(九)MySQL数据库
1、数据库基础
ACID-四大特性:
原⼦性Atomicity: ⼀个事务必须被事务不可分割的最⼩⼯作单元,整个操作要么全部成功,要么全部失败,⼀般就是通过 commit和rollback来控制
⼀致性Consistency:数据库总能从⼀个⼀致性的状态转换到另⼀个⼀致性的状态,只要有任何⼀⽅发⽣异常就不会成功提交事务
隔离性Isolation:⼀个事务相对于另⼀个事务是隔离的,⼀个事务在最终提交以前,对其他事务是不可⻅见的
持久性Durability:⼀旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失
脏读: 读到未提交的数据称为脏读
不可重复读: 同个事务前后多次读取,数据内容不相同,因为⼀个事务也操作了该同⼀数据
幻读:同个事务前后读取某个范围内的记录时,数据内容不相同,因为另外⼀个事务⼜在该范围内插⼊了新的记录
幻读和不可重复读的区别是:前者是⼀个范围,后者是本身,从总的结果来看, 两者都表现为两次读取的 结果不⼀致
事务隔离级别:未提交读:读取未提交内容;存在脏读;
提交读:读取提交内容;存在幻读;能读取到其他事务提交的数据;
可重复读:mysql默认事务级别;读取不到其他事务提交的数据;
可串行化:所有事务串行,效率低;
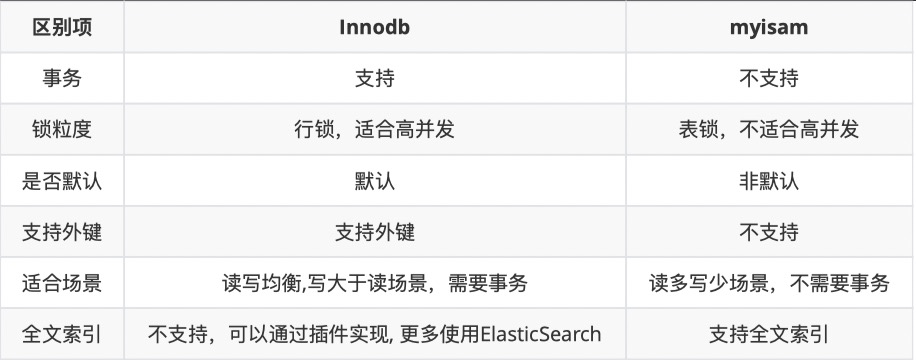
常见存储引擎:⼀般⽐较常⽤的有InnoDB、MyISAM、MEMORY;MySQL 5.5以上的版本默认是InnoDB,5.5之前默认存储引擎是MyISAM;
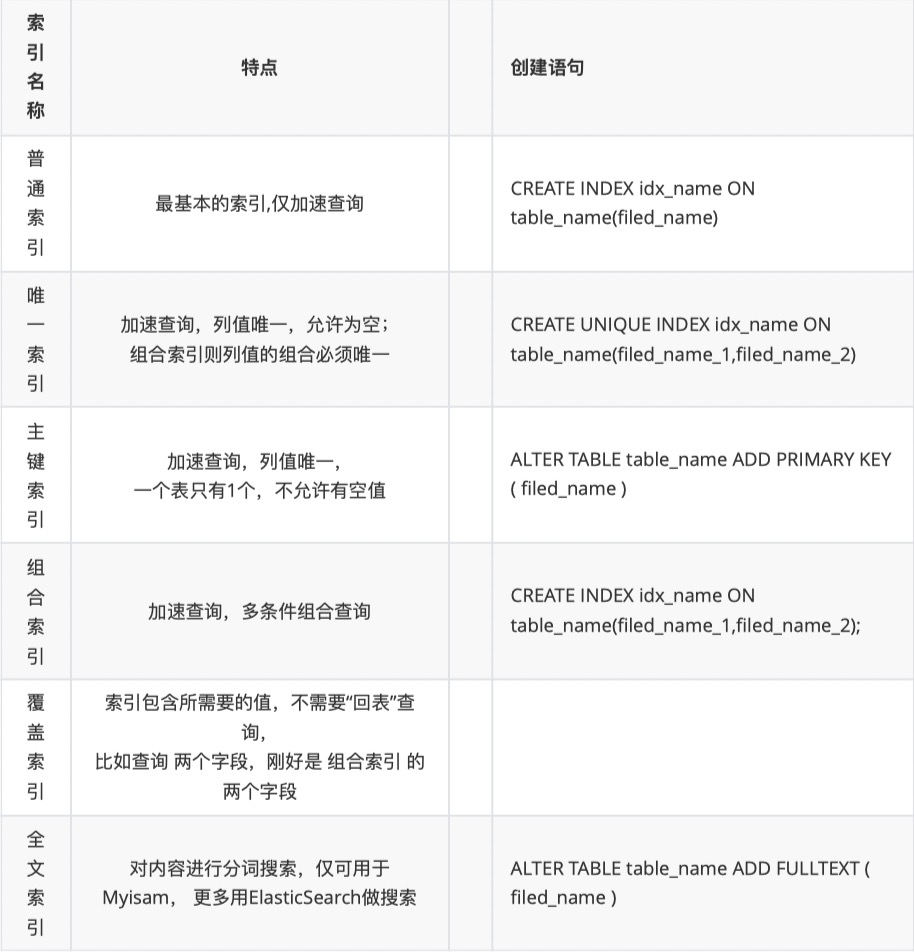
常用索引:
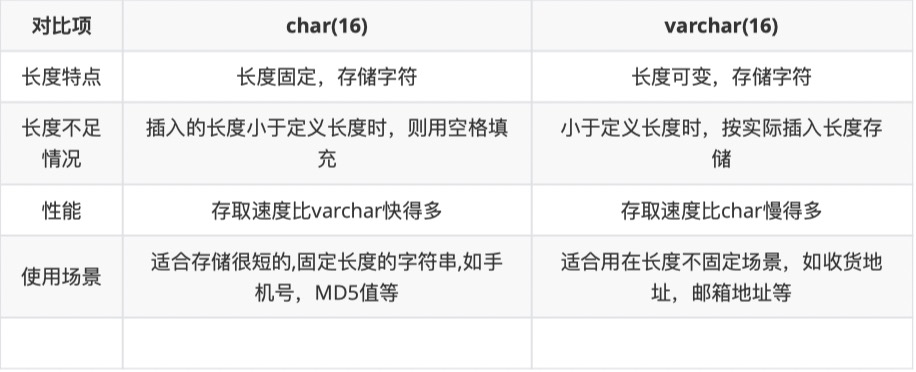
索引好处:快速定位到表的位置,减少服务器扫描的数据,有些索引存储了实际的值,特定情况下只要使⽤索引就能完成查询
索引缺点:索引占磁盘空间,插⼊、更新、删除需要维护索引,修改表的时候重构索引性能差
索引优化实践:尽量使⽤数据量较短较少、内容变动频率较小字段;根据业务尽量选常用筛选字段、业务查询最相关的字段;根据业务需要建合适数量的索引,避免过多/过少;是TEXT和BLOG类型使用前缀索引-前面几个字符;
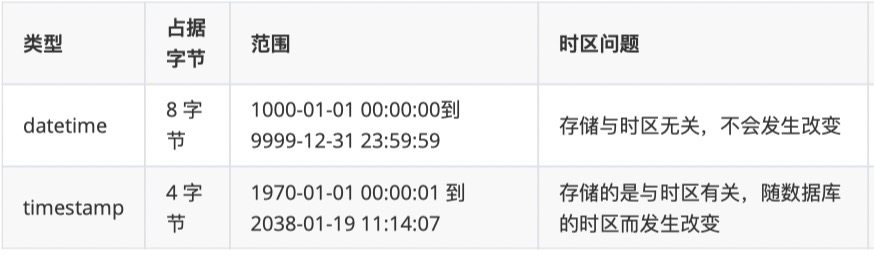
注:timestamp类型是4个字节,最⼤值是2的31次⽅减1,结果是2147483647,转换成北京时间就是2038-01-19 11:14:07
2、数据库性能
分页查询优化:使用缓存-首次查将其保存到redis中;索引覆盖字段-直接返回索引值,不再去表中回查;子查询id等索引字段结果做主查询条件;
数据库监控与安全:
业务流程上:功能预上线时审查代码/sql--避免select * /索引不合理;开启慢查询日志,定期去看;运维会定时发CPU/内存利⽤率/读写、⽹关IO、流量带宽、吞吐量QPS/TPS等统计数据;
数据安全方面:日增量备份,周全量备份;主从架构;检查数据库授权账号、不同业务不同号、不同数据库不同号等;数据导出授权与限制;数据库操作日志审查,防止内部篡改数据;
3、数据库主从复制
mysql常见日志种类:
slow query log 慢查询⽇志:记录执⾏时间过⻓长的sql,时间阈值可以配置,只记录执⾏成功
binlog ⼆进制⽇志:⽤于主从复制,实现主从同步
errorlog 错误⽇志:Mysql本身启动、停⽌、运⾏期间发⽣的错误信息
redo 重做⽇志:防止出现故障时,缓存中的脏⻚数据未写⼊磁盘,保证事务持久性、⼀致性;(注:修改数据是从磁盘读到缓存修改,修改完毕再写回磁盘)
undo 回滚⽇志:保证原⼦性,记录事务发⽣之前的数据的⼀个版本,⽤于回滚。 innodb事务的可重复读和读取已提交就是通过mvcc+undo实现;
relay log 中继⽇志,和binlog相关 :⽤于数据库主从同步,从库将主库发送的binlog先保存在本地,然后从库进⾏回放
general log 普通⽇志:记录数据库操作明细,默认关闭,开启会降低数据库性能
主从数据库原理:数据库是多点,主从复制;异步复制,不影响主库;
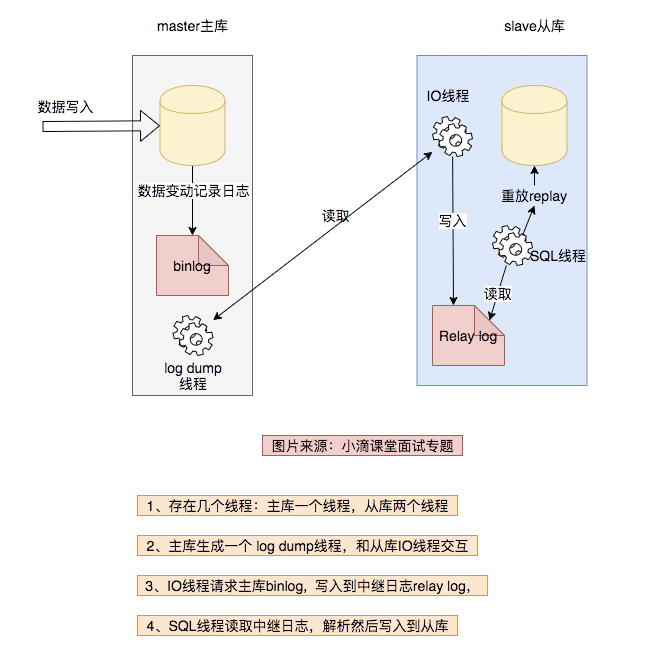
搭建主从数据库问题点:
主从数据库目的:灾备,故障切换;读写分离;
主从同步延迟问题:延迟是100%存在,延迟是相对的;通信/网络延迟等;大数据量情况下,主库有从库没有;
原因:主从复制是单线程的,主库 TPS系统吞吐量很高 且超出了从库的sql线程的执行能力;重放sql锁住表导致后边阻塞;磁盘/cpu/网络等硬件问题;
解决:加缓存,写完主库写redis,读完redis再读从库;一主多从,多从库减少读;分库分表;提高硬件设施配置;
主从数据不一致问题:延迟;主或从宕机;从库升级到主库;
校验一致性:不用工具(主从库-每表的每行/每十行各个字段拼接字符串做hash进行比较);使用Percona公司的工具,pt-table-checksum⼯具进⾏⼀致性校验(利用主库表索引对表分成chunk块,计算checksum值与从库比较;对计算的chunk块或行加锁,防止校验时有更新操作导致 校验不一致);
修复不一致:在从库使用pt-table-sync⼯具修复不⼀致数据,但不修复表结构,也可以修复非主从库关系的数据;要先备份再修复,防止误修复;
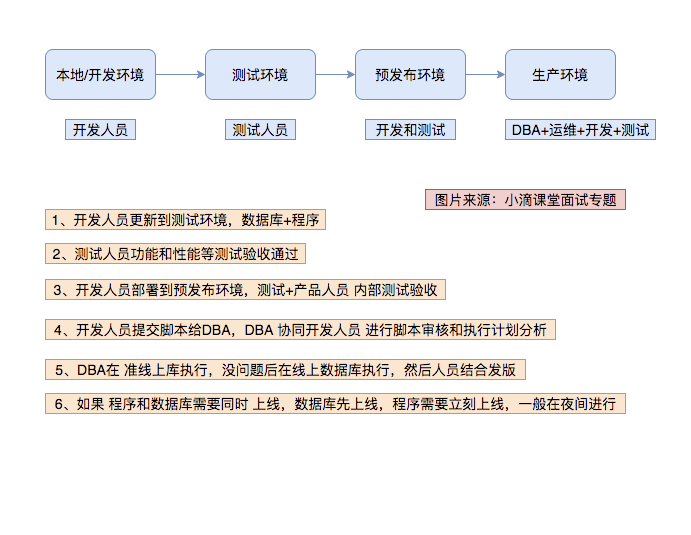
4、版本上线流程--数据库发版部署流程
组提交思想:Multi-Threaded Slave配置,从库SQL线程就分裂为coordinator线程和worker线程,worker线程对组提交的事务进行并行回放
多个事务的redo刷盘操作合并成一个;刷盘 由准备阶段移只 commit产生binlog之前;
常用字段:bigint/varchar/int/datetime
超卖:sql加where语句校验-num大于等于0;
事务:异常情况下进行回滚+多个事务提交时的事务隔离;
ACID:原子性-修改要么全部成功; 一致性-事务执行前后所有数据保持一致状态; 隔离性-事务仅能读取到另一个事务前后的数据状态,不可能时中间状态; 持久性-完成后是永久的;
悲观锁:数据总会冲突,处理数据时锁住数据防止别人修改; select for update;但不影响查询;悲观锁必须走索引,否则全表扫描上锁;
乐观锁:数据不会冲突,处理时校验; 版本号/时间戳;将select查询也放到事务中,查master数据库;
共享锁:shared locks,共享读锁;读锁基础上只能加读锁,不能写; select … lock in share mode
排他锁:exclusive locks,排他写锁;独占,不能再加任何锁,可以读写; select … for update
意向锁:表锁,意向共享锁(IS锁)和意向排它锁(IX锁); 判断表锁存在,行锁就等待;
间隙锁:防幻读,保证数据的恢复复制; 同一事务两次读结果一样; Next-key lock:record+gap
死锁:A-读+写,B-写; A-读区域,B-写区域; 加锁情况与 事务隔离级别、索引有关;主键、唯一索引、普通索引;
MVCC并发控制协议:优势-读不加锁,读写不冲突;
快照读-不加锁-普通select;
当前读-会加锁-读锁/写锁的select+写操作;
覆盖索引:查询字段全在索引字段中;
组合索引:左前缀,第一个字段必须用到,依次比较索引字段在where中;> < 单列索引:选取最有效的;
7种事务行为:
mysql加锁等待超时原因:inodb基于索引的行级锁,大表写没用到索引/普通索引重复率高 就会 锁表;行锁升级到表锁;----索引写;读写分离;
rc/rr实现:mvcc多版本并发控制,写版本+删版本;增-写版本;删-改删版本;改-复制 旧删新写;查-早于当前版本; 区别:gap锁+过滤不释放;
sql语句:先on临时表,再join表,最后where过滤临时表;inner无区别,outer就有区别;top/having/avg/min/count/sum/order by/group by等;
binlog:二进制文件,.index索引文件+.00*日志文件;
DB2与MySQL区别:MySQL有用户体系,IP+用户名 存储在MySQL数据库的user表中,DB2无用户体系;MySQL用MVCC实现锁并发控制,DB2使用内存模型;MySQL开源,二开及扩展较好mycat,DB2查询性能好价格贵;MySQL两个都有,DB2归档日志依赖事务日志;MySQL的数据库相当于DB2的schema;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号