
问题导读:
1.如何进行作业划分?
2.TaskScheduler如何提交Task?![]()
1、作业执行
上一章讲了RDD的转换,但是没讲作业的运行,它和Driver Program的关系是啥,和RDD的关系是啥?
官方给的例子里面,一执行collect方法就能出结果,那我们就从collect开始看吧,进入RDD,找到collect方法。
def collect(): Array[T] = { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) }
它进行了两个操作:
1、调用SparkContext的runJob方法,把自身的引用传入去,再传了一个匿名函数(把Iterator转换成Array数组)
2、把result结果合并成一个Array,注意results是一个Array[Array[T]]类型,所以第二句的那个写法才会那么奇怪。这个操作是很重的一个操作,如果结果很大的话,这个操作是会报OOM的,因为它是把结果保存在Driver程序的内存当中的result数组里面。
我们点进去runJob这个方法吧。
val callSite = getCallSite val cleanedFunc = clean(func) dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal, resultHandler, localProperties.get) rdd.doCheckpoint()
追踪下去,我们会发现经过多个不同的runJob同名函数调用之后,执行job作业靠的是dagScheduler,最后把结果通过resultHandler保存返回。
2、DAGScheduler如何划分作业
好的,我们继续看DAGScheduler的runJob方法,提交作业,然后等待结果,成功什么都不做,失败抛出错误,我们接着看submitJob方法。
val jobId = nextJobId.getAndIncrement() val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _] // 记录作业成功与失败的数据结构,一个作业的Task数量是和分片的数量一致的,Task成功之后调用resultHandler保存结果。 val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler) eventProcessActor ! JobSubmitted(jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties)
走到这里,感觉有点儿绕了,为什么到了这里,还不直接运行呢,还要给eventProcessActor发送一个JobSubmitted请求呢,new一个线程和这个区别有多大?
不管了,搜索一下eventProcessActor吧,结果发现它是一个DAGSchedulerEventProcessActor,它的定义也在DAGScheduler这个类里面。它的receive方法里面定义了12种事件的处理方法,这里我们只需要看JobSubmitted的就行,它也是调用了自身的handleJobSubmitted方法。但是这里很奇怪,没办法打断点调试,但是它的结果倒是能返回的,因此我们得用另外一种方式,打开test工程,找到scheduler目录下的DAGSchedulerSuite这个类,我们自己写一个test方法,首先我们要在import那里加上import org.apache.spark.SparkContext._ ,然后加上这一段测试代码。
test("run shuffle") { val rdd1 = sc.parallelize(1 to 100, 4) val rdd2 = rdd1.filter(_ % 2 == 0).map(_ + 1) val rdd3 = rdd2.map(_ - 1).filter(_ < 50).map(i => (i, i)) val rdd4 = rdd3.reduceByKey(_ + _) submit(rdd4, Array(0,1,2,3)) complete(taskSets(0), Seq( (Success, makeMapStatus("hostA", 1)), (Success, makeMapStatus("hostB", 1)))) complete(taskSets(1), Seq((Success, 42))) complete(taskSets(2), Seq( (Success, makeMapStatus("hostA", 2)), (Success, makeMapStatus("hostB", 2)))) complete(taskSets(3), Seq((Success, 68))) }
这个例子的重点还是shuffle那块,另外也包括了map的多个转换,大家可以按照这个例子去测试下。
我们接着看handleJobSubmitted吧。
var finalStage: Stage = null try { finalStage = newStage(finalRDD, partitions.size, None, jobId, Some(callSite)) } catch { // 错误处理,告诉监听器作业失败,返回.... } if (finalStage != null) { val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties) clearCacheLocs() if (allowLocal && finalStage.parents.size == 0 && partitions.length == 1) { // 很短、没有父stage的本地操作,比如 first() or take() 的操作本地执行. listenerBus.post(SparkListenerJobStart(job.jobId, Array[Int](), properties)) runLocally(job) } else { // collect等操作走的是这个过程,更新相关的关系映射,用监听器监听,然后提交作业 jobIdToActiveJob(jobId) = job activeJobs += job resultStageToJob(finalStage) = job listenerBus.post(SparkListenerJobStart(job.jobId, jobIdToStageIds(jobId).toArray, properties)) // 提交stage submitStage(finalStage) } } // 提交stage submitWaitingStages()
从上面这个方法来看,我们应该重点关注newStage方法、submitStage方法和submitWaitingStages方法。
我们先看newStage,它得到的结果叫做finalStage,挺奇怪的哈,为啥?先看吧
val id = nextStageId.getAndIncrement() val stage = new Stage(id, rdd, numTasks, shuffleDep, getParentStages(rdd, jobId), jobId, callSite) stageIdToStage(id) = stage updateJobIdStageIdMaps(jobId, stage) stageToInfos(stage) = StageInfo.fromStage(stage) stage
可以看出来Stage也没有太多的东西可言,它就是把rdd给传了进去,tasks的数量,shuffleDep是空,parentStage。
那它的parentStage是啥呢?
private def getParentStages(rdd: RDD[_], jobId: Int): List[Stage] = { val parents = new HashSet[Stage] val visited = new HashSet[RDD[_]] def visit(r: RDD[_]) { if (!visited(r)) { visited += r // 在visit函数里面,只有存在ShuffleDependency的,parent才通过getShuffleMapStage计算出来 for (dep <- r.dependencies) { dep match { case shufDep: ShuffleDependency[_,_] => parents += getShuffleMapStage(shufDep, jobId) case _ => visit(dep.rdd) } } } } visit(rdd) parents.toList }
它是通过不停的遍历它之前的rdd,如果碰到有依赖是ShuffleDependency类型的,就通过getShuffleMapStage方法计算出来它的Stage来。
那我们就开始看submitStage方法吧。
private def submitStage(stage: Stage) { //... val missing = getMissingParentStages(stage).sortBy(_.id) logDebug("missing: " + missing) if (missing == Nil) { // 没有父stage,执行这stage的tasks submitMissingTasks(stage, jobId.get) runningStages += stage } else { // 提交父stage的task,这里是个递归,真正的提交在上面的注释的地方 for (parent <- missing) { submitStage(parent) } // 暂时不能提交的stage,先添加到等待队列 waitingStages += stage } } }
这个提交stage的过程是一个递归的过程,它是先要把父stage先提交,然后把自己添加到等待队列中,直到没有父stage之后,就提交该stage中的任务。等待队列在最后的submitWaitingStages方法中提交。
这里我引用一下上一章当中我所画的那个图来表示这个过程哈。
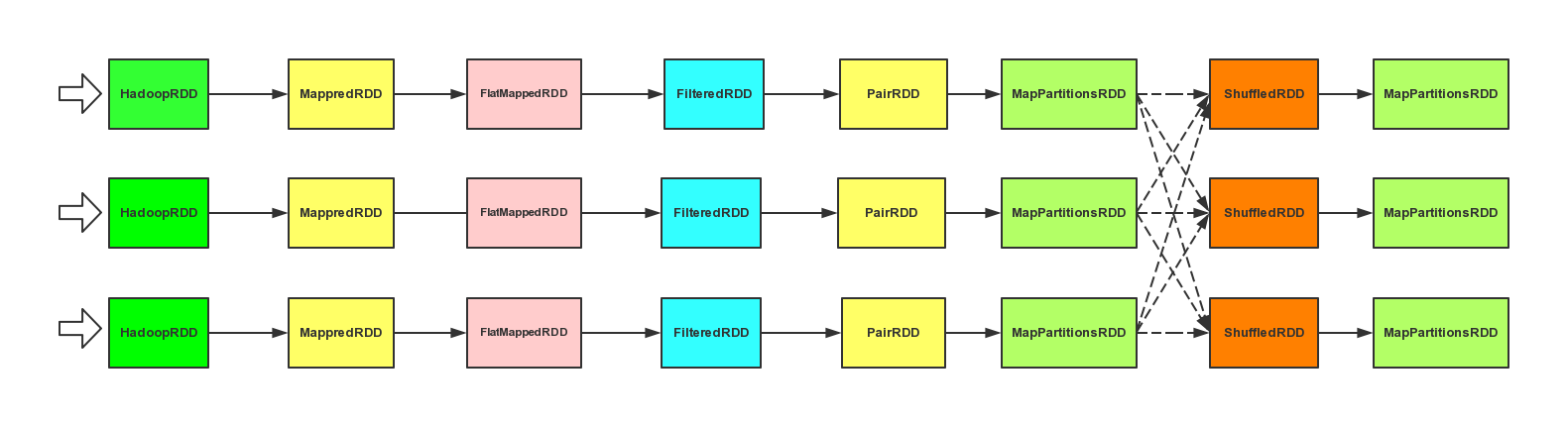
从getParentStages方法可以看出来,RDD当中存在ShuffleDependency的Stage才会有父Stage, 也就是图中的虚线的位置!
所以我们只需要记住凡是涉及到shuffle的作业都会至少有两个Stage,即shuffle前和shuffle后。
4、TaskScheduler提交Task
那我们接着看submitMissingTasks方法,下面是主体代码。
private def submitMissingTasks(stage: Stage, jobId: Int) { val myPending = pendingTasks.getOrElseUpdate(stage, new HashSet) myPending.clear() var tasks = ArrayBuffer[Task[_]]() if (stage.isShuffleMap) { // 这是shuffle stage的情况 for (p <- 0 until stage.numPartitions if stage.outputLocs(p) == Nil) { val locs = getPreferredLocs(stage.rdd, p) tasks += new ShuffleMapTask(stage.id, stage.rdd, stage.shuffleDep.get, p, locs) } } else { // 这是final stage的情况 val job = resultStageToJob(stage) for (id <- 0 until job.numPartitions if !job.finished(id)) { val partition = job.partitions(id) val locs = getPreferredLocs(stage.rdd, partition) tasks += new ResultTask(stage.id, stage.rdd, job.func, partition, locs, id) } } if (tasks.size > 0) { myPending ++= tasks taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.newAttemptId(), stage.jobId, properties)) stageToInfos(stage).submissionTime = Some(System.currentTimeMillis()) } else { runningStages -= stage } } Task也是有两类的,一种是ShuffleMapTask,一种是ResultTask,我们需要注意这两种Task的runTask方法。最后Task是通过taskScheduler.submitTasks来提交的。 我们找到TaskSchedulerImpl里面看这个方法。 override def submitTasks(taskSet: TaskSet) { val tasks = taskSet.tasksthis.synchronized { val manager = new TaskSetManager(this, taskSet, maxTaskFailures) activeTaskSets(taskSet.id) = manager schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) hasReceivedTask = true } backend.reviveOffers() }
Task也是有两类的,一种是ShuffleMapTask,一种是ResultTask,我们需要注意这两种Task的runTask方法。最后Task是通过taskScheduler.submitTasks来提交的。
我们找到TaskSchedulerImpl里面看这个方法。
override def submitTasks(taskSet: TaskSet) { val tasks = taskSet.tasksthis.synchronized { val manager = new TaskSetManager(this, taskSet, maxTaskFailures) activeTaskSets(taskSet.id) = manager schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) hasReceivedTask = true } backend.reviveOffers() }
调度器有两种模式,FIFO和FAIR,默认是FIFO, 可以通过spark.scheduler.mode来设置,schedulableBuilder也有相应的两种FIFOSchedulableBuilder和FairSchedulableBuilder。
那backend是啥?据说是为了给TaskSchedulerImpl提供插件式的调度服务的。
它是怎么实例化出来的,这里我们需要追溯回到SparkContext的createTaskScheduler方法,下面我直接把常用的3中类型的TaskScheduler给列出来了。
mode Scheduler Backend
cluster TaskSchedulerImpl SparkDeploySchedulerBackend
yarn-cluster YarnClusterScheduler CoarseGrainedSchedulerBackend
yarn-client YarnClientClusterScheduler YarnClientSchedulerBackend
好,我们回到之前的代码上,schedulableBuilder.addTaskSetManager比较简单,把作业集添加到调度器的队列当中。
我们接着看backend的reviveOffers,里面只有一句话driverActor ! ReviveOffers。真是头晕,搞那么多Actor,只是为了接收消息。。。
照旧吧,找到它的receive方法,找到ReviveOffers这个case,发现它调用了makeOffers方法,我们继续追杀!
def makeOffers() { launchTasks(scheduler.resourceOffers(executorHost.toArray.map {case (id, host) => new WorkerOffer(id, host, freeCores(id))})) }
从executorHost中随机抽出一些来给调度器,然后调度器返回TaskDescription,executorHost怎么来的,待会儿再说,我们接着看resourceOffers方法。
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized { SparkEnv.set(sc.env) // 遍历worker提供的资源,更新executor相关的映射 for (o <- offers) { executorIdToHost(o.executorId) = o.host if (!executorsByHost.contains(o.host)) { executorsByHost(o.host) = new HashSet[String]() executorAdded(o.executorId, o.host) } } // 从worker当中随机选出一些来,防止任务都堆在一个机器上 val shuffledOffers = Random.shuffle(offers) // worker的task列表 val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores)) val availableCpus = shuffledOffers.map(o => o.cores).toArray val sortedTaskSets = rootPool.getSortedTaskSetQueue // 随机遍历抽出来的worker,通过TaskSetManager的resourceOffer,把本地性最高的Task分给Worker var launchedTask = false for (taskSet <- sortedTaskSets; maxLocality <- TaskLocality.values) { do { launchedTask = false for (i <- 0 until shuffledOffers.size) { val execId = shuffledOffers(i).executorId val host = shuffledOffers(i).host if (availableCpus(i) >= CPUS_PER_TASK) { // 把本地性最高的Task分给Worker for (task <- taskSet.resourceOffer(execId, host, maxLocality)) { tasks(i) += task val tid = task.taskId taskIdToTaskSetId(tid) = taskSet.taskSet.id taskIdToExecutorId(tid) = execId activeExecutorIds += execId executorsByHost(host) += execId availableCpus(i) -= CPUS_PER_TASK assert (availableCpus(i) >= 0) launchedTask = true } } } } while (launchedTask) } if (tasks.size > 0) { hasLaunchedTask = true } return tasks }
resourceOffers主要做了3件事:
1、从Workers里面随机抽出一些来执行任务。
2、通过TaskSetManager找出和Worker在一起的Task,最后编译打包成TaskDescription返回。
3、将Worker-->Array[TaskDescription]的映射关系返回。
我们继续看TaskSetManager的resourceOffer,看看它是怎么找到和host再起的Task,并且包装成TaskDescription。
通过查看代码,我发现之前我解释的和它具体实现的差别比较大,它所谓的本地性是根据当前的等待时间来确定的任务本地性的级别。
它的本地性主要是包括四类:PROCESS_LOCAL, NODE_LOCAL, RACK_LOCAL, ANY。
private def getAllowedLocalityLevel(curTime: Long): TaskLocality.TaskLocality = { while (curTime - lastLaunchTime >= localityWaits(currentLocalityIndex) && currentLocalityIndex < myLocalityLevels.length - 1) { // 成立条件是当前时间-上次发布任务的时间 > 当前本地性级别的,条件成立就跳到下一个级别 lastLaunchTime += localityWaits(currentLocalityIndex) currentLocalityIndex += 1 } myLocalityLevels(currentLocalityIndex) }
等待时间是可以通过参数去设置的,具体的自己查下面的代码。
private def getLocalityWait(level: TaskLocality.TaskLocality): Long = { val defaultWait = conf.get("spark.locality.wait", "3000") level match { case TaskLocality.PROCESS_LOCAL => conf.get("spark.locality.wait.process", defaultWait).toLong case TaskLocality.NODE_LOCAL => conf.get("spark.locality.wait.node", defaultWait).toLong case TaskLocality.RACK_LOCAL => conf.get("spark.locality.wait.rack", defaultWait).toLong case TaskLocality.ANY => 0L } }
下面继续看TaskSetManager的resourceOffer的方法,通过findTask来从Task集合里面找到相应的Task。
findTask(execId, host, allowedLocality) match { case Some((index, taskLocality)) => { val task = tasks(index) val serializedTask = Task.serializeWithDependencies(task, sched.sc.addedFiles, sched.sc.addedJars, ser) val timeTaken = clock.getTime() - startTime addRunningTask(taskId) val taskName = "task %s:%d".format(taskSet.id, index) sched.dagScheduler.taskStarted(task, info) return Some(new TaskDescription(taskId, execId, taskName, index, serializedTask)) }
它的findTask方法如下:
private def findTask(execId: String, host: String, locality: TaskLocality.Value) : Option[(Int, TaskLocality.Value)] = { // 同一个Executor,通过execId来查找相应的等待的task for (index <- findTaskFromList(execId, getPendingTasksForExecutor(execId))) { return Some((index, TaskLocality.PROCESS_LOCAL)) } // 通过主机名找到相应的Task,不过比之前的多了一步判断 if (TaskLocality.isAllowed(locality, TaskLocality.NODE_LOCAL)) { for (index <- findTaskFromList(execId, getPendingTasksForHost(host))) { return Some((index, TaskLocality.NODE_LOCAL)) } } // 通过Rack的名称查找Task if (TaskLocality.isAllowed(locality, TaskLocality.RACK_LOCAL)) { for { rack <- sched.getRackForHost(host) index <- findTaskFromList(execId, getPendingTasksForRack(rack)) } { return Some((index, TaskLocality.RACK_LOCAL)) } } // 查找那些preferredLocations为空的,不指定在哪里执行的Task来执行 for (index <- findTaskFromList(execId, pendingTasksWithNoPrefs)) { return Some((index, TaskLocality.PROCESS_LOCAL)) } // 查找那些preferredLocations为空的,不指定在哪里执行的Task来执行 if (TaskLocality.isAllowed(locality, TaskLocality.ANY)) { for (index <- findTaskFromList(execId, allPendingTasks)) { return Some((index, TaskLocality.ANY)) } } // 最后没办法了,拖的时间太长了,只能启动推测执行了 findSpeculativeTask(execId, host, locality) }
从这个方面可以看得出来,Spark对运行时间还是很注重的,等待的时间越长,它就可能越饥不择食,从PROCESS_LOCAL一直让步到ANY,最后的最后,推测执行都用到了。
找到任务之后,它就调用dagScheduler.taskStarted方法,通知dagScheduler任务开始了,taskStarted方法就不详细讲了,它触发dagScheduler的BeginEvent事件,里面只做了2件事:
1、检查Task序列化的大小,超过100K就警告。
2、提交等待的Stage。
好,我们继续回到发布Task上面来,中间过程讲完了,我们应该是要回到CoarseGrainedSchedulerBackend的launchTasks方法了。
def makeOffers() { launchTasks(scheduler.resourceOffers(executorHost.toArray.map {case (id, host) => new WorkerOffer(id, host, freeCores(id))})) }
它的方法体是:
def launchTasks(tasks: Seq[Seq[TaskDescription]]) { for (task <- tasks.flatten) { freeCores(task.executorId) -= scheduler.CPUS_PER_TASK executorActor(task.executorId) ! LaunchTask(task) } }
通过executorId找到相应的executorActor,然后发送LaunchTask过去,一个Task占用一个Cpu。
5、注册Application
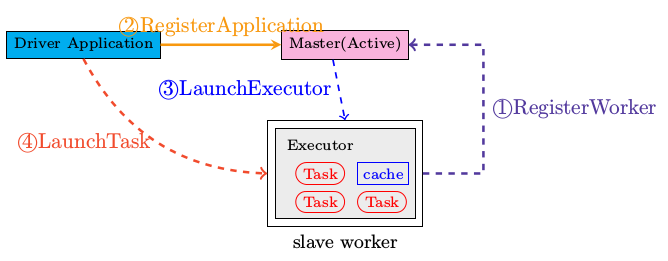
那这个executorActor是怎么来的呢?找呗,最后发现它是在receive方法里面接受到RegisterExecutor消息的时候注册的。通过搜索,我们找到CoarseGrainedExecutorBackend这个类,在它的preStart方法里面赫然找到了driver ! RegisterExecutor(executorId, hostPort, cores) 带的这三个参数都是在初始化的时候传入的,那是谁实例化的它呢,再逆向搜索找到SparkDeploySchedulerBackend!之前的backend一直都是它,我们看reviveOffers是在它的父类CoarseGrainedSchedulerBackend里面。
关系清楚了,在这个backend的start方法里面启动了一个AppClient,AppClient的其中一个参数ApplicationDescription就是封装的运行CoarseGrainedExecutorBackend的命令。AppClient内部启动了一个ClientActor,这个ClientActor启动之后,会尝试向Master发送一个指令actor ! RegisterApplication(appDescription) 注册一个Application。
别废话了,Ctrl +Shift + N吧,定位到Master吧。
case RegisterApplication(description) => { val app = createApplication(description, sender) registerApplication(app) persistenceEngine.addApplication(app) sender ! RegisteredApplication(app.id, masterUrl) schedule() }
它做了5件事:
1、createApplication为这个app构建一个描述App数据结构的ApplicationInfo。
2、注册该Application,更新相应的映射关系,添加到等待队列里面。
3、用persistenceEngine持久化Application信息,默认是不保存的,另外还有两种方式,保存在文件或者Zookeeper当中。
4、通过发送方注册成功。
5、开始作业调度。
Application一旦获得资源,Master会发送launchExecutor指令给Worker去启动Executor,进到Worker里面搜索LaunchExecutor。
val manager = new ExecutorRunner(appId, execId, appDesc, cores_, memory_, self, workerId, host, appDesc.sparkHome.map(userSparkHome => new File(userSparkHome)).getOrElse(sparkHome), workDir, akkaUrl, ExecutorState.RUNNING) executors(appId + "/" + execId) = manager manager.start() coresUsed += cores_ memoryUsed += memory_ masterLock.synchronized { master ! ExecutorStateChanged(appId, execId, manager.state, None, None) }
原来ExecutorRunner还不是传说中的Executor,它内部是执行了appDesc内部的那个命令,启动了CoarseGrainedExecutorBackend,它才是我们的真命天子Executor。
启动之后ExecutorRunner报告ExecutorStateChanged事件给Master。
Master干了两件事:
1、转发给Driver,这个Driver是之前注册Application的那个AppClient
2、如果是Executor运行结束,从相应的映射关系里面删除
6、发布Task
上面又花了那么多时间讲Task的运行环境ExecutorRunner是怎么注册,那我们还是回到我们的主题,Task的发布。
发布任务是发送LaunchTask指令给CoarseGrainedExecutorBackend,接受到指令之后,让它内部的executor来发布这个任务。
这里我们看一下Executor的launchTask。
def launchTask(context: ExecutorBackend, taskId: Long, serializedTask: ByteBuffer) { val tr = new TaskRunner(context, taskId, serializedTask) runningTasks.put(taskId, tr) threadPool.execute(tr) }
TaskRunner是这里的重头戏啊!看它的run方法吧。
override def run() { // 准备工作若干...那天我们放学回家经过一片玉米地,以上省略一百字 try { // 反序列化Task SparkEnv.set(env) Accumulators.clear() val (taskFiles, taskJars, taskBytes) = Task.deserializeWithDependencies(serializedTask) updateDependencies(taskFiles, taskJars) task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader) // 命令为尝试运行,和hadoop的mapreduce作业是一致的 attemptedTask = Some(task) logDebug("Task " + taskId + "'s epoch is " + task.epoch) env.mapOutputTracker.updateEpoch(task.epoch) // 运行Task, 具体可以去看之前让大家关注的ResultTask和ShuffleMapTask taskStart = System.currentTimeMillis() val value = task.run(taskId.toInt) val taskFinish = System.currentTimeMillis() // 对结果进行序列化 val resultSer = SparkEnv.get.serializer.newInstance() val beforeSerialization = System.currentTimeMillis() val valueBytes = resultSer.serialize(value) val afterSerialization = System.currentTimeMillis() // 更新任务的相关监控信息,会反映到监控页面上的 for (m <- task.metrics) { m.hostname = Utils.localHostName() m.executorDeserializeTime = taskStart - startTime m.executorRunTime = taskFinish - taskStart m.jvmGCTime = gcTime - startGCTime m.resultSerializationTime = afterSerialization - beforeSerialization } val accumUpdates = Accumulators.values // 对结果进行再包装,包装完再进行序列化 val directResult = new DirectTaskResult(valueBytes, accumUpdates, task.metrics.getOrElse(null)) val serializedDirectResult = ser.serialize(directResult) // 如果中间结果的大小超过了spark.akka.frameSize(默认是10M)的大小,就要提升序列化级别了,超过内存的部分要保存到硬盘的 val serializedResult = { if (serializedDirectResult.limit >= akkaFrameSize - 1024) { val blockId = TaskResultBlockId(taskId) env.blockManager.putBytes(blockId, serializedDirectResult, StorageLevel.MEMORY_AND_DISK_SER) ser.serialize(new IndirectTaskResult[Any](blockId)) } else { serializedDirectResult } } // 返回结果 execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult) } catch { // 这部分是错误处理,被我省略掉了,主要内容是通关相关负责人处理后事 } finally { // 清理为ResultTask注册的shuffle内存,最后把task从正在运行的列表当中删除 val shuffleMemoryMap = env.shuffleMemoryMap shuffleMemoryMap.synchronized { shuffleMemoryMap.remove(Thread.currentThread().getId) } runningTasks.remove(taskId) } } }
以上代码被我这些了,但是建议大家看看注释吧。
最后结果是通过statusUpdate返回的。
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) { driver ! StatusUpdate(executorId, taskId, state, data) }
这回这个Driver又不是刚才那个AppClient,而是它的家长SparkDeploySchedulerBackend,是在SparkDeploySchedulerBackend的父类CoarseGrainedSchedulerBackend接受了这个StatusUpdate消息。
这关系真他娘够乱的。。
继续,Task里面走的是TaskSchedulerImpl这个方法。
scheduler.statusUpdate(taskId, state, data.value)
到这里,一个Task就运行结束了,后面就不再扩展了,作业运行这块是Spark的核心,再扩展基本就能写出来一本书了,限于文章篇幅,这里就不再深究了。
以上的过程应该是和下面的图一致的。
本文来自博客园,作者:大码王,转载请注明原文链接:https://www.cnblogs.com/huanghanyu/
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号