推导分页的原理
分页:当我们要展示的数据特别多的时候,一页展示不完,这个时候我们需要把要展示的数据分成多页展示
分页中需要的几个参数:
1. 总数据有多少条
2. 每页展示多少条数据(自己规定的20)
3. 一共展示多少页
4. 总页数 = 总数据量 / 每页展示多少条数据
5. 当前第几页(前端传过去的)
总页数怎么算?
"""
总条数 每页展示的数据 页数
100 10 10
101 10 11
99 10 10
...
divmod(100, 10)
start_page = (current_page - 1)* per_page_num
end_page = current_page* per_page_num
"""
自定义分页器封装代码
以后我们针对像分页类这种第三方工具,我们一般在Django中创建一个utils文件夹保存,
在这个文件下建一个py文件(可随意命名,但要见名知意):列如----mypage.py
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=2, pager_count=11):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)
else:
temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
分页类的使用
后端:
'''导入模块'''
from utils.mypage import Pagination
def get_book(request):
book_list = models.Book.objects.all()
current_page = request.GET.get("page",1)
all_count = book_list.count()
page_obj = Pagination(current_page=current_page,all_count=all_count,per_page_num=10)
page_queryset = book_list[page_obj.start:page_obj.end]
page_html = page_obj.page_html()
return render(request,'booklist.html',locals())
前端
<div class="container">
<div class="row">
<div class="col-md-8 col-md-offset-2">
{% for book in page_queryset %}
<p>{{ book.title }}</p>
{% endfor %}
{{ page_obj.page_html|safe }}
</div>
</div>
</div>
扩展:
'''
显示左5,右5,总共11个页,
1 如果总页码大于11
1.1 if 当前页码减5小于1,要生成1到12的列表(顾头不顾尾,共11个页码)
page_range=range(1,12)
1.2 elif 当前页码+5大于总页码,生成当前页码减10,到当前页码加1的列表(顾头不顾尾,共11个页码)
page_range=range(paginator.num_pages-10,paginator.num_pages+1)
1.3 else 生成当前页码-5,到当前页码+6的列表
page_range=range(current_page_num-5,current_page_num+6)
2 其它情况,生成的列表就是pageinator的page_range
page_range=paginator.page_range
'''
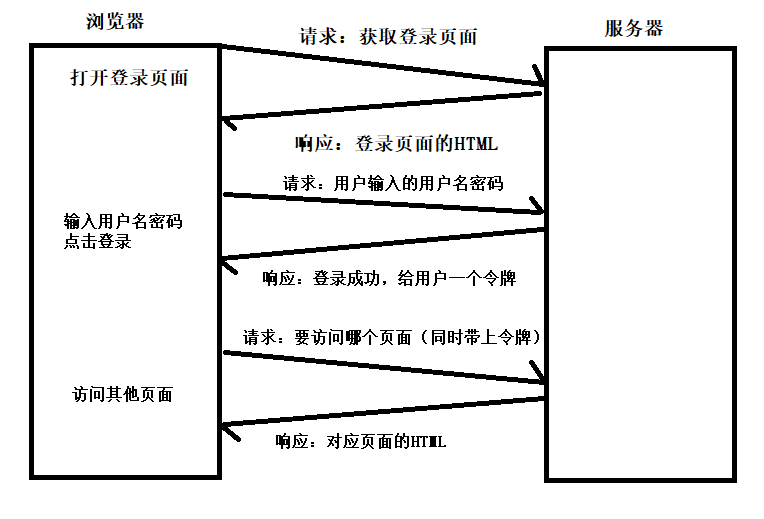
cookie和session的介绍(重要)
HTTP协议的特性之一:无状态
背景信息:
1. 早期的时候一些网站都是静态网站,不需要登录,比如:新闻类、博客等
2. 随着技术的发展以及用户的要求,诞生了诸如支付宝、淘宝、京东等电商网站,这些网站就必须要求用户登录,
如果不登录,上家怎么知道是谁买的东西? 登录的目的其实就是上架可以识别这个用户是谁
3. 诞生了保存用户状态的技术:cookie和session
"""
以登录功能为例:
分析cookie 的原理
你进入到一个淘宝网站,第一次肯定需要登录的,如果登录成功,淘宝网站不保存你的用户信息,
意味着你下次再访问淘宝的时候,就需要从新登录,每一次访问淘宝的页面都需要登录,如果真的是这样,你想用吗?
如何解决上述问题?
这个时候就利用到了cookie,比如你第一次登录成功之后,django后端让浏览器把你的用户名和密码保存在浏览器中,
你下次再访问淘宝页面的时候,浏览器会自动把它之前保存的用户名和密码一块提交到Django后端,
Django后端每次拿到浏览器发过来的用户名和密码再次做验证.
上述的做法有没有什么问题? 有
数据保存在浏览器上面,很明显的问题是:数据不够安全
如何解决上述数据不安全的问题
其实是做了优化:把原本存在浏览器上的数据存到后端,就称之为是session
session就解决了cookie数据不安全的问题
session的原理:
以登录功能为例:
第一次登录成功之后,把用户信息保存在后端,其中,django默认是把用户信息保存在数据表中了 django_session表中了
1. 先生成一个随机字符串
2. 把用户的信息保存在django_session表中
session_key session_data expire_date
随机字符串1 用户信息1
随机字符串2 用户信息2
随机字符串3 用户信息3
随机字符串4 用户信息4
随机字符串5 用户信息5
3. Django后端会把随机字符串告诉浏览器保存起来
4. 以后用户每次访问页面的时候,浏览器每次都要把随机字符串提交过来,Django后端拿到随机字符串,
去django_session表中查询数据,如果查到了,就说明以前登录成功了,如果查不到,就说明还没有登录
select * from django_session where session_key = ''
"""
# 如果都把用户信息保存在django_session表中,有没有其他问题?
最大的问题就是数据量一旦很大,查询就是致命的
# 怎么解决这个问题
需要用到token
token就是一个随机字符串------->保存着用户信息---------->字符串返回给前端------>每次都把token提交过来------>后端做验证.
加密和解密都是后端做的,前端只需要每次把这个串来回传递就行了
# jwt------------>三段式--------->
跟面试相关的:
1. 保存在浏览器上的数据都称之为是cookie
2. session是保存在服务端的
3. session的数据相对更加安全,cookie不够安全
4. session是基于cookie工作的? 对还是不对? 对
5. django让浏览器保存cookie,用户有权可以设置浏览器不保存
6. session离开cookie一定就不能工作了,对还是不对?
务必掌握!!!
Django操作cookie
# 在Django这种如何使用cookie、
三板斧:
return HttpResponse
return render
return redirect
obj = HttpResponse
return obj
obj = render
return obj
obj = redirect
return obj
# 操作cookie的时候,就用到了这个obj对象
设置cokokie:
rep = HttpResponse(...)
rep = render(request, ...)
rep.set_cookie(key,value)
rep.set_signed_cookie(key,value,salt='加密盐')
获取cookie
request.COOKIES['key']
request.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None)
参数:
key,键
value=’,,值
man_age=None,超时时间 cookie需要延续的时间 (以秒为单位) 如果参数是 None,
这个cookie会延max_age=None.续到浏览器关闭为止
expires=None,超时时间(IE requires expires,so set it if hasn't been already.)path=’/,cookie生效的路径,/ 表示根路径
# 案例:基于cookie的登录功能
#登录的原理
第一次输入用户名和密码,后端做验证,验证成功之后,把用户的信息保存起来,保存在cookie中
下次再访问页面的时候,浏览器会自动把cookie信息提交到后端,后在做验证判断用户是否登录;
判断cookie值是否存在,存在就登录,不存在就没有登录
以上相关图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号