

研究动态扩容数据库解决方案
随着互联网的数据量越来越大,很多单表的数据量已经上亿了,甚至更多,这样单表的数据已经达到了查询的瓶颈,那么就需要将数据库进行拆分。
如何有效的进行数据库拆分呢,而且在互联网公司停机进行数据库处理不是很现实,因为影响了业务量。那么就需要更好的方法去进行解决。
首先咱们先准备一下数据库,然后将数据库建立好相同的表结构。通过服务双写继续将旧数据库继续进行CRUD操作,然后将新数据进行增删改操作。记录就数据库里边的一个标志,然后将旧数据库的标志之前的数据,通过写一个同步工具将旧的数据库表的数据同步到新数据库中。效果如下图:
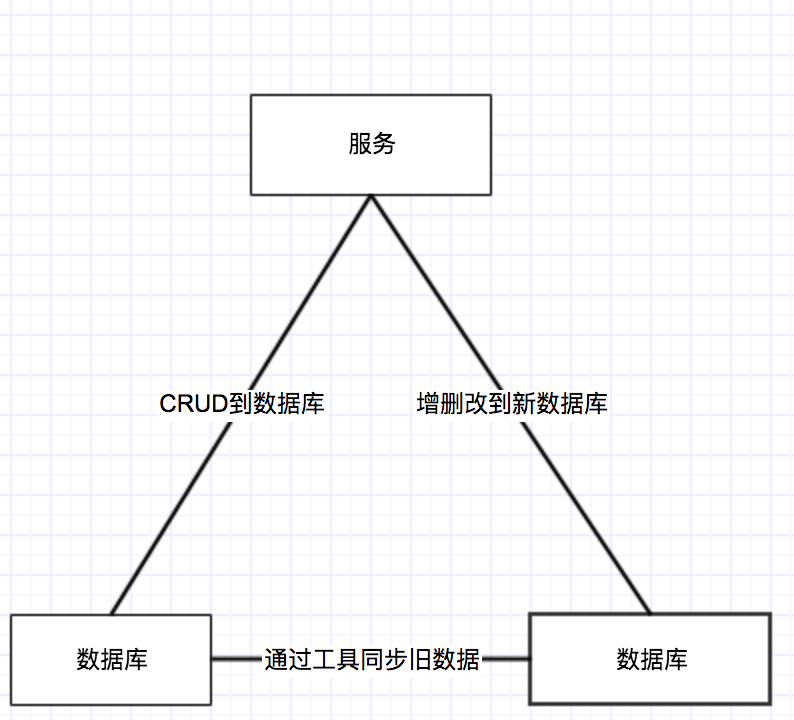
这样新产生的数据将写到新库,同时旧数据库的数据进行及时同步。
数据同步完成后需要进一步检查所有的数据,如果没有问题就申请两个虚拟IP或者域名,然后分别挂到两台机器上。
这样一个数据库就变成两台数据库了,然后两台数据库将表中的字段进行hash,hash结果为0的走到第一个数据库中,hash结果为1的走到数据库中。效果如下:
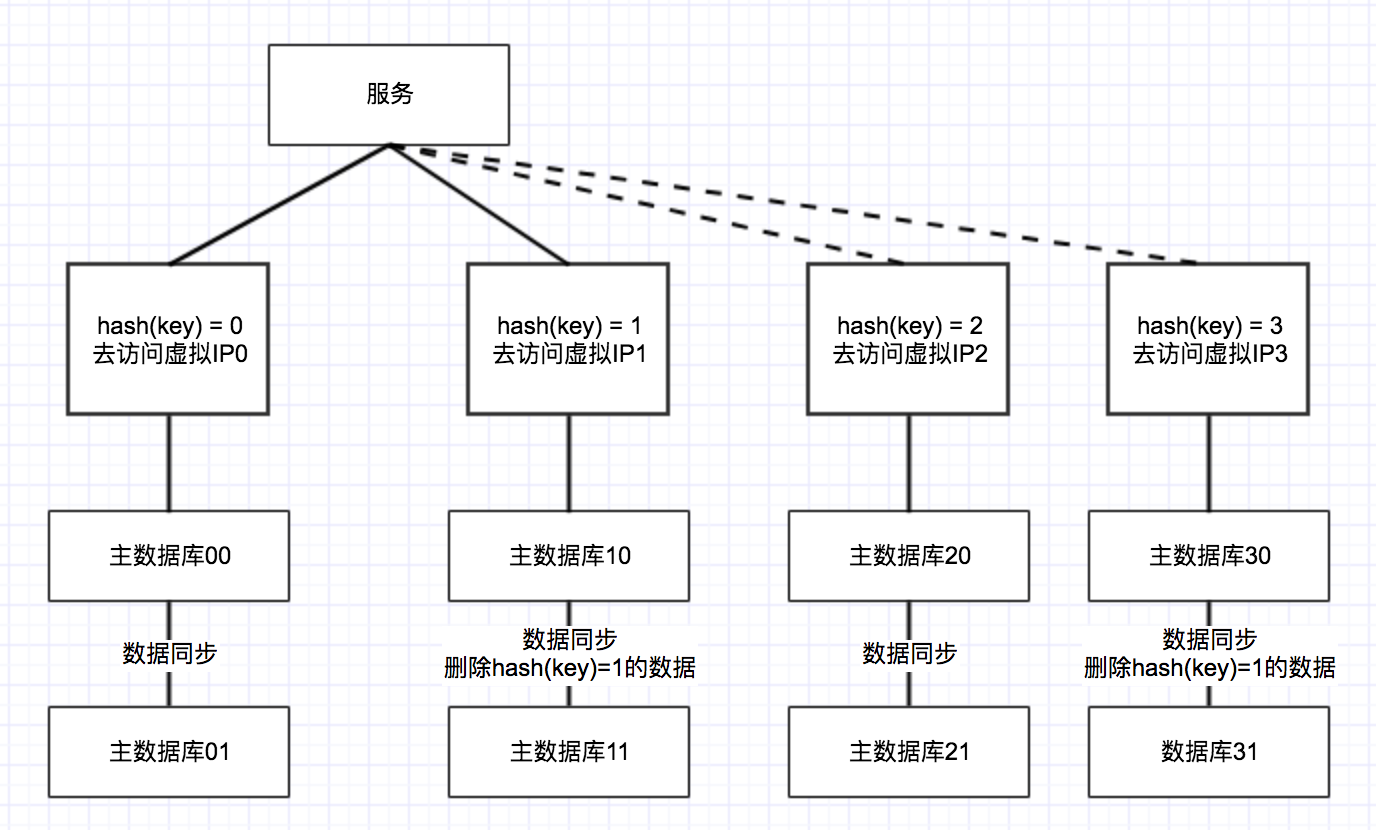
在切换的过程中,需要通过ZK配置直接将数据库进行这种方式的切换。此时需要观察一周左右的时间,同时两个数据库双写可以继续写着,防止新库出现数据问题是及时往旧数据库进行切换。
如果一周之后没有问题的话,将双写去掉,实现数据的分离。
这个时候数据库还没有完全分开,has(key)=0的数据库中还存在着hash(key) = 1的数据,这时需要把这样的数据删除掉。这样上亿的数据分为两个库,然后两个数据库每个各5000万条。
数据库分开之后,后续的统计等结果还要进行相应的修改,需要通过在内存中计算结果,然后把计算的结果放到汇总起来,得到统计和分析的结果。
这样就基本实现了不用停机服务而进行的数据库切换。
大家应该也注意到上图中,为了实现高可用,一个主库都带着一个主库,两个库之间通过任务进行的数据同步,假如访问虚拟IP的时候一个数据库出现了问题,那么直接接到另一个数据库上。
未来的话,需要再需要继续扩容的话,还需要以2*n的库进行扩容,这样has(key) = 0 和 hash(key) = 2数据保持一致, hash(key) = 1 和 hash(key) = 3数据一致。当数据同步完成之后0,2就可以按照上述的方法进行拆分,然后拆为两个虚拟IP,同时将hash(key)=2的数据从数据库 hash(key)= 0的数据库删除掉,1、3相同的原理,这样数据库就实现了同步。
同学们有没有更好的方法?可以和我一起讨论。当然咱们还有一些分库分表比较成熟的工具比如ShardingSphere和MyCAT,这些工具都是比较好的分库分表解决方案,当然在使用之前一定要做好功课,避免使用的时候采坑。
有问题欢迎来拍~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号