大数据预处理-- 房型和房价的关系
在租房时候,有整租有合租,还存在一些多人共用一间的情况(有点类似青年旅社),可以尝试性探究不同的房型与房价之间的关系
sort_price = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('room_type')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='room_type', data=listings.loc[(listings.price <= 600) & (listings.price > 0)], order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
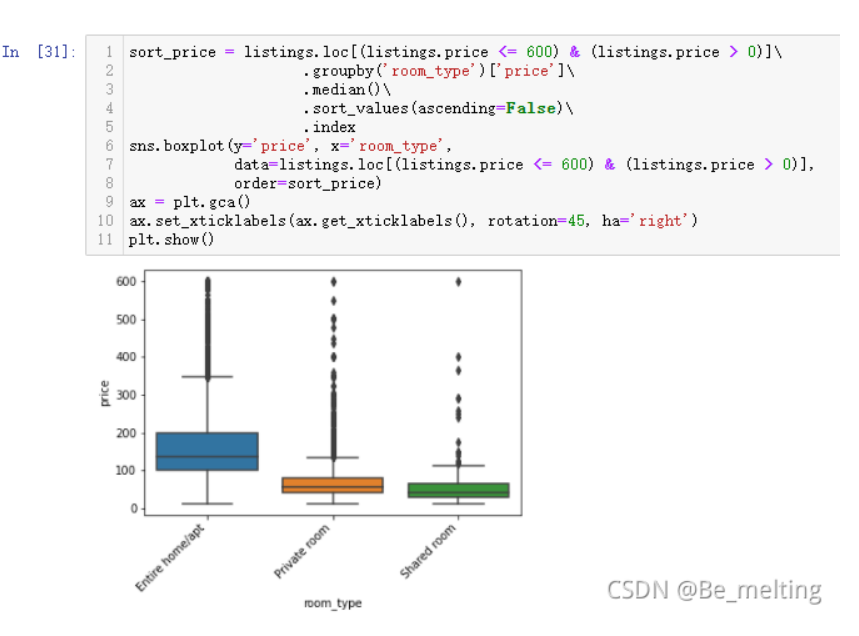
输出结果如下:(整租价格最贵,其次是合租,最便宜的就是多人共用)
除了查看字段中各房型的房价信息,也可以逆向思维,根据价格来看不同房型的出租的多少,通过堆叠图来尝试探究
listings.loc[(listings.price <= 600) & (listings.price > 0)].pivot(columns = 'room_type',
values = 'price').plot.hist(stacked = True, bins=100)
plt.xlabel('Listing price')
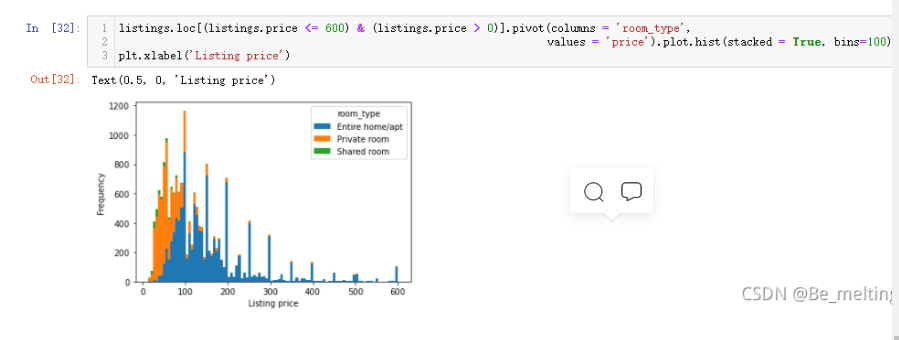
输出结果如下:(有个明显的分界线,就是在100前后整租房的出租的数量和其它两种房型存在着较大的差距,100之前合租占据较大的比例,但是100以后就是整租的绝对优势了)
配套设施必备类型
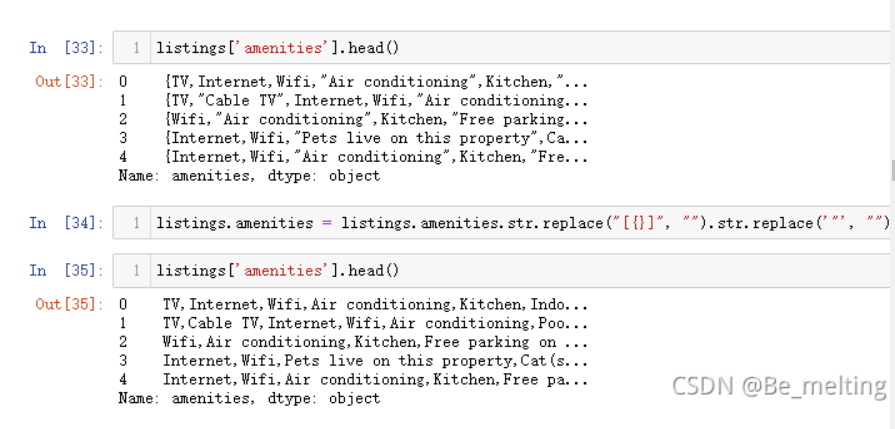
酒店中房间的配套设施,比如wifi,卫生间,开窗,24小时热水等条件,尝试探究出租房中必备的配套设施都有哪些,首先对amenities字段的数据进行清洗,提取里面的具体设施
listings['amenities'].head()
listings.amenities = listings.amenities.str.replace("[{}]", "").str.replace('"', "")
listings['amenities'].head()
输出结果如下:(需要对花括号和引号进行去除,最后就是按照逗号进行分割)
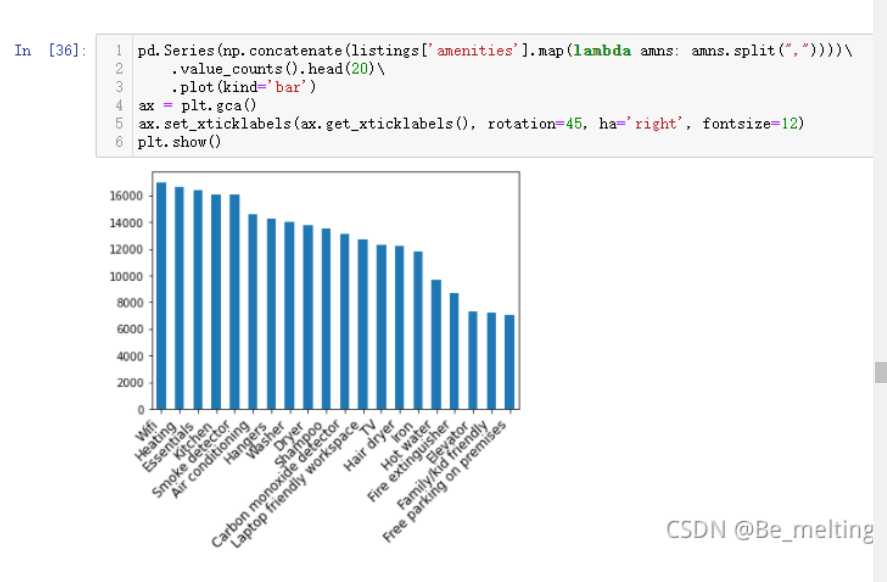
找出前20个最重要的便利设施
pd.Series(np.concatenate(listings['amenities'].map(lambda amns: amns.split(","))))\
.value_counts().head(20)\
.plot(kind='bar')
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right', fontsize=12)
plt.show()
输出结果如下:(Wifi 暖气 厨房等便利设施是最重要的部分。这一部分有个很常用的功能,就是对一个字段中多项元素进行合并后进行统计计数后绘制图像)
配套设施和房价之间的关系。理解下面的前三行代码将会有不少的收获
#获取字段中的唯一元素
amenities = np.unique(np.concatenate(listings['amenities'].map(lambda amns: amns.split(","))))
#对包含的元素进行统计求平均值,排除空值
amenity_prices = [(amn, listings[listings['amenities'].map(lambda amns: amn in amns)]['price'].mean()) for amn in amenities if amn != ""]
#按照元素作为索引,平均价格作为值
amenity_srs = pd.Series(data=[a[1] for a in amenity_prices], index=[a[0] for a in amenity_prices])
#绘制前20的条形图
amenity_srs.sort_values(ascending=False)[:20].plot(kind='bar')
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right', fontsize=12)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号