
XLM论文原理解析
1. 前言
近一年来,NLP领域发展势头强劲,从ELMO到LSTM再到去年最牛叉的Google Bert,在今年年初,Facebook又推出了XLM模型,在跨语言预训练领域表现抢眼。实验结果显示XLM在XNLI任务上比原来的state-of-the-art直接高了4.9个百分点;在无监督机器翻译WMT’16 German-English中,比原来的state-of-the-art高了9个BLEU;在有监督的机器翻译WMT’16 Romanian-English中,比原来的state-of-the-art高了4个BLEU。
最近的研究已经证明了生成预训练对于英语自然语言理解的有效性。在这项工作中,我们将这种方法扩展到多种语言并展示跨语言预训练的有效性。我们提出了两种学习跨语言语言模型(XLM)的方法:一种是无监督方式,只依赖于单语言数据,另一种是监督,利用新的跨语言语言模型目标来利用并行数据。我们获得了关于跨语言分类,非监督和监督机器翻译的最新结果。
2. 介绍
句子编码器的生成式预训练(Generative pretraining)已经使许多自然语言理解的 benchmark 取得了显著的进步。在此背景下,Transformer 语言模型在大型无监督文本语料库上学习后,再针对具体的自然语言理解 (NLU) 任务进行微调,如分类或自然语言推理。尽管目前研究人员对学习通用句子表示的兴趣激增,但该领域的研究基本上都是集中在英语 Benchmark上。学习和评估多语言的跨语言句子表示的最新进展,旨在减轻以英语为中心的偏见,并提出可以构建通用的跨语言编码器,将任何句子编码到共享嵌入空间中。在本文的工作中,证明了跨语言模型预训练在多个跨语言理解(XLU)benchmark 上的有效性。具体来说,本文工作有以下贡献:
- 提出了一种新的无监督方法。使用跨语言语言建模来学习跨语言表示,并研究了两种单语预训练的目标函数。
- 提出一个新的监督学习目标。当有平行语料时,该目标可以改进跨语言的预训练。
- 本文的模型在跨语言分类、无监督机器翻译和有监督机器翻译方面都显著优于以往的最优结果。
- 本文实验表明跨语言模型对于low-resource 语种数据集,也能够显著改善其他语种的困惑度(perplexity)。
3. 跨语言模型
本文提出3个语言模型目标函数,其中2个仅仅需要单语种数据集(无监督方式),另一个需要平行语料(有监督方式)。假设有个N个语种,对应的语料记为\(\{C_i\}_{i=1…N}\)表示\(C_i\)中的句子数量。
3.1 sub-word字典
在本文的所有实验中,所有语种共用一个字典,该字典是通过Byte Pair Encoding (BPE)构建的。共享的内容包括相同的字母、符号token如数字符号、专有名词。这种共享字典能够显著的提升不同语种在嵌入空间的对齐效果。本文在单语料库中从随机多项式分布中采样句子进行BPE学习。为了保证平衡语料,句子的采样服从多项式分布:
其中\(\alpha=0.5\)。使用这种分布抽样,可以增加分配给low-resource 语种的token数量,并减轻对high-resource 语种的偏见。这可以防止low-resource 语种数据集的单词在字符级被分割。
3.2 因果语言模型(CLM)
使用Transformer在给定前序词语的情况下预测下一个词的概率。
本文的因果语言建模 (CLM) 任务其实是一个Transformer语言模型,该模型被训练来对给定句子预测后一个单词的概率,\(P(w_t∣w_1,…,w_{t−1},θ)\)。虽然 CNN 在语言建模基准(benchmarks)测试中是性能最好的, 但Transformer 模型也很有竞争力。
在 LSTM 语言模型的情况下,通过向 LSTM 提供上一个迭代的最后隐藏状态来执行时间反向传播 (backpropagation through time, BPTT)。对于 Transformer,可以将之前的隐藏状态传递给当前的batch,为当前batch中的第一个单词提供上下文信息。但是,这种技术不能扩展到跨语言,因此为了简单起见,我们只保留每个 batch 中的第一个单词,而不考虑上下文。
3.3 掩模语言模型(MLM)
本文也采用Devlin et al. (2018) 论文中提出的掩模语言模型(MLM),也称为完形填空任务。与Devlin等人一样,我们从文本流中随机抽取 15% 的 BPE token,使用的时候,80%的时间用 [MASK] token 替换,10%时间的用随机 token 替换,10%时候保持不变。与其不同的是,本文使用由任意数量的句子(每个句子截断为256个token)组成的文本流代替成对的句子。为了均衡稀有tokens和高频tokens(比如标点符号和停止词),本文采用类似于Mikolov et al. (2013b)的方法对高频词汇进行二次采样:文本流中的tokens都是以多项式分布进行采样的,其权重与它们的逆文本频率的平方根成正比。本文的MLM目标如图1所示:
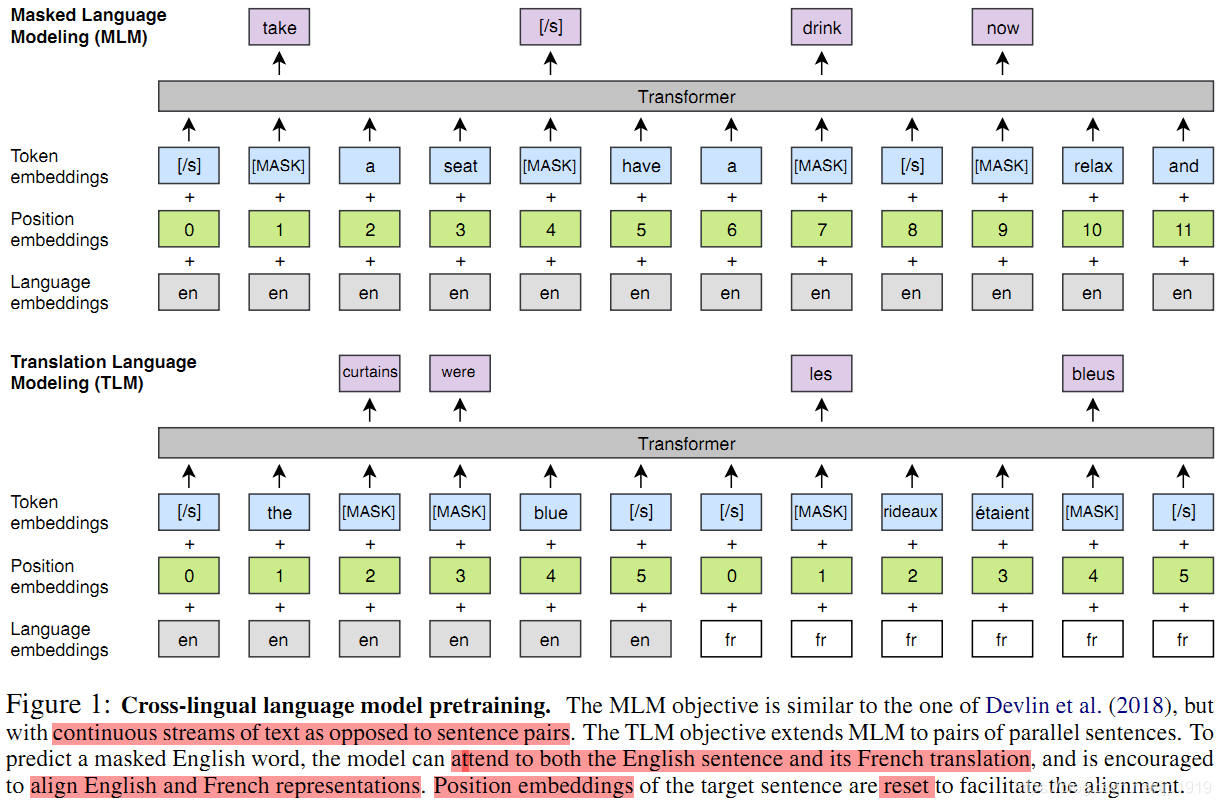
图 1: 跨语言模型预训练。 MLM 目标类似于 Devlin et al. (2018) 里的,但不是句子对,是连续的文本流。TLM 目标将 MLM 扩展到并行的句子对。为了预测一个被遮挡的英语单词,该模型可以同时考虑英语句子及其法语翻译,并鼓励将英语和法语表进行示对齐。目标句子的位置嵌入被重置以方便对齐。
3.4 翻译语言模型(TLM)
CLM 和 MLM都是无监督的,只需要单语数据。但是,当存在平行语料数据时,上述两者都无法使用。为此本文提出一种新的翻译语言建模方法 (TLM) 来提高跨语言训练的效果。TLM的目标是MLM的扩展,TLM不考虑单语种的文本流, 而是将并行的翻译句子拼接起来,如图 1 所示的第三张图片,在source 句子和 target 句子中都随机mask掉words。当要预测英文句子中被masked的word时,该模型不仅能够注意到英文words还能够注意到法语的翻译内容。这就引导模型将英语和法语的表征进行对齐。特别地,该模型在英文句子不足以推断出被masked的英文单词时,能够利用法语上下文信息。为了方便对齐,在target句子部分,位置编码需要重置。
3.5 跨语言模型
本文的跨语言预训练模型由于 CLM与MLM,或MLM与TLM结合的模型组成。对于CLM和MLM的目标,本文训练模型过程使用的每个batch由64个句子流组成,每个句子流由256 个 token 组成。每次的迭代,一个batch来自同一个语种中的句子,句子则是按照此前介绍的多项式分布采样得到$${q_i}_{i=1…N}$$ ,其中\(\alpha=0.7\)*当TLM联合MLM使用时,需要在这两个目标之间交替,并使用类似的方法对翻译对进行采样。
4. 跨语言模型的预训练
本章节主要介绍如何训练得到跨语言模型:
- 得到一个能够处理zero-shot跨语言分类任务的初始化更好的句子编码器
- 初始化更好的有监督和无监督的神经机器翻译系统
- 低资源(low-resource)语言的语言模型
- 无监督的跨语言词汇嵌入
4.1 跨语言分类器
本文预训练的XLM模型提供通用的跨语言文本表示。在英文文本分类任务上,本文的XLM与单语种语言模型下的微调类似,在一个跨语言分类benchmark上进行微调。本文这里使用cross-lingual natural language inference (XNLI)数据集。准确地讲,本文在预训练的Transformer的第一个隐藏状态之上加入一个线性分类器,再在英文NLI训练集上进行微调所有参数。之后,在15个XNIL 语种数据集上评估模型。此外,本文还在训练集和测试集上以机器翻译任务做了性能对比。具体结果在Table 1中。
4.2 无监督机器翻译
预训练是无监督神经机器翻译的重要部分,Lample et al.(2018b)的研究表明用于初始化查找表的预训练跨语言单词嵌入, 对无监督机器翻译模型的性能有重要影响。本文进一步提出用跨语言模型对整个encoder和decoder进行预训练,以提升无监督神经机器翻译的性能。本文探索了多种不同的初始化策略,并评估了各种策略在标准机器翻译任务(包括WMT’14 English-French,
WMT’16 English-German and WMT’16 English-Romanian)中的表现。详细结果请见Table 2。
4.3 有监督机器翻译
本文同时研究跨语言预训练对于有监督机器翻译的影响。并将Ramachandran et al. (2016)的方法进一步拓展到多语种神经机器翻译中。本文在WMT’16 Romanian-English中评估了CLM和MLM预训练的影响, 其结果见于Table 3。
4.4 low-resource语言建模
对于资源较少的语言,可以使用数据较相似的资源较多的语言进行预训练,特别是它们的词汇表很大部分相同时。比如,在维基上有100k个尼泊尔语的句子,其数量是印地语的6倍。这两种语言在共享的BPE字典(100k subword单元)中有80%tokens是相同的。Table 4展示了尼泊尔语语言模型和在尼泊尔语上训练的跨语言模型在perplexity上对比。这个跨语言模型还用不同的印地语和英文的组合数据进行了数据扩充。
4.5 无监督跨语言词嵌入
Conneau et al. (2018a) 介绍过如何通过对抗训练(MUSE)对齐单语种词嵌入空间,来实施无监督的单词翻译。Lample et al. (2018a)则采用2个语种的共享字典,再将单语种语料进行拼接后输入到fastText,也能够提供高质量的跨语言词嵌入(Concat),同时共享一份字母表。本文的词嵌入是通过提出的XLM模型获得,从余弦相似度、L2距离和跨语言词语相似度几个维度评估嵌入质量,在SemEval’17 cross-lingual word similarity task进行评估测试。
5. 实验和结果
实验结果都是一些数据表格,建议大家去原文XLM里面查看。
6. 总结
本文首次验证了跨语言模型(XLM)的预训练所带来的巨大收益。
- CLM和MLM,并证实了二者都能够提供用于预训练的有效跨语言特征。同时本文也证明了跨语种语言模型能够用以提升low-resource的Nepali语言模型,此外也提供了无监跨语言词嵌入。在无需使用任何的平行句子语料,跨语言模型在XNLI的跨语言分类任务上,平均准确率能够超出此前最优的有监督模型1.3个百分点。
- TLM目标的提出,该目标使用了平行语料提升了跨语言模型的预训练。TLM天然地扩展了BERT的MLM方法,使用平行语料的batches而不是连续的句子。在MLM上使用TLM能够进一步提升结果指标。该有监督方法以高出平均准确率4.9%的优势刷新了此前XNLI的记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号