python高级应用程序设计任务
一、主题式网络爬虫设计方案
1、主题式网络爬虫名称
爬取链家泉州二手房数据及其数据分析
2、主题式网络爬虫爬取的内容与数据特征分析
A、爬虫的内容
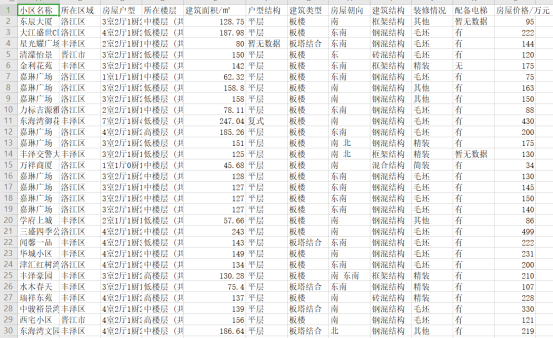
小区名称、所在区域、房屋户型、所在楼层、建筑面积、户型结构建筑类型、房屋朝向、建筑结构、装修情况、配备电梯、房屋价格
B、数据特征分析
b1、对泉州二手房房价分布进行可视化分析
b2、对泉州二手房房屋面积分布进行可视化分析
b3、对泉州二手房所在楼层进行可视化分析
b4、对泉州二手房房屋户型分布进行可视化分析
b5、对泉州各区二手房房价进行可视化分析
b6、对相关指标进行相关性分析
3、主题式网络爬虫设计设计方案概述
A、实现思路
定义get_page_index()获取所有详情页的网页源代码,然后在通过parse_page_index()来提取每个详情页的url,在通过get_page_detail()获取每个详情页的网页源代码,在通过parse_page_detail()获取每个详情页所需要爬取的具体信息数据,最后通过save_to_csv()保存到csv文件中。
B、技术难点
详情页的每个指标的提取具有一定的困难,爬取的速度比较慢。
二、主题页面的结构特征分析
1、主题页面的结构特征
每页共30条数据,共爬取了100页,数据总量为3000条,通过F12检查页面,发现所需要爬取的数据都是静态的。
2、Htmls页面解析
需要爬取的数据如图所示:
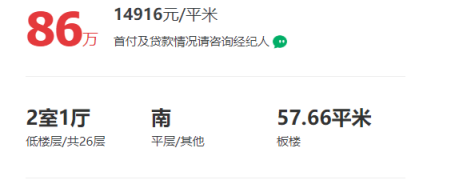
3、节点查找方法与遍历方法
在索引页上获取每个详情页url运用正则表达式的方法,然后运用BeautifulSoup,使用select方法,获取所需要的数据所在的节点。
三、网络爬虫程序设计
1、数据爬取与采集
爬虫代码如下所示:
1 # !/usr/bin/env python
2 # -*- coding:utf-8-*- 3 4 import requests 5 from requests.exceptions import RequestException 6 from bs4 import BeautifulSoup 7 import re 8 import csv 9 import pandas as pd 10 11 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}#获取索引页的源代码 12 def get_page_index(url): 13 try: 14 response = requests.get(url, headers=headers) #get请求获取网页源码 15 if response.status_code == 200: 16 return response.text 17 return None 18 except RequestException: 19 print('请求页面出错...') 20 return None 21 #获取每条详情页的URL 22 def parse_page_index(html): 23 pattern = re.compile('<a class="" href="(.*?)" target="_blank" data-log', re.S) 24 items = re.findall(pattern, html) 25 return items 26 #获取每个详情页的网页源码 27 def get_page_detail(url): 28 try: 29 response = requests.get(url, headers=headers) 30 if response.status_code == 200: 31 return response.text.encode('utf-8') 32 return None 33 except RequestException: 34 print('请求页面出错...') 35 return None 36 #获取所需要爬取的数据信息 37 def parse_page_detail(html): 38 soup = BeautifulSoup(html, 'lxml') 39 infos = {} 40 infos['小区名称'] = soup.select('.info')[0].get_text() 41 infos['所在区域'] = soup.select('.info a')[0].get_text() 42 infos['房屋户型'] = soup.select('.content ul li')[0].get_text().replace('房屋户型', '') 43 infos['所在楼层'] = soup.select('.content ul li')[1].get_text().replace('所在楼层', '') 44 infos['建筑面积/㎡'] = soup.select('.content ul li')[2].get_text().replace('建筑面积', '').replace('㎡', '') 45 infos['户型结构'] = soup.select('.content ul li')[3].get_text().replace('户型结构', '') 46 infos['建筑类型'] = soup.select('.content ul li')[5].get_text().replace('建筑类型', '') 47 infos['房屋朝向'] = soup.select('.content ul li')[6].get_text().replace('房屋朝向', '') 48 infos['建筑结构'] = soup.select('.content ul li')[7].get_text().replace('建筑结构', '') 49 infos['装修情况'] = soup.select('.content ul li')[8].get_text().replace('装修情况', '') 50 infos['配备电梯'] = soup.select('.content ul li')[10].get_text().replace('配备电梯', '') 51 infos['房屋价格/万元'] = soup.select('.total')[0].get_text() 52 # print(infos) 53 yield infos 54 #将标题添加到csv文件中 55 def write_csv_header(fileheader): 56 with open("lianjia.csv", "a", newline='') as csvfile: 57 writer = csv.DictWriter(csvfile, fileheader) 58 writer.writeheader() 59 #把爬取到的数据保存到csv文件之中 60 def save_to_csv(result, fileheader): 61 with open("lianjia.csv", "a", newline='') as csvfile: 62 print('正在写入csv文件中.....') 63 writer = csv.DictWriter(csvfile, fieldnames=fileheader) 64 writer.writerow(result) 65 #主函数 66 def main(page, fileheader): 67 url = 'https://quanzhou.lianjia.com/ershoufang/pg' + str(page) + '/' 68 html = get_page_index(url) 69 for item in parse_page_index(html): 70 html_detail = get_page_detail(item) 71 if html_detail: 72 results = parse_page_detail(html_detail) 73 for result in results: 74 save_to_csv(result, fileheader) 75 76 if __name__ == '__main__': 77 fileheader = ['小区名称', '所在区域', '房屋户型', '所在楼层', '建筑面积/㎡', '户型结构', '建筑类型','房屋朝向','建筑结构', '装修情况', '配备电梯', '房屋价格/万元'] 78 write_csv_header(fileheader) 79 for page in range(1, 101): 80 main(page,fileheader)
1、对数据进行清洗和处理
删除含有缺失值的数据,并删除重复行。将所在楼层那一列中的所在楼层的类型提取出来作为所在楼层这一列,将其中的总楼层数提取出来,并增加一列。
1 # !/usr/bin/env python 2 # -*- coding:utf-8-*- 3 4 import pandas as pd 5 import matplotlib.pyplot as plt 6 import seaborn as sns 7 8 9 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体 10 plt.rcParams['axes.unicode_minus'] = False 11 data = pd.read_csv('lianjia.csv') 12 data = data.dropna() 13 data = data.drop_duplicates() 14 df = data.copy() 15 data = data[data['房屋价格/万元'] <= 1000] 16 data['总楼层'] = df['所在楼层'].str.extract(r'共(\d+)层').astype('int64') 17 df = data.copy()
3、数据分析与可视化
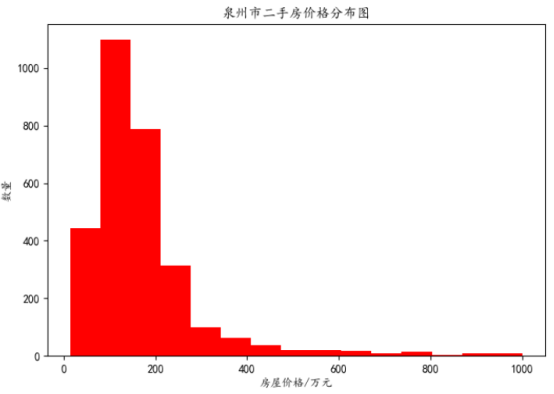
A、房屋价格分布分析:为了使图的效果更加明显,我们这里选择房屋价格小于1000万元的。
代码如下所示:
1 data['总楼层'] = df['所在楼层'].str.extract(r'共(\d+)层').astype('int64') 2 data['所在楼层'] = data['所在楼层'].str.extract(r'(.*?)楼层') 3 plt.figure(figsize = (7,5)) 4 plt.hist(data['房屋价格/万元'],bins = 15,color = 'r') 5 plt.xlabel('房屋价格/万元') 6 plt.ylabel('泉州市二手房价格分布图') 7 plt.show()
所得到的分布图如下图所示:
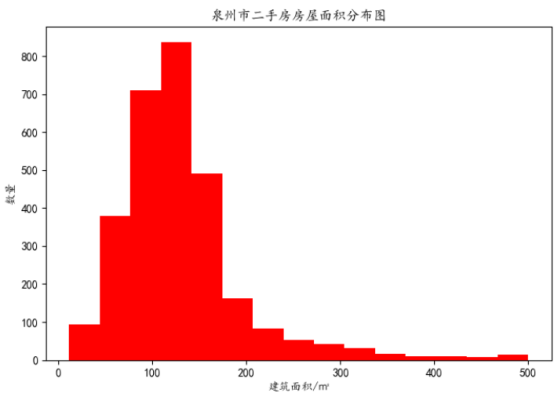
B、房屋面积分布情况:为了使图的效果更加明显,房屋面积选取面积小于500平米的。
代码如下所示:
1 data = data[data['建筑面积/㎡'] <= 500] 2 plt.figure(figsize = (7,5)) 3 plt.hist(data['建筑面积/㎡'],bins = 15,color = 'r') 4 plt.xlabel('建筑面积/㎡') 5 plt.ylabel('数量') 6 plt.title('泉州市二手房房屋面积分布图') 7 plt.show()
其分布图如下图所示:
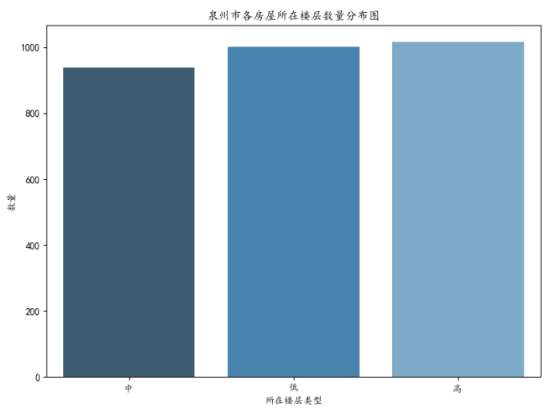
C、所在楼层分布图:所在楼层这里主要分为三类,分别是高层楼,中层楼和低层楼。
代码如下所示:
1 floor_count_data = data.groupby('所在楼层')['房屋价格/万元'].count().to_frame().reset_index() 2 _,ax = plt.subplots(figsize = (8,6)) 3 sns.barplot(x = '所在楼层',y = '房屋价格/万元',palette = 'Blues_d',data = floor_count_data,ax = ax) 4 ax.set_title('泉州市各房屋所在楼层数量分布图') 5 ax.set_xlabel('所在楼层类型') 6 ax.set_ylabel('数量') 7 plt.show()
所得到的分布图如下图所示:
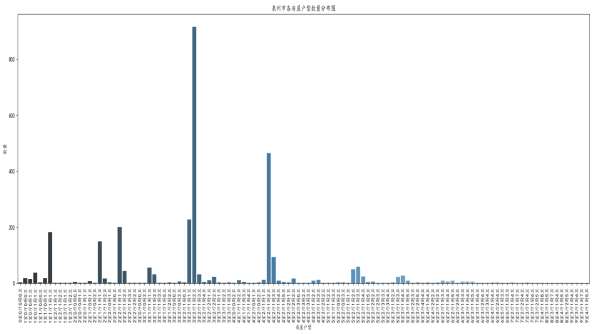
D、房屋户型分布图:
代码如下所示:
1 type_count_data = data.groupby('房屋户型')['房屋价格/万元'].count().to_frame().reset_index() 2 _,ax = plt.subplots(figsize = (20,8)) 3 sns.barplot(x = '房屋户型',y = '房屋价格/万元',palette = 'Blues_d',data = type_count_data,ax = ax) 4 ax.set_title('泉州市各房屋户型数量分布图') 5 ax.set_xlabel('房屋户型') 6 ax.set_xticklabels(type_count_data.iloc[:,0],rotation = 90) 7 ax.set_ylabel('数量') 8 plt.show() 9 data = data[data['房屋价格/万元'] < 500]
所得到的分布图如下图所示:
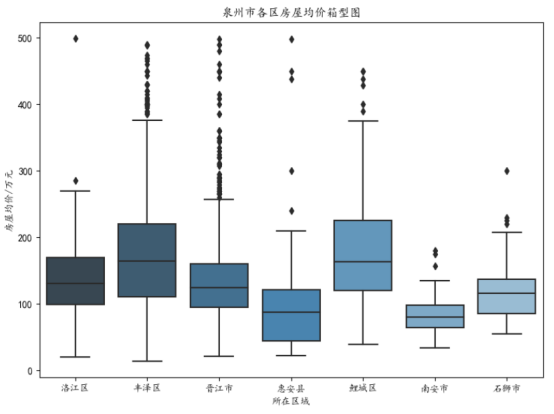
E、各区房屋均价箱型图:同时选取房屋价格低于500万元的数据部分。
代码如下所示:
1 region_price_data = data.groupby('所在区域')['房屋价格/万元'].mean().to_frame().reset_index() 2 _,ax = plt.subplots(figsize = (8,6)) 3 sns.boxplot(x = '所在区域',y = '房屋价格/万元',palette = 'Blues_d',data = data,ax = ax) 4 ax.set_title('泉州市各区房屋均价箱型图') 5 ax.set_xlabel('所在区域') 6 ax.set_ylabel('房屋均价/万元') 7 plt.show()
箱型图如下所示:
F、房屋价格与建筑面积的相关性分析:
代码如下所示:
1 part_data = data[['建筑面积/㎡','房屋价格/万元']] 2 corr = part_data.corr() 3 print(corr) 4 sns.heatmap(corr) 5 plt.show()
所得到的相关性矩阵为:


4、数据持久化
将爬取到的数据保存为csv文件,可用excel打开该文件。
四、结论
1、经过对主题数据的分析与可视化,可以得到哪些结论?
a、泉州市二手房房价主要分布于50万到300万元之间。
b、泉州市二手房房屋面积主要分布于50到250平米之间。
c、高中低三种楼层分布数量大致相同。
d、丰泽区和鲤城区的房价较其他城区相对较高。
e、房屋价格与建筑面积具有较强的正相关关系。
f、3室2厅1厨1卫,4室2厅1厨2卫,1室1厅1厨1卫,2室1厅1厨1卫,2室2厅1厨1卫这四种户型相对其他户型数量较多。
2、对本次程序设计任务完成的情况做一个简单的小结
通过本次程序设计任务,本人首先在编程上学习到了很多知识,提高了自己的代码编写能力,并且对数据分析的认识也有所提高,继续加油。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号