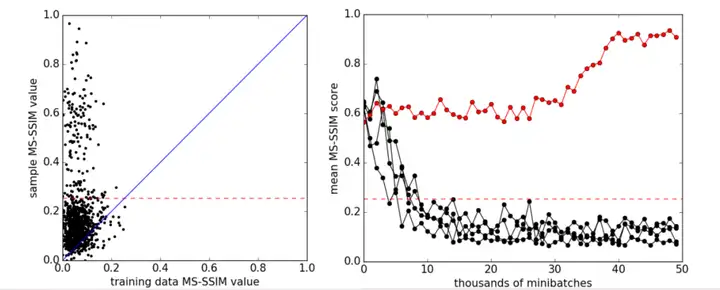
1.3.5 ACGAN分析
ACGAN分析是否通过记忆样本合成图像。

1.3.6 ModelArts介绍
ModelArts 是面向开发者的一站式AI开发平台,为机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。下图就是ModelArts的能力图:
2.代码移植ModelArts
2.1 ModelArts简介
ModelArts是面向AI开发者的一站式开发平台,提供海量数据预处理及半自动化标注、大规模分布式训练、自动化模型生成及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。
“一站式”是指AI开发的各个环节,包括数据处理、模型训练、模型部署都可以在ModelArts上完成。从技术上看,ModelArts底层支持各种异构计算资源,开发者可以根据需要灵活选择使用,而不需要关心底层的技术。同时,ModelArts支持Tensorflow、PyTorch、MindSpore等主流开源的AI开发框架,也支持开发者使用自研的算法框架,匹配用户的使用习惯。
ModelArts的理念就是让AI开发变得更简单、更方便。面向不同经验的AI开发者,提供便捷易用的使用流程。例如:
- 面向业务开发者,不需关注模型或编码,可使用自动学习流程快速构建AI应用;
- 面向AI初学者,不需关注模型开发,使用预置算法构建AI应用;
- 面向AI工程师,提供多种开发环境,多种操作流程和模式,方便开发者编码扩展,快速构建模型及应用。
2.1.1 ModelArts特点
• 自动学习;
• 数据管理;
• 开发环境;
• 算法、训练、模型、部署。
2.1.2 Notebook开发环境
2.2 ACGAN-动漫头像生成
使用的数据集64*64的动漫头像,共36740张。
数据可以存放在对象存储服务(Object Storage Service, OBS)。

2.3 代码讲解
2.3.1输入
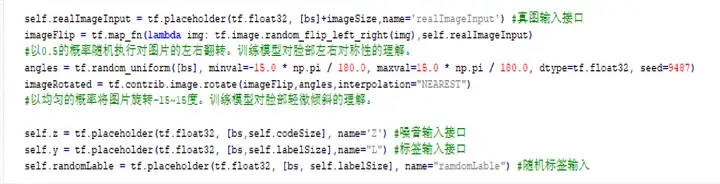
2.3.2判别器
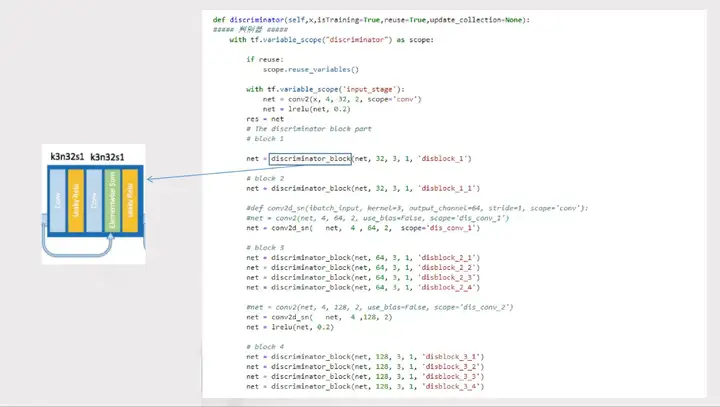
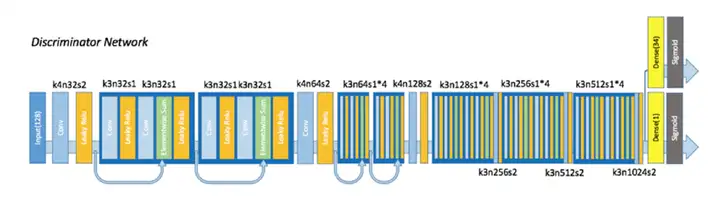
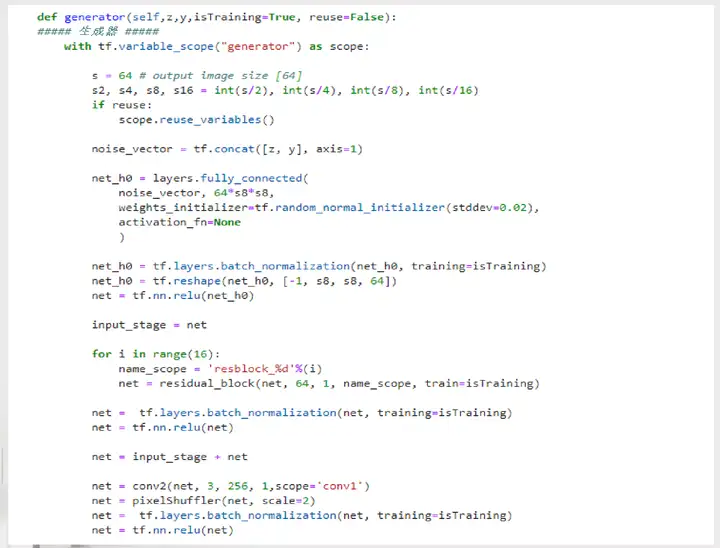
2.3.3生成器
2.3.4 PixelShuffle
主要实现了这样的功能:N*(C* r* r)*W*H——>>N*C*(H*r)*(W*r)。
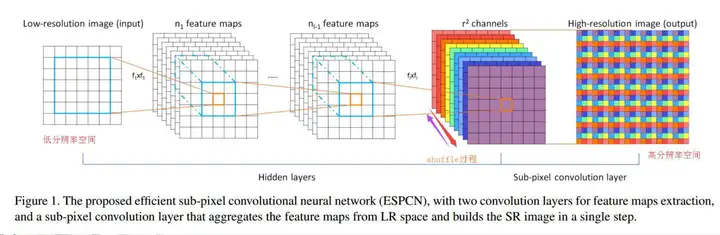
2.3.5损失函数
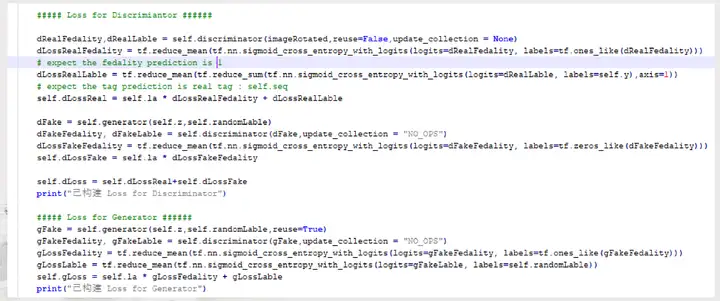
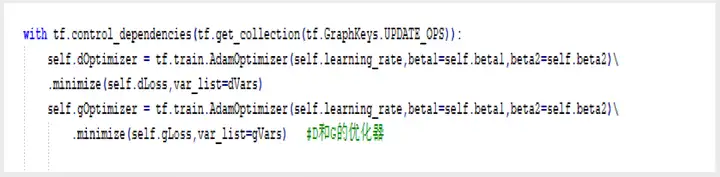
2.3.6优化器
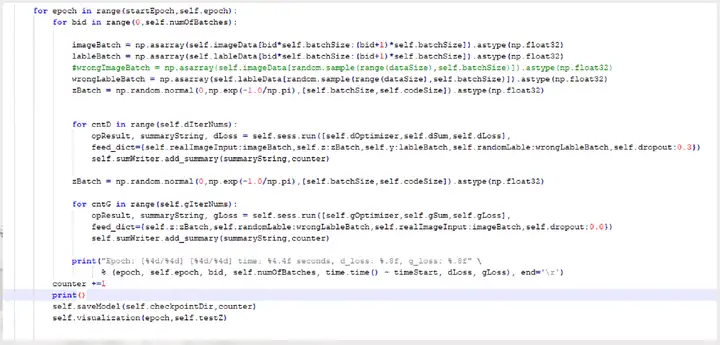
2.3.7训练
2.3.8模型预测

2.4查看效果

2.5后期优化方向
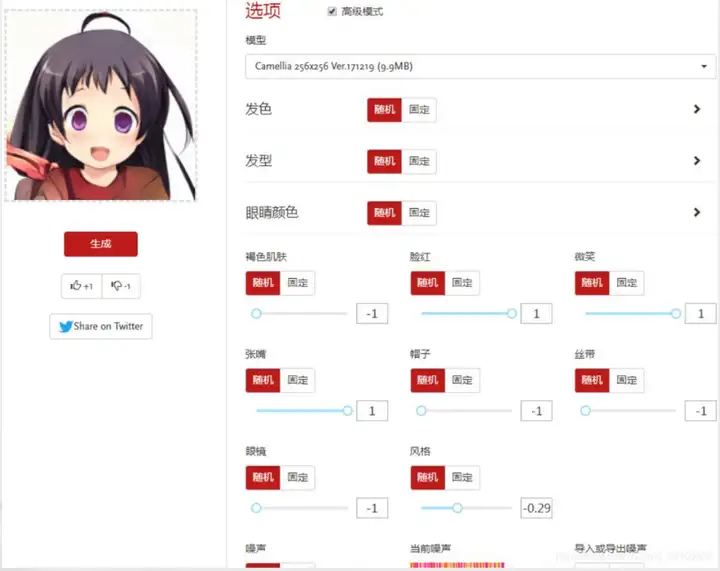
2.6参考网址/体验网址
参考网址:
https://blog.csdn.net/forlogen/article/details/93852960
https://blog.csdn.net/qq_24477135/article/details/85758496
https://www.cnblogs.com/punkcure/p/7873566.html
https://www.zjusct.io/2019/06/16/Animation%20Avatar%20Generation/
https://blog.csdn.net/u014636245/article/details/98071626
体验网址:
GitHub网址: https://github.com/makegirlsmoe/makegirlsmoe_web
在线体验: https://make.girls.moe/#/
3.总结
ACGAN-动漫头像生成是一个十分优秀的开源项目,针对已有的动漫人物头像生成方法中生成结果的多样性较差,且难以准确地按照用户想法按类生成或按局部细节生成的问题,基于含辅助分类器的对抗生成网络(ACGAN),结合互信息理论、多尺度判别等方法,最终用于动漫人物头像的生成。
此项目在生成图像的过程中使得生成的图像更接近于样本集,这样在显得更真实的同时又不发生模式崩塌;但是如何人为定义连续标签以控制细节,而不是通过模型自学习产生仍是值得继续研究的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号