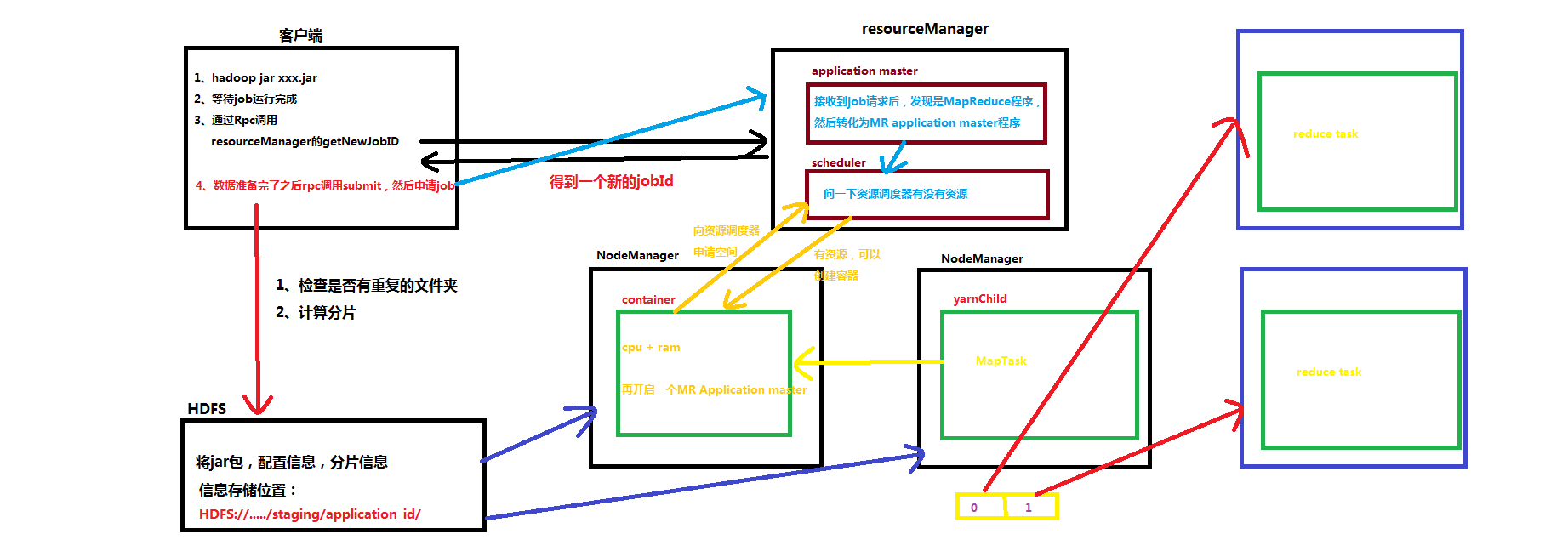
MapReduce on yarn的流程
![]()
1、准备阶段
1、客户端执行写好的jar包程序
2、客户端通过RPC调用YarnRunnable.getNewJobID()得到新的job id
3、然后检查我们的输出路径是不是存在的(存在的话就会报错)
4、然后再计算分片,看是否可以计算出分片信息(都没问题的话就往下继续)
5、将当前应用对应的信息(jar包,job的配置信息,分片信息)提交到hdfs://.../staging/application_id下面
6、客户端通过RPC的方式调用 YarnRunner.submit()方法把job提交到resourceManager下申请运行
2、运行阶段
1、job请求会转换为 MR AppMaster请求
2、MR AppMaster请求会提交到scheduler里面,由scheduler分配容器
3、给Appmaster申请容器(在哪个NameNode上,分配几个核心,几个cpu,多少内存)
4、在NodeManager中启动一个MR AppMaster(这个创建薄记对象,用于保存各task执行进度。状态)
5、然后获取分片信息、配置信息、split个数,每个split所在节点的reduce个数
6、正常执行MapReduce,获得分区数据
7、拉去Reduce Task程序,有几个分区就有几个Reduce Task程序
8、等待执行结束
3、结束阶段
1、将结果写入HDFS,一个reduce Task写入一个文件中,名称为part-r-00000,part-r-00001


 浙公网安备 33010602011771号
浙公网安备 33010602011771号