

正则表达式结合实例简单梳理
正则表达式在所有语言中都是通用的,它使用一种特定的规则来匹配一个字符串,当满足这个规则,就认为此字符串匹配成功。结合各个语言中的不同方法,可以返回匹配成功true、false或者匹配的字符串等。
本文对正则表达式做一个简单的知识梳理,结合一些小例子来加深印象。
正则表达式的验证方法现在也多种多样,在这里就不推荐了,大家选择适合自己用得惯的就好。
常用元字符
既然是特定的规则,那么在正则表达式中就有相对应的特殊符号,你不用去记它的名字是什么,只需要知道它做了什么。
. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \s 匹配任意的空白符 \d 匹配数字 \b 匹配单词的开始或结束 ^ 匹配字符串的开始 $ 匹配字符串的结束
这里分辨一下\b与^、$的区别,\b匹配的是单词的开始或结束,也就是说它匹配的是一个“单词”,而^与$是匹配字符串的开始或结束。看下面的例子
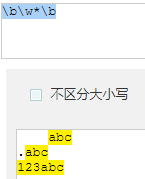
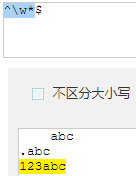
图中,用\b去匹配字符串的时候虽然设定的匹配条件是\w.*匹配任意数量的字母数字汉字或下划线,□□□abc虽然不是以匹配条件开头,但对于\b来说,a才是一个单词的开始。而^与$则是指定了必须要以匹配条件开头,所以□□□abc未能匹配。
另外,对于单词界限通常认为是以空格,符号做分割。
更多例子:
\ba\w*\b匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。
^\d\w*$匹配以1个数字开头,任意字母或数字结尾
常用反义字符
与上述元字符所匹配的规则相反。这里的反义字符一般用于想匹配没有数字,或没有空白字符的情况,也就是限定条件唯一的情况下用比较方便(好吧,可能是我用这方面的功能比较多,其他功能大家可以自行去发掘~)
\W 匹配任意不是字母,数字,下划线,汉字的字符 \S 匹配任意不是空白符的字符 \D 匹配任意非数字的字符 \B 匹配不是单词开头或结束的位置 [^x] 匹配除了x以外的任意字符
需要注意的是,\S匹配的并不是以空格分割的字符串,而是每个字符,也就是说匹配的是单个字符。
更多例子:
\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括号括起来的以a开头的字符串。
常用限定符
个人理解限定符就相当于把原来的元字符从加法转换成了乘法。
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
例如\d\d\d\d\d匹配五个数字现在就可以写成\d{5}。
更多例子:
abc\d+匹配abc后面跟1个或更多数字
^\w+匹配一行的第一个单词
分组
重复单个字符很简单,那重复多个字符就需要用到分组了。分组就是在你需要重复的字符外加一个括号。这就像我们做四则运算时需要先算加法再算乘法的话,需要先把加法式子用括号括起来一样。
捕获
(exp) 匹配exp,并捕获文本到自动命名的组里 (?<name>exp) 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) (?:exp) 匹配exp,不捕获匹配的文本,也不给此分组分配组号
零宽断言 (?=exp) 匹配exp前面的位置 (?<=exp) 匹配exp后面的位置 (?!exp) 匹配后面跟的不是exp的位置 (?<!exp) 匹配前面不是exp的位置
注释 (?#comment) 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读
在正则表达式中,用括号分组之后的匹配文本会被捕获到自动命名的组中,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。利用这个特点,我们可以给分组命名,这样就可以很方便地获得分组中的文本了。
更多例子:
\b(\w+)\b\s+\1\b匹配重复的文本。(括号中的文本被捕获成一个分组,后面\1又匹配了一次第一个分组中的文本)
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
其他小规则
| 分支
懒惰匹配
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。分支的用法就相当于或,匹配 | 分割的任意一个规则。
需要注意的是,分支也有短路现象。
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。但我们有时候需要的是匹配尽可能短的字符,这个时候就需要用到懒惰匹配。
a.*?b匹配最短的,以a开始,以b结束的字符串。当我们输入abbaab时,它会匹配ab和aab。
常用匹配规则
以下整理自网络
匹配合法邮箱:
[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?
匹配网址URL:
[a-zA-z]+://[^\s]*
匹配18位身份证号码:
^(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)$
匹配合法年月日:
([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8])))
参考资料:
http://www.jb51.net/tools/zhengze.html
http://blog.sina.com.cn/s/blog_47664968010093q0.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号