
保姆级带你深入阅读NAS-BERT
摘要:本文用权重共享的one-shot的NAS方式对BERT做NAS搜索。
本文分享自华为云社区《[NAS论文][Transformer][预训练模型]精读NAS-BERT》,作者:苏道 。
NAS-BERT: Task-Agnostic and Adaptive-Size BERT Compression with Neural Architecture Search
简介:
论文代码没有开源,但是论文写得挺清晰,应该可以手工实现。BERT参数量太多推理太慢(虽然已经支持用tensorRT8.X取得不错的推理效果,BERT-Large推理仅需1.2毫秒),但是精益求精一直是科研人员的追求,所以本文用权重共享的one-shot的NAS方式对BERT做NAS搜索。
涉及到的方法包括 block-wise search, progressive shrinking,and performance approximation
讲解:
1、搜索空间定义
搜索空间的ops包括深度可分离卷积的卷积核大小[3/5/7],Hidden size大小【128/192/256/384/512】MHA的head数[2/3/4/6/8],FNN[512/768/1021/1536/2048]、和identity 连接,也就是跳层了,一共26个op,具体可见下图:
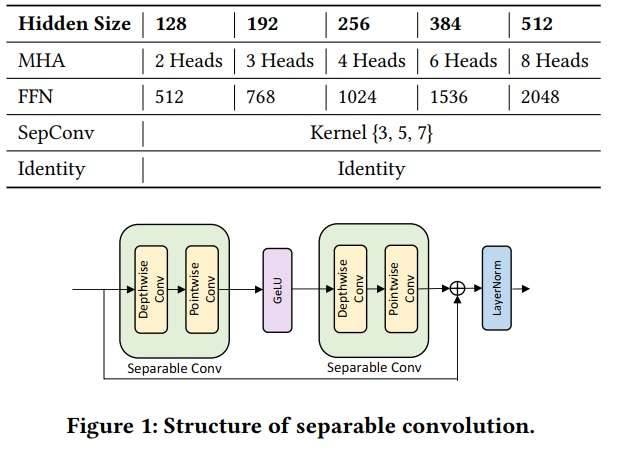
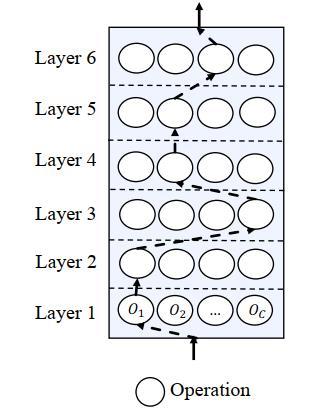
注意这里的MHA和FNN是二选一的关系,但是可以比如说第一层选MHA第二层选FNN,这样构成一个基本的Transformer块,可以说这个方法打破的定式的Transformer块的搜索又包含了Transformer和BERT的结构,不同层间也是链式链接,每层只选择一个op,如下图
2、超网络的训练方式
【 Block-Wise Training + Knowledge Distillation、分块训练+KD蒸馏】
(1)首先把超网络等分成N个Blocks
(2)以原始的BERT作为Teacher模型,BERT也同样分为N个Blocks
(3)超网络(Student)中第n个块的输入是teacher模型第n-1个块的输出,来和teacher模型的第n个块的输出做均方差来作为loss,来预测teacher模型中这第n个block的输出
(4)超网络的训练是单架构随机采样训练
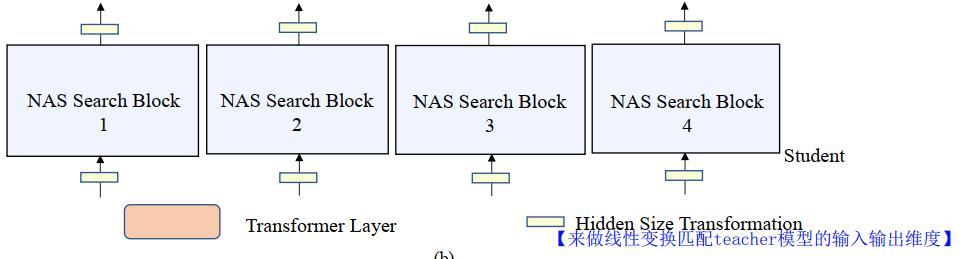
(5)由于student 块的隐藏大小可能与teacher块中的hidden size不同,能直接利用教师块隐藏的输入,和输出作为学生块的训练数据。为了解决这个问题,需要在学生块的输入和输出处使用一个可学习的线性变换层来转换每个hidden size,以匹配教师块的大小,如下图所示
【 Progressive Shrinking】
搜索空间太大,超网络需要有效的训练,可以借助Progressive Shrinking的方式来加速训练和提高搜索效率,以下简称为PS。但是不能简单粗暴的剔除架构,因为大架构再训练初期难收敛,效果不好,但是并不能代表其表征能力差,所以本文设置了一个PS规则:
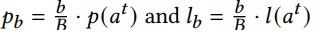
其含义,a^t表示超网络中最大的架构,p(▪)表示参数量大小,l(▪)表示latency大小,B表示设置B个区间桶,b表示当前为第几个区间。如果一个架构a不满足p_b>p(a)>pb_1并且l_b>l(a)>l_b-1这个区间,就剔除。
PS的过程就是从每个B桶中抽E个架构,过验证集,剔除R个最大loss的架构,重复这个过程直到只有m个架构在每个桶中
3、Model Selection
建一个表,包括 latency 、loss、 参数量 和结构编码,其中loss和latency是预测评估的方法,评估方法具体可以看论文,对于给定的模型大小和推理延迟约束条件,从满足参数和延迟约束的表中选择最低loss的T个架构,然后把这个T个架构过验证集,选取最好的那个。
实验结果
1、和原始BERT相比在 GLUE Datasets上都有一定的提升:
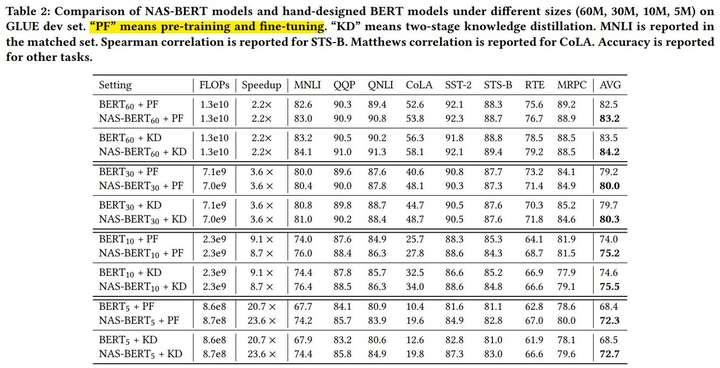
2、和其他变种BERT相比效果也不错:
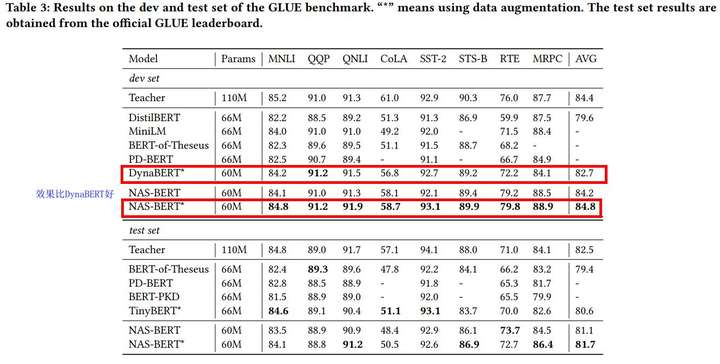
消融实验
1、PS是否有效?
如果不用PS方法,需要巨大的验证上的时间(5min vs 50hours),并且超网络训练更难收敛,影响架构排序:
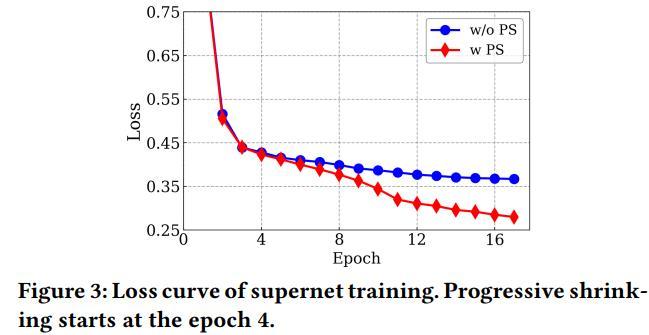
2、是PS架构还是PS掉node
结论是PS掉node太过粗暴,效果不好:

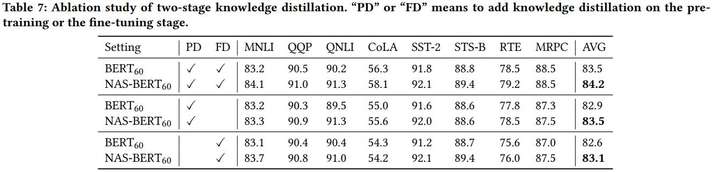
3、二阶段蒸馏是否有必有?
本文蒸馏探究了预训练阶段和finetune阶段,也就是pre-train KD 和 finetune KD,结论是:
1、预训练蒸馏效果比finetune时候蒸馏好
2、两阶段一起蒸馏效果最好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号