正则表达式的介绍
定义:
"""
它是一门独立的语言,跟Python等的语言没有任何的关系,但是其他语言可以使用正则表达式来做一些功能,
主要是用来筛选数据的 。
"""
什么是正则表达式:
利用一些特殊的符号匹配除想要的数据就是正则表达式,简称'正则'
在线测试工具: http://tool.chinaz.com/regex/
列子:
^(13|14|15|18)[0-9]{9}$
形如上述代码的就是正则表达式
字符组
定义:
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
解析:
[0123456789] # 匹配0-9之间的数字
[0-9] # 匹配0-9之间的数字
\d # 匹配0-9之间的数字
[a-z] # 匹配a-z之间的字符
[A-Z] # 匹配A-Z之间的字符
列子:
#1. 匹配0-9a-zA-Z如何写
[0123456789ABCDEFGHIJ...abcdefghij...]
[0-9A-Za-z]
字符
. 匹配除换行符以外的任意字符 # 掌握
\w 匹配字母或数字或下划线 # 掌握
\s 匹配任意的空白符
\d 匹配数字 # 掌握
\n 匹配一个换行符 # 掌握
\t 匹配一个制表符
\b 匹配一个单词的结尾
^ 匹配字符串的开始 # 掌握
$ 匹配字符串的结尾 # 掌握
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b # 掌握
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符 # 掌握
[^...] 匹配除了字符组中字符的所有字符 # 掌握
量词
1. 量词只能影响前面的一个字符
2. 量词不能单独使用,必须配合其他字符串使用
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配和非贪婪匹配
# 待匹配的字符
<script>123</script>
# 正则表达式是:
<.*>
# 匹配结果是:
<script>
<script>123</script>
# 默认匹配的是贪婪匹配:尽可能的多匹配
'''把贪婪匹配转为非贪婪匹配'''
<.*?> # 非贪婪匹配尽可能的少匹配
.*?组合的用法
小练习
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
# 由于正则表达式的复杂性,所以,以后遇到常见的匹配规则,我们可以去百度搜
1. 写一个匹配常见的手机号的正则
^((13[0-9])|(14[5,7])|(15[0-3,5-9])|(17[0,3,5-8])|(18[0-9])|166|198|199|(147))\d{8}$
转义字符
'\\\\\\\\n'
\\\\\\\\\\\\\\\\n
'\t'
\\t
'''一个斜杠只能转义一个字符'''
# 在python中转义字符推荐使用:r'\n' '\\n' =====》
re模块
定义:
1. re是内置的模块,可以直接使用
2. 在python中,要想使用正则需要借助于re模块
re: regular express
列子:
import re
# re.findall('这是正则表达式', '待匹配的文件')
# res=re.findall('b', 'eva jason kavin')
# print(res) # ['a', 'a', 'a']
# 如果匹配不到字符,就返回空列表[]
# res=re.search('b', 'eva jason kavin')
# print(res)
# print(res.group())
"""如果匹配不到,就返回None"""
# if res:
# print(res.group())
# else:
# print('没有匹配到')
方式二:
# try:
# print(res.group())
# except Exception:
# print('没有找到')
res=re.match('a', 'aeva jason kavin') # 从开头开始匹配
print(res)
print(res.group())
分组
定义:
分组就是用一对园括号“()”括起来的正则表达式,匹配出的内容的就表示一个分组。
从正则表达式的左边开始看,看到的第一个左括号“(”表示第一个分组,第二个表示第二个分组,依次类推,需要注意的是,有一个隐含的全局分组(就是0),就是整个正则表达式。
分组完组之后,想要获取某个分组的内容,直接使用group(num)函数去提取就OK了。
分组相关:

无名分组:

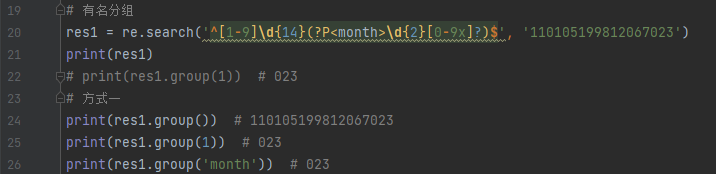
有名分组:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号