

Agentic RAG
学习资料:
https://arxiv.org/html/2501.09136v1
https://github.com/asinghcsu/AgenticRAG-Survey
https://github.com/jiangxinke/Agentic-RAG-R1
原文地址:https://qdrant.tech/articles/agentic-rag/
Agentic RAG:借助 Qdrant 构建智能体
一、原文翻译
(一)什么是 Agentic RAG?
标准的检索增强生成(RAG)遵循可预测的线性流程:接收查询、检索相关文档、生成响应。在很多情况下,这足以解决特定问题。但在最坏的情况下,由于上下文信息不足,大语言模型(LLM)可能会拒绝回答问题。
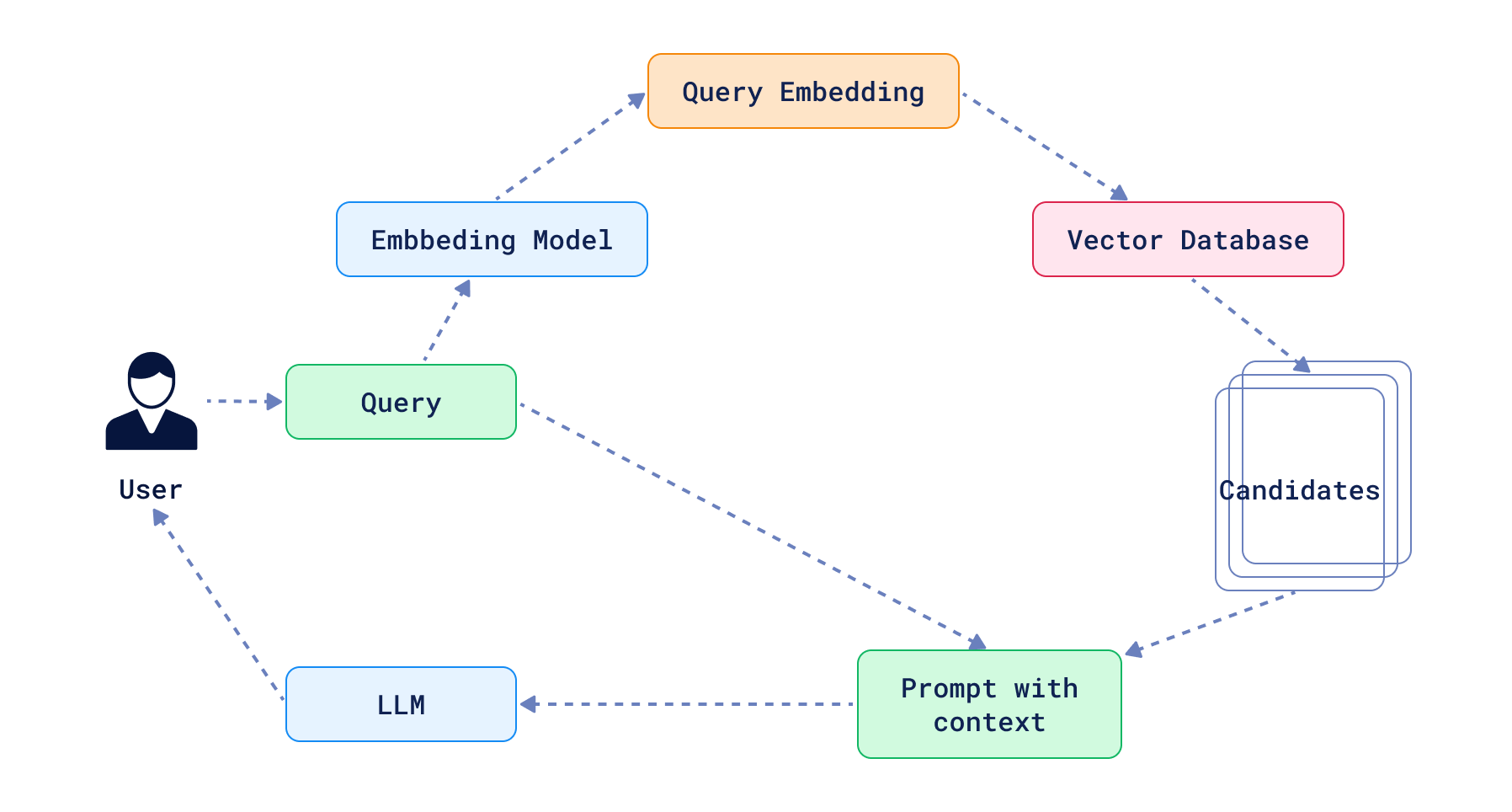
而智能体(Agents)则不同。这类系统拥有更大的行动自由度,能够通过多个非线性步骤实现特定目标。目前,智能体尚无统一定义,但总体而言,它是一种利用 LLM 且通常结合部分工具与外部世界交互的应用程序。LLM 充当决策者,决定下一步采取何种行动。行动形式多样,但通常具有明确界定且局限于特定范围。其中一种行动是,当现有上下文不足以支撑决策时,查询向量数据库(如 Qdrant)以检索相关文档。不过,RAG 只是智能体工具库中的一个工具而已。
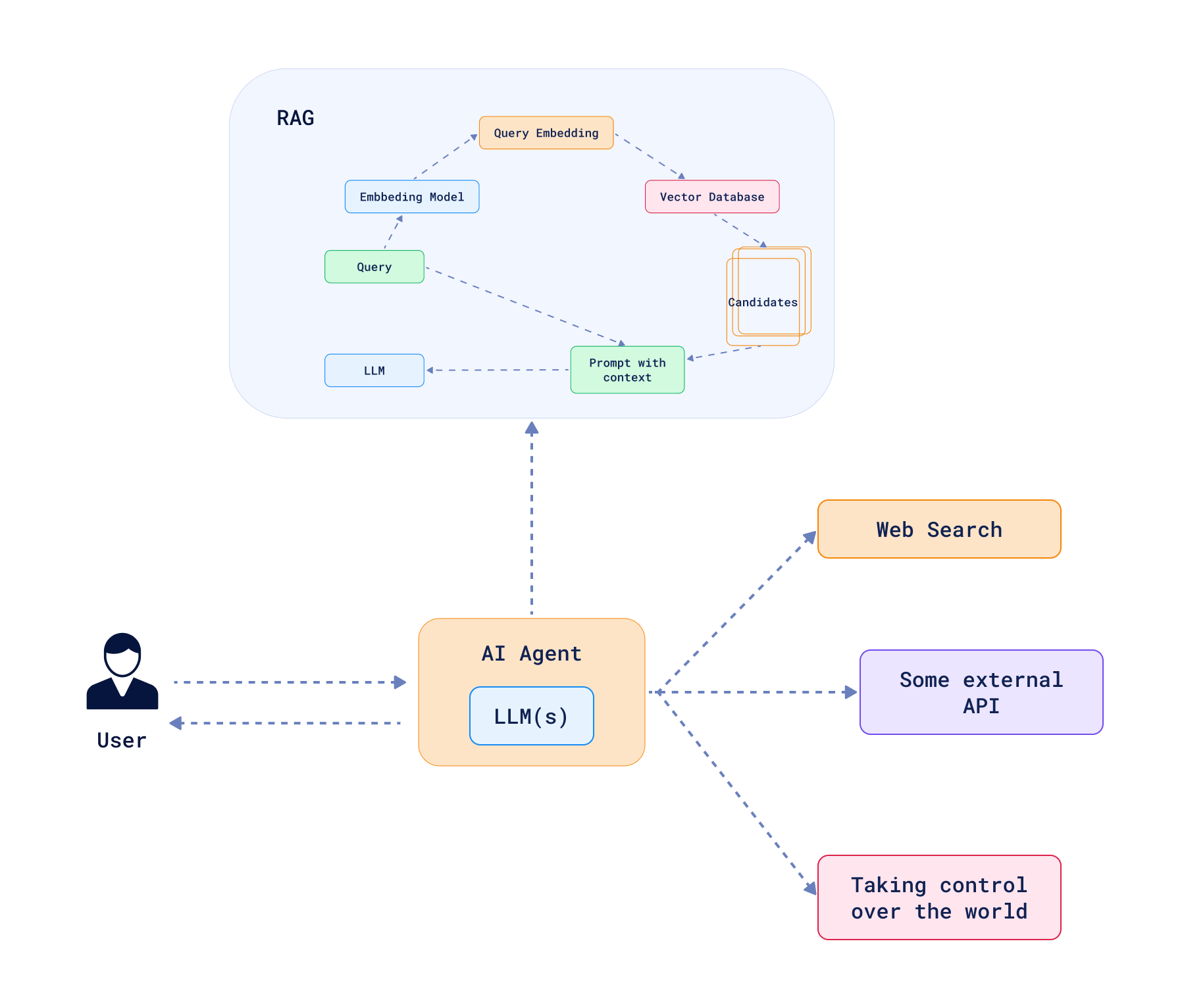
Agentic RAG:融合 RAG 与智能体
由于智能体的定义较为模糊,Agentic RAG 的概念也尚未明确。总体来说,它指的是 RAG 与智能体的结合。这使得智能体能够利用外部知识源进行决策,且主要用于判断何时需要调用外部知识。如果一个系统打破了标准 RAG 的线性流程,赋予智能体通过多步骤实现目标的能力,那么我们就可以将其称为 Agentic RAG。
简单的路由器(用于选择执行路径)通常被视为最简单的智能体形式。这类系统包含多条路径,且每条路径都有对应的条件,规定了何时选择该路径。在 Agentic RAG 的场景中,智能体可以根据情况做出判断:若上下文不足以回答问题,则查询向量数据库;若上下文足够,或问题涉及常识性内容,则跳过查询步骤。此外,也可能存在多个存储不同类型信息的集合,智能体可依据上下文决定查询哪个集合。关键在于,路径选择的决策由作为智能体核心的 LLM 做出。路由智能体不会回溯到之前的步骤,因此本质上它只是一个条件决策系统。
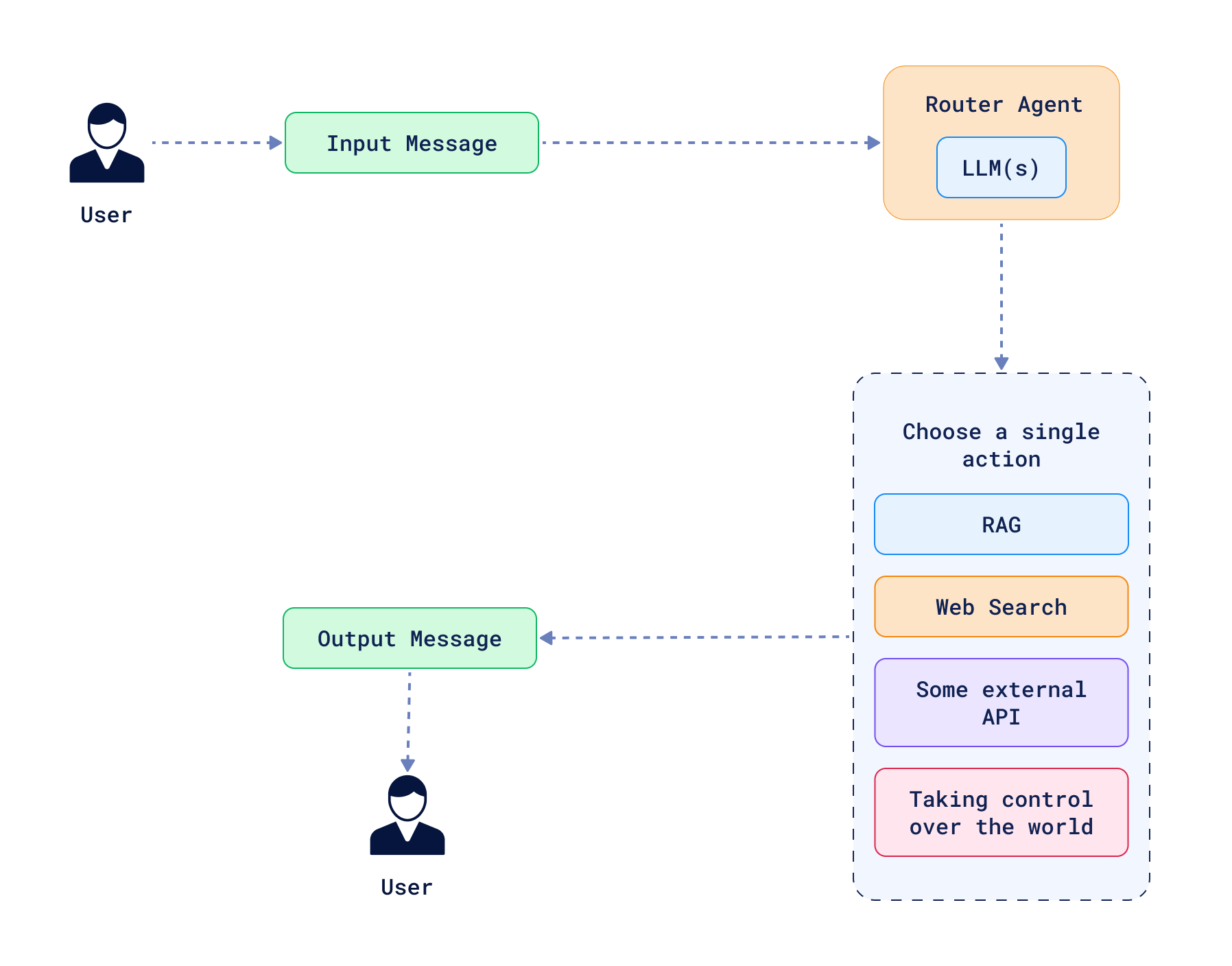
然而,路由仅仅是起点。智能体可以变得更为复杂,高级形式的智能体拥有完全的行动自主权。在这种情况下,智能体被赋予一组工具,能够自主决定使用哪些工具、如何使用以及使用顺序。LLM 会规划并执行这些行动,智能体可通过多个步骤实现目标,必要时还能回溯调整。这类系统无需遵循有向无环图(DAG)结构,允许存在循环,以帮助修正过往做出的决策。基于这种方式构建的 Agentic RAG 系统,其工具不仅可用于查询向量数据库,还能优化查询、总结结果,甚至生成新数据来回答问题。其应用场景极具多样性,但在实际应用中也存在一些常见模式。
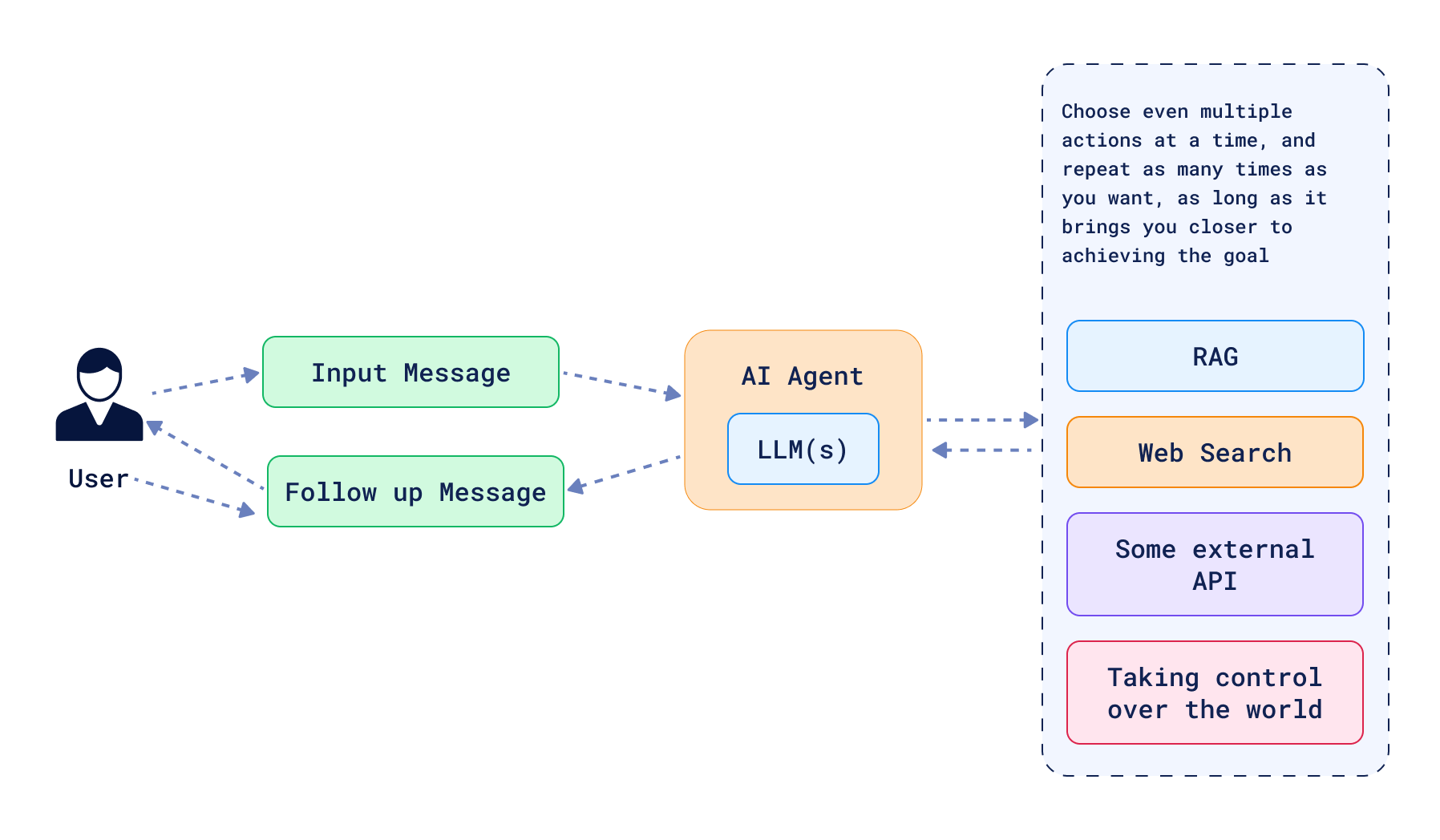
(二)利用 LLM 解决信息检索问题
通常来说,Agentic RAG 系统中提供的工具用于解决信息检索问题,这类问题在搜索领域早已存在。尽管 LLM 改变了我们处理这些问题的方式,但问题的核心本质并未改变。以下是 Agentic RAG 中常见的工具类型:
- 查询向量数据库:这是 Agentic RAG 系统中最常用的工具,能让智能体根据查询检索相关文档。
- 查询扩展:用于优化查询的工具,可添加同义词、纠正拼写错误,甚至基于原始查询生成新的查询。例如,原始查询为 “mens denim jacket”(男士牛仔夹克),经工具处理后可能扩展为 “mens denim jacket jeans size large coat outerwear size large”(男士牛仔夹克、牛仔裤、大号、外套、户外服装、大号)。
![image]()
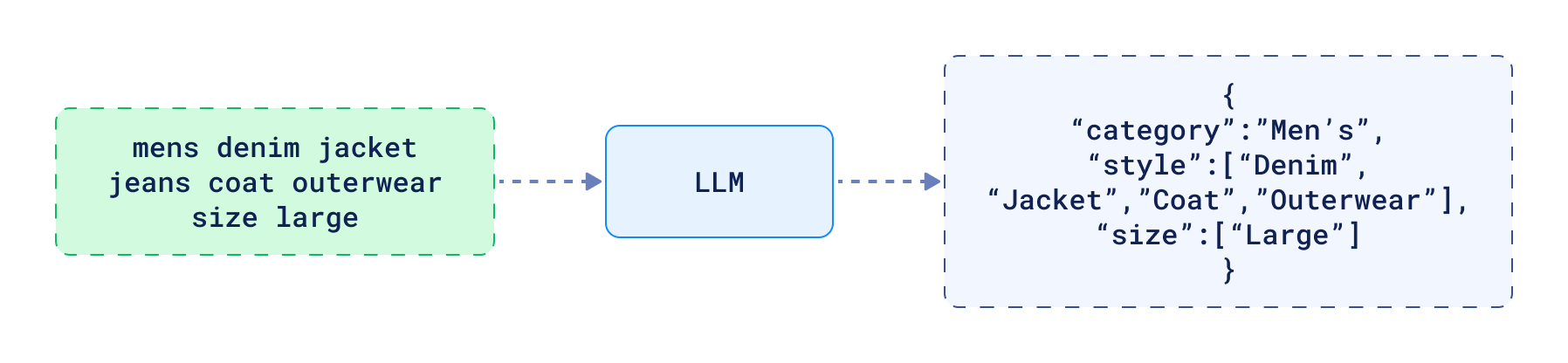
- 提取过滤器:仅依靠向量搜索有时并不足够。在很多情况下,需要根据特定参数缩小结果范围。提取过滤器能从查询中自动识别相关条件,否则用户就需手动定义这些搜索约束。例如,对于查询 “mens denim jacket jeans coat outerwear size large”,工具可提取出过滤器条件:{"category": ["Jacket", "Coat", "Outerwear"], "size": ["Large"]}。
![image]()
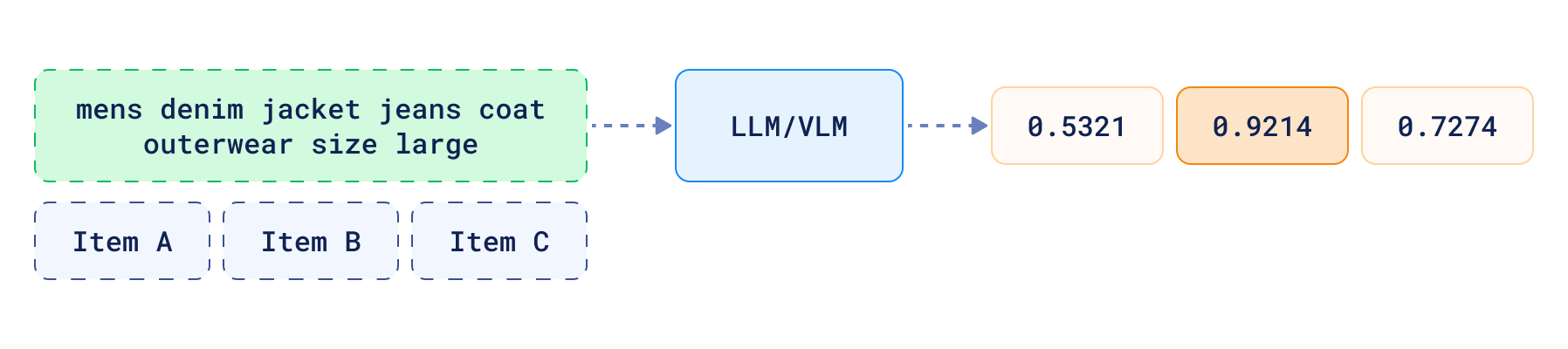
- 质量判断:通过评估查询结果的质量,判断其是否足以回答问题,或是否需要智能体进一步采取措施优化结果,也可直接告知用户无法提供满意答复。例如,对于上述查询,工具会为不同结果项给出质量评分(如 Item A:0.5321、Item B:0.9214、Item C:0.7274)。
![image]()

以上仅为部分示例,工具种类远不止这些。例如,LLM 可调整 Qdrant 的搜索参数或选择不同的查询方式。若用户使用特定关键词搜索,稀疏向量可能比稠密向量更高效,此时就需要为智能体配备工具,使其能够判断何时使用稀疏向量、何时使用稠密向量。了解集合结构的智能体能够轻松做出此类决策。
这些工具中的每一个都可作为独立的智能体,多智能体系统也并不少见。在多智能体系统中,智能体之间可以相互通信,一个智能体可决定借助另一个智能体解决特定问题。Agentic RAG 中一个非常实用的组成部分是 “人机协作(human-in-the-loop)”,通过人工反馈修正智能体的决策,或引导其朝着正确方向推进。
(三)智能体的应用场景
智能体是一个有趣的概念,但由于其严重依赖 LLM,并非适用于所有问题。使用大语言模型成本高昂且速度较慢,在很多情况下并不值得投入。标准 RAG 仅需调用一次 LLM,响应生成方式可预测;而智能体可能需要执行多个步骤,用户面临的延迟会不断累积,这在很多场景下是无法接受的。Agentic RAG 可能不太适用于电子商务搜索(用户期望快速得到响应),但对于客户支持场景可能较为合适 —— 用户愿意为更优质的答案等待稍长的时间。
(四)最佳框架选择
目前有许多用于构建智能体的框架,选择最佳框架并非易事,这取决于你现有的技术栈或熟悉的工具。一些最受欢迎的 LLM 库已经朝着智能体范式发展,并提供了相关构建工具。不过,也有一些工具是专门为智能体开发设计的,以下重点介绍这类框架:
1. LangGraph
由 LangChain 团队开发,对于那些已经使用 LangChain 构建 RAG 系统并希望转向 Agentic RAG 的用户来说,LangGraph 是一个自然的延伸选择。
令人意外的是,LangGraph 本身与大语言模型并无关联。它是一个用于构建基于图结构的应用程序的框架,其中每个节点代表工作流的一个步骤。每个节点接收应用程序状态作为输入,并生成修改后的状态作为输出,该状态随后传递给下一个节点,依此类推。节点之间的边可以带有条件,支持分支逻辑。与部分基于有向无环图(DAG)的工具(如 Apache Airflow)不同,LangGraph 允许图中存在循环,从而能够实现循环工作流,使智能体具备自我反思和自我修正的能力。从理论上讲,LangGraph 可用于以图结构的方式构建各类应用程序,而非仅限于 LLM 智能体。
LangGraph 的优势包括:
- 持久性:工作流图的状态会以检查点的形式存储,这一过程发生在每个所谓的 “超级步骤(super-step)”(即图的单个连续节点)。这一机制支持工作流特定步骤的重试、容错处理以及人机协作交互,同时还可作为短期记忆,在特定工作流执行过程中提供上下文支持。
- 长期记忆:LangGraph 还支持不同工作流运行之间共享的记忆机制,但这一机制需要通过节点明确处理。具备语义搜索功能的 Qdrant 常被用作长期记忆层。
- 多智能体支持:虽然 LangGraph 中没有单独的多智能体系统概念,但可以通过构建包含多个智能体和某种 “监督者”(负责决定在特定场景下使用哪个智能体)的图来实现多智能体架构。由于节点可以是任何类型,因此也可以是另一个智能体。
LangGraph 还有其他一些有趣的功能,包括图可视化、自动重试失败步骤以及支持人机协作交互等。
一个简单的 Agentic RAG 示例可能会先优化用户查询(如纠正拼写错误、添加同义词、基于原始查询生成新查询等),然后根据优化后的查询从向量数据库中检索文档,最后生成响应。基于 LangGraph 实现该逻辑的应用程序代码如下:
from typing import Sequence
from typing_extensions import TypedDict, Annotated
from langchain_core.messages import BaseMessage
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
class AgentState(TypedDict):
# The state of the agent includes at least the messages exchanged between the agent(s)
# and the user. It is, however, possible to include other information in the state, as
# it depends on the specific agent.
messages: Annotated[Sequence[BaseMessage], add_messages]
def improve_query(state: AgentState):
...
def retrieve_documents(state: AgentState):
...
def generate_response(state: AgentState):
...
# Building a graph requires defining nodes and building the flow between them with edges.
builder = StateGraph(AgentState)
builder.add_node("improve_query", improve_query)
builder.add_node("retrieve_documents", retrieve_documents)
builder.add_node("generate_response", generate_response)
builder.add_edge(START, "improve_query")
builder.add_edge("improve_query", "retrieve_documents")
builder.add_edge("retrieve_documents", "generate_response")
builder.add_edge("generate_response", END)
# Compiling the graph performs some checks and prepares the graph for execution.
compiled_graph = builder.compile()
# Compiled graph might be invoked with the initial state to start.
compiled_graph.invoke({
"messages": [
("user", "Why Qdrant is the best vector database out there?"),
]
})流程中的每个节点本质上都是一个执行特定操作的 Python 函数。你可以在函数内部调用任意选择的 LLM,但框架并不要求消息必须由 AI 生成。LangGraph 更像是一个运行时环境,按照特定顺序启动这些函数,并在函数之间传递状态。虽然 LangGraph 与 LangChain 生态系统集成良好,但也可独立使用。对于需要额外支持和功能的团队,其商业版本 LangGraph Platform 也已推出。该框架支持 Python 和 JavaScript 环境,可适配不同的技术栈。
2. CrewAI
CrewAI 是另一个用于构建智能体(包括 Agentic RAG)的热门选择。它是一个高级框架,核心假设是多个基于 LLM 的智能体协同工作以实现共同目标 —— 这也是 “CrewAI” 中 “Crew”(团队)一词的由来。CrewAI 专为多智能体系统设计。与 LangGraph 不同,开发者无需构建处理流程图,而是定义智能体及其在团队中的角色。
CrewAI 的核心概念包括:
- 智能体(Agent):具有特定角色和目标的单元,由 LLM 控制。它可以选择性地使用一些外部工具与外部世界交互,但总体上受我们提供给 LLM 的提示词引导。
- 流程(Process):目前支持顺序流程和分层流程两种类型,定义了智能体执行任务的方式。在顺序流程中,智能体按顺序依次执行;在分层流程中,由管理智能体决定在特定场景下使用哪个智能体。
- 角色和目标(Roles and goals):每个智能体在团队中都有特定角色和需要实现的目标。这些在定义智能体时设定,并用于决策在特定场景下使用哪个智能体。
- 记忆(Memory):强大的记忆系统包括短期记忆、长期记忆、实体记忆以及融合了前三者的上下文记忆,此外还有用于存储用户偏好和个性化信息的用户记忆。Qdrant 可作为长期记忆层应用于该系统。
CrewAI 框架中集成了丰富的工具集,对于希望将 RAG 与代码执行、图像生成等功能结合的用户来说,这是一个巨大的优势。其生态系统丰富,且易于扩展,即使是集成自定义工具也并不复杂。
基于 CrewAI 实现的简单 Agentic RAG 应用程序代码如下:
from crewai import Crew, Agent, Task
from crewai.memory.entity.entity_memory import EntityMemory
from crewai.memory.short_term.short_term_memory import ShortTermMemory
from crewai.memory.storage.rag_storage import RAGStorage
class QdrantStorage(RAGStorage):
...
response_generator_agent = Agent(
role="Generate response based on the conversation",
goal="Provide the best response, or admit when the response is not available.",
backstory=(
"I am a response generator agent. I generate "
"responses based on the conversation."
),
verbose=True,
)
query_reformulation_agent = Agent(
role="Reformulate the query",
goal="Rewrite the query to get better results. Fix typos, grammar, word choice, etc.",
backstory=(
"I am a query reformulation agent. I reformulate the "
"query to get better results."
),
verbose=True,
)
task = Task(
description="Let me know why Qdrant is the best vector database out there.",
expected_output="3 bullet points",
agent=response_generator_agent,
)
crew = Crew(
agents=[response_generator_agent, query_reformulation_agent],
tasks=[task],
memory=True,
entity_memory=EntityMemory(storage=QdrantStorage("entity")),
short_term_memory=ShortTermMemory(storage=QdrantStorage("short-term")),
)
crew.kickoff()尽管并非技术层面的优势,但 CrewAI 拥有完善的文档。该框架支持 Python 语言,易于上手。其商业版本 CrewAI Enterprise 提供了大规模构建和部署智能体的平台。
3. AutoGen
AutoGen 将多智能体架构作为核心设计原则。该框架要求任何系统中至少包含两个智能体才能被称为 “智能体应用”—— 通常是助手智能体和用户代理智能体通过交换消息实现共同目标。它支持两个以上智能体的顺序对话、群聊以及用于内部对话的嵌套聊天。不过,AutoGen 并不假设智能体之间传递结构化状态,聊天对话是智能体之间唯一的通信方式。
该框架包含许多有趣且独特的概念:
- 工具 / 函数(Tools/functions):智能体用于与外部世界交互的外部组件,定义为 Python 可调用对象,可支持任何允许智能体执行的外部交互。通过类型注解定义工具的输入和输出,支持 Pydantic 模型用于更复杂的类型模式。目前,AutoGen 仅支持与 OpenAI 兼容的工具调用 API。
- 代码执行器(Code executors):内置的代码执行器包括本地命令、Docker 命令和 Jupyter。智能体可以编写并运行代码,因此理论上能够完成任何 Python 可实现的任务。其他框架均未将代码生成和执行置于如此重要的地位,代码执行是 AutoGen 中的核心功能,这一设计非常独特。
每个 AutoGen 智能体至少使用以下组件之一:人机协作、代码执行器、工具执行器或 LLM。基于两个智能体协作(可检索向量数据库文档或优化查询)的简单 Agentic RAG 示例代码如下:
from os import environ
from autogen import ConversableAgent
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
from qdrant_client import QdrantClient
client = QdrantClient(...)
response_generator_agent = ConversableAgent(
name="response_generator_agent",
system_message=(
"You answer user questions based solely on the provided context. You ask to retrieve relevant documents for "
"your query, or reformulate the query, if it is incorrect in some way."
),
description="A response generator agent that can answer your queries.",
llm_config={"config_list": [{"model": "gpt-4", "api_key": environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER",
)
user_proxy = RetrieveUserProxyAgent(
name="retrieval_user",
llm_config={"config_list": [{"model": "gpt-4", "api_key": environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER",
retrieve_config={
"task": "qa",
"chunk_token_size": 2000,
"vector_db": "qdrant",
"db_config": {"client": client},
"get_or_create": True,
"overwrite": True,
},
)
result = user_proxy.initiate_chat(
response_generator_agent,
message=user_proxy.message_generator,
problem="Why Qdrant is the best vector database out there?",
max_turns=10,
)对于智能体开发新手,AutoGen 提供了 AutoGen Studio—— 一个低代码界面,用于智能体原型开发。尽管它不适合生产环境使用,但极大地降低了实验智能体架构的门槛。
值得注意的是,AutoGen 目前正在进行重大更新,开发中的 0.4.x 版本与稳定版 0.2.x 相比,API 发生了显著变化。该框架目前的内置持久性和状态管理功能有限,但这些功能可能会在未来版本中不断完善。
4. OpenAI Swarm
与本文介绍的其他框架不同,OpenAI Swarm 是一个教育性项目,尚未准备好投入生产使用。但值得一提的是,它非常轻量且易于上手。OpenAI Swarm 是一个实验性框架,用于编排多智能体工作流,其核心是通过直接交接而非复杂的编排模式实现智能体协作。
在该框架中,智能体通过聊天交换消息,可选择性地调用 Python 函数与外部服务交互,或在另一个智能体更适合回答问题时,将对话交接给该智能体。每个智能体都有特定角色,由我们定义的指令确定。我们需要为每个智能体指定所使用的 LLM 以及可调用的函数集合。例如,检索智能体可使用向量数据库检索文档,并将结果返回给下一个智能体。这意味着需要一个函数代表智能体执行语义搜索,而查询的具体形式由模型决定。
基于 OpenAI Swarm 实现的类似 Agentic RAG 应用程序代码如下:
from swarm import Swarm, Agent
client = Swarm()
def retrieve_documents(query: str) -> list[str]:
"""
根据查询检索文档。
"""
...
def transfer_to_query_improve_agent():
return query_improve_agent
query_improve_agent = Agent(
name="查询优化智能体",
instructions=(
"你是一名搜索专家,负责优化用户查询以获得更优结果。如需修正拼写错误、添加同义词,"
"但不得向用户询问更多信息。"
),
)
response_generation_agent = Agent(
name="响应生成智能体",
instructions=(
"你需根据整个对话历史生成最终响应。若信息不足,可从知识库检索文档或通过交接给其他智能体优化查询,"
"不得向用户询问更多信息,且必须是每个对话的最后参与者。"
),
functions=[retrieve_documents, transfer_to_query_improve_agent],
)
response = client.run(
agent=response_generation_agent,
messages=[
{
"role": "user",
"content": "为什么 Qdrant 是目前最优秀的向量数据库?"
}
],
)尽管我们没有明确定义处理流程图,但智能体仍可决定将处理任务交接给其他智能体。该框架中不存在 “状态” 概念,所有交互都依赖于不同组件之间交换的消息。
OpenAI Swarm 并不侧重于与外部工具的集成,若要将其与 Qdrant 语义搜索集成,需完全自行实现相关功能。显然,该库与 OpenAI 模型紧密耦合,尽管也可使用其他模型,但需要额外的工作(如设置代理以适配 OpenAI API 接口)。
(五)最佳框架选择?
选择适合 Agentic RAG 系统的最佳框架,取决于你现有的技术栈、团队专业知识以及项目的具体需求。本文介绍的所有工具都是强有力的竞争者,且都在快速发展中。值得持续关注这些框架,它们未来可能会不断演进和完善。理论上,使用任何一个框架都能实现相同的流程,但在特定的工具生态系统中,某些框架可能更具优势。
不过,选择框架时需考虑以下重要因素:
- 人机协作(Human-in-the-loop):尽管我们的目标是构建自主智能体,但纳入人工反馈通常至关重要,可防止智能体执行恶意操作。
- 可观测性(Observability):系统的调试难度以及内部运行状态的可理解性 —— 这一点尤为重要,因为我们需要处理大量的 LLM 提示词。
归根结底,选择合适的工具包取决于项目现状和具体需求。若需将智能体与多个外部工具集成,CrewAI 可能是最佳选择,因为它提供了最丰富的开箱即用集成。而如果你熟悉 LangChain 生态系统,LangGraph 可能更适合你。
所有框架都有各自构建智能体的方法,建议尝试所有框架以找到最适合自己需求的工具。LangGraph 和 CrewAI 更为成熟,功能更丰富;而 AutoGen 和 OpenAI Swarm 则更轻量,更具实验性。然而,现有框架都无法解决所有上述信息检索问题,因此你仍需构建自定义工具来弥补不足。
(六)借助 Qdrant 构建 Agentic RAG
无论选择哪种框架,Qdrant 都是构建 Agentic RAG 系统的理想工具。请查看我们的集成文档,选择最适合你的使用场景和偏好的集成方式。开始使用 Qdrant 最简单的方式是使用我们的托管服务 Qdrant Cloud—— 提供免费的 1GB 集群,让你在几分钟内即可启动 Agentic RAG 系统的构建。
二、内容总结
本文围绕 Agentic RAG 展开全面介绍,首先阐释了 Agentic RAG 的核心概念 —— 它是检索增强生成(RAG)与智能体(Agents)的融合,打破了标准 RAG 的线性流程,赋予智能体多步骤决策和行动能力,可灵活调用外部知识源解决问题。
接着,文章介绍了 Agentic RAG 中用于解决信息检索问题的常见工具,包括查询向量数据库、查询扩展、提取过滤器、质量判断等,同时提及多智能体协作与人机协作的重要性。
在应用场景方面,指出 Agentic RAG 因依赖 LLM 导致成本高、延迟高,不适用于对响应速度要求高的电子商务搜索,但适用于客户支持等可接受稍长等待时间的场景。
随后,重点对比了四款主流的智能体构建框架:LangGraph 基于图结构,支持循环工作流和多智能体架构,与 LangChain 生态兼容性好;CrewAI 以多智能体协同为核心,工具集成丰富,文档完善;AutoGen 强调多智能体架构,代码执行功能突出,提供低代码开发工具;OpenAI Swarm 轻量易上手,但偏向实验性,与外部工具集成需自行实现。
最后,总结了框架选择的关键因素(人机协作、可观测性等),并推荐 Qdrant 作为构建 Agentic RAG 系统的向量数据库工具,其托管服务 Qdrant Cloud 可降低入门门槛。
三、摘要
本文详细解析了 Agentic RAG 的概念、工具、应用场景及相关构建框架。Agentic RAG 是 RAG 与智能体的结合,突破了标准 RAG 的线性限制,可通过多步骤决策与外部知识源交互。文中介绍了查询优化、结果过滤等信息检索工具,指出其适用于客户支持等场景,不适用于电商搜索。重点对比了 LangGraph、CrewAI、AutoGen、OpenAI Swarm 四款框架的核心特性、优势及适用场景,强调框架选择需结合技术栈、项目需求等因素。同时推荐 Qdrant 作为向量数据库工具,其托管服务可助力快速搭建 Agentic RAG 系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号