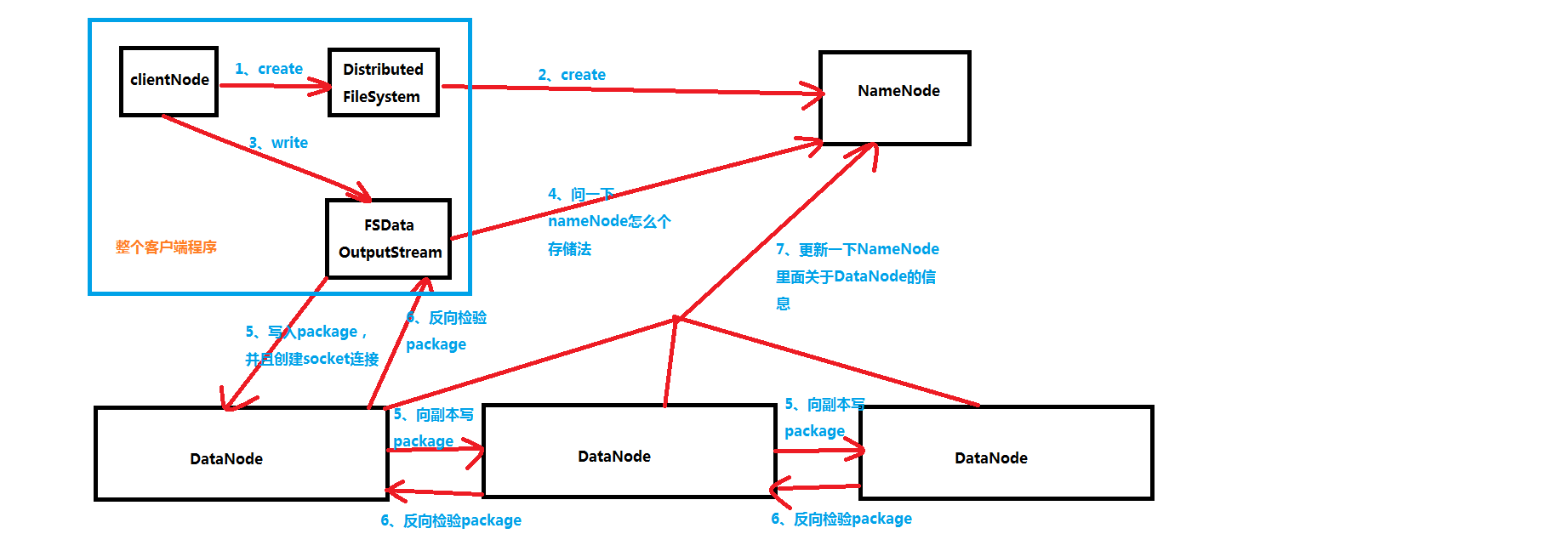
HDFS的写入流程
![]()
1、客户端程序会调用DistributedFileSystem类中的create方法,获取FSDataOutputStream对象
2、DistributedFileSystem调用NameNode中的create方法,告诉一下NameNode,我们要传递数据了,你准备一下,我之后要做一些校验(例如文件夹是不是存在啊,文件夹是不是重复,权限又是怎么样的)
3、clientNode调用FSDataOutputStream向输出流输出数据
4、FSDataOutputStream调用NameNode的 addBlock方法申请block1的blockId和block要存储在哪几个DataNode
5、ClientNode与datanode1建立一个socket连接,然后向它发送package,一般一个package是64KB,它是一个单位,而数据传输最基本的单位是chunk,它是512B,chunk是带数据校验的数据,因此会在本地生成一个一个chunk往package里面放
package放满了之后会加入到dataqueue数据队列之中,然后将package从dataqueue数据对列中取出,沿pipeline发送到DataNode1,DataNode1保存
然后将package发送到DataNode2,DataNode2保存,再向DataNode3发送package。DataNode3接收到package,然后保存
6、package到达DataNode3后做校验,将校验结果逆着pipeline回传给ClientNode。DataNode3将校验结果传给DataNode2,DataNode2做校验后将校验结果传给DataNode1,DataNode1做校验后将校验结果传给ClientNode。
ClientNode根据校验结果判断,如果”成功“,则将ackqueue确认队列中的package删除;如果”失败“,则将ackqueue确认队列中的package取出,重新放入到dataqueue数据队列末尾,等待重新沿pipeline发送。
7、当block1的所有package发送完毕。即DataNode1、DataNode2和DataNode3都存在block1的完整副本,则三个DataNode分别调用NameNode的 blockReceivedAndDeleted方法。
NameNode会更新内存中DataNode和block的关系。ClientNode关闭同DataNode建立的pipeline。文件仍存在未发送的block2,则继续执行4。直到文件所有数据传输完成
8、关闭FSDataOutputStream
9、ClientNode调用NameNode的 complete 方法,通知NameNode全部数据输出完成。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号