

MySQL多数据源笔记5-ShardingJDBC实战
Sharding-JDBC集分库分表、读写分离、分布式主键、柔性事务和数据治理与一身,提供一站式的解决分布式关系型数据库的解决方案。
从2.x版本开始,Sharding-JDBC正式将包名、Maven坐标、码云仓库、Github仓库和官方网站统一为io.shardingjdbc。
Sharding-JDBC是一款基于JDBC的数据库中间件产品,对Java的应用程序无任何改造成本,只需配置分片规则即可无缝集成进遗留系统,使系统在数据访问层直接具有分片化和分布式治理的能力。
Sharding-JDBC 2.x提供了全新的Orchestration模块,关注数据库和数据库访问层应用的治理。2.0.0在治理方面的主要更新是:
- 配置动态化。可以通过zookeeper或etcd作为注册中心动态修改数据源以及分片规则。
- 数据治理。提供熔断数据库访问程序对数据库的访问和禁用从库的访问的能力。
- 跟踪系统支持。可以通过sky-walking等基于Opentracing协议的APM系统中查看Sharding-JDBC的调用链,并提供sky-walking的自动探针。
- 提供Sharding-JDBC的spring-boot-starter。
通过2.x提供的数据治理能力,sharding-jdbc的架构图是:
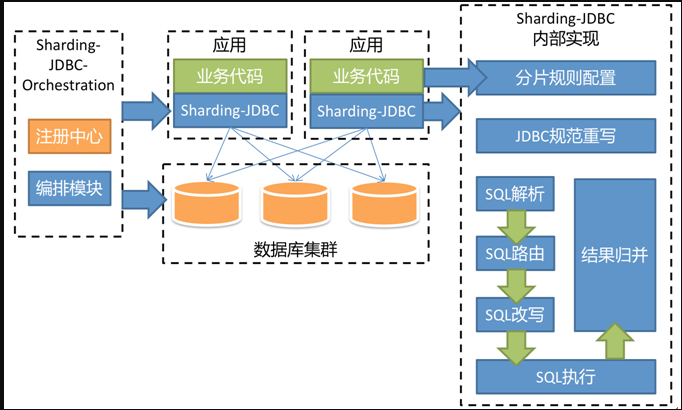
左边是部署架构图,右边是核心逻辑架构图。
分片规则配置
Sharding-JDBC的分片策略配置是自定义的,因此可以通过编程的方式最大限度的灵活调整。它并不仅支持=运算符分片,可支持BETWEEN和IN的运算符分片,支持将一条逻辑SQL最终散落至多个数据节点。同时支持多分片键,
例如:根据用户ID分库,订单ID分表这种分库分表结合的分片策略;或根据年分库,月份+用户区域ID分表这样的多片键分片。
通过编程的方式定制分片规则虽然灵活,但配置起来略显繁琐。因此Sharding-JDBC又提供了In line表达式编写分片策略的方式,用于配置集中化,以避免配置散落在配置文件和代码中的情况。此外,它还提供了定制化的Spring命名空间和YAML进一步简化配置。
Sharding-JDBC核心流程:
Sharding-JDBC是一个具有分库分表功能的数据库中间件。它通过JDBC扩展 => SQL解析 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程,
在SQL通过使用逻辑表,配合用户配置的分片规则,将对数据库访问的真实SQL完全屏蔽。
1JDBC扩展:
将JDBC接口中的Connection和Statement(PreparedStatement)的对应关系从一对一转换为一对多。因此一个逻辑SQL的执行,则有可能被拆分为多个执行结果集。
2.SQL解析:
分为词法解析和语法解析。先通过词法解析将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。
解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
Sharding-JDBC支持各种连接、聚合、排序、分组以及分页的解析,并且可以有限度的支持子查询。
3.SQL路由:
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由、Hint路由、广播路由、单播路由以及阻断路由等方式。
分片路由用于携带分片键的SQL路由,根据分片键的不同又可以划分为单片路由(分片操作符是等号)、多片路由(分片操作符是IN)和范围路由(分片操作符是BETWEEN)。
Hint路由用于通过程序的方式注入路由最终目的地的方式路由,可用于分片信息不包含在SQL中的场景。
广播路由用于SQL中不包含分片键的场景。根据SQL类型又可以划分为全库广播路由(SET AUTOCOMMIT=1)和全库表广播路由(DQL, DML, DDL)。
单播路由用于获取某一真实表信息的场景,如DESCRIBE table_name。
阻断路由用于屏蔽SQL对数据库的操作,如USE db_name,因为Sharding-JDBC仅有一个逻辑数据源,无需切换。
3.SQL改写:
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
正确性改写包括将逻辑表名称替换为真实表名称,将分页信息的启示取值和结束取值改写,增加为排序、分组和自增主键使用的补列,将AVG改写为SUM / COUNT等。
优化改写则是能将SQL改写的更加适于在分布式的数据库中执行,如将仅有分组的SQL增加排序字段,以便于将分组归并从内存归并转化为流式归并。
正确性改写包括将分表的逻辑表名称替换为真实表名称,修正分页信息和增加补列。举两个例子:
-
-
-
AVG计算。分布式场景,以avg1 + avg2 + avg3 / 3计算平均值并不正确,需要改写为 (sum1 + sum2 + sum3) / (count1 + count2 + count3)。这就需要将包含AVG的SQL改写为SUM和COUNT,并在结果归并时重新计算平均值。
-
-
-
-
-
分页。假设每10条数据为一页,取第2页数据。在分片环境下获取LIMIT 10, 10,归并之后再根据排序条件取出前10条数据是不正确的结果。正确的做法是将分条件改写为LIMIT 0, 20,取出所有前两页数据,再结合排序条件计算出正确的数据。因此越是获取靠后数据,分页的效率就会越低。有很多方法可避免使用LIMIT进行分页。比如构建记录行记录数和行偏移量的二级索引,或使用上次分页数据结尾ID作为下次查询条件的分页方式。
-
-
优化改写这里同样举两个例子:
-
-
-
单路由拒绝改写。这是将SQL改写挪到SQL路由之后的原因。当获得路由结果之后,单路由的情况因为不涉及到结果归并,因此分页、补列等改写都无需存在。尤其是分页,无需将数据从第1条开始取,节省了网络带宽。
-
-
-
-
-
流式归并改写。一会讲到归并时会说,这里先提一句,将仅包含GROUPBY的SQL改写为GROUPBY + ORDERBY。
-
-
4.SQL执行:
通过多线程执行器异步执行,但同一个物理数据源的不同分表的SQL会采用同一连接的同一线程,以保证其事务的完整性。
路由至真实数据源后,Sharding -JDBC将采用多线程并发执行SQL。它用3种执行引擎分别对应处理Statement,PreparedStatement和AddBatchPreparedStatement。
Sharding-JDBC线程池放在一个名为ShardingContext的对象中,它的生命周期同ShardingDataSource保持一致。
如果一个应用中创建了多个Sharding-JDBC的数据源,它们将持有不同的线程池。
5.结果归并:
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
流式归并用于简单查询、排序查询、分组查询以及排序和分组但排序项和分组项完全一致的场景,流式归并的结果集的遍历方式是通过每一次调用next方法取出,无需占用额外的内存。
内存归并仅用于排序项和分组项不一致的场景,需要将结果集中的所有数据加载至内存处理,如果结果集过多,会占用大量内存。
使用装饰者模式的追加归并用于分页,无论是简单查询、排序查询还是分组查询,包含分页的SQL都会经过分页的装饰器处理分页相关的结果归并。
Sharding-JDBC支持的结果归并从功能上分为遍历、排序、分组和分页4种类型,它们是组合而非互斥的关系。从结构划分,可分为流式归并、内存归并和装饰者归并。
流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
流式归并是将数据游标与结果集的游标保持一致,顺序的从结果集中一条条的获取正确的数据。遍历和排序都是流式归并,分组比较复杂,分为流式分组和内存分组。
内存归并则是需要将结果集的所有数据都遍历并存储在内存中,再通过内存归并后,将内存中的数据伪装成结果集返回。
遍历类型最为简单,只需将多结果集组成链表,遍历完成当前结果集后,将链表位置后移,继续遍历下一个结果集即可。
排序类型稍微复杂,由于ORDER BY的原因,每个结果集自身数据是有序的,因此只需要将结果集当前游标指向的值排序即可。Sharding-JDBC在排序类型归并时,将每个结果集的当前排序数据实现了比较器,并将其放入优先级队列。
每次JDBC调用next时,将队列顶端的结果集出队并next,然后获取新的队列顶端的结果集供JDBC获取数据。
分组类型最为复杂,分组归并已经不属于OLTP范畴,而更面向OLAP,但由于遗留系统使用很多,因此Sharding-JDBC还是将其实现。分组归并分成流式分组归并和内存分组归并。流式分组归并节省内存,但必须要求排序和分组的数据保持一致。
如果GROUPBY和ORDER BY的内容不一致,则必须使用内存分组归并。由于数据不是按照分组需要的顺序取出,因此需要将结果集中的所有数据全部加载至内存。在SQL改写时提到的仅有GROUP BY的SQL,会优化增加ORDER BY语句,即使将内存分组归并优化为流式分组归并的提升。
无论是流式分组还是内存分组,对聚合的处理都是一致的。聚合分为比较、累加和平均值3种类型。比较聚合包括MAX和MIN,只返回最大(小)结果。累加聚合包括SUM和COUNT,需要将结果累加后返回。平均值聚合则是通过SQL改写的SUM和COUNT计算,相关内容已在SQL改写涵盖,不再赘述。
最后再聊一下装饰者归并,他是对所有的结果集归并进行统一的功能增强,目前装饰者归并只有分页一种类型。
上述的所有归并类型,都可能分页或不分页,因此可以通过装饰者模式来增加分页的能力。分页归并会将改写的LIMIT中,不需要获取的数据过滤掉。
Sharding-JDBC的分页很容易产生误解,很多人认为分页会占用大量内存,因为Sharding-JDBC会因为分布式正确性的考量,将LIMIT 100000, 10改写为LIMIT 0, 100010,产生Sharding-JDBC会将100010数据都加载到内存的错觉。
通过上面分析可知,会全部加载到内存的只有内存分组归并这一种情况。其他情况都是通过流式获取结果集数据的方式,因此Sharding-JDBC会通过结果集的next方法将无需取出的数据全部跳过,并不会将其存入内存。
分布式主键
传统数据库软件开发中,主键自动生成技术是基本需求。而各大数据库对于该需求也提供了相应的支持,比如MySQL的自增键。
对于MySQL而言,分库分表之后,不同表生成全局唯一的Id是非常棘手的问题。因为同一个逻辑表内的不同实际表之间的自增键是无法互相感知的,
这样会造成重复Id的生成。我们当然可以通过约束表生成键的规则来达到数据的不重复,但是这需要引入额外的运维力量来解决重复性问题,并使框架缺乏扩展性。
目前有许多第三方解决方案可以完美解决这个问题,比如UUID等依靠特定算法自生成不重复键,或者通过引入Id生成服务等。
但也正因为这种多样性导致了Sharding-JDBC如果强依赖于任何一种方案就会限制其自身的发展。
基于以上的原因,最终采用了以JDBC接口来实现对于生成Id的访问,而将底层具体的Id生成实现分离出来。
使用方法分为设置自动生成键和获取生成键两部分:
设置自动生成键:
配置自增列,代码如下:
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(); tableRuleConfig.setLogicTable("t_order"); tableRuleConfig.setKeyGeneratorColumnName("order_id");
设置Id生成器的实现类,该类必须实现io.shardingjdbc.core.keygen.KeyGenerator接口。
配置全局生成器(com.xx.xx.KeyGenerator),代码如下:
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.setDefaultKeyGeneratorClass("com.xx.xx.KeyGenerator");
有时候我们希望部分表的Id生成器与全局Id生成器不同,比如t_order_item表希望使用com.xx.xx.OtherKeyGenerator来生成Id:
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(); tableRuleConfig.setLogicTable("t_order"); tableRuleConfig.setKeyGeneratorColumnName("order_id"); tableRuleConfig.setKeyGeneratorClass("com.xx.xx.OtherKeyGenerator");
这样t_order就使用com.xx.xx.KeyGenerator生成Id,而t_order_item使用com.xx.xx.OtherKeyGenerator生成Id。
获取自动生成键:
通过JDBC提供的API来获取。对于Statement来说调用```statement.execute("INSERT ...", Statement.RETURN_GENERATED_KEYS)```
来通知需要返回的生成的键值。对于PreparedStatement则是```connection.prepareStatement("INSERT ...", Statement.RETURN_GENERATED_KEYS)```
调用```statement.getGeneratedKeys()```来获取键值的ResultSet。
默认的分布式主键生成器:
类名称:io.shardingjdbc.core.keygen.DefaultKeyGenerator
该生成器采用snowflake算法实现,生成的数据为64bit的long型数据。
在数据库中应该用大于等于64bit的数字类型的字段来保存该值,比如在MySQL中应该使用BIGINT。
其二进制表示形式包含四部分,从高位到低位分表为:1bit符号位(为0),41bit时间位,10bit工作进程位,12bit序列位。
具体可以去看官方文档
分布式主键最独立的部分是生成策略,Sharding-JDBC提供灵活的配置分布式主键生成策略方式。在分片规则配置模块可配置每个表的主键生成策略,默认使用snowflake。
通过策略生成的分布式主键可以无缝的融入JDBC协议,它实现了Statement的getGeneratedKeys方法,将其返回改写后的Result和ResultMetaData,将Sharding-JDBC生成的分布式主键伪装为数据库生成的自增主键返回。
SQL解析时,需要根据分布式主键配置策略判断是否在逻辑SQL中已包含主键列,如果未包含则需要将INSERTItems和INSERT Values的最后位置写入解析上下文。
SQL改写时,将根据解析上下文中的位置改写SQL,增加未包含的主键列名称和值。如果是Statement则在INSERT Values后追加生成后的分布式主键;如果是PreparedStatement则在INSERT Values后追加?,并在传入的参数后追加生成后的分布式主键。
ShardingJDBC实战
首先去github上面下载官方提供的练习,github地址为:https://github.com/shardingjdbc 下载sharding-jdbc-example练习中的sharding-jdbc-spring-namespace-example/sharding-jdbc-spring-namespace-mybatis-example,sharding-jdbc-doc是官方文档。
自己搭建一个SSM工程。以下只展示关键的配置和代码。
jdbc.properties配置如下:
jdbc_url_1=jdbc:mysql://localhost:3306/db_1?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull jdbc_url_2=jdbc:mysql://localhost:3307/db_2?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull jdbc_url_3=jdbc:mysql://localhost:3308/db_3?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull jdbc_username=root jdbc_password=root
spring-cfg.xml的配置,配置说明已经在配置文件注释说明好了。如下代码:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:sharding="http://shardingjdbc.io/schema/shardingjdbc/sharding" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://shardingjdbc.io/schema/shardingjdbc/sharding http://shardingjdbc.io/schema/shardingjdbc/sharding/sharding.xsd"> <!--扫描注解生成bean--> <context:annotation-config/> <!--包扫描--> <context:component-scan base-package="com.coder520"/> <context:property-placeholder location="classpath:jdbc.properties"/> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="shardingDataSource"/> <property name="mapperLocations" value="classpath:com/coder520/**/**.xml"/> </bean> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.coder520.*.dao"/> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> </bean> <!--声明事务管理 采用注解方式--> <tx:annotation-driven transaction-manager="transactionManager"/> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="shardingDataSource"/> </bean> <!--开启切面代理--> <aop:aspectj-autoproxy/> <!--主数据库设置--> <bean id="ds_0" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close" init-method="init"> <property name="url" value="${jdbc_url_1}"/> <property name="username" value="${jdbc_username}"/> <property name="password" value="${jdbc_password}"/> </bean> <!--从数据库设置--> <bean id="ds_1" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close" init-method="init"> <property name="url" value="${jdbc_url_2}"/> <property name="username" value="${jdbc_username}"/> <property name="password" value="${jdbc_password}"/> </bean> <!--从数据库设置--> <bean id="ds_2" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close" init-method="init"> <property name="url" value="${jdbc_url_3}"/> <property name="username" value="${jdbc_username}"/> <property name="password" value="${jdbc_password}"/> </bean> <!--分库策略,sharding-column这里根据user_id(这列属性不能是String,只能是整型)分库,precise-algorithm-class是分库算法,--> <sharding:standard-strategy id="databaseShardingStrategy" sharding-column="user_id" precise-algorithm-class="com.coder520.sharding.PreciseModuloDatabaseShardingAlgorithm"/> <!--分表策略,sharding-column这里根据order_id(这列属性不能是String,只能是整型)分表,precise-algorithm-class是分表算法--> <sharding:standard-strategy id="tableShardingStrategy" sharding-column="order_id" precise-algorithm-class="com.coder520.sharding.PreciseModuloTableShardingAlgorithm"/> <!--自己写shardingDataSource嵌入Spring里面--> <sharding:data-source id="shardingDataSource"> <!--告诉shardingjdbc你所有库的名字,这里为什么要从0开始命名呢?因为shardingjdbc的分库分表策略是求余来分配的,比如user_id求余3有0,1,2,所以只能这样命名--> <sharding:sharding-rule data-source-names="ds_0,ds_1,ds_2"> <sharding:table-rules> <!--ds_${0..2}.t_order_${0..2},这里用到了In line表达式${0..2},这里是用了笛卡尔乘积运算,比如ds_0.t_order_0 ds_0.t_order_1 ds_0.t_order_2--> <!--logic-table是逻辑表 actual-data-nodes是实际的数据源节点--> <!--generate-key-column生成主键列,这是一个全局序列号,是唯一的,这是shardingjdbc自动会帮我们生成的。避免我们自己自增造成id重复--> <sharding:table-rule logic-table="t_order" actual-data-nodes="ds_${0..2}.t_order_${0..2}" database-strategy-ref="databaseShardingStrategy" table-strategy-ref="tableShardingStrategy" generate-key-column="order_id"/> <sharding:table-rule logic-table="t_order_item" actual-data-nodes="ds_${0..2}.t_order_item_${0..2}" database-strategy-ref="databaseShardingStrategy" table-strategy-ref="tableShardingStrategy" generate-key-column="order_item_id"/> </sharding:table-rules> </sharding:sharding-rule> </sharding:data-source> </beans>
接着在工程中自己建立一个包,把github上的两个分库分表的算法类复制进来,因为spring-cfg.xml中根据这两个类来分库分表的,我这里的包是com.coder520.sharding,
分库算法类,如下:
package com.coder520.sharding; import io.shardingjdbc.core.api.algorithm.sharding.PreciseShardingValue; import io.shardingjdbc.core.api.algorithm.sharding.standard.PreciseShardingAlgorithm; import java.util.Collection; public final class PreciseModuloDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {
//Collection<String> availableTargetNames是我们在配置文件配置的数据源 PreciseShardingValue<Long> shardingValue是传进来配置文件逻辑表的逻辑表名和传进来user_id列名和值
@Override
public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Integer> shardingValue) { for (String each : availableTargetNames) {
//这里求余3是因为我这里在spring-cfg.xml中配置的三个数据库,这里的意思是将数据分到哪一个库中,比如user_id为51,则分配到第一个数据库中,其他数据库中没用信息
if (each.endsWith(shardingValue.getValue() % 3 + "")) {
return each;
}
}
thrownew UnsupportedOperationException();
}
}
分表算法类代码如下:
package com.coder520.sharding; import io.shardingjdbc.core.api.algorithm.sharding.PreciseShardingValue; import io.shardingjdbc.core.api.algorithm.sharding.standard.PreciseShardingAlgorithm; import java.util.Collection; public final class PreciseModuloTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
//Collection<String> availableTargetNames是我们在配置文件配置的数据源 PreciseShardingValue<Long> shardingValue是传进来配置文件逻辑表的逻辑表名和传进来user_id列名和值
@Override
public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Long> shardingValue) { for (String each : availableTargetNames) {
//这里求余3是因为我这里有三个库,分别是我们在spring-cfg.xml配置的 if (each.endsWith(shardingValue.getValue() % 3 + "")) { return each; } } throw new UnsupportedOperationException(); } }
springmvc.xml和web.xml省略。自己配置。
接着使用github上面的下载下来的小demo来练习
controller代码如下:
package com.coder520.order.controller; import com.coder520.order.service.DemoService; import org.springframework.web.bind.annotation.RequestMapping; import javax.annotation.Resource; /** * Created by cong on 2018/3/19. */ public class OrderController { @Resource private DemoService demoService; @RequestMapping("/test") public void test(){ demoService.demo(); } }
service代码如下:
package com.coder520.order.service; import com.coder520.order.dao.OrderItemRepository; import com.coder520.order.dao.OrderRepository; import com.coder520.order.entity.Order; import com.coder520.order.entity.OrderItem; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.util.ArrayList; import java.util.List; @Service public class DemoService { @Resource private OrderRepository orderRepository; @Resource private OrderItemRepository orderItemRepository; public void demo() { orderRepository.createIfNotExistsTable(); orderItemRepository.createIfNotExistsTable(); } }
entity和dao都是用github上的那个练习下载下来的的,如下:
Order类:
public final class Order { private long orderId; private int userId; private String status; public long getOrderId() { return orderId; } public void setOrderId(final long orderId) { this.orderId = orderId; } public int getUserId() { return userId; } public void setUserId(final int userId) { this.userId = userId; } public String getStatus() { return status; } public void setStatus(final String status) { this.status = status; } @Override public String toString() { return String.format("order_id: %s, user_id: %s, status: %s", orderId, userId, status); } }
OderItem类如下:
package com.coder520.order.entity; public final class OrderItem { private long orderItemId; private long orderId; private int userId; private String status; public long getOrderItemId() { return orderItemId; } public void setOrderItemId(final long orderItemId) { this.orderItemId = orderItemId; } public long getOrderId() { return orderId; } public void setOrderId(final long orderId) { this.orderId = orderId; } public int getUserId() { return userId; } public void setUserId(final int userId) { this.userId = userId; } public String getStatus() { return status; } public void setStatus(final String status) { this.status = status; } @Override public String toString() { return String.format("order_item_id:%s, order_id: %s, user_id: %s, status: %s", orderItemId, orderId, userId, status); } }
dao和Mapper.xml文件自己去找到那个下载好的DEMO哪里复制进来

注意数据库表不用建立了,因为orderRepository.createIfNotExistsTable();orderItemRepository.createIfNotExistsTable();这里判断表存不存在,不存在自己会建立好的。但是db_1,db_2,db_3,这三个数据库必须建立好。
如下图:
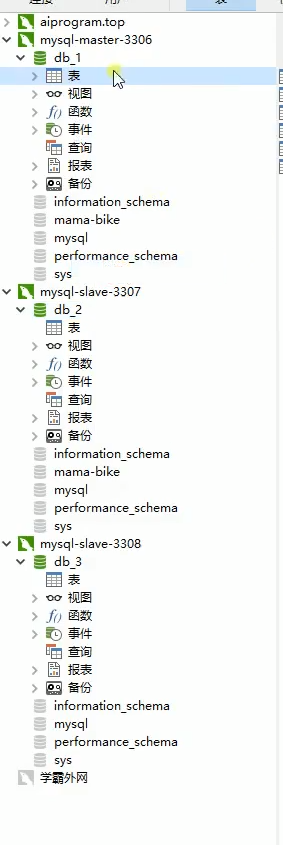
接着运行,可以看到每一个数据库表已经建立好了,如下图:

接着进行插入测试,修改service的代码,如下:
package com.coder520.order.service; import com.coder520.order.dao.OrderItemRepository; import com.coder520.order.dao.OrderRepository; import com.coder520.order.entity.Order; import com.coder520.order.entity.OrderItem; import org.springframework.stereotype.Service; import javax.annotation.Resource; import java.util.ArrayList; import java.util.List; @Service public class DemoService { @Resource private OrderRepository orderRepository; @Resource private OrderItemRepository orderItemRepository; public void demo() { List<Long> orderIds = new ArrayList<>(10); System.out.println("1.Insert--------------"); for (int i = 0; i < 10; i++) { Order order = new Order(); order.setUserId(51); order.setStatus("INSERT_TEST"); orderRepository.insert(order); long orderId = order.getOrderId(); orderIds.add(orderId); OrderItem item = new OrderItem(); item.setOrderId(orderId); item.setUserId(51); item.setStatus("INSERT_TEST"); orderItemRepository.insert(item); } System.out.println(orderItemRepository.selectAll()); System.out.println("2.Delete--------------"); for (Long each : orderIds) { orderRepository.delete(each); orderItemRepository.delete(each); } System.out.println(orderItemRepository.selectAll()); orderItemRepository.dropTable(); orderRepository.dropTable(); } }
接着在启动,可以看到数据全部被分配到第一个数据库中,因为分局分库算法user_id为51%3=0如下图:

那么是怎么个分库的呢?我们先把在代码中将user_id再设置成52。
那么下面进行打断点查看分库分表的过程。分别在那两个分库分表策略打断点,如下:
可以看到断点进来了,可以看到首先是找数据库,
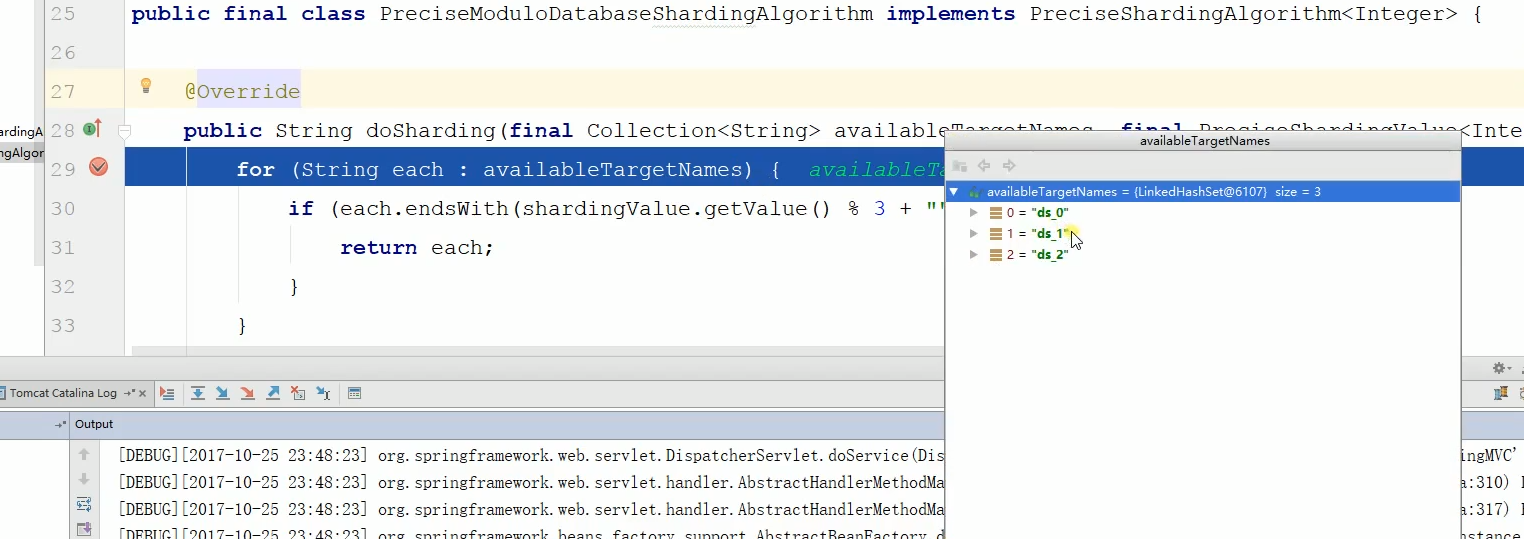
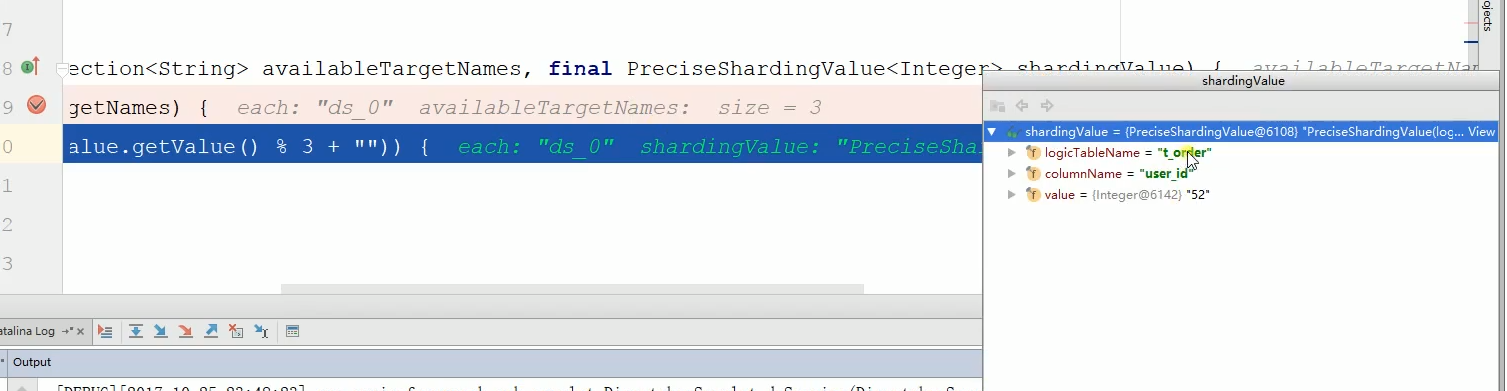
最终可以看到分配到最终的数据库,如下:
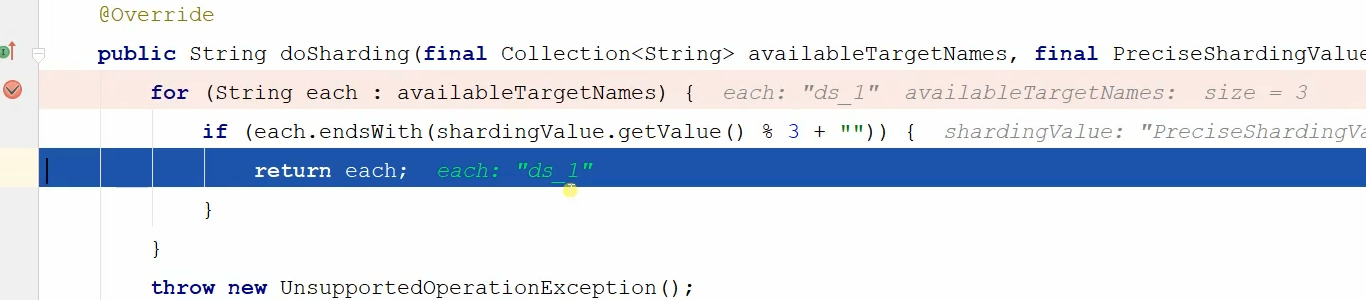
接着继续打断点,进到了分表策略这个类里面了
这是传进来的是逻辑表名和分表的依据order_id,分表依据order_id跟3求余,如下图:

最后选中求余后的表如下:
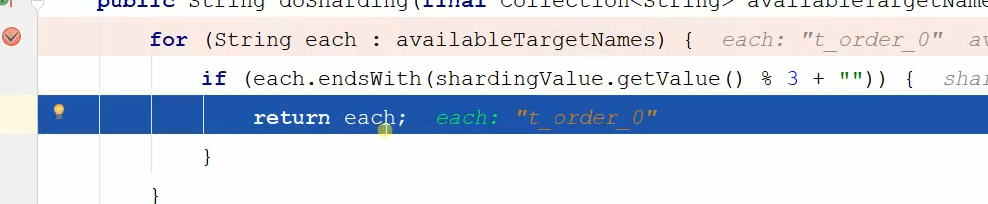
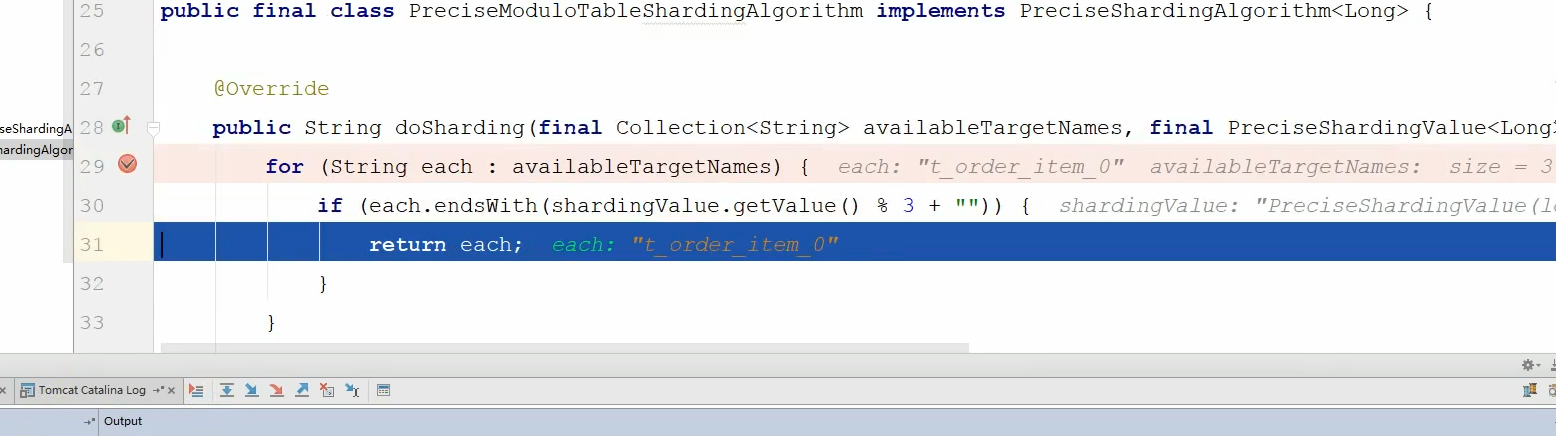
这里要注重说一点,each.endsWith是根据你数据源的尾号是否跟匹配的订单号求余后是否相等,相等了就说明被分配到这里了。比如ds_o和求余后0相等,
最后我们可以看到数据不再分配到第一个数据库了,而是本配到第二个数据库了,因为52%3=1.
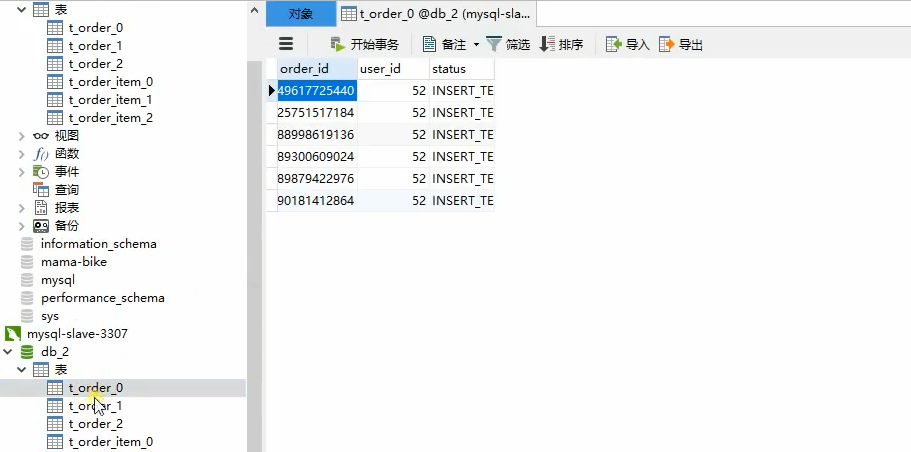

 浙公网安备 33010602011771号
浙公网安备 33010602011771号