
java中的哈希表原理
java中的哈希表
我们都知道java中有hashmap可以快速的存取值,内部的结构其实是哈希表,那么java是如何实现哈希表的呢?
首先、接下来我们分析一下
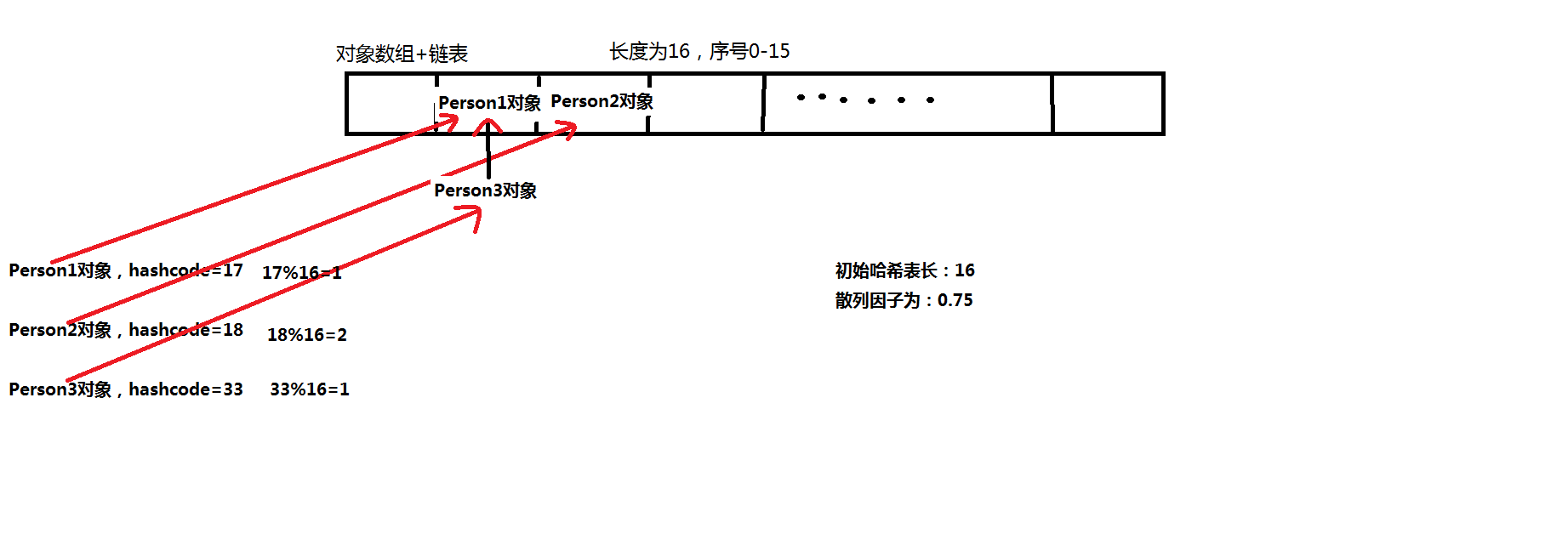
1、java中创建哈希表的时候会创建一个长度为16的数组,散列因子为0.75
2、我们每个对象都会有一个hashcode,这个hashcode可以继承Object的,也可以自己重写
3、根据类中的hashcode值,跟我们的数组长度进行取余数,就可以得到我们的类存在哪个位置。
4、如图所示,Person1存储在1位置,Person2存储在2位置
5、如果有重复的,就像图中的Person3所示,会以一个链表的方式链接到上一个存储的对象后面
那么问题来了,如果数据量很大呢,假设在数组的1位置,这个哈希桶中有大量数据,链表查找起来也特别的慢
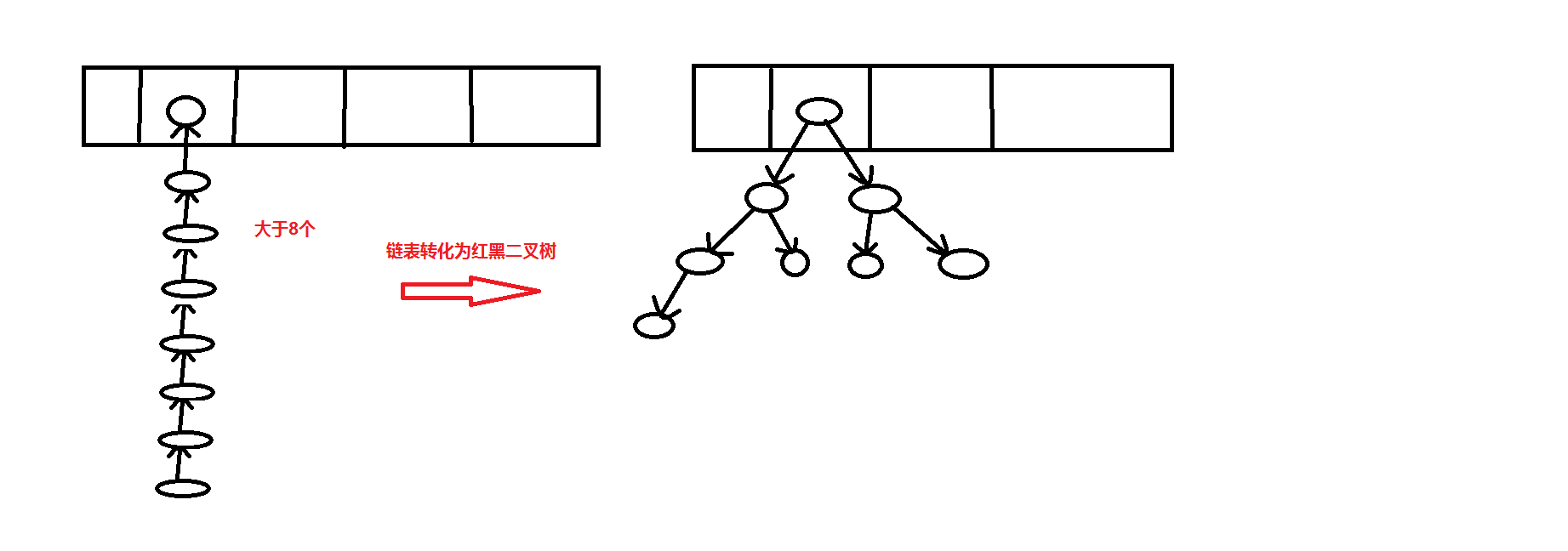
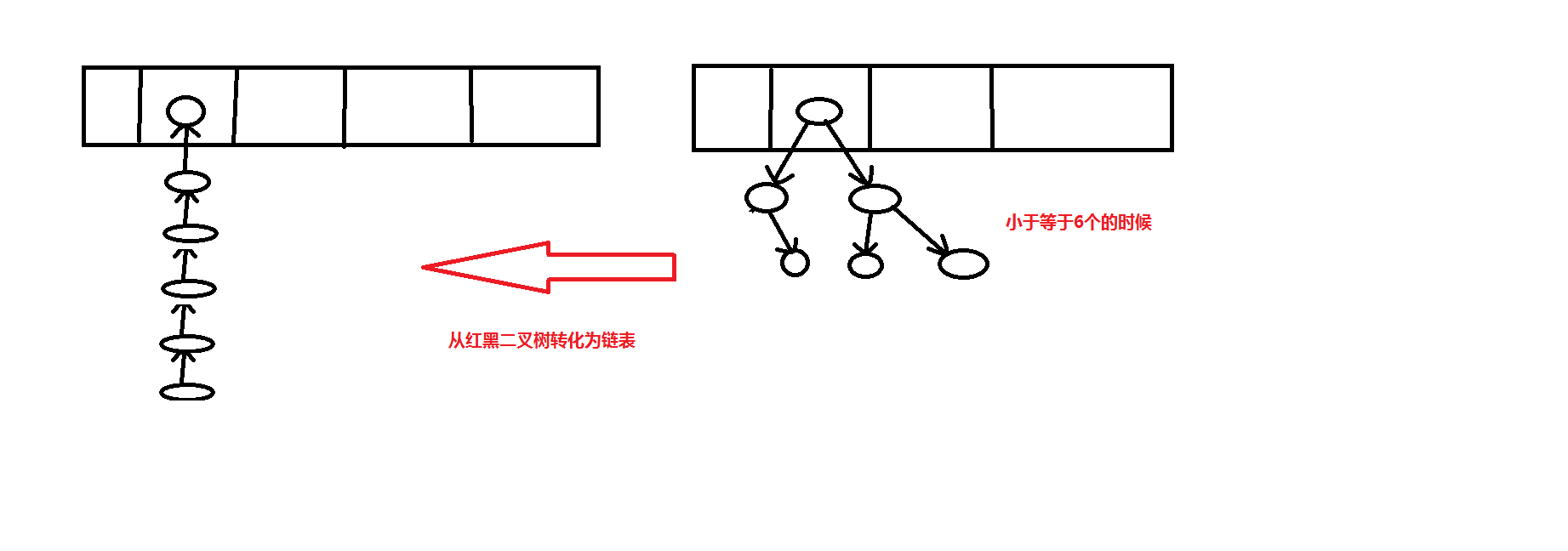
从JDK1.8之后:
1、当一个哈希桶中存储的对象数量大于8个的时候,这时候哈希桶会采用红黑二叉树的方式存储
2、当变为红黑二叉树时候,因为某种原因删除使的哈希桶中的元素元素就剩6个了,就会变为链表存储
那么问题又来了,如果我的数据量特别庞大,那么我们及时采用上面的方式,访问也很慢,这个时候怎么办呢
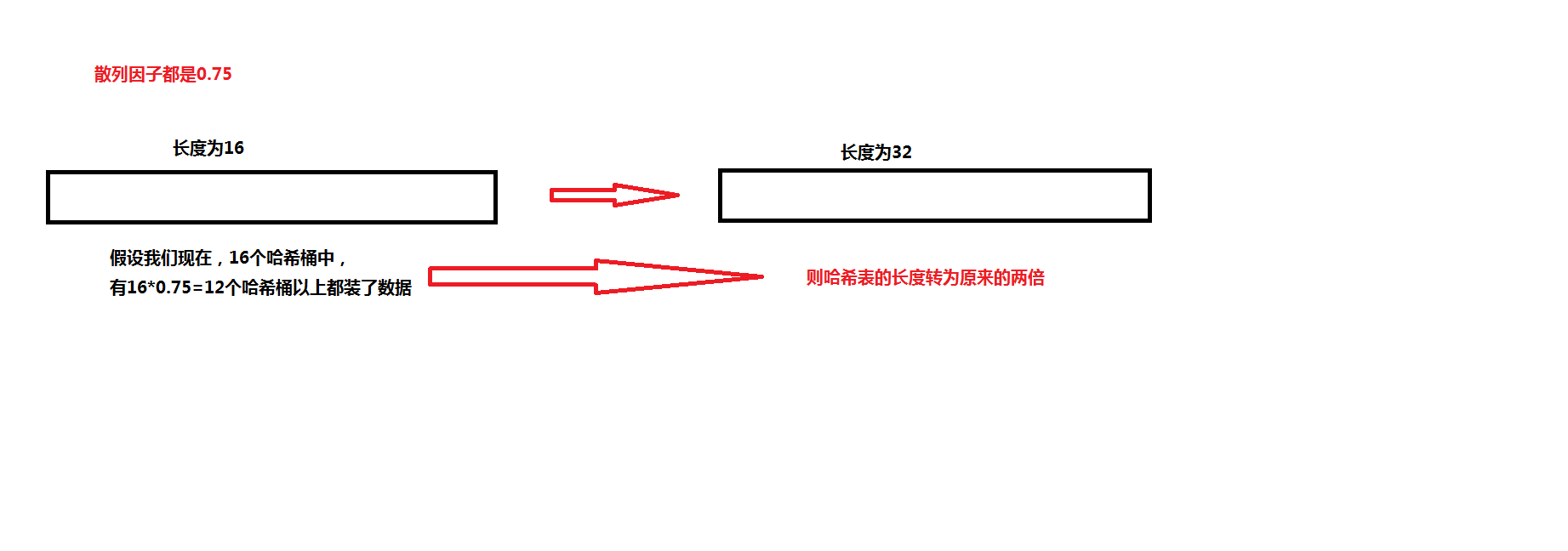
1、当哈希表这个数组中有X个元素都存储了 X >= 哈希表长度*散列因子,那么java中会自动扩展哈希表的长度,扩展为原来的两倍
2、后续的存储值,都安装新长度进行计算存储

 浙公网安备 33010602011771号
浙公网安备 33010602011771号