
七、强化学习第七篇--Tips of DQN
对于原始的DQN算法,可以通过如下方式进行改进。
1、Double DQN
Q-function 是取决于你的策略的。学习的过程中你的策略越来越强,你得到的 Q 值会越来越大。在同一个状态,你得到 reward 的期望会越来越大,所以一般而言,这个值都是上升的,但这是 Q-network 估测出来的值。 你接下来会得到累积奖励 (accumulated reward) 是多少。你会发现估测出来的值远比实际的值大,在每一个游戏都是这样,都大很多。所以今天要提出 Double DQN 的方法,它可以让估测的值跟实际的值是比较接近的 。

为了解决目标值总是太大的问题,可以采用Double DQN的算法策略。

Double DQN 相较于原来的 DQN 的更改是最少的,它几乎没有增加任何的运算量,连新的网络都不用,因为原来就有两个网络了。你唯一要做的事情只有,本来你在找 Q 值最大的 a 的时候,你是用 Q′ 来算,你是用目标网络来算,现在改成用另外一个会更新的 Q-network 来算。
2、Dueling DQN
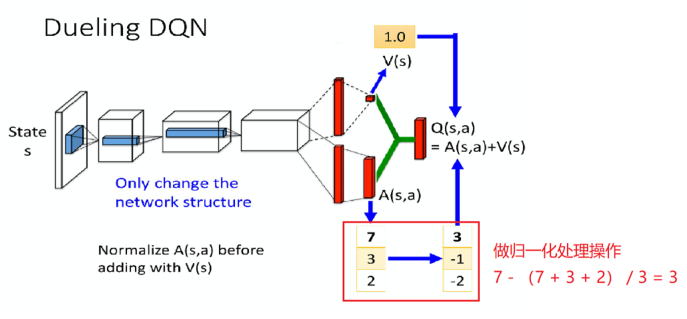
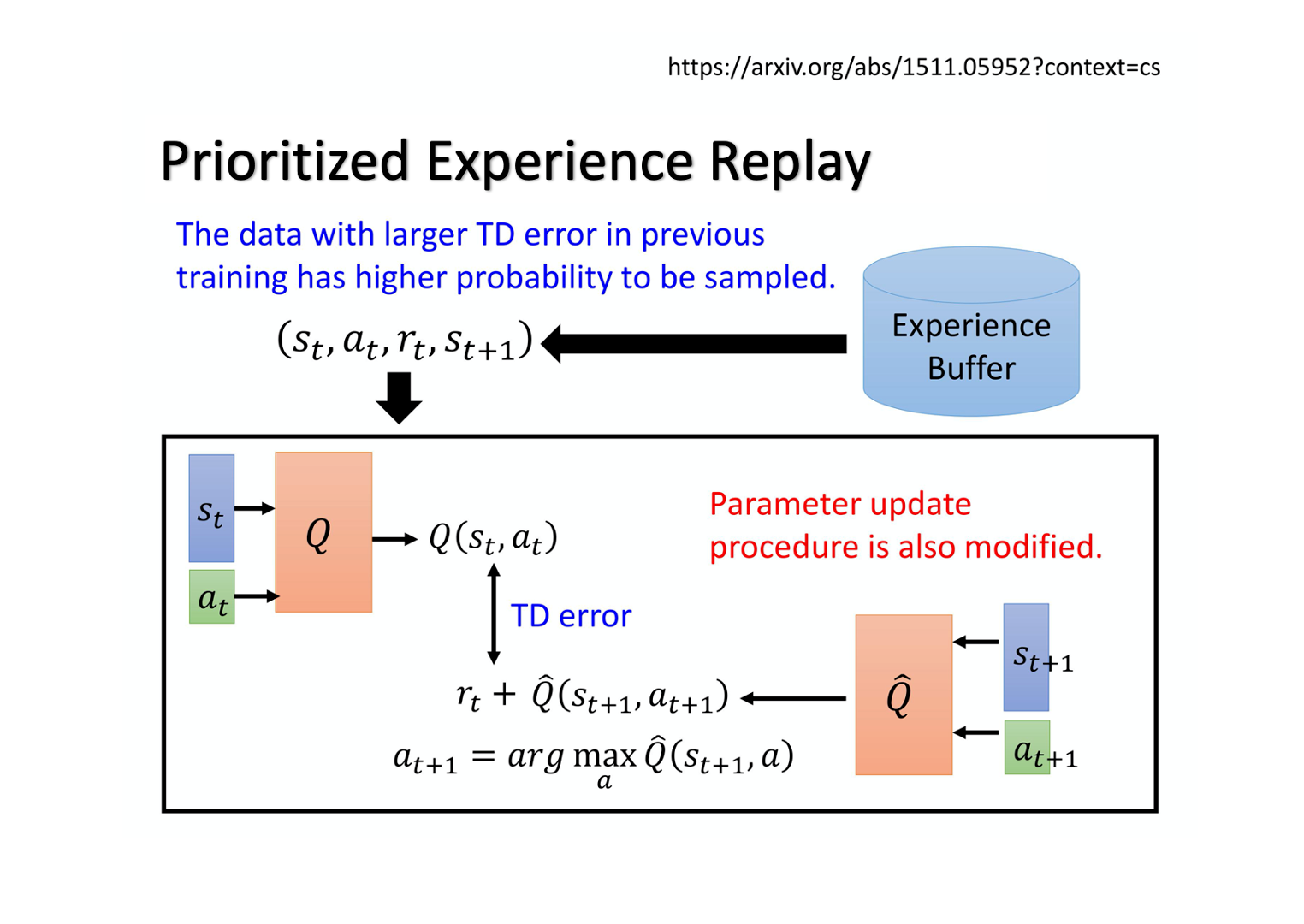
3、Prioritized Experience Reply
假设有一些数据,你之前有 sample 过。你发现这些数据的 TD error 特别大(TD error 就是网络的输出跟目标之间的差距),那这些数据代表说你在训练网络的时候,你是比较训练不好的。那既然比较训练不好,那你就应该给它比较大的概率被 sample 到,即给它 priority。这样在训练的时候才会多考虑那些训练不好的训练数据。实际上在做 prioritized experience replay 的时候,你不仅会更改 sampling 的 process,你还会因为更改了sampling 的过程,更改更新参数的方法。所以 prioritized experience replay 不仅改变了 sample 数据的分布,还改变了训练过程 。
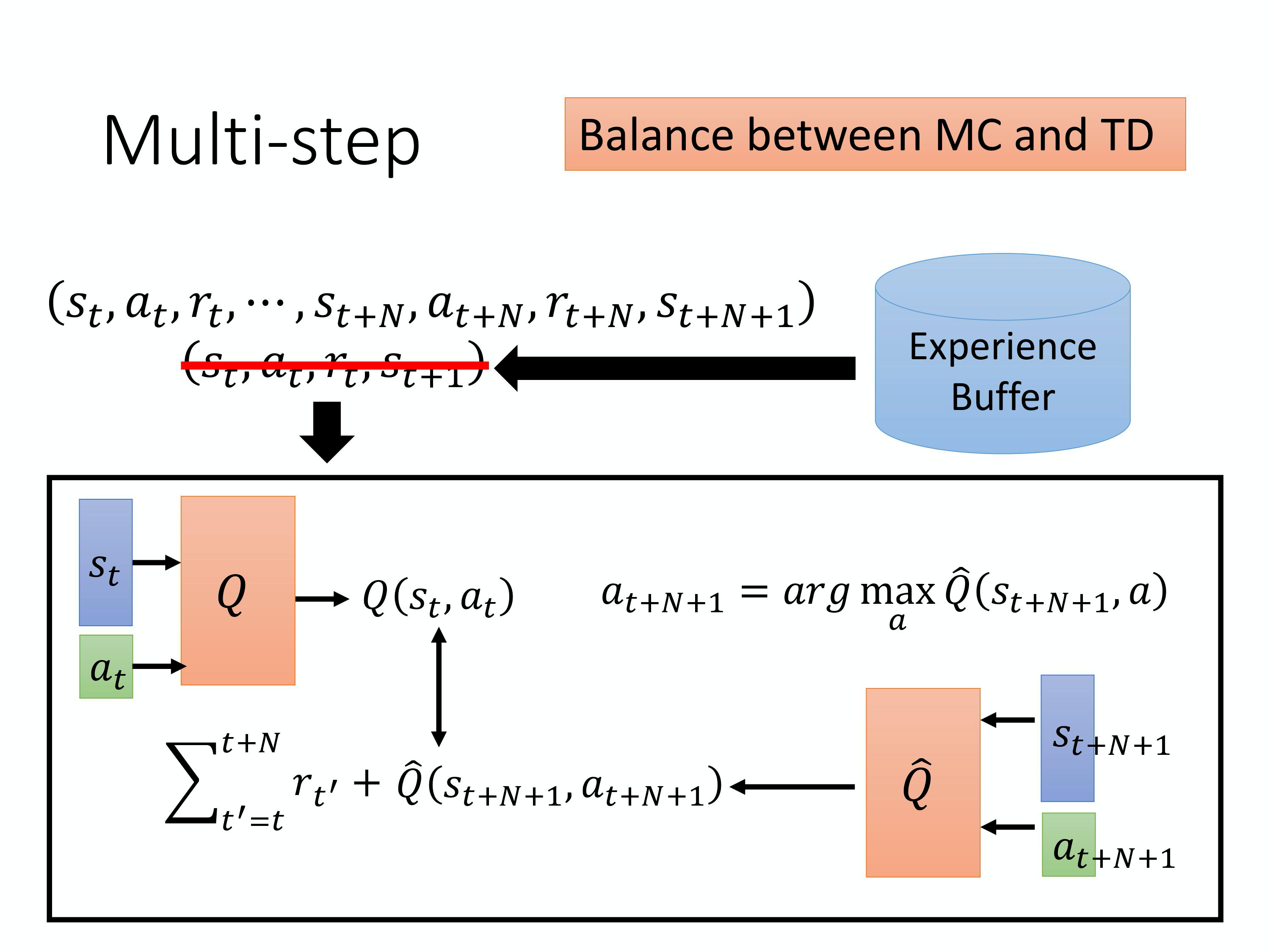
4、Balance between MC and TD
主要思想就是batch_size。
5、Noisy Net 、
其在每一个 episode 开始的时候,即要和环境互动的时候,将原来的 Q-function 的每一个参数上面加上一个 Gaussian noise。那你就把原来的 Q-function 变成 Q˜ ,即 Noisy Q-function。同样的我们把每一个 network 的权重等参数都加上一个 Gaussian noise,就得到一个新的 network Q˜。我们会使用这个新的 network 从与环境互动开始到互动结束 。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号