

华为鲲鹏专家解读:90%代码如何移植到鲲鹏平台
摘要:探讨一下软件移植到鲲鹏平台过程的原理,以及软件工程的相应的过程。
Linux环境下跨平台软件移植过程中,需要开发者阅读代码、手工修改、反复编译和调试,移植周期长,效率低,那么如何改进周期长,效率低的问题呢?
基于此,来自华为智能计算专家张汝涛带来了“90%代码如何实现自动移植到鲲鹏平台”的主题分享活动,他主要从鲲鹏开发套件实现基于C/C++软件的高效代码移植,加速开发者实现跨平台软件移植两个层面进行分享。以下分享的速记内容:
今天要讲的主题是关于软件迁移这一件事,是一个久远的话题。因为但凡是牵扯到切换平台、CPU架构的变化,甚至一些语言版本的升级,我们都可能会面临到一些软件迁移的问题。今天一起来探讨一下软件移植过程的原理,以及软件工程的相应的过程。
鲲鹏在软件移植的过程当中,如何去帮助开发者去提升效率,如何把鲲鹏沉淀下来的,把华为沉淀下来的软件开发以及一致的经验如何反馈到开发者,让开发者能够加速软件开发的进度,降低成本。我们推出我们鲲鹏的开发套件,帮助用户做软件的移植,以及做基于鲲鹏平台的性能加速,今天主要是这样三个内容。

一提到软件移植,我不知道大家有多少是做了比较底层软件的,做底层软件的话,大家可能会用到一些汇编,C++加这样的底层语言。用到这种底层语言,它是会和机器的硬件架构强相关的,当你在从一个平台切换到另外一个平台的时候,这些强相关的语言势必要进行一次,跟我们所采用的编程语言以及移植的平台环境强相关。
当我们用汇编代码或者是用这种编译型语言的时候,我们就会面临着一些移植的问题、一些挑战。有些问题可通过编译器能解决,有些问题特别是一些低阶的代码或者底层的代码,我们就会可能要面临着必须要手工去查手册,然后去把它相应的去转换到新平台所使用的机器码。
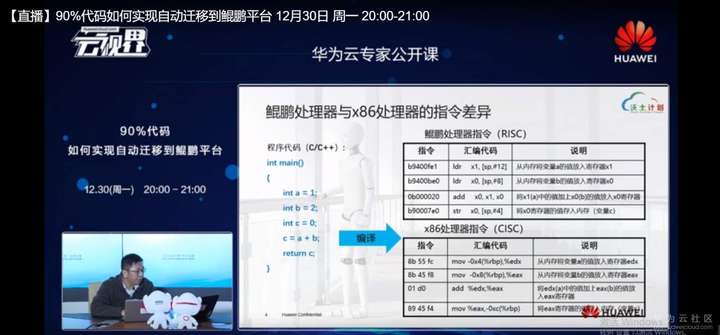
这里就列出我们鲲鹏处理器和x86处理器的一个指令差异,例如一个简单的两个数相加,两个int型相加的这样一个简单程序。通过GCC编译完之后,我们去通过OMGD,我们就能看到指令的具体的格式形式以及相应的对应的汇编代码。这里能看到对x86平台而言,因为x86是CICS指令是复杂指令集,鲲鹏是完全兼容Arm64架构的,是华为自研的vinic,指令集也是和Arm64副精简指令集是完全兼容的。
其实所谓的经限指定集和复杂指令集的区分是从上个世纪的70年代开始的,IBM曾经做过一个研究,就是关于说CPU如何去高效的运行,然后他们会发现可能有些常用的指令或者是程序代码,当时背景下常用的程序代码,可能常用的和不常用的有很大的差异,当时又因为IC的制程或者工艺或者器件的设计水平没有现在这么突飞猛进,所以就会想如何去把CPU从硬件设计上简单一点,从软件上高效一点,所以他们就提出了精简指令集这么一个概念,其最大显著的特点就是它的指令宽度就是长度。我们说的指令长度,是相等的,也就说每一个指令这个位宽是相等的,那么每个指令执行的SICO几乎也相同,就是他把很繁杂的事情做的尽可能的简单,然后用很多简单的操作去完成一件复杂的任务。
从相反的复杂指令集的角度,我们看一下x86下面的复杂指令级,它每一个指定的长度是不同的,也就是说像这里列举的mov和add这两个指令,它的机器码、指令码是不同的,长度是不同的,势必会造成我们IC器件的解码器,以及包括我们真正的到软件流水操作上处理的步骤是不一样的,也必然会导致我们每条指令的执行的周期是不同的,但是这样也有一个好处,就是我一个指令就能完成一个比较复杂的事情,尽管说我的指令可能会变得很长,但是我一条指令能完成一比较复杂的事情,对上层的程序员来讲,可能就便于理解或者是相对的会容易理解一些。
这就是精简指令集和复杂指令集的一个简单背景,在反汇编下来的x86指令集和鲲鹏指令集的汇编代码上,可以看到操作指令是完全不同的,计存器的命名也是完全不同的,在x86的平台上,有16个通用寄存器。这里讲的是x86 64模式下,有16个通用寄存器,浮点计存器,根据我们支持的MMX技术、SSE或者是ABS技术,x86平台最多可以存在32个浮点寄存器。
反观鲲鹏平台,因为它是和Arm64指令兼容的,所以指令集要事完全对照,所以从这个角度来讲,鲲鹏平台有31个通用寄存器,除了这31个通用寄存器以外,还有一些状态寄存器或者是一个站寄存器。那对应到浮点寄存器,就有32个这样一个叫做ASMB的的advances单指令多数据这样一个寄存器。鲲鹏有32个寄存器位,位宽是128。这一点是和x86 64平台是有差异的,比如说现在x8664,它如果支持ABX512的话,它的位宽是500 12比特,从这个角度上,是一个硬件器件差异是非常明显的。
然后从反汇编的角度来看,大家不知道有没有注意到x86平台上有一个mov指令。从第一行我们能看到从寄存器、rbp一个mov的存储数据,到EDX这样一个寄存器,做一个从把变量从内存里漏斗进来。同样的一件事情在上面的鲲鹏处理器平台上寄存器的指令就变成了LDR和然后下面当然加法还是有add的,然后存储的时候对于x86来讲,又是从寄存器mov到了内存力,但是对于鲲鹏平台它是用一个str指令,所以这也反映出了一个risk指令的特点,也许是第2个特点,我们姑且这么叫,它是用一个load stall这样一个模式,也就是说在鲲鹏处理器平台上不支持内存到内存的一个直接访问,必须要经过一个寄存器作为桥接作为一个中转。
这一点是和x86指令复杂型指令集不同的另外一个地方。还有就是在x86这个平台上,它的内存访问的模式非常多,对于公共平台上就没有丰富了。这个就是以一个程序为例,简单列举一下,从CPU的角度来看,同样是一段C代码,CPU他做了不同的事情,执行了不同的指令,经过不同的周期不同的运算以后,它会输出最终计算的一个结果。当然从这个角度来讲,从这段程序两个平台是没有任何差异的,除了指令上以外,执行结果是不会有任何变化。
但这里侧面反应出来,因为指令集不一样,所以对于C,C++这样偏底层的这样一个语言来讲,虽然它是个高级语言,但是必须要考虑一个平台差异,在平台切换的时候,甚至在平台这个软件的编制过程当中,就要考虑一个平台兼容性,所以要养成一个良好的编程习惯。

跨平台移植软件要面临的不少问题,因为软件移植本身就是一个工程性问题。这里通常第1步来讲,如果说我们决定从x86平台迁移到鲲鹏平台,就要去判断一下这个软件迁移值不值得,困难有多大?通常目前的常用的做法就是把x86的平台,相应的软件包拿下来,然后去看看它的依赖性关系。这个是什么意思呢?就是我们看看这个软件,如果跑在x86平台上,它依赖哪些第三方组件?这些第三方组件在你这个目标平台上存不存在要做一些这样的判断。这种判断通常都是这个平台之间的反反复复的安装、运行,然后根据系统报出来的错误去一个个来排除,所以这都是通过人工来完成的,比较费劲。如果有移植经验的同学就会觉得比较费劲,有些事情很繁琐琐碎,一个不小心就错了,可能还找不出来原因。
当你解决完第1步编译的过程的这个问题之后,你可能会还碰到一些跑过,结果新平台上出现了function fault,功能性错误我们就很讨厌了,可能性原因比较多,有的是本身软件逻辑有问题;可能是第三方组件的APA跨平台兼容性有问题;可能是系统本身支持度也有问题,这个就是影响因素比较多。这样就需要移植之后,技术人员去相应定位。定位对每个人对相应的工程人员来讲,专业技术要求会比较高,也存在着一个反复编译、反复调整、反复验证,这个过程成本会很高。
当完成了功能验证之后,跑过一些基本测试以后,感觉这个软件在新平台上可以刊用了。你可能会面临的一个性能的问题,当你用在工作环境、生产环境的情况下,因为生产环境的软件都希望用最小的硬件跑出最大的性能,然后跑出最高的一个性价比,这时候都会对软件性能上的需求,对它有要求。这个时候我们就会不得不去采取一些方法,例如用一些商业软件也好,或者一些开源的软件命令也好,去分析这个软件的瓶颈到底是哪里有问题,是系统有配置的参数有问题,还是我软件本身逻辑有问题。
所以这三步是我们在华为的软件这么多年的开发过程当中积累下来觉得比较重要的三步,对我们软件的质量、移植的质量是有决定性影响的。这三步也同时对于任何人来讲,可能都不是一个能轻松逾越的几个障碍。
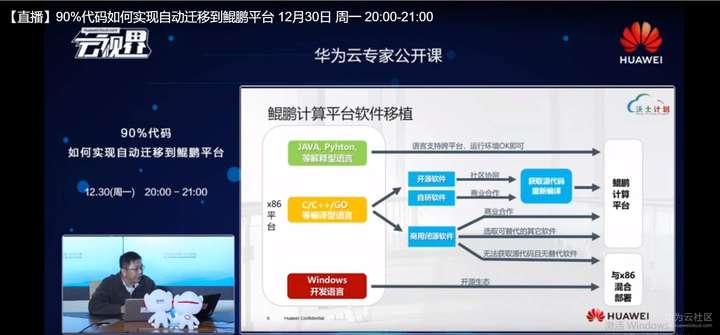
对于我们软件移植这件事情,通常我们讲的是对于编译型软件会面临这样的一个困难,对于解释性反而比较轻松,为什么?比如像我们现在常用的一些Java的或者Python的,甚至一些GOD这样一些软件,我们的依赖是什么?依赖的是语言所提供的虚拟运行环境,甚至是一些像Java提供的Java虚拟机GUM,我们只需要选一相应平台的GUM安装,我们就能把底层的所有差异性都屏蔽掉。
这个软件只根据运行环境去跑,通常是没有问题的。对于像C,C++,GOD这种的,可能作为编译,甚至说可能会调用C,C++加这种组件的这种软件,我们就需要C,C++这种代码进行移植,可以分这么几种情况。
第1种是开源软件,对我们通常是和社区进行合作,让社区去支持空洞平台,或者是支持M64的平台,这样我们就一劳永逸的解决问题。然后对于自研软件,对于有些SB用户会开发者资源软件,他不能开放代码,我们就需要进行商业合作,去引导客户去移植到我们鲲鹏平台上。
对于商业B软件是最典型的,比如说像微软的一系列软件,或者是Oracle的软件数据库,我们不可能去获得源码,去推动他们和我们中国的软件界合作也非易事.这个时候你只能找到要么是合作,要么就是找一个替代方案,对吧?如果实在是又不能替换用户的业务,又不能去修改,我们就可能不得已采取一个鲲鹏平台和x86进行一些混合部署,这是一个软件部署方面的策略。
还有一种就是对于我们常用的windows平台的一种系列开发,我们也知道windows虽然一年多前可能说要支持Arm64这个架构,但实际上到现在为止他也没有宣布。其实商业上的考虑或者是其他的因素可能都考虑的比较多,尤其是这样一个大体量的公司,但是对于windows平台就是说我们进行有限度的在开元生态里面进行有限度的支持,比如说像微软的C shut,其实他的call3.0已经开源了,已经在Arm平台上能够用起来了。换句话来讲,我们也可以在鲲鹏平台上基于call3.0支持C shut。对于鲲鹏软件移植的过程,可以把它分解为这样几个步骤流程,其中最重要的就是所列到的第2步第3步以及性能达标分析这一步,我们现在提供了相应的每一步提供一些的辅助工具去帮助客户进行用户开发者进行分析进行移植。
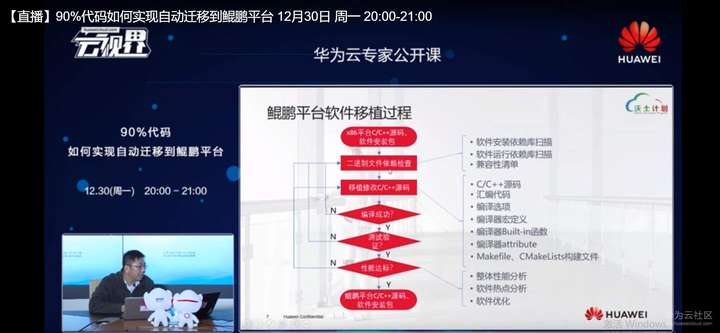
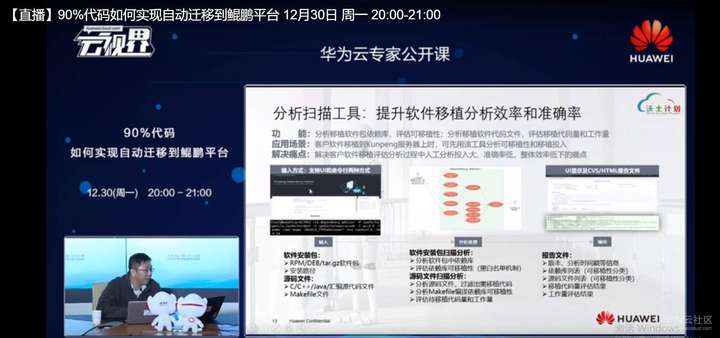
其中的二进制文件依赖扫描,是我们去提供了一个工序软件进行软件安装、依赖库的扫描和软件运行依赖库的扫描。根据我们长期积累的有一个兼容性清单,这个兼容性清单覆盖了市面上大多数流行的以及常用的OS以及相应的版本,还有相应的GCC的版本,对于移植的第二阶段,像移植修改C,C++原码,我们也同样提供了一款工具去做C,C++源码的分析,这个分析主要是集中在这样几个方面,集中在汇编代码、边选项,还有宏定义,还有built in函数和编辑提供的built in函数和attribute,然后去重点检查用户的Makefile和CMakeList。如果用户软件是用make构建的或者CMake构建的,我们能帮助去发现一些,识别一些移植中需要修改的地方,同时我们会给出移植修改的建议。
当移植完成之后,我们会提供一个性能分析的工具,去帮助用户去check这个软件是不是能够达到工作这样一个标准,也就是说check它的性能指标,我们会去进行系统性的性能分析,也会去做软件级的热点定位分析。然后在此基础上我们会给用户提供一些华为所积累下来的认为比较有效的一些软件优化的方法,做一些比如说终端版壳操作,甚至一些其他的软件修改的这样建议,这个就是我们今天要介绍的三款软件,通过这三款软件我们就能比较方便的或者比较高效率的完成C,C++代码,从非鲲鹏平台向鲲鹏平台的这样一个迁移值的过程。
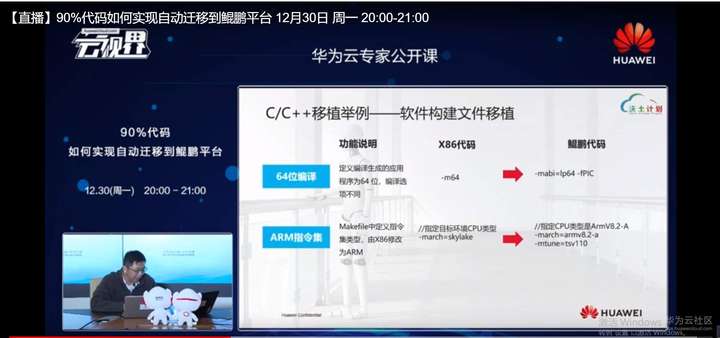
在C,C++软件移植的过程当中,我们要着重考虑三个方面的问题,第1个问题是软件构建文件的差异。这里面举两个例子,一种是咱们这个方案里面,我们可能在x86平台上常看到一个叫-M64的这样一个知道编译选项的option,这个含义,实际上是说要把我这个软件生成成为64位模式的。是分成64位模式的,我们编译目标代码的ABI。实际上在鲲鹏平台上,我们可以用类似的,我们可以用-mabi=lp64去来替换,当然如果安全的情况下,加上-FPIC就生成一个flowting的address,来屏蔽一些底层的相关依赖性,这样子就能达到一个编译选项M64的一个替换。
还有一个就是对应Arm指令集、SA的这样一个替换,我们常用的可能会见到一些-march的这样一个参数,在x86的平台上提供了多达二三十种架构平台,从intend到AMD的各种各样的,Arm平台来说,就相对简单一点,我们只需要去选用我们鲲鹏平台,你CPU所支持的兼容Arm的架构。我们鲲鹏920,我们进入的是AArm8.2-a这样一个架构。如果这些版本比较新,比如说9.1以上的,我们就可以去选用-mtune=tsv110。这实际上是我们泰山微内核110这个型号这里面会在Gcc内部进行了我们提了一些措施,针对架构做的一些的public的tune优化,能够提供一个相对较好的性能。 性能增加,据说有5%~10%的性能提升。
接下来第二部分就是C,C++原码的移植,这里面也举两个例子,第1个例子是这个是基本数据类型,尽管说我们鲲鹏平台支持的是LP64,然后这个x86平台也支持LP64的这样一个规范,但是实际上大家在某些细节定义上还是有区别的,虽然字符宽度,比如说对x来讲都是8字节,但是x86他这个x是有符号类型的,但是对于我们鲲鹏平台,我们用是无符号类型的,但这块的改动我们就可以通过修改makefile里面,加一个参数,加上-makefilex,去把默认的无符号的x定义成有符号的x,这样就能保证C代码逻辑,关于x操作上不会引入歧义。
第2类问题就是我们编译器当中提供了多达数百个的这个宏定义,可以被我们C,C++软件识取,比如说我们用GC的话,我们可以在C,C++的软件里面,原文件里面直接去使用相应的宏定义,这个宏定义在编译的时候可能会我们的编译器直接做环境变量的check,然后直接设置了相应的正确的值,跟host环境相关的。我这里指编译和运行在同一款机器上,我们不讲host和target相异的情况。这个时候对于相应的软件,我们就可能需要区分一下宏定义,比如说像这里x86 64,显然一看就知道他是支持x86的,不可能在我们鲲鹏平台上运行,这时候我们就会建议用户去修改用户代码,用预编译的方式做软件范围的定义隔离,很显然对于我们鲲鹏平台,我们常用的关键字就是aarch64或者是Arm64,这样的关键字去做软件逻辑的定义,除了这些以外,包括BBC都有各自的架构定义关键字。
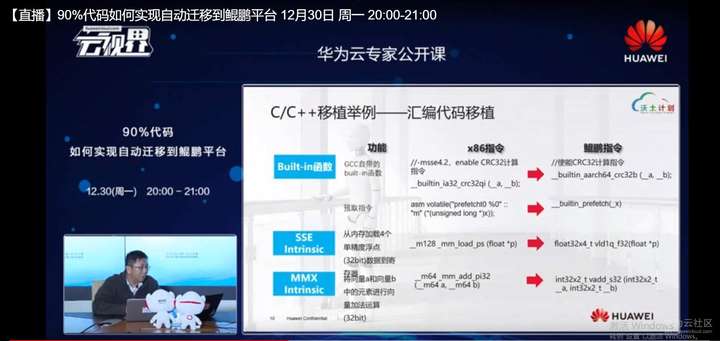
第3类问题就是我们汇编代码的移植,这也是最头疼的一块,因为x86平台如果细算的话,他将有2100个不到的汇编指令,鲲鹏平台因为兼容Arm64,我们有1000出头,1100不到,这样一个汇编指令,其实这加起来3000多条指令,如果大家想把它分清楚,那是非常痛苦的。Int的相应指令集的手册有4000多页,Arm相关指令集的手册有7000多页,纯英文的文档大家读起来肯定会崩溃的,所以在这里面汇编代码的移植,这是一个难点。
汇编代码在我们的软件过程中表现有若干种形式,第1种是我们纯粹的就用Asm关键字去写汇编代码,第2种是我们用built in函数做一些替换,比如说这里举个例子,像GCC里提供了built in的CRC的32计算的一些加速指令,我们可以去寻找鲲鹏平台上的相应的指令去进行替换,比如说像x86平台上用到的预取的指令,我们也可以去找到鲲鹏平台,上的built in函数去做替换。接下来还有第3种,就是我们可能会用到的Intrisic。Intrisic实际上是在jcc里提供的像C语言可以一样去使用的汇编函数,引出这个Intrisic是在x86平台上和Arm64平台,就相差非常的大。
在x86的平台上Intrisic总数总数将近达到7000个,7000不到,然后在鲲鹏水平上相差就差的比较多,远远少于这个数,为什么?这是因为在x86平台上它支持的指令集比较多,他自己经过二三十年的演进,对吧?他有mx的指令集,有SSE的指令集,还有AVX,AVX也分了128比特的,256以及500 12比特的三种。 每一种它对应的Intrisic非常的多,所以移植的数量是非常大的。在这个里面我们可以找到一些,比如说对于一个28比特的操作进行一些对应,可以做一些替换。
针对上面提出的这些问题,比如说我们C,C++刚才提出这些问题,我们就提供了这样几个工具,我们这里提供了分析扫描工具,代码迁移工具。分析扫描工具,就是识别我们软件移植的依赖性,然后去帮助用户做兼容性的排查。然后第2个提供代码迁移的工具是做源码的构建工程工程构建文件,还有C,C++原码以及汇编代码的扫描移植指导。第三个工具就是性能优化工具,我们刚把软件移植到鲲鹏平台之后,我们需要去用这个工具去分析性能,去发现热点,我们也提供了基于鲲鹏平台的一个加速库这么一个概念,一个组件。 这里面就提供了一个软件硬件协同加速用户应用的一个方式。
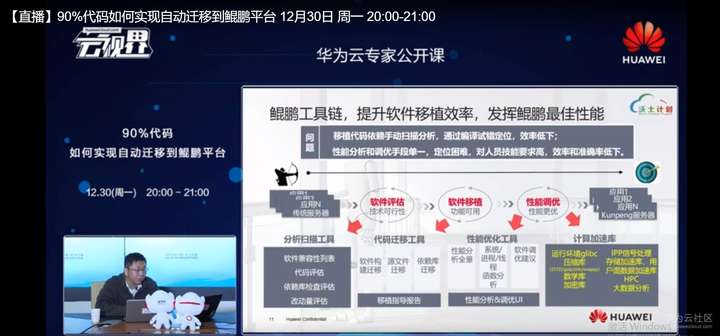
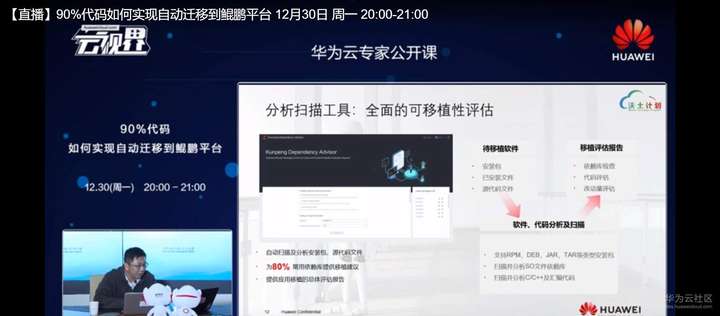
比如说我们这里优化了GDPC基础运行环境,我们优化的压缩、加密、加解密,包括一些数学计算这样一些开源的或者是三方的组建,我们优化了一些IPP信号处理的一些程序功能提升,就是用我们软硬结合的方式极大提升了性能。这里面我们大致分析的一个流程,我们会在分析扫描里面,我们把用户的软件上传到我们的工具环境下,我们工具环境就会分析用户X86平台上软件的安装包,比如说这里的RPM包还有一些JAR、Java类的程序,包括一些压缩包,我们就会去扫描识别里面软件包内部以及软件安装路径内,包括我们压缩包内部的集成的,比如说这些SO件、二进制文件,去检验它是否在鲲鹏平台上不同的操作系统上是否支持,去反馈用户一个一致性的分析报告,会逐个告诉用户SO是否兼容,不兼容的话怎么去处理?我们会提供链接是原码的值,这个是源码级的链接,或者是提供移植文档方式书的这种链接,都会在我们报告里提供出来。
我们这个工具提供了两种工作方式,一种是我们通过命令行的方式,下面这种形式通过参数输入,一种是通过这种外部方式,我们在做了安装包的依赖性分析以及原码的扫描之后,会给用户产生一个移植分析指导的报告,这个报告是提供CVS的格式或者是HDM的格式,用户可以去下载,里面就会详细罗列出哪些依赖库,哪些二级制文件需要移植,然后哪些C,C++以及汇编代码,需要移植规模有多大? 会给用户呈现一个移植的工作量,比如以每月为单位提供一个工作量。
计算标准,用户是可以自己输入的,比如说你的编正能力强,你一个月C,C++代码,你可以完成800行,汇编代码你可以完成600行,对吧?如果你的移植能力有限,有的编码能力有限,技术成本有限,你可以把它设置成比如说我C,C++代码一个月300行,汇编代码100行,它就会根据不同的标准,计算出你移植工作量,做工程技术上的第1步,第1部信息掌握。

这里就列出了我们主要的功能,前面我已经基本赘述了,就是SO文件的检查,构建工程的检查、源文件的检查,评估一致性,然后进行工作量评估,两种方式,外部方式和命令行方式。
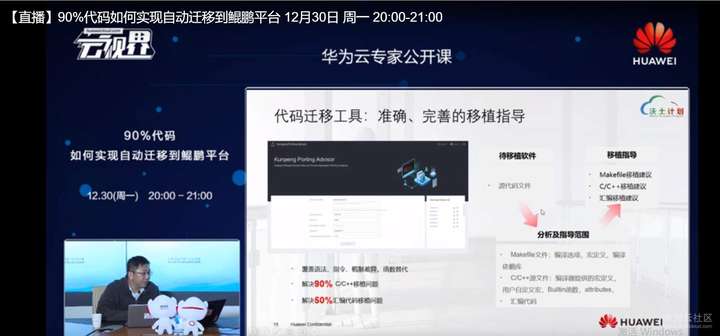
通过这个工具,我们就可以拿到软件移植的工程量的第1手资料,然后决定是否移植。当决定极值之后,我们就可以用代码迁移工具去做进一步的分析,代码移植工具主要是分析了用户的源代码,还是一样,他着重分析的是makefile,C,C++的源码,就包括我们这里的编译器提供的宏定义,然后用户自定义宏,还有built in函数,Intrisic,还有汇编代码,我们分析完这些内容会提供一个详尽的移植指导,这里面就包含makefile怎么修改?C,C++代码怎么修改? 然汇编代码,我们怎么去修改?

这里我们只是给移植建议,我们并不去修改用户的原码,用户可以参照着相应的输出我们这里输出的一致报告,去用GTDF的方式,大家去做一个这个对比,然后去把它在工具界面以外用第三方的,比如说用其他的编辑工具把它完成修改。那么这一页我们就列出了我们代码移植工具的一个大致工作流程,同样我们也是外部方式和命令行方式两种方式,方便用户做选择。我们分析用户的源码构建工程,还有公共建工程配置文件,还有C,CC+加的源码或者是汇编源码,然后给出移植知道,那么对于源码的变化,我们会提供对比的方式显示,像这里举的例子就是左边第1点是我们要改哪些文件,就是修改文件列表,第2类就是我们要原文件是什么样子,第3类就是我们建议修改成什么样子?

这是我们软件移植工具所能提供的能力,我们C,C++,我们这里还是针对C,C++目前为止C,C++的这样编译型语言,去做了建议值,然后我们要有源码,没有源码,也就谈不上移植了。

前面已经讲了,我们如何去做软件依赖性的分析,通过华为开发套件去做软件依赖性的分析,以及做C,C++的移植,我们在完成移植之后,我们会在生产环境上去跑我们这个软件,我们可能会去做性能分析,这时候我们就会提供一个我们叫做分析的一个工具,这个工具主要是帮助用户去做软件性能定位,比如说你有些性能瓶颈或者有想继续优化,我们这里提供了一些手段,这里对于这个工具我们可以帮助用户去分析处理器相关指标,以及看到调度的一些信息,包括外设的信息,包括CPU、磁盘,甚至网卡、短期性的数据,去帮助用户分析C,C++或者是Java程序这样一个性能指标。
我们Java类不是说把GBM当成一个进程,我们是看到GBM内部的,还是有一定作用的,还是比较有用的。我们会把这些数据统统的分析起来,然后通过我们自己定的定义的数学模型进行分析,去看到用户的软件性能瓶颈,比如说是资源竞争的问题或者是调度的问题,甚至说比如说有一些bug导致了一些次循环等等的,我们提供了多种的方式来呈现这样一个结果。比如说我们常用的这种火焰图的方式,我们这里能够提供比较直观的可视化方式,帮助用户去看自己的软件里面到底有没有性质上的问题。
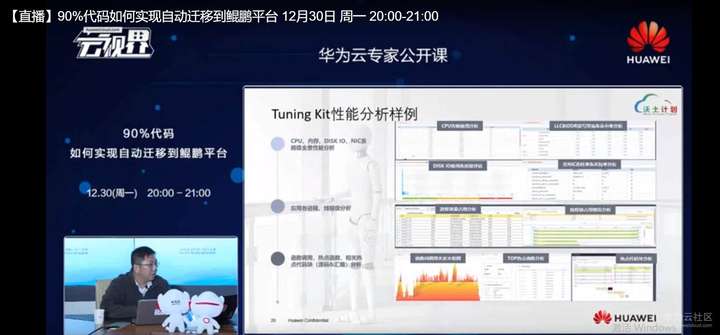
这个是我们这里是罗列一下我们目前性能分析工具能够提供的性能指标,我们能够看硬件器件相关的,比如CPU、内存、磁盘、网卡、系统级的,我们也能看这种线系统调度以及的比如说进程、线程,还有彼此之间的切换,或者是资源的争抢,锁这样的一些关键变量的这样一些性能分析先行指标,我们也提供了一个基于火焰图、基于代码逻辑的深层次检查,能够提出用户代码的真正的开销,大的地方在哪里,对应的代码对应到源码。
通过这样一个手段,我们就能帮助客户比较快的去帮助开发者比较快的定位自己的软件,编译形软件的瓶颈。,当定位到软件瓶颈的时候,我们会提供一些附加的能力,比如说这里我们就提供加一个叫加速库,我们软硬结合的加速库帮助用户去优化代码。这个原因是什么?这原因主要是因为我们鲲鹏是一个sock,我们是一个片量系统。
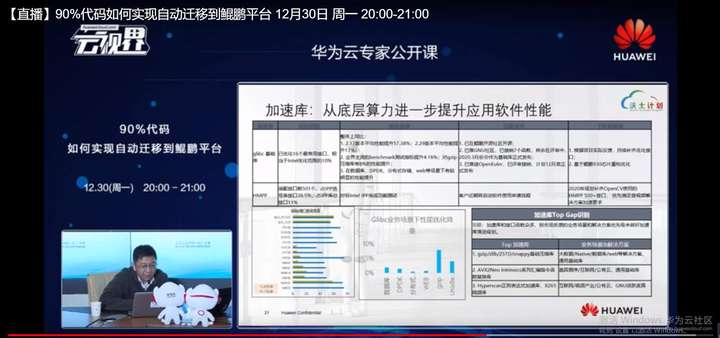
除了泰山内核,以及多达48甚至64的内核以外,我们还提供了一些额外的能力,额外的一些引擎,这些加速引擎就可以支持,比如说压缩LZ77的这种算法,还有加解密的,比如说非对称的,还有对称加密的,包括一些常用的变加解密的这样算法,比如说DH编码等等。
我们还支持了比如说存储用到code等一些这样一些常用的软件算法,我们把它运化成加速器,这种压缩用起来非常简单,就跟我们用一个外设一样,我们只需要从华为的网站上去获取相应的硬件驱动代码,把它安装上之后,我们就可以像一个正常的外设一样去使用它。
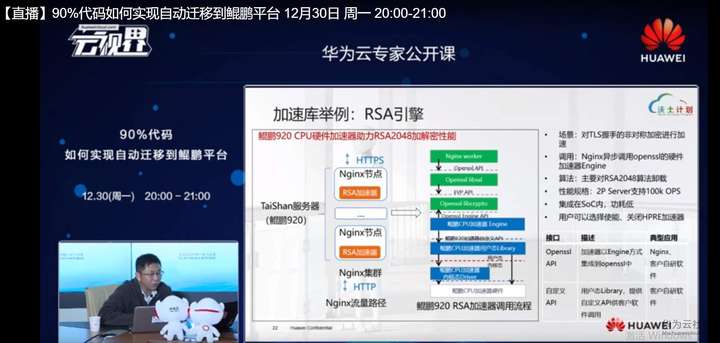
当然了你要使用我们提供的一些API的话,可能还要遵循一些,比如说我们要提供给用户手册,用户可能要去修改一下自己的源码,比如说可能原来掉的一些是软件的这样一些函数,或者是三方组建的API,这时候可能去要用加速器的话,就需要根据API修改我相应的这个代码逻辑,但这个代码逻辑只是存在于API层面。
这里举个例子,比如说我们这里集成了一个叫RC的加速的引擎,是用来计算finish加密的,我们支持1024~4096,4种:1024 2048 3072 3096,4种密钥长度。我们在我们加速器引擎里面,我们是通过一个用户态的来libry去做一个隔离,对上去隔离用户的,比如说开源的第三方软件,比如说这里贴到open SSL的的API,我们去对接open SSAPI我们也可以把API暴露出来,直接给用户的APP去使用,在libry下层的就是我们IC引擎的相应的驱动,用户可以完全不用知道下面细节是如何实现的,但是我们通过只要使用我们正确调用鲲鹏RC的提供的用户libry,就可以去使用我们加速器的硬件计算能力,极大的加快了RC的计算。
其实我们也知道RC计算如果用CPU算的话,那是相当费时费力的。比如说一个像x86的一个中高端的一个call,可能它每秒钟只能执行720次左右的一个RC2048的计算。但是你要用到了鲲鹏920提供的RC计算引擎的话,计算量将是大幅度的提升,也就是说,我可以把原本用来计算RC的这些CPU完全释放出来,跑我的业务!在一个芯片内完成这样业务,就会对用户来讲就会提供另外一个选择,我不需要去买某些PCIE的插卡,我直接去用软件的方式来提升我的软件性能,达到一个比较简单的提升性能的一个方式。 这是我们举的一个例子,在这些里面,在我们移植工具里面,都会去通过我们软件移植的这样一些能力去提供给开发者直接使用。
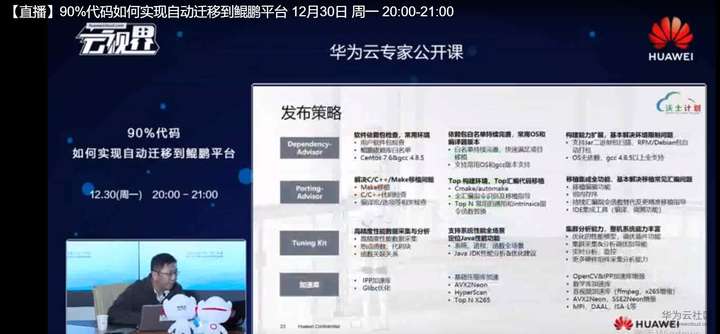
这个是我们几个工具组建的发布的策略,我们目前为止是停留在中间这一列上,我们完成了多OS的适配,比如说我们支持3~4、74、7.5、7.6、7.7、7.8对吧?我们也支持中标麒麟等,我们也支持了像苏C这样一些的操作系统,就是我们尽可能的去帮尽可能覆盖我们常用的这样一些操作系统的类型,我们也支持了GCC的多个版本,我们从4.8.9一直支持到目前为止至少8.3,我们后续会支持到9点几的版本,一直往上支持上去,帮助客户去尽可能的简化一些重复劳动,我们也支持MAC构建工具,也要支持CVK构建工具,未来还会支持automake这样的一个构建工具的一些检查。
支持C,C++的与代码移植,也支持汇编代码的识别,因为刚才前面说了,从汇编指令的角度来讲,从你Intrisic的数量来讲,这个量非常的大,而且也很有技术挑战的,就是汇编语言的替换,所以这块我们会逐步完善。对于加速这一块,我们是提供一些Intrisic的一些替换,比如说我们有abs或者有SSE。
我们也去优化了,像一些常用的加速的三方的组件,比如说像一些z-lib的加速或者stapi的一些加速,还有一些scan这种字符扫描的加速的,我们用鲲鹏的指令去进行优化,进行性能提升,取得了比较可观的一个性能改变都是50%,一倍,甚至更多的3,4倍的这样一个性能提升,所以加速的效果还是挺明显的。这样也能让用户的软件应用跑在空间当中跑的更快又快又好。
如何去获取我们这几个工具,我们可以通过华为的spot网站去下载,也可以通过华为空方社区去下载相应的软件,这上面提供了一些链接。

对于我们加速库软件,这里的策略是主要采取开源的这种策略,比如说像JDPC或者一些三方组建的,包括一些压缩算法,压缩引擎的,包括这些软件组件,我们都是把相应的patch去推动到社区里面去。对于硬件加速引擎,我们也是直接可以从华为的鲲鹏社区上去下载,然后去安装使用,取用起来还是比较方便的。
鲲鹏社区以后就是华为重点建设的一个和开发者沟通的互动的地方桥梁。在这个地社区里,我们就可以下载到数百份的软件移植指导以及相应的软件调优的经验,可以在这里面和其他的开发者做互动,做技术上进一步的探讨。 然后很多新的技术资料、技术文档,包括一些白皮书,一些产品设计方案都会在社区里陆续发布,不同的开发者都能得到一些不同的信息。
这里列出来,我们空开发者社区里面如何去得到两工具这几个工具,目前我们这些工具都已经上线了,9月30号是第1版本,9月30号以后我们是每月逐月发布的这样一个节奏,这个节奏将延续到2020年,就是说我们不是一个短期行为,我们会一直从开发者的需求角度来出发,去把这个工具做的更加应用,更加方便帮助用户完成C,C++加代码的90%的工具化移植。
其实在鲲鹏的开发的平台里面,因为鲲鹏是空中平台,是一个新生事物,对吧?对于x86而言是一个新生事物,在这个里面我们也能感受到,随着鲲鹏计算平台的壮大,应用越来越多,需要大量的开发者去投入到平台的生态建设里面来。所以华为在这里推出了这种线上认证培训的这么一系列的技能提升的活动,包括在线课程,包括云端的实验室,包括线上认证和线下培训,希望大家能够积极参与,来共同构建华为鲲鹏的生态软件生态。
这里提到一个华为鲲鹏认证开发工程师这么一件事情,就是HCIA认证认证其实在华为内部还在对华为来讲还是蛮有价值的,对开发者来讲也是很有价值的。因为你通过了认证之后,在一定程度上将会成为你进入华为从事软件开发的一个直通车。
所以大家可以关注一下相关的一些培训认证的信息,去找到一个适合自己的方向,然后去在一个更大的舞台上,我们一起来构建华为鲲鹏的软件生态环境,让华为鲲鹏做得越来越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号