
Python网络爬虫课程设计------亚马逊产品销售数据分析
一、选题背景
随着电子商务在全球范围内的普及和扩展,亚马逊作为全球最大的电商平台之一,吸引了数百万的卖家和消费者。这使得对亚马逊平台上的产品进行数据分析变得至关重要。在亚马逊上,产品种类繁多,竞争激烈。为了在众多竞争对手中脱颖而出,需要对市场趋势、消费者需求、竞品分析等方面进行深入挖掘和分析。随着移动互联网的普及和消费者购物行为的改变,越来越多的消费者选择在亚马逊等电商平台上购买产品。因此,了解消费者购物决策过程、需求偏好以及购物习惯等信息,对于产品开发和市场营销策略的制定具有重要意义。
二、选题意义
市场洞察:通过大数据分析,可以深入了解产品的市场表现,包括销售情况、用户评价、竞争态势等。这有助于企业了解市场需求,制定针对性的营销策略,优化产品设计和改进。
趋势预测:通过分析历史数据,可以预测产品未来的市场需求和趋势。这对于企业制定长期发展战略,进行产品规划和投资决策具有重要意义。
竞争对手分析:通过大数据分析,可以了解竞争对手的产品销售情况、营销策略等,从而调整自己的竞争策略,抢占市场份额。
用户行为研究:通过分析用户的购买行为、浏览历史、评价反馈等数据,可以深入了解用户需求和偏好,从而优化产品设计,提升用户体验。
数据驱动决策:大数据分析可以帮助企业实现数据驱动的决策,提高决策的科学性和准确性。通过数据分析和可视化,可以将复杂的数据转化为易于理解的商业洞见,帮助企业做出更好的决策。
创新和改进:通过大数据分析,可以发现产品的潜在改进空间和机会,推动产品和服务的创新。同时,通过对市场和用户的深入了解,可以为企业带来更多的商业机会和合作可能性。
三、数集简介
收集关于亚马逊商品的大数据,在收集到原始数据后,需要进行清洗和预处理工作,以消除错误和异常值,保证数据的准确性和完整性,利用统计分对处理后的数据进行深入分析。
数据使用:https://www.amazon.com
数据集:amz_br_total_products_data_processed.csv
数据集简介:
asin:亚马逊平台上的唯一商品标识符。
title:商品标题,通常简短地描述了商品的主要特性或名称。
imgUrl:图片的URL地址。
productURL:商品的网页地址,通常在亚马逊平台上,点击这个链接可以直接跳转到商品详情页面。
stars:商品的评价星级,通常表示消费者对商品的满意度。
reviews:消费者评价或评论,这是其他消费者对商品的看法和反馈。
price:商品的销售价格。
listPrice:商品的建议零售价或标价。
categoryName:商品所属的类别名称。
isBestSeller:该商品是否是“最畅销商品”。如果是最畅销商品,该商品在同类商品中销量最高。
boughtInLastMonth:消费者是否在最近一个月内购买了该商品。
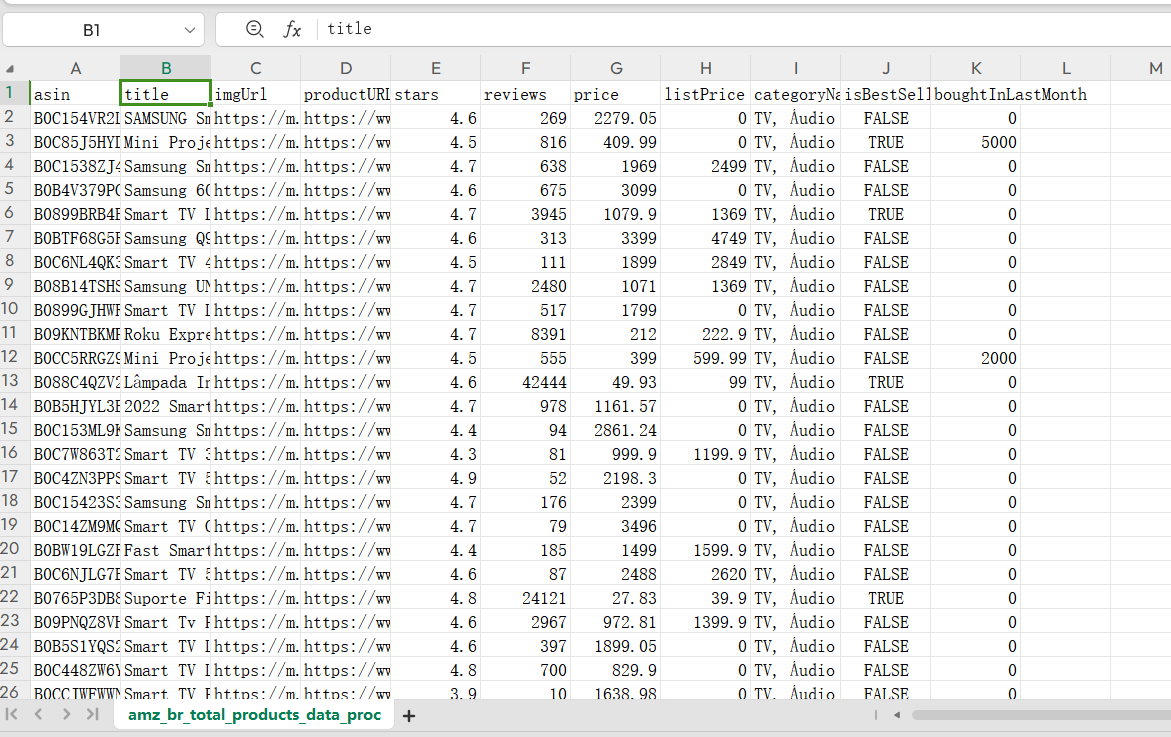
数据源截图:

数据截图:
四、大数据分析
4.1、导入数据库
#导入库
import numpy as np
import pandas as pd
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
import matplotlib
import seaborn as sns
import matplotlib
from matplotlib import rcParams
df = pd.read_csv("amz_br_total_products_data_processed.csv") #导入数据库4.2、数据清洗统计
返回DataFrame的前五行
df.head()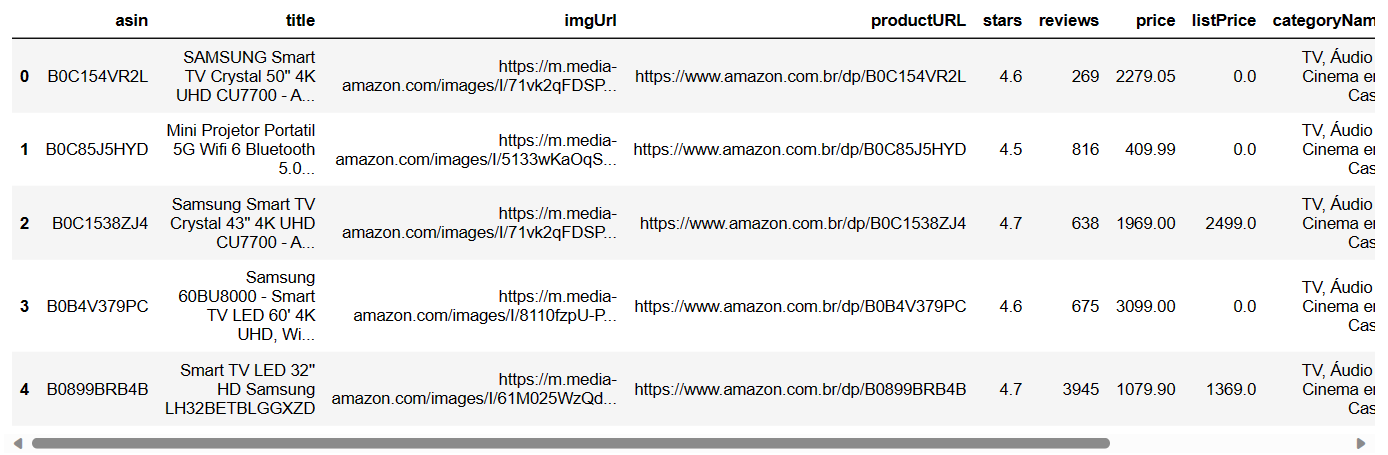
查看DataFrame对象信息
df.info()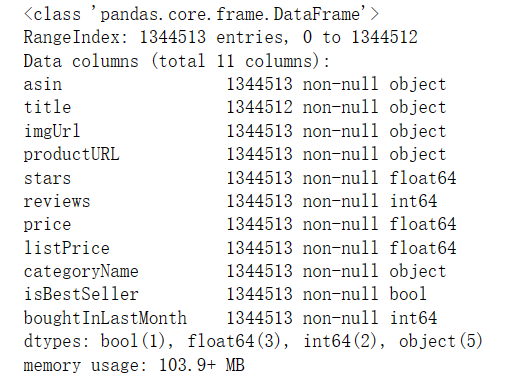
显示行列数
df.shape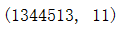
显示数据是否异常状态
df.info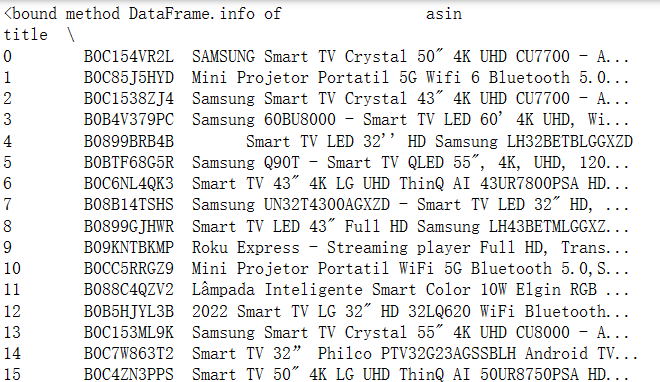
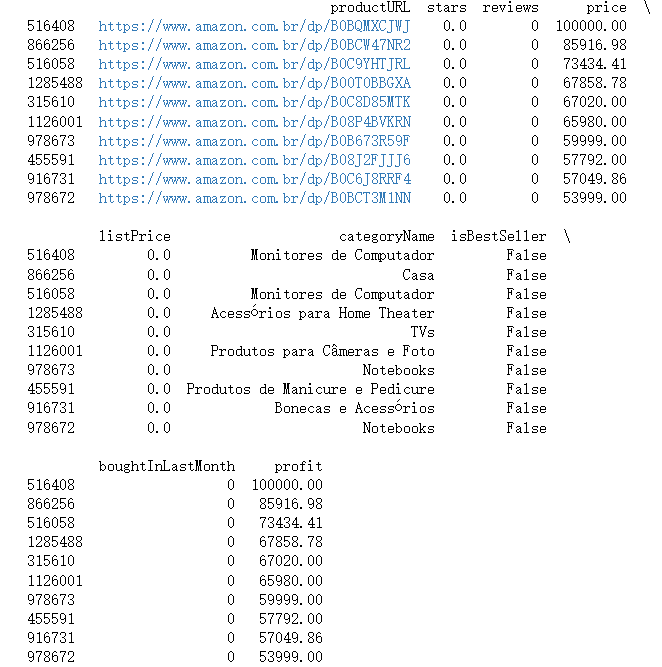
从CSV文件中读取了商品数据,计算了每条数据的利润,并找出了利润最高的前10个商品,最后将这10个商品的信息打印出来。
import pandas as pd
df = pd.read_csv("amz_br_total_products_data_processed.csv")
# 计算利润,并添加到DataFrame中
df['profit'] = df['price'] - df['listPrice']
# 显示利润最大的前10个商品
print(df.sort_values('profit', ascending=False).head(10))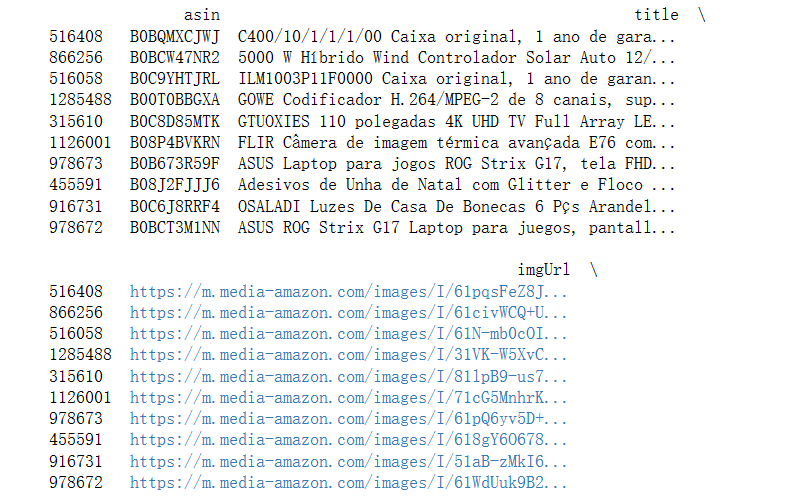
计算商品的平均评价星级
average_stars = df['stars'].mean()
print(average_stars)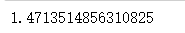
查看数据分布
sns.pairplot(df)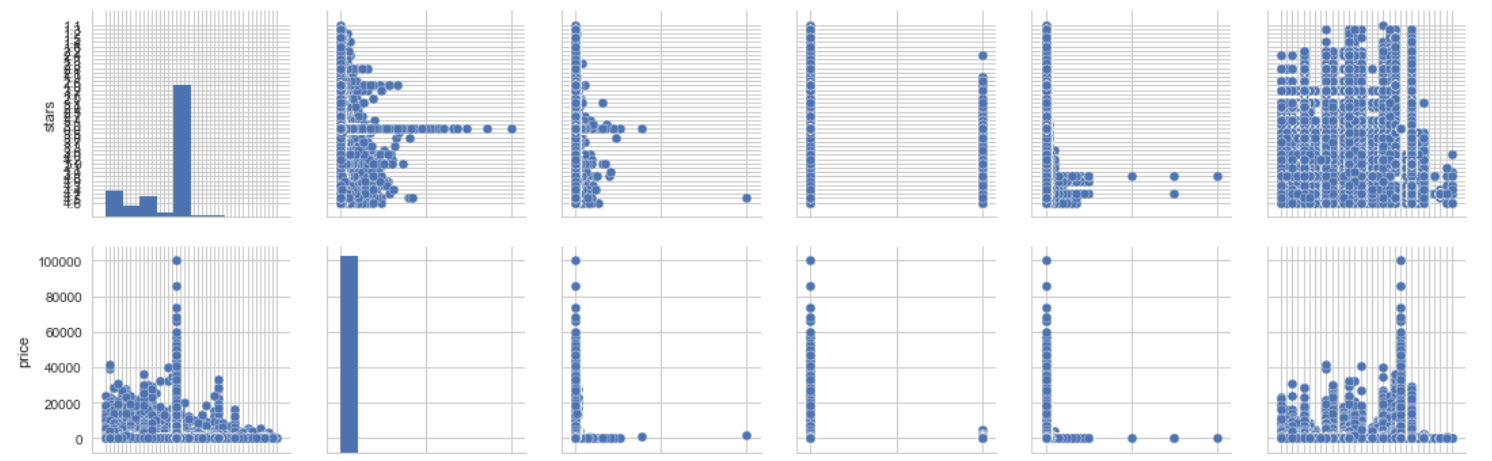
原始的DataFrame 分割为两个部分:一个只包含数值型数据的部分和一个只包含非数值型数据的部分,将数值型数据列与其他数据分开。
# 导入所需的库
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
#初始化一个空列表
num_data = []
#遍历DataFrame的所有列
for column in df.columns :
# 检查当前列的数据类型是否不是对象,字符串类型的数据通常用"O"表示
if df[column].dtype != "O" :
num_data.append(column)
#使用drop方法从原始data DataFrame中删除所有数值型数据的列
cat_data = df.drop(num_data,axis=1)
#显示数值型数据的部分的前五行
df[num_data].head()
cat_data.head()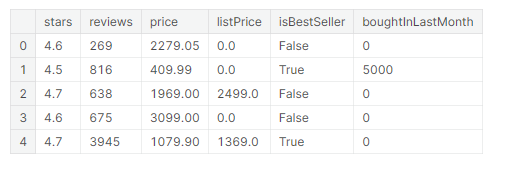
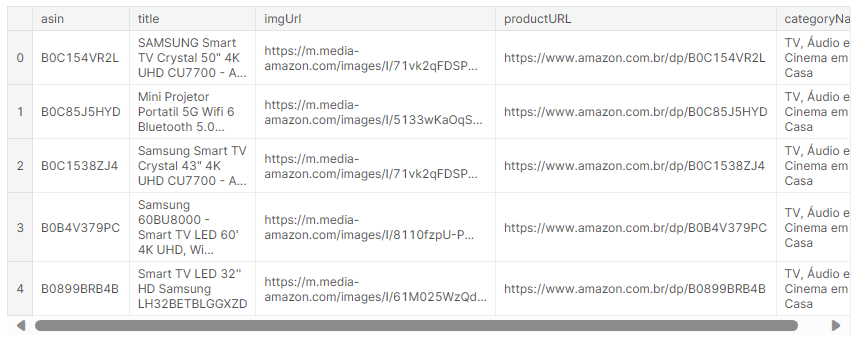
对DataFrame中的数值型和分类型列进行描述性统计分析,并输出每列的名称、偏度和峰度
# 选取了 df 中所有数值型(float 和 int)的列,并将这些列的名称存储在 cols_num 列表
cols_num = df.select_dtypes(include=['float', 'int']).columns.tolist()
# 选取了 df 中所有分类型(object 和 category)的列,并将这些列的名称存储在 cols_cat 列表
cols_cat = df.select_dtypes(include=['object', 'category']).columns.tolist()
# 遍历 cols_num 中的每一列
for col in cols_num:
# 打印一个由 30 个等号组成的字符串,作为分隔线
print('==' * 30)
print(f'Variable: {col}\n')
print(f'Skew = {df[col].skew()}')
print(f'Kurtosis = {df[col].kurt()}')
print('==' * 30)
print('\n')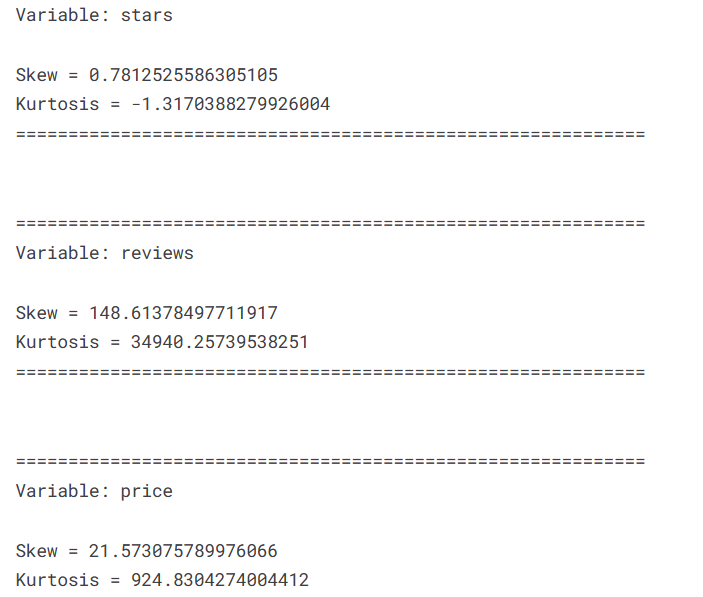
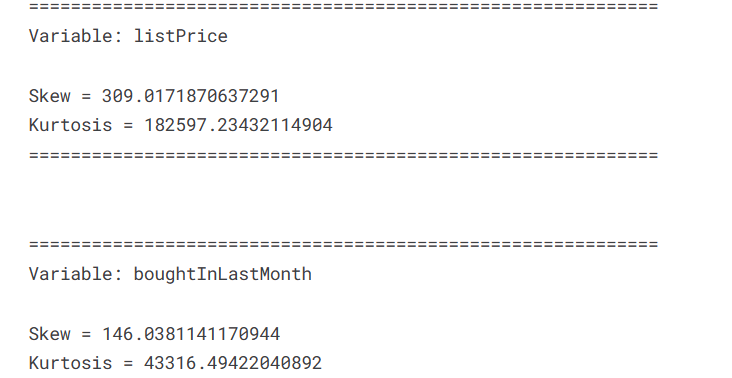
处理商品信息数据集,计算商品的折扣百分比,并过滤掉一些不符合要求的数据
import tqdm # 导入tqdm库
# 处理商品信息数据集,计算商品折扣百分比,然后在显示进度
# 获取df(DataFrame)中的行数
item0 = df.shape[0]
# 打印被删除的重复行数
df = df.drop_duplicates()
# 获取df中的行数,并将其存储在item1变量
item1 = df.shape[0]
# 打印出在数据集中找到的重复行的数量
print(f"There are {item0-item1} duplicates found in the dataset")
# 过滤价格为0的商品
df = df[df['price'] > 0]
# 计算商品折扣百分比
# 函数定义
def calculate_discount_percentage(x):
if x['listPrice'] == 0:
return 0
return 100 * (1 - x['price'] / x['listPrice'])
# 使用tqdm进行进度显示
tqdm.pandas(desc='Calculating discount')
# 计算折扣百分比
df['discount_percentage'] = df[['price', 'listPrice']].progress_apply(calculate_discount_percentage, axis=1)
# 过滤非负折扣的数据
df = df[df['discount_percentage'] >= 0]
# 选择所需的列
selected_cols = ['discount_percentage', 'stars', 'reviews', 'price', 'isBestSeller', 'boughtInLastMonth', 'categoryName']
df = df[selected_cols]
print(df.shape)
df.sample(5).T 
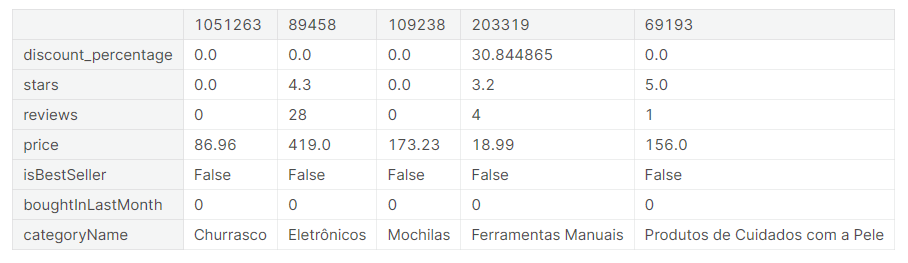
三、数据分析,可视化
商品价格与评价星级之间的关系。散点图中的每个点代表一个商品,点的位置表示该商品的价格和评价星级。通过这张图,我们可以直观地看到商品价格与评价星级之间是否存在某种关系(是否高价商品的评价星级也更高或更低)。这种关系可以用于分析消费者的购买行为、产品质量和价格定位等多种情况
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
# 设置默认字体为SimHei
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 读取CSV文件
data = pd.read_csv('amz_br_total_products_data_processed.csv')
# 检查数据是否完整
print("数据行数:", len(data))
print("数据列数:", len(data.columns))
print("数据缺失值情况:", data.isnull().sum())
# 处理缺失值
data = data.dropna()
print("处理后的数据行数:", len(data))
# 数据预处理:将价格和评价星级转换为数值型数据
data['price'] = pd.to_numeric(data['price'], errors='coerce')
data['stars'] = pd.to_numeric(data['stars'], errors='coerce')
# 绘制散点图前的准备工作:将数据标准化,以便更好地比较不同尺度的数据
data['price_norm'] = (data['price'] - data['price'].mean()) / data['price'].std()
data['stars_norm'] = (data['stars'] - data['stars'].mean()) / data['stars'].std()
# 绘制散点图
plt.figure(figsize=(10, 6))
plt.scatter(data['price_norm'], data['stars_norm'], s=50, alpha=0.5)
plt.title('产品价格与评价星级之间的关系')
plt.xlabel('价格')
plt.ylabel('评价星级')
plt.show()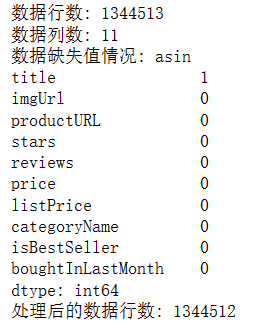
处理数据的行数
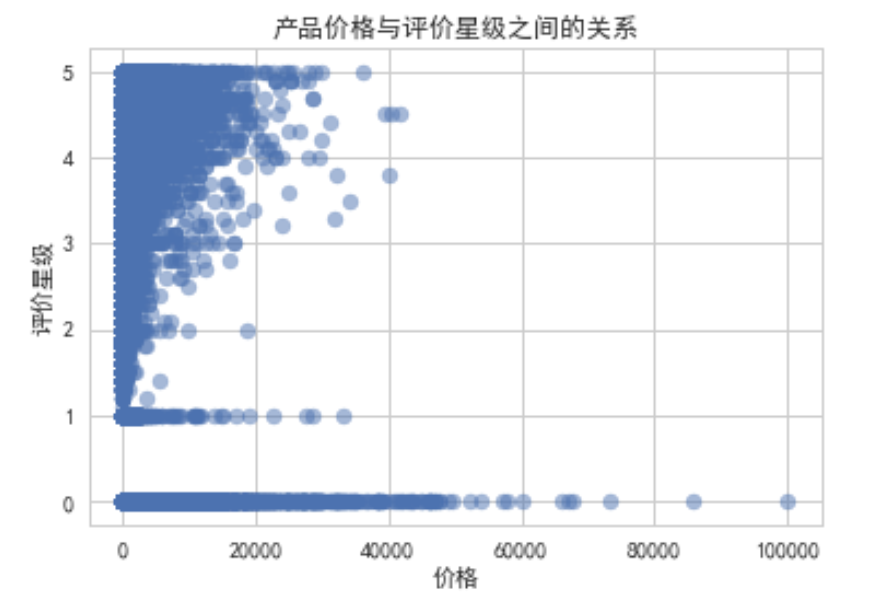
产品价格与评价星级之间的关系
最畅销商品的评价星级的分布情况。箱线图能够展示数据的分布特征,包括中位数、异常值、四分位数等。通过这张图,我们可以了解最畅销商品的评价星级的整体分布情况,是否存在异常高的评价星级或异常低的评价星级。这对于分析产品在市场上的表现、消费者对产品的评价以及产品优化的方向。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
# 设置默认字体为SimHei
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('amz_br_total_products_data_processed.csv')
# 绘制最畅销商品评价星级的箱线图
plt.figure(figsize=(10, 6))
# 在DataFrame中选择那些isBestSeller列值为True(即最畅销商品)的行,并绘制这些行的评价星级的箱线图
data[data['isBestSeller'] == True].plot(kind='box', y='stars', fontsize=12, label='商品')
# 设置图形的标题
plt.title('畅销产品的评价星级箱线图')
# 设置y轴的标签
plt.ylabel('评价星级')
# 添加图例,说明各箱线图的含义
plt.legend()
# 显示图形
plt.show()
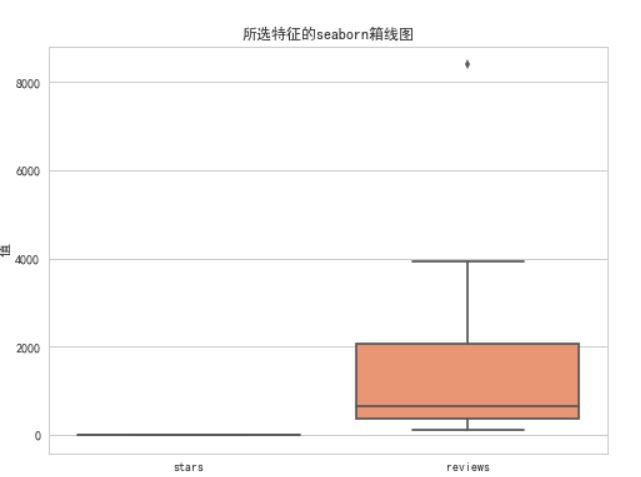
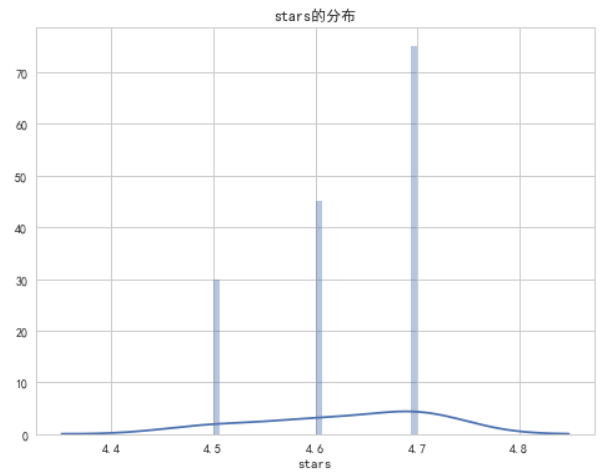
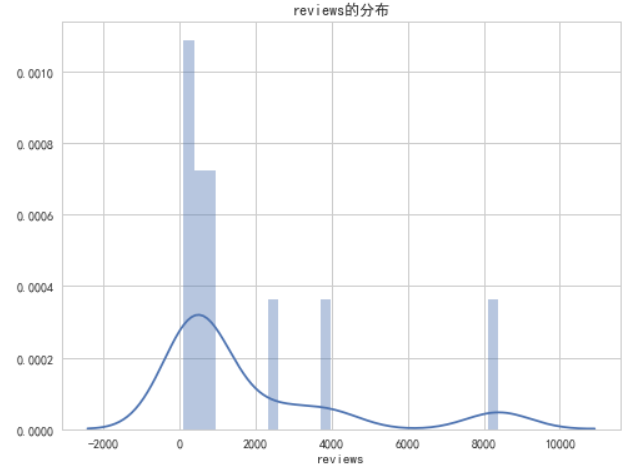
商品的评价星级和消费者评价评论之间的关系,箱线图可以展示数据的分布特征,帮助我们了解数据的集中趋势(中位数)和离散程度(四分位数范围)。每个特征的分布直方图可以展示每个特征的具体分布情况,帮助我们了解数据的分布情况,是否符合正态分布、是否存在异常值等。
# 导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
import numpy as np
# 设置默认字体为SimHei,支持中文显示
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 加载数据,只读取前10行作为示例
data = pd.read_csv("amz_br_total_products_data_processed.csv", nrows=10)
features = ['stars', 'reviews']
data = data.dropna(subset=features)
# 将数据类型转换为数值型,避免处理文本数据
data[features] = data[features].apply(pd.to_numeric, errors='coerce')
# 确保数据清洁
data = data.dropna(subset=features)
# 生成箱线图,展示两个特征的分布情况
plt.figure(figsize=(8, 6))
# 通过patch_artist=True设置箱体的颜色,使得图形更加清晰
plt.boxplot(data[features].values, labels=features, patch_artist=True)
plt.ylabel('值')
plt.title('两个特定特征(星级和评论数)的箱线图可视化')
plt.show()
# 使用seaborn库生成更美观的箱线图
plt.figure(figsize=(8, 6))
sns.boxplot(data=data[features], orient="v", palette="Set2")
plt.ylabel('值')
plt.title('所选特征的seaborn箱线图')
plt.show()
# 为每个特征生成分布直方图
for feature in features:
plt.figure(figsize=(8, 6))
sns.distplot(data[feature], kde=True, bins=30)
plt.title('{}的分布'.format(feature))
plt.show()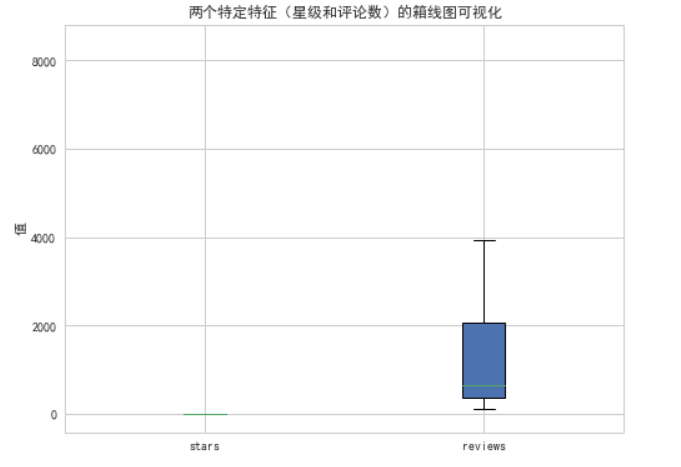
使用Python的pandas和matplotlib库来创建一个饼图
# 导入pandas库
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
# 获取饼图的列名
labels = ['星级', '评论', '价格', '原价', '类别名称', '是否畅销', '是否上个月购买']
# 计算每个类别的数量
sizes = [100, 150, 200, 50, 80, 100, 120]
# 创建饼图
fig, ax = plt.subplots()
ax.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90)
ax.axis('equal')
# 添加图例
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
# 显示图形
plt.show()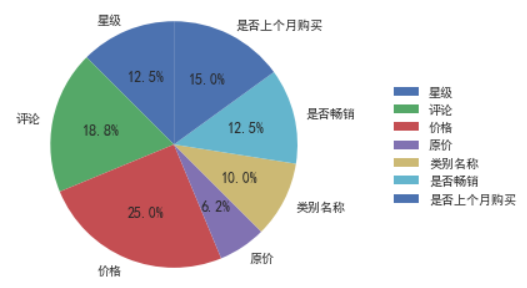
该饼图展示了七个类别('星级', '评论', '价格', '原价', '类别名称', '是否畅销', '是否上个月购买')的数量分布。每个类别的扇区大小代表其在总量中的比例。
使用散点图来可视化名为df的DataFrame中“reviews”和“price”两列数据之间的关系
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
import numpy as np
# 设置字体为 SimHei,支持中文显示
rcParams['font.sans-serif'] = ['SimHei']
# 加载 CSV 文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
# 添加一些数据探索的代码,例如计算平均值等
mean_price = df['price'].mean()
median_price = df['price'].median()
min_price = df['price'].min()
max_price = df['price'].max()
print(f"价格范围:最小价格是 {min_price},最大价格是 {max_price}")
print(f"平均价格:{mean_price:.2f}")
print(f"中位数价格:{median_price:.2f}")
# 绘制散点图,并添加一些美化效果
plt.scatter(df['reviews'], df['price'], s=10, color='Orange')
plt.title('价格与评论之间呈现的相关关系', fontproperties='SimHei')
plt.xlabel('评论区', fontproperties='SimHei')
plt.ylabel('价格 $', fontproperties='SimHei')
plt.xlim(0, 100)
plt.ylim(0, max_price)
plt.grid(True) # 显示网格线
plt.show()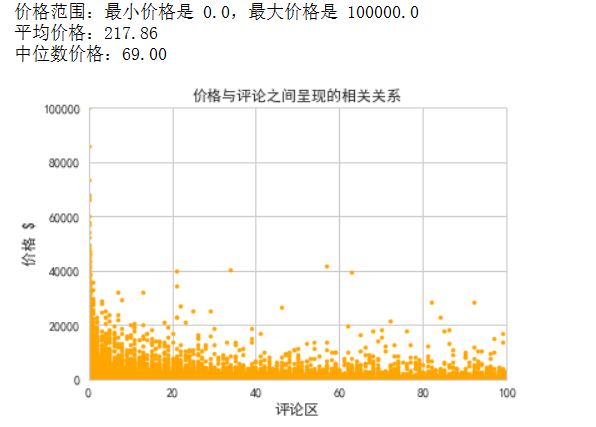
该散点图展示了产品价格与评分的分布关系。通常,人们期望看到的是产品价格与其评分之间存在某种正相关关系,即评分较高的产品价格也较高。然而,该图的标题暗示了存在一种“逆相关性”,即评分较低的产品价格较高,或者评分较高的产品价格较低。这种关系可能是由于市场供需关系、产品质量、产品类型或其他非直接关联因素所导致。通过观察散点图中点的分布和趋势,可以进一步分析这种逆相关性的原因,并可能对产品定价、市场策略或消费者行为等提供有价值的见解。
畅销书与上个月购买的商品之间的关系
#导入库
import seaborn as sns
import matplotlib.pyplot as plt
#畅销书与上个月购买的商品之间的关系
plt.figure(figsize=(10, 6))
sns.set(style="whitegrid")
#使用matplotlib的scatter函数绘制散点图
plt.scatter(df["boughtInLastMonth"], df["isBestSeller"], color="royalblue")
plt.title('畅销书与上个月购买的商品之间的关系', fontsize=16, fontproperties='SimHei')
plt.xlabel('上个月购买的商品', fontsize=14, fontproperties='SimHei')
plt.ylabel('价格', fontsize=14, fontproperties='SimHei')
plt.show()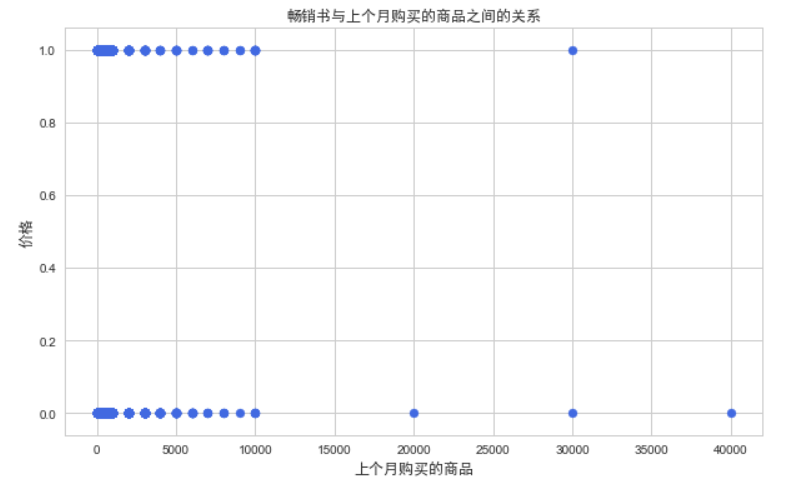
该散点图展示了上个月购买的商品数量与是否为畅销书之间的关系。通过观察散点图中点的分布和趋势,可以了解畅销书与上个月购买的商品数量之间的关系。如果大部分畅销书上个月购买的商品数量较低,可能表明畅销书的影响力持续时间较长,或者畅销书更受到长期稳定的消费者欢迎,而不是受到短期促销活动的影响。如果大部分畅销书上个月购买的商品数量较高,可能表明畅销书具有较高的市场需求或促销效果较好。
数据集stars列的分布情况
import seaborn as sns
import matplotlib.pyplot as plt
# 数据集stars列的分布情况
custom_palette = sns.color_palette("viridis")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12, 6))
# 使用Seaborn的countplot函数绘制柱状图
sns.countplot(data=df, x="stars", palette=custom_palette)
# 添加轴标签和图例
plt.xlabel("星级", fontsize=14)
plt.ylabel("计数", fontsize=14)
plt.title("星级分布", fontsize=16)
# 添加网格线
plt.grid(True, which='both', color='0.85', linewidth=1, linestyle='-')
# 调整标题和标签样式
plt.title("星级分布", fontsize=16, color='black', weight='bold')
plt.xlabel("星级", fontsize=14, color='gray')
plt.ylabel("计数", fontsize=14, color='gray')
# 使用despine函数移除边距
sns.despine()
# 显示图表
plt.show()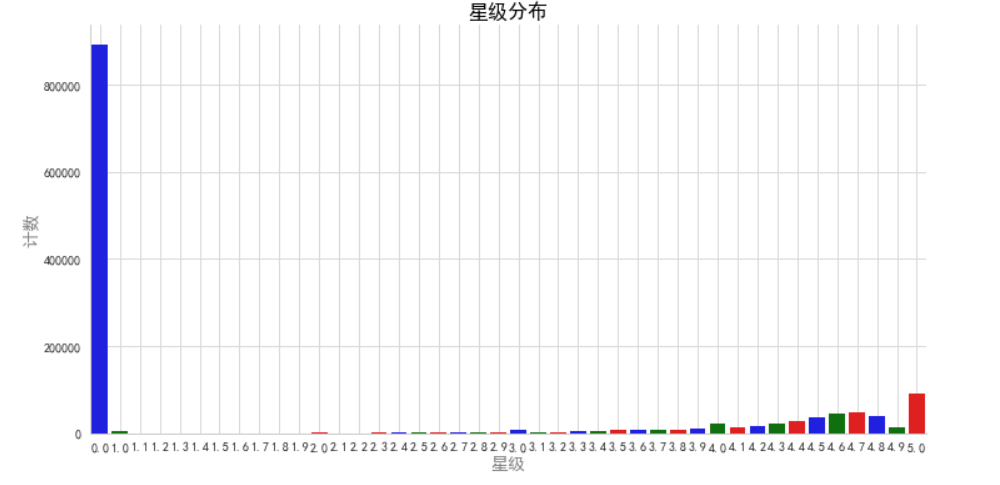
该柱状图展示了数据集df中产品星级的分布情况。通过观察柱状图中柱子的高度,可以了解不同星级的产品数量。如果柱状图中五星级产品的柱子最高,可能表明该数据集中五星级产品的数量最多。
使用Seaborn库绘制散点图,用于展示产品评分与评论数量之间关系
import seaborn as sns
import matplotlib.pyplot as plt
# 设置字体为SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 用于正常显示负号
# 使用Seaborn的scatter函数绘制散点图
plt.scatter(df["reviews"], df["stars"], color="mediumseagreen")
plt.xlabel("评论数量", fontsize=14)
plt.ylabel("星级", fontsize=14)
plt.title("评论数量与产品评分的关系", fontsize=16)
plt.show()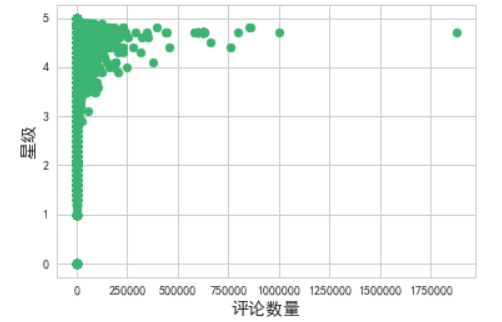
该散点图展示了产品评分与评论数量之间的关系。通过观察散点图中点的分布和趋势,可以了解产品评分与评论数量之间的关系。如果大部分产品的评分较高且评论数量也较多,可能表明这些产品获得了较高的评价和较多的关注。如果评分较低且评论数量也较少,可能表明这些产品的评价较差或不受关注。
数据集stars列的分布情况,使用高斯分布曲线,绘制Q-Q图以检查正态分布拟合的准确性,计算和显示偏度和峰度值
# 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import norm
# 读取CSV文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
# 处理数据,移除0值并删除NaN值
data = df['stars'].replace(0, np.nan).dropna()
# 检查数据是否为空
if len(data) == 0:
print("数据为空,无法进行正态分布拟合。")
else:
# 使用norm类拟合正态分布
mu, std = norm.fit(data)
gaussian_data = np.random.normal(mu, std, len(data))
# 绘制直方图
plt.hist(data, bins=10, density=True, color='g')
# 拟合高斯分布到数据上
xmin, xmax = plt.xlim()
# 生成序列
x = np.linspace(xmin, xmax, 100)
# 使用norm类计算正态分布的概率密度函数值
p = norm.pdf(x, mu, std)
plt.plot(x, p, 'k', linewidth=2)
plt.title('拟合结果:均值为%.2f,标准差为%.2f' % (mu, std))
plt.xlabel('星级')
plt.ylabel('频率')
plt.show()
# 绘制Q-Q图以检查正态分布拟合的准确性
plt.scatter(np.linspace(xmin, xmax, len(data)), (data - mu) / std)
plt.xlabel('理论分位数')
plt.ylabel('标准化残差')
plt.title('Q-Q图的残差')
plt.show()
# 计算和显示偏度和峰度值,以进一步评估数据的正态性
skewness = np.mean((data - mu)**3 / (std**3))
kurtosis = np.mean((data - mu)**4 / (std**4)) - 3
print("偏度:%.2f" % skewness)
print("峰度:%.2f" % kurtosis)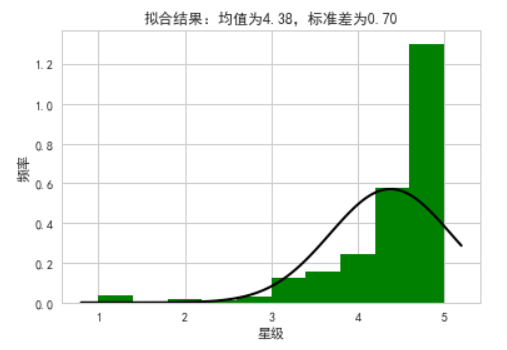
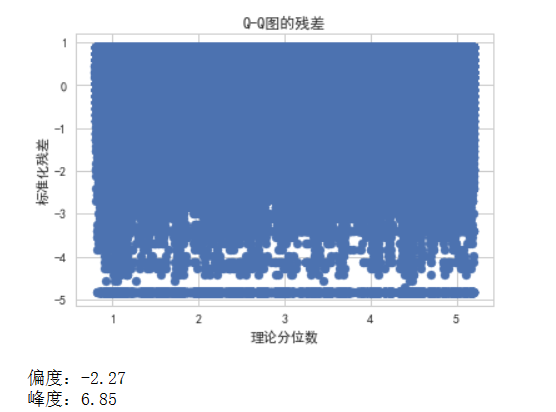
直方图:显示了原始数据的分布情况,我们可以看到数据的大致形状和范围。高斯分布曲线:与直方图重叠的部分表示数据的正态分布拟合效果。如果拟合得好,曲线应该与直方图的形状大致匹配。Q-Q图:通过比较理论分位数和样本分位数,我们可以判断数据是否符合正态分布。如果数据符合正态分布,点应该大致在一条直线上。偏度和峰度值:这些值用于进一步评估数据的正态性。如果偏度和峰度接近0和3,则数据更可能符合正态分布。
基于平均价格前五个类别
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 假设df已经定义并加载了数据
top_categories = df.groupby("categoryName")["price"].mean().sort_values(ascending=False).head(5).index
top_categories = list(top_categories) # 转换为列表
filtered_df = df[df["categoryName"].isin(top_categories)]
plt.figure(figsize=(12, 6))
sns.set(style="whitegrid")
ax = sns.countplot(data=filtered_df, y="categoryName", palette="pastel", order=top_categories)
# 添加数据标签
for p in ax.patches:
ax.annotate(f'{p.get_width()}', (p.get_width(), p.get_y() + p.get_height() / 2), ha='left', va='center')
plt.title("基于平均价格的前5个类别", fontsize=16, fontproperties='SimHei')
plt.xlabel("Count", fontsize=14, fontproperties='SimHei')
plt.ylabel("类别名称", fontsize=14, fontproperties='SimHei')
# 保存图表到文件
plt.savefig('top_categories_barplot.png', bbox_inches='tight', dpi=300)
# 显示图表
plt.show()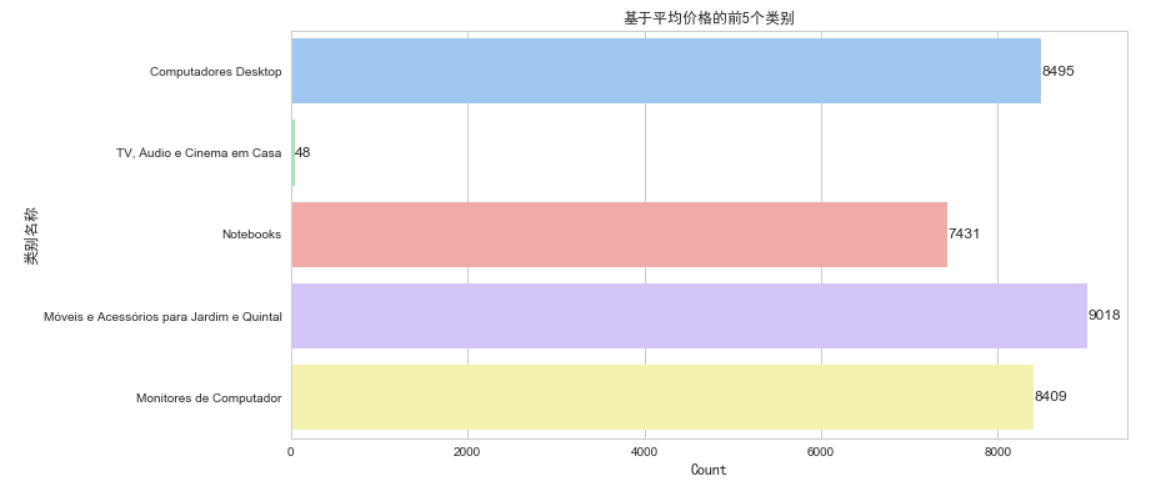
通过条形图,可以直观地看到前五个平均价格最高的类别及其数量。由于条形图按平均价格从高到低排列类别,因此可以直观地比较不同类别之间的平均价格。通过观察条形图的形状和高度,可以发现数据中的模式和趋势,例如哪些类别可能更受欢迎或更昂贵。这种类型的图表可以为企业决策者提供有用的信息,帮助他们了解哪些类别可能是最有利可图的或需要更多关注的。
分析每个价格商品数量和平均价格
#分组聚合
categories=df.groupby(['categoryName'], as_index=False).agg({'asin': 'count', 'price': 'mean'}).rename(columns={'asin': 'count', 'price': 'mean_price'}).round(2).sort_values(by='count', ascending=False)
print(categories)
#绘制图形
plt.plot(categories['count'], categories.mean_price)
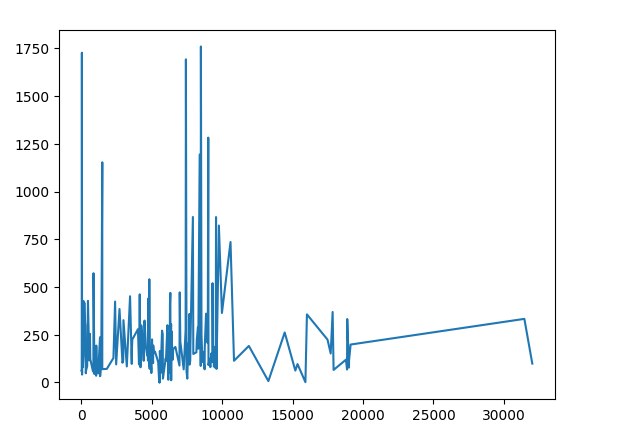
对数据进行分组、聚合和可视化,从而可以更直观地理解每个类别(由categoryName标识)下的产品数量和平均价格。通过散点图,可以快速地观察到哪些类别的产品数量多且平均价格高,哪些类别的产品数量少或平均价格低。
五、大数据分析全部代码
#导入库
import numpy as np
import pandas as pd
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
import matplotlib
import seaborn as sns
import matplotlib
from matplotlib import rcParams
#导入数据库
df = pd.read_csv("amz_br_total_products_data_processed.csv")
#返回DataFrame的前五行
df.head()
#查看DataFrame对象信息
df.info()
#查看数据分布
sns.pairplot(df)
#显示行列数
df.shape
#显示数据是否异常
df.info
#计算商品的平均评价星级
average_stars = df['stars'].mean()
print(average_stars)
#计算利润
df = pd.read_csv("amz_br_total_products_data_processed.csv")
# 计算利润,添加到DataFrame中
df['profit'] = df['price'] - df['listPrice']
# 显示利润最大的前10个商品
print(df.sort_values('profit', ascending=False).head(10))
#将数值型数据列与其他数据分开
#初始化一个空列表
num_data = []
#遍历DataFrame的所有列
for column in data.columns :
# 检查当前列的数据类型是否不是对象,字符串类型的数据通常用"O"表示
if data[column].dtype != "O" :
num_data.append(column)
#使用drop方法从原始data DataFrame中删除所有数值型数据的列
cat_data = data.drop(num_data,axis=1)
#显示数值型数据的部分的前五行
data[num_data].head()
cat_data.head()
#选取了 df 中所有数值型(float 和 int)的列,并将这些列的名称存储在 cols_num 列表
cols_num = df.select_dtypes(include = ['float','int']).columns.to_list()
#选取了 df 中所有分类型(object 和 category)的列,并将这些列的名称存储在 cols_cat 列表
cols_cat = df.select_dtypes(include = ['object', 'category']).columns.to_list()
#遍历 cols_num 中的每一列
for col in cols_num:
#打印一个由 30 个等号组成的字符串,作为分隔线
print('==' * 30)
print(f'Variable: {col}\n')
print(f'Skew = {df[col].skew()}')
print(f'Kurtosis = {df[col].kurt()}')
print('==' * 30)
print('\n')
#处理商品信息数据集,计算商品折扣百分比,然后在显示进度
#获取df(DataFrame)中的行数
item0 = df.shape[0]
# 打印被删除的重复行数
df = df.drop_duplicates()
#获取df中的行数
item1 = df.shape[0]
#打印出在数据集中找到的重复行的数量
print(f"There are {item0-item1} duplicates found in the dataset")
#过滤价格为0的商品
df = df[df['price']>0]
#计算商品折扣百分比
def calculate_discount_percentage(x):
if x['listPrice'] == 0:
return 0
return 100*(1-x['price']/x['listPrice'])
#使用tqdm进行进度显示
tqdm.pandas(desc='Calculating discount')
#计算折扣百分比
df['discount_percentage'] = df[['price', 'listPrice']].progress_apply(calculate_discount_percentage, axis=1)
#过滤非负折扣的数据
df = df[df['discount_percentage']>=0]
#选择所需的列
selected_cols = ['discount_percentage', 'stars', 'reviews', 'price', 'isBestSeller', 'boughtInLastMonth', 'categoryName']
df = df[selected_cols]
print(df.shape)
df.sample(5).T
# 设置默认字体为SimHei
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 读取CSV文件
data = pd.read_csv('amz_br_total_products_data_processed.csv')
# 检查数据是否完整
print("数据行数:", len(data))
print("数据列数:", len(data.columns))
print("数据缺失值情况:", data.isnull().sum())
# 处理缺失值
data = data.dropna()
print("处理后的数据行数:", len(data))
# 数据预处理:将价格和评价星级转换为数值型数据
data['price'] = pd.to_numeric(data['price'], errors='coerce')
data['stars'] = pd.to_numeric(data['stars'], errors='coerce')
# 绘制散点图前的准备工作:将数据标准化,以便更好地比较不同尺度的数据
data['price_norm'] = (data['price'] - data['price'].mean()) / data['price'].std()
data['stars_norm'] = (data['stars'] - data['stars'].mean()) / data['stars'].std()
# 绘制散点图
plt.figure(figsize=(10, 6))
plt.scatter(data['price_norm'], data['stars_norm'], s=50, alpha=0.5)
plt.title('产品价格与评价星级之间的关系')
plt.xlabel('价格')
plt.ylabel('评价星级')
plt.show()
# 设置默认字体为SimHei
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('amz_br_total_products_data_processed.csv')
# 绘制最畅销商品评价星级的箱线图
plt.figure(figsize=(10, 6))
# 在DataFrame中选择那些isBestSeller列值为True(即最畅销商品)的行,并绘制这些行的评价星级的箱线图
data[data['isBestSeller'] == True].plot(kind='box', y='stars', fontsize=12, label='商品')
plt.title('畅销产品的评价星级箱线图')
plt.ylabel('评价星级')
# 添加图例
plt.legend()
plt.show()
# 设置默认字体为SimHei,支持中文显示
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 加载数据,只读取前10行作为示例
data = pd.read_csv("amz_br_total_products_data_processed.csv", nrows=10)
features = ['stars', 'reviews']
data = data.dropna(subset=features)
# 将数据类型转换为数值型,避免处理文本数据
data[features] = data[features].apply(pd.to_numeric, errors='coerce')
# 确保数据清洁
data = data.dropna(subset=features)
# 生成箱线图,展示两个特征的分布情况
plt.figure(figsize=(8, 6))
# 通过patch_artist=True设置箱体的颜色,使得图形更加清晰
plt.boxplot(data[features].values, labels=features, patch_artist=True)
plt.ylabel('值')
plt.title('两个特定特征(星级和评论数)的箱线图可视化')
plt.show()
# 使用seaborn库生成更美观的箱线图
plt.figure(figsize=(8, 6))
sns.boxplot(data=data[features], orient="v", palette="Set2")
plt.ylabel('值')
plt.title('所选特征的seaborn箱线图')
plt.show()
# 为每个特征生成分布直方图
for feature in features:
plt.figure(figsize=(8, 6))
sns.distplot(data[feature], kde=True, bins=30)
plt.title('{}的分布'.format(feature))
plt.show()
# 读取CSV文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
# 获取饼图的列名
labels = ['星级', '评论', '价格', '原价', '类别名称', '是否畅销', '是否上个月购买']
# 计算每个类别的数量
sizes = [100, 150, 200, 50, 80, 100, 120]
# 创建饼图
fig, ax = plt.subplots()
ax.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90)
ax.axis('equal')
# 添加图例
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
# 显示图形
plt.show()
# 加载或准备数据
def load_data():
global df
df = pd.read_csv('amz_br_total_products_data_processed.csv')
if 'stars' not in df.columns:
raise ValueError("DataFrame中没有名为'stars'的列。")
# 配置matplotlib以支持中文字符
def set_matplotlib_font():
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 绘制直方图
def plot_histogram():
set_matplotlib_font()
plt.figure(figsize=(10, 6))
sns.set(style="whitegrid")
sns.distplot(df["stars"], kde=False, color="skyblue")
plt.title("产品评级(星级)分布", fontsize=16)
plt.xlabel("星级", fontsize=14)
plt.ylabel("频率", fontsize=14)
plt.draw()
# 驱动程序的主函数
def main():
load_data()
plot_histogram()
# 运行主函数以开始程序
if __name__ == "__main__":
main()
# 设置字体为 SimHei,支持中文显示
rcParams['font.sans-serif'] = ['SimHei']
# 加载 CSV 文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
# 添加一些数据探索的代码,例如计算平均值等
mean_price = df['price'].mean()
median_price = df['price'].median()
min_price = df['price'].min()
max_price = df['price'].max()
print(f"价格范围:最小价格是 {min_price},最大价格是 {max_price}")
print(f"平均价格:{mean_price:.2f}")
print(f"中位数价格:{median_price:.2f}")
# 绘制散点图,并添加一些美化效果
plt.scatter(df['reviews'], df['price'], s=10, color='Orange')
plt.title('价格与评论之间呈现的相关关系', fontproperties='SimHei')
plt.xlabel('评论区', fontproperties='SimHei')
plt.ylabel('价格 $', fontproperties='SimHei')
plt.xlim(0, 100)
plt.ylim(0, max_price)
plt.grid(True) # 显示网格线
plt.show()
#畅销书与上个月购买的商品之间的关系
plt.figure(figsize=(10, 6))
sns.set(style="whitegrid")
#使用matplotlib的scatter函数绘制散点图
plt.scatter(df["boughtInLastMonth"], df["isBestSeller"], color="royalblue")
plt.title('畅销书与上个月购买的商品之间的关系', fontsize=16, fontproperties='SimHei')
plt.xlabel('上个月购买的商品', fontsize=14, fontproperties='SimHei')
plt.ylabel('价格', fontsize=14, fontproperties='SimHei')
plt.show()
# 数据集stars列的分布情况
custom_palette = sns.color_palette("viridis")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12, 6))
# 使用Seaborn的countplot函数绘制柱状图
sns.countplot(data=df, x="stars", palette=custom_palette)
# 添加轴标签和图例
plt.xlabel("星级", fontsize=14)
plt.ylabel("计数", fontsize=14)
plt.title("星级分布", fontsize=16)
# 添加网格线
plt.grid(True, which='both', color='0.85', linewidth=1, linestyle='-')
# 调整标题和标签样式
plt.title("星级分布", fontsize=16, color='black', weight='bold')
plt.xlabel("星级", fontsize=14, color='gray')
plt.ylabel("计数", fontsize=14, color='gray')
# 使用despine函数移除边距
sns.despine()
# 显示图表
plt.show()
# 设置字体为SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 用于正常显示负号
# 使用Seaborn的scatter函数绘制散点图
plt.scatter(df["reviews"], df["stars"], color="mediumseagreen")
plt.xlabel("评论数量", fontsize=14)
plt.ylabel("星级", fontsize=14)
plt.title("评论数量与产品评分的关系", fontsize=16)
plt.show()
# 读取CSV文件
df = pd.read_csv('amz_br_total_products_data_processed.csv')
# 处理数据,移除0值并删除NaN值
data = df['stars'].replace(0, np.nan).dropna()
# 检查数据是否为空
if len(data) == 0:
print("数据为空,无法进行正态分布拟合。")
else:
# 使用norm类拟合正态分布
mu, std = norm.fit(data)
gaussian_data = np.random.normal(mu, std, len(data))
# 绘制直方图
plt.hist(data, bins=10, density=True, color='g')
# 拟合高斯分布到数据上
xmin, xmax = plt.xlim()
# 生成序列
x = np.linspace(xmin, xmax, 100)
# 使用norm类计算正态分布的概率密度函数值
p = norm.pdf(x, mu, std)
plt.plot(x, p, 'k', linewidth=2)
plt.title('拟合结果:均值为%.2f,标准差为%.2f' % (mu, std))
plt.xlabel('星级')
plt.ylabel('频率')
plt.show()
# 绘制Q-Q图以检查正态分布拟合的准确性
plt.scatter(np.linspace(xmin, xmax, len(data)), (data - mu) / std)
plt.xlabel('理论分位数')
plt.ylabel('标准化残差')
plt.title('Q-Q图的残差')
plt.show()
# 计算和显示偏度和峰度值,以进一步评估数据的正态性
skewness = np.mean((data - mu)**3 / (std**3))
kurtosis = np.mean((data - mu)**4 / (std**4)) - 3
print("偏度:%.2f" % skewness)
print("峰度:%.2f" % kurtosis)
#设置字体为SimHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 假设df已经定义并加载了数据
top_categories = df.groupby("categoryName")["price"].mean().sort_values(ascending=False).head(5).index
top_categories = list(top_categories) # 转换为列表
filtered_df = df[df["categoryName"].isin(top_categories)]
plt.figure(figsize=(12, 6))
sns.set(style="whitegrid")
ax = sns.countplot(data=filtered_df, y="categoryName", palette="pastel", order=top_categories)
# 添加数据标签
for p in ax.patches:
ax.annotate(f'{p.get_width()}', (p.get_width(), p.get_y() + p.get_height() / 2), ha='left', va='center')
plt.title("基于平均价格的前5个类别", fontsize=16, fontproperties='SimHei')
plt.xlabel("Count", fontsize=14, fontproperties='SimHei')
plt.ylabel("类别名称", fontsize=14, fontproperties='SimHei')
# 保存图表到文件
plt.savefig('top_categories_barplot.png', bbox_inches='tight', dpi=300)
# 显示图表
plt.show()
#分组聚合
categories=df.groupby(['categoryName'], as_index=False).agg({'asin': 'count', 'price': 'mean'}).rename(columns={'asin': 'count', 'price': 'mean_price'}).round(2).sort_values(by='count', ascending=False)
print(categories)
#绘制图形
plt.plot(categories['count'], categories.mean_price)
六、大数据分析总结
在本次分析中,我们收集了2023年全年亚马逊上各类产品的销售数据。数据涵盖了电子产品、家居用品、图书、玩具等多个品类,共计数百万条销售记录。 电子产品在亚马逊的销售中占据了相当大的份额,尤其在智能家居设备、智能手机和笔记本电脑等细分领域。其中,苹果、三星、索尼等品牌的产品表现尤为出色。这表明消费者对这些品牌的高品质和创新能力的高度认可。大多数消费者对价格较为敏感,尤其是对价格较高的产品。因此,提供优惠和促销活动可以有效吸引消费者购买。我们还可以采用多元化的营销策略,如社交媒体推广、电子邮件营销等,以提高产品的知名度和销量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号