
一、层级架构
常见的两种层级架构:“主-从”、“主-从-从”,如下图:
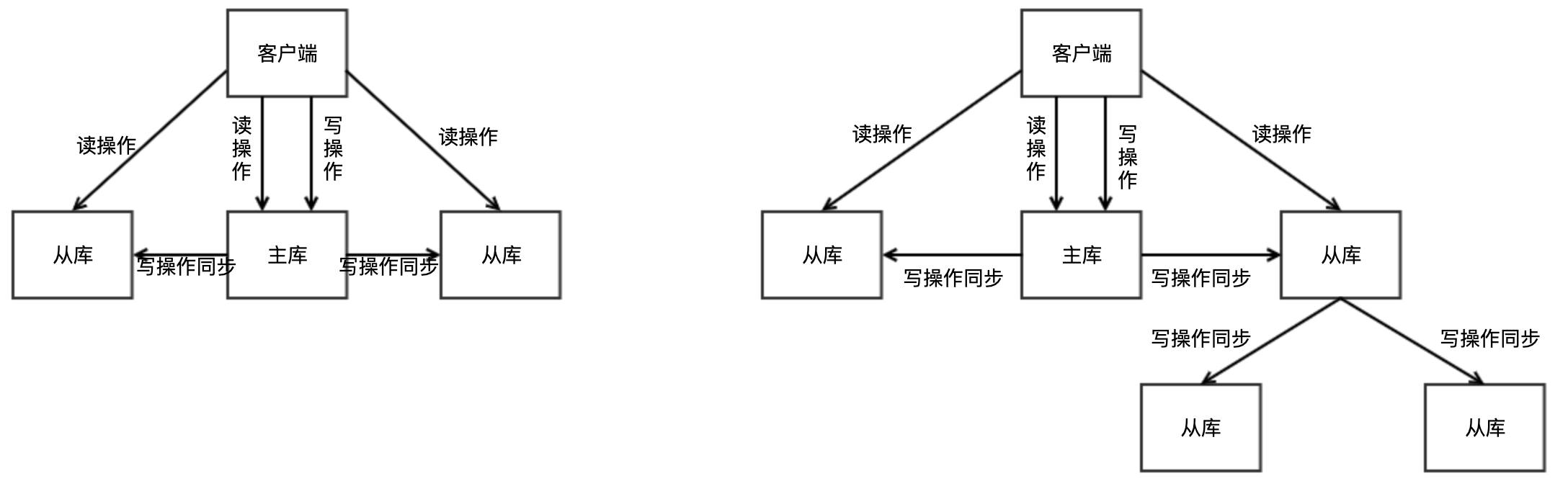
读操作主库、从库都可以执行,写操作先由主库执行然后同步到从库。“主-从-从”这种层级架构的好处在于从库复制主库信息时,不需要直接和主库进行交互,减少主库压力。
通过SLAVEOF命令可以构建起主从库关系。假设现在由两个服务器127.0.0.1:6379和127.0.0.1:12345,如果在port为12345这台机器上执行命令
127.0.0.1:12345 > SLAVEOF 127.0.0.1 6379
OK
那么 127.0.0.1:12345 将成为 127.0.0.1:6379 的从服务器
二、全量复制
全量复制是在主从库第一次建立连接期间进行的。全量复制分为三个阶段

第一阶段 建立连接、协商同步
首先从库与主库建立连接,并告知主库即将同步,主库确认回复后,主从开始同步。详细来讲,从库发送 psync {runID} {offset} 命令到主库,主库收到命令后会响应 FULLRESYNC {runID} {offset} 到从库,确立连接。
·runID:主库runID,每个redis实例启动的时候都会自动生成一个随机的runID,第一次建立连接不知道主库的runID,所以是?
·offset:复制进度,-1 表示第一次复制
·FULLRESYNC:表示全量复制
第二阶段 主库同步数据给从库
在第二阶段,主库首先会将所有数据同步给从库,从库收到数据后,在本地完成加载。详细过程是主库执行bgsave命令,生成RDB文件,将RDB文件发送给从库,从库会先清空当前数据库,然后加载RDB文件。RDB文件是异步生成异步传输因此并不会阻塞Redis主进程,在执行bgsave命令的那一刻起新的写命令都会写入主库内存的缓冲区 replication buffer(每个从库对应一个replication buffer)
第三阶段 主库发送新写命令给从库
将 replication buffer 中的内容发送至从库,至此完成全量复制
三、命令传播
当完成全量复制后,主从库达成数据一致状态,但这种一致状态不是一成不变的。每当主库有新的写命令都会影响主从库之间的状态一致性。为了让主从服务再一次达到一致状态,主服务需要对从服务器执行命令传播操作,将主服务器的写命令传播到从服务器。
四、心跳检测
在命令传播阶段,从服务器会以每秒一次的频率,向主服务器发送命令:REPLCONF ACK <replication_offset>,其中replication_offset是从服务器的复制偏移量。心跳检测主要有三个作用:
1.检测主服务器的网络连接状态
如果超过一秒钟没有收到从服务器发来的REPLCONF ACK命令,那么主服务器就知道主从服务器之间连接出现了问题。通过向主服务器发送INFO replconf命令,可以观测出最后一次向主服务器发送REPLCONF ACK命令过了多少秒。
2.辅助实现min-slaves选项
Redis的 min-slaves-to-write 和 min-slaves-max-lag 两个选项可以防止主服务器在不安全的情况下执行写命令。
3.检测命令丢失
如果因为网络故障,导致主服务器给从服务器传播的命令半路丢失时,那么当从服务器向主服务器发送 REPLCONF ACK 命令时,主服务器将发觉从服务器当前的复制偏移量少于自己的复制偏移量,然后主服务器根据从服务器提交的复制偏移量,在复制积压缓冲区里面找到从服务器缺少的数据,并将这些数据重新发送给从服务器。
五、增量复制
Redis 2.8之前,如果命令传播阶段主从库由于网络原因断开连接,主从库需要重新进行一次全量复制。Redis2.8 之后,网络断开连接后,主从库采用增量复制继续同步。
当主从库断连后,主库会把断连期间收到的写操作命令,写入 replication buffer 和 repl_backlog_buffer(环形缓冲区)。下图是增量复制流程图:
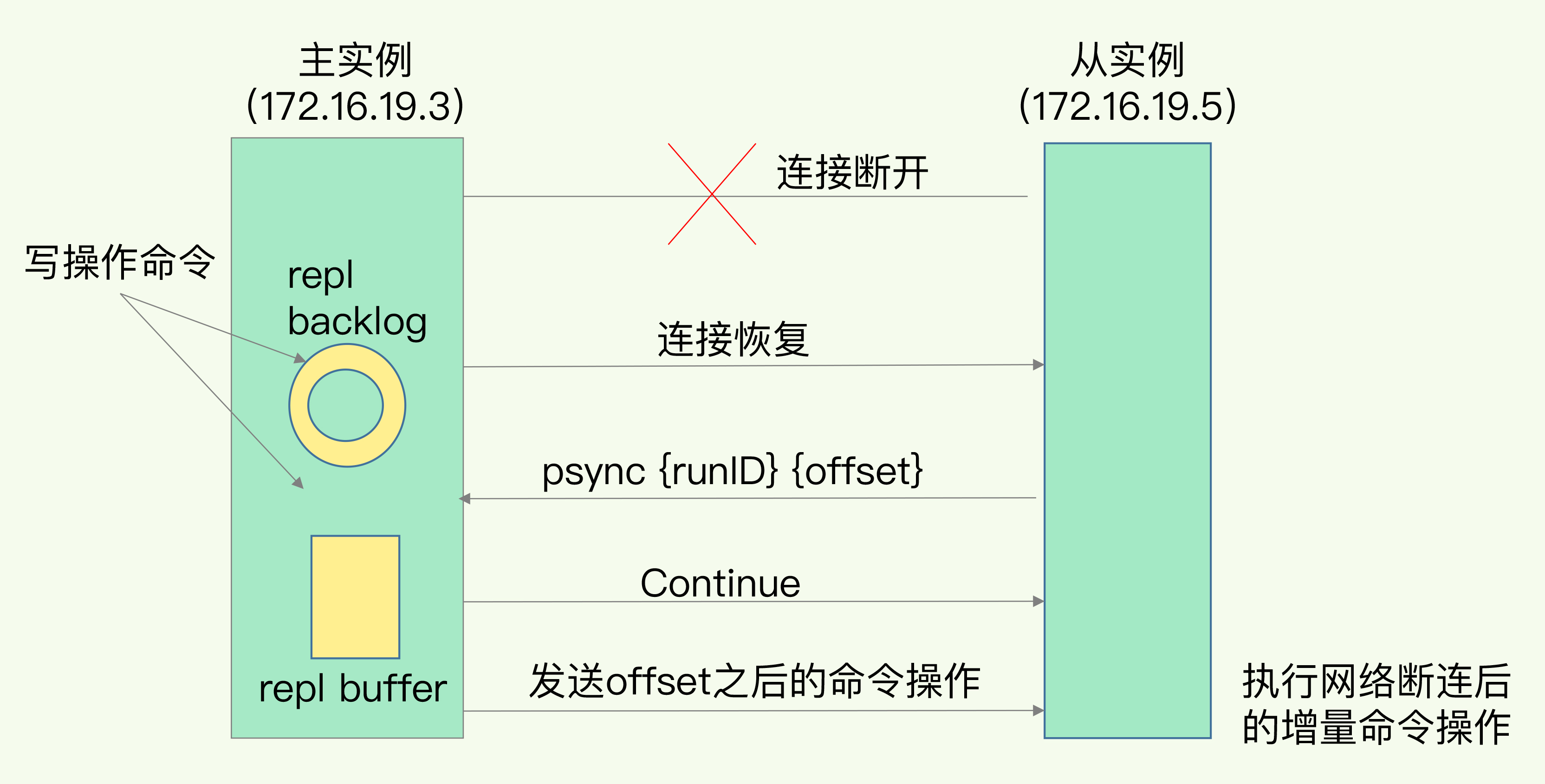
1、repl_backlog_buffe
repl_backlog_buffer是一个环形缓冲区,主库记录自己写到的位置master_repl_offset,从库记录自己读的位置slave_repl_offset。通常master_repl_offset会大于slave_repl_offset,主库只需要把master_repl_offset和slave_repl_offset之间的命令同步给从库就行。(命令同步通过replication buffer缓冲区 类似全量复制)
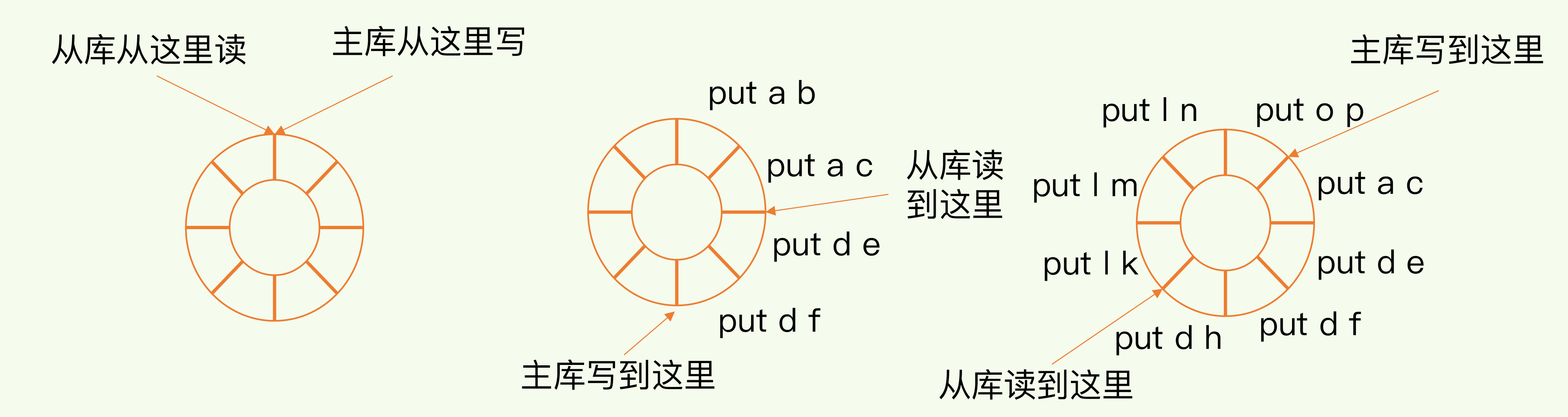
该缓冲区是环形缓冲区,因此当缓冲区写满后,主库继续写入时会覆盖掉之前写入的操作。repl_backlog_buffer是所有从库共享的,当不同从库向主库发起增量同步请求psync时,需要携带slave_repl_offset偏移量,在缓冲区中只要slave_repl_offset没有被覆盖就可以恢复。
为避免全量复制,repl_backlog_buffer缓冲空间要设置大一点。缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小,在实际情况中,通常需要把这个缓冲区扩大一倍。
repl_backlog_buffer和replication buffer区别:
两个缓冲区,两者作用不同repl_backlog_buffer是为增量同步提供保障, replication buffer是数据交互的通道。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号