反序列化之更新,高级用法source(了解),高级用法定制字段,多表关联序列化和反序列化
1 反序列化之更新
序列化视图
class BookDetailView(APIView):
# 查询单条
def get(self, request, pk, *args, **kwargs):
book = Book.objects.all().filter(pk=pk).first()
ser = BookSerializer(book,many=False)
return Response({'code': 100, 'msg': '查询单条成功', 'result': ser.data})
# 修改一条
def put(self, request, pk, *args, **kwargs):
# 要用查出来的对象,使用传入的数据,做修改
book=Book.objects.filter(pk=pk).first()
ser = BookSerializer(instance=book,data=request.data) # 使用前端传入的数据,修改book
if ser.is_valid():
ser.save() # 调用了序列化类的save:内部会触发序列化类中 update方法的执行 不是book.save()
return Response({'code': 100, 'msg': '修改成功'})
else:
return Response({'code': 100, 'msg': ser.errors})
def delete(self, request, pk, *args, **kwargs):
Book.objects.filter(pk=pk).delete()
return Response({'code': 100, 'msg': '删除成功'})
序列化
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.IntegerField()
publish = serializers.CharField()
# 重写create 前端传入,校验过后的数据validated_data
def create(self, validated_data):
book = Book.objects.create(**validated_data) # 前端传入的key值必须跟数据库字段一致的
return book
# 如果是修改,需要重写update方法
def update(self, instance, validated_data):
# instance 就是pk 2
# Book.objects.filter(pk=instance).update(**validated_data)
# instance 待修改的对象 咱们在 view中的那个book
# validated_data 校验过后的数据 本质还是 request.data 经过了数据校验
# 方式一:
# instance.name=validated_data.get('name')
# instance.price=validated_data.get('price')
# instance.publish=validated_data.get('publish')
# instance.save()
# 方式二: 反射是通过字符串动态的获取或设置属性或方法
# get=getattr(self,'get')
# get()
# setattr(instance,'name','西游记') ---》 instance.name='西游记'
for k in validated_data: # {"name":"西游记","price":99,"publish":南京出版社}
setattr(instance, k, validated_data.get(k))
# instance.publish=validated_data.get('publish')
instance.save()
return instance
2 高级用法source(了解)
字段类的属性
如下写法,就能修改序列化的字段
class BookSerializer(serializers.Serializer)😃
- 用法一:
最简单,拿表中的字段:
xxx = serializers.CharField(source='name')

- 用法二 :跨表查询
自动对应成出版社的名字 可以通过 . 跨表查询
publish = serializers.CharField(source='publish.name')
- 用法三:
表模型中写方法,拿到方法的返回值
yyy = serializers.CharField(source='get_name')
models.py中
@property
def get_name(self):
return self.name+'sb'

3 高级用法定制字段
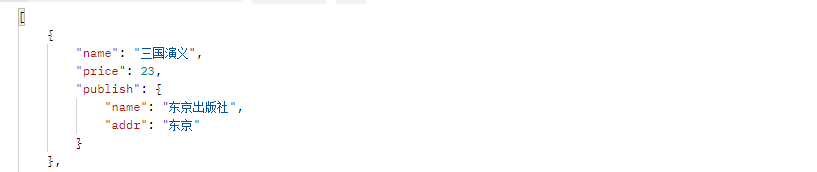
定制返回的字段格式,publish也是一个对象
{
"name": "信息",
"price": 12,
"publish": {name:xx,addr:xx}
}
三种方案,目前只讲两种
- 方案一:
使用SerializerMethodField 定制
在序列化类中使用SerializerMethodField
publish_detail = serializers.SerializerMethodField()
def get_publish_detail(self, obj): # 返回什么,序列化后publish就是什么
# obj 就是序列化到的book对象
return {'name':obj.publish.name,'addr':obj.publish.addr}
- 方案二:
在表模型中定制
-
1 表模型中写方法,包装成数据属性
@property def publish_dict(self): return {'name': self.publish.name} -
2 序列化类中
publish_dict=serializers.DictField()

4 多表关联序列化和反序列化
以后一个序列化类,想即做序列化,又做反序列化,会出现问题:字段不匹配,尤其是多表关联的字段
以后,有的字段 即做序列化,又做反序列化
name = serializers.CharField()
price = serializers.IntegerField()
有的字段:只做序列化(read_only表示 只做序列化)
# 只读访问
publish_dict = serializers.DictField(read_only=True) # 只做序列化
author_list = serializers.ListField(read_only=True) # 只做序列化
有的字段只做反序列化(write_only=True)-->是什么类型,取决于前端传入的格式什么样
# 只写访问
publish_id = serializers.IntegerField(write_only=True) # 反序列化
authors = serializers.ListField(write_only=True) # 反序列化
保存方法需要自己重写
def create(self, validated_data):
# {"name":"111水浒传111","price":999,"publish":1,"authors":[1,2]}
authors=validated_data.pop('authors')
book = Book.objects.create(**validated_data)
# 增加中间表的记录:图书和作者的关系
book.authors.add(*authors) # 向中间表中存入:这个图书关联的做作者
return book
笨办法:
序列化用一个序列化类
反序列化换另一个序列化类
5 反序列化校验总结
什么情况用反序列化校验?
做反序列化的时候,才用----》校验前端传入的数据
三层:
- 字段自己:字段类属性---》可控制的比较小
- 局部钩子:单个字段校验
- 全局钩子:多个字段同时校验
拓展:
# 新增传这种数据过来,新增图书,新增一个作者,新增一个出版社
{"name":"新西游记111","price":199,"publish_id":{name:西安出版社,addr:西安},"authors":[{"name": "lqz","sex": "男","age": 19}]}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号