

SqlServer 在查询结果中如何过滤掉重复数据
问题背景
在一个多表查询的sql中正常情况下产生的数据都是唯一的,但因为数据库中存在错误(某张表中存在相同的外键ID)导致我这边查询出来的数据就会有重复的问题
下面结果集中UserID:15834存在多个

查询Sql如下:
SELECT * FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY T.USERID asc )AS Row ,T.USERID ,T.CreateTime FROM UserInfo T LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID ) TT WHERE TT.Row between 0 AND 20 ORDER BY UserID DESC
解决方法:
参考下面新的解决方案
在网络上了解到MSSql中通过关键字“PARTITION BY”可以将查询结果集进行分区处理,然后在查询结果集时就可以过滤掉重复的记录了(如果有指定分区字段则区ID相同)
通过更改后的Sql,在Over中添加PARTITION BY T.USERID以UserID进行分区,然后在查询结果集时通过DISTINCT ROW ,过滤掉重复的分区ID号
SELECT DISTINCT ROW ,* FROM ( SELECT ROW_NUMBER() OVER (PARTITION BY T.USERID ORDER BY T.USERID asc )AS Row ,T.USERID ,T.CreateTime FROM UserInfo T LEFT JOIN DiseaseInfo i ON i.UserID=T.UserID ) TT WHERE TT.Row between 0 AND 12 ORDER BY UserID DESC
查询时未过滤重复分区IDDISTINCT ROW ,下面的结果集跟上面的结果集不同(Row是进行过分区的所有有重复Row)

在查询结果集时过滤掉重复的分区ID号 DISTINCT ROW ,

新解决方案:
由于在Sqlserver中如果多表联合查询中除非所有的字段都完全相同否则在使用DISTINCT 用进行去重时还是会当成两个不同的数据集进行处理,因此DISTINCT会失效即
如下面的结果集,虽然 USERID和其他字段内容相同但HID是不相同的所以无法使用DISTINCT进行去重
出现这种问题是因为数据库设计的错误(正常情况下关联表 HospitalInfo中只可能存在一条ClinicInfo表对应的记录)
Sql语句:
SELECT * FROM ( SELECT ROW_NUMBER() OVER ( order by T.USERID asc )AS Row ,T.USERID ,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel ,T.CreateTime ,h.HName ,h.HID fromUserInfo T LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1 LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1 AND t.UserID>=17867 AND T.UserID<=17875 --(T.Patient_Tel1 like '%13800000000%') ) TT WHERE TT.Row between 0and20

可以看到上面的结果集中Row是有重复的,其他Row为2的是跟第一个是重复的
因为数据库涉及到其他业务和人员因此我只能提交该问题给相关的技术,但在该问题解决前不能影响到我这边也出现此问题
于是在原sql基础上进行处理,虽然HospitalInfo表中不重复记录但表的自增ID是不可能重复的那我只需要最新的一条记录即可
如果通过DISTINCT过进行去重则就无法成功,因为数据存在差别,可以看到第一条和最后一条数据还是重复的
SELECT DISTINCT row,* FROM ( SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row ,T.USERID ,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel ,T.CreateTime ,h.HName ,h.HID fromUserInfo T LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1 LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1 AND t.UserID>=17867 AND T.UserID<=17875 --(T.Patient_Tel1 like '%13800000000%') ) TT WHERE --row=1 AND TT.Row between 0 and 20

更改后的Sql
SELECT * FROM ( --partition by T.USERID 以UserID对结果集进行分区 SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row ,T.USERID ,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel ,T.CreateTime ,h.HName ,h.HID fromUserInfo T LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1 LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1 AND t.UserID>=17867 AND T.UserID<=17875 --(T.Patient_Tel1 like '%13800000000%') ) TT WHERE --因为之前已经以UserID对结果集进行分区,所以如果存在重复的字段则row的值会不相同 --row=1 AND TT.Row between 0 and 20
USERID=17867相同经过分区后会存在不同的Row值
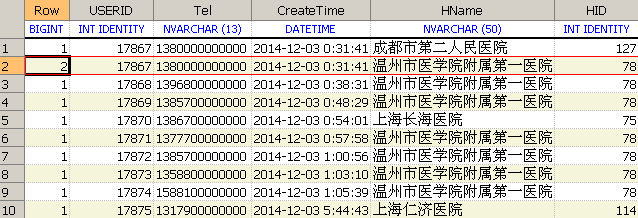
在对结果集再次过滤时添加条件 : row=1,已经将重复记录中旧的数据过滤掉了 (HID:78)

根据新的解决方案解决了重复的问题,但又出现的新的问题即Row分区后都是重复的,而我再进行分页的时候就无效了(因为此时结果集中的Row都是为1)
解决方案:在结果集再加一层查询并加上ID号然后再对结果集进行分页处理
-- 新增一层查询解决过滤掉重复数据后无法分页的问题 SELECT * FROM ( SELECT ROW_NUMBER() OVER (ORDER BY userid) AS RowNum,* FROM ( --partition by T.USERID 以UserID对结果集进行分区 SELECT ROW_NUMBER() OVER ( partition by T.USERID order by T.USERID asc )AS Row ,T.USERID ,LEFT(T.Patient_Tel1,5)+'00000000' AS Tel ,T.CreateTime ,h.HName ,h.HID fromUserInfo T LEFT JOIN ClinicInfo c ON c.UserID=T.UserID AND C.Disabled=1 LEFT JOIN HospitalInfo H ON H.HID=c.VisitHospital WHERE T.Disabled=1 AND t.UserID>=17867 AND T.UserID<=20875 --(T.Patient_Tel1 like '%13800000000%') ) TT )AS T WHERE --过滤重复数据 Row=1 --对结果进行分页 AND RowNum between 13 and 24

参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号