MySQL索引介绍及使用
索引概念
索引是 MySQL 中用于加速数据查询的核心数据结构,本质是对表中一列或多列数据进行排序后的 “快速查找目录”。通过索引,MySQL 无需全表扫描即可快速定位目标数据,大幅提升查询效率;但索引会占用额外存储空间,且会降低插入 / 更新 / 删除(写操作)的性能(需同步维护索引结构),因此需合理设计与使用。
索引的核心作用
核心价值:加速查询
-
无索引时:MySQL 需执行「全表扫描」(逐行遍历表中所有数据),数据量越大,查询越慢;
-
有索引时:通过索引结构(如 B+Tree)快速定位数据所在的物理位置,查询时间与数据量规模解耦(类似查字典时先查目录,而非逐页翻找)。
辅助作用
-
保证数据唯一性:如主键索引(PRIMARY KEY)、唯一索引(UNIQUE)可强制列值不重复;
-
优化排序 / 分组:若查询的 ORDER BY/GROUP BY 子句与索引列一致,MySQL 可直接利用索引的有序性避免额外排序(即 “Using index for 排序” 优化)。
索引的底层数据结构
MySQL 绝大多数索引(主键、唯一、普通、联合索引)均基于 B+Tree 实现(InnoDB 引擎默认使用聚簇 B+Tree,MyISAM 用非聚簇 B+Tree),其结构设计专为数据库优化:
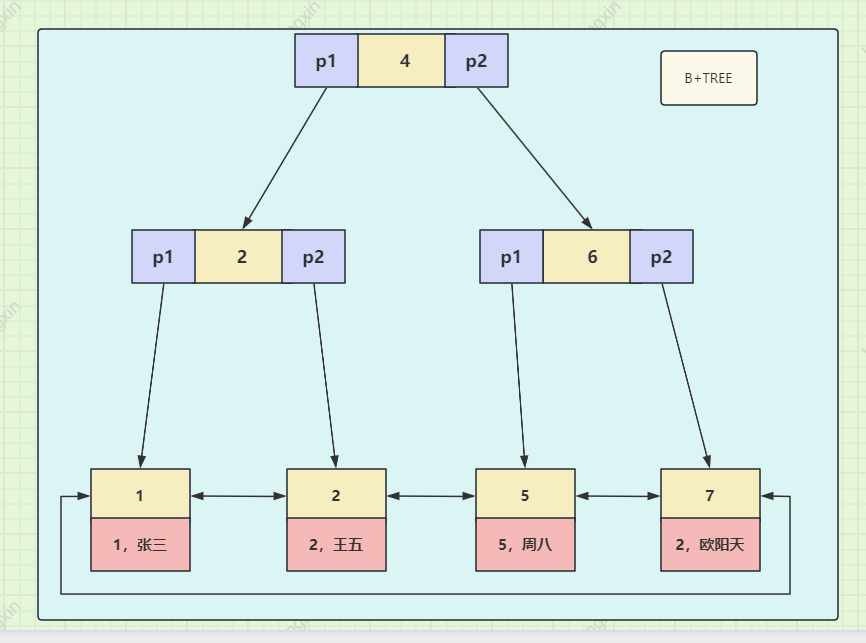
-
B+TREE索引是自平衡二叉树的升级版,B+TREE索引将数据存储在叶子节点,并且叶子节点之间采用双向链表互相连接,这样很适合范围查询,且叶子节点是排好序的。所以我们MySQL数据库是默认根据主键索引升序排序的
-
B+TREE的非叶子节点只有索引值和指针,没有数据,所以非叶子节点可以存储更多的索引值,这样可以使B+TREE更矮更胖,减少检索的深度(也就是减少磁盘IO),提高检索效率。
聚簇索引 vs 非聚簇索引(InnoDB 核心区别):
- 聚簇索引(主键索引):叶子节点直接存储整行数据,InnoDB 表必须有聚簇索引(默认主键,无主键则选唯一非空列,否则自动生成隐藏主键);
- 非聚簇索引(二级索引,如普通索引、唯一索引):叶子节点存储主键值,查询时需先通过二级索引找到主键,再回表查聚簇索引获取整行数据(即 “回表查询”)。
MySQL索引分类
主键索引(PRIMARY KEY)
作用:用来组织存储表的数据行信息的,也可以理解为数据行信息都是按照聚簇索引结构进行存储的,即按区分配空间的;
特点:索引列数据唯一且非空,一张表只能有一个主键索引;
创建方式
- 方式一:创建数据表时,显示的创建主键索引
CREATE TABLE user (
id INT PRIMARY KEY, -- 主键索引
name VARCHAR(20)
);
- 方式二:创建完表之后添加索引
alter table 表名 ADD PRIMARY KEY (id);
- 方式三:没有显示的构建主键索引时,会将第一个不为空的unique约束作为主键索引
- 方式四:以上条件都不符合时,会生成一个6字节的隐藏列作为主键索引
唯一索引(UNIQUE)
作用:保证数据唯一性(如手机号、邮箱),同时加速查询;
特性:索引列的值必须唯一,但允许有空值
创建方式
- 方式一:创建表时指定
CREATE TABLE user (
id INT PRIMARY KEY,
phone VARCHAR(11) UNIQUE -- 唯一索引
);
- 方式二:创建完表之后指定
ALTER TABLE 表名 ADD UNIQUE 索引名称 on (name) ;
普通索引(INDEX)
作用:纯粹加速查询,是最常用的索引类型;
特性:无唯一性约束,允许重复值和 NULL;
创建方式
- 方式一:创建表时指定
create table 表名 (id int,name char(10),index 索引名称(name));
create table 表名 (id int,name char(10),index 索引名称(name(5))); -- 设置前缀
create table 表名 (id int,name char(10),age char(5),index xiaoA(name desc)); -- 设置索引排序方式,默认升序
- 方式二:创建完表后指定
alter table 表名 add index 索引名称(name);
alter table 表名 add index 索引名称(name(length)); -- 设置前缀
alter table 表名 add index 索引名称(name desc) ; -- 调整排序方式
联合索引
核心特性:基于多列组合创建的索引(如 (col1, col2, col3));
作用:优化多列联合查询(如 WHERE a=? AND b=?),比单列索引更高效;
联合索引命中规则
最左前缀匹配原则—— 查询时必须从索引的第一列开始匹配,否则无法命中索引!!!
例如联合索引 (a, b, c):
命中索引:WHERE a=1、WHERE a=1 AND b=2、WHERE a=1 AND b=2 AND c=3;
未命中索引:WHERE b=2、WHERE a=1 AND c=3(跳过 b 列);
创建方式
- 方式一:创建表时指定
create table 表名 (id int,name char(10),age char(5),index 索引名称(name,age));
- 方式二:创建完表后指定
alter table 表名 add index 索引名称(name,age);
索引的优缺点
优点
-
提高查询性能:通过创建索引,可以大大减少数据库查询的数据量,从而提高查询的速度
-
加速排序,当查询需要按照某个字段进行排序时,索引可以加速排序的过程,提高排序的效率
-
减少磁盘的IO,索引可以减少磁盘IO的次数,这对于磁盘读写速度较低的场景,尤其重要
缺点
-
占据额外的存储空间,索引需要占据额外的存储空间,特别是在大型数据库系统中,索引可能占据较大的空间
-
增删改的操作会导致索引更新,会导致操作的性能降低
-
资源消耗较大,索引需要占用额外的内存和cpu资源,特别是在大规模并发访问的情况下,可能对系统的性能产生影响
什么时候建议使用索引?
- 频繁执行查询操作的字段:如果这些字段经常被查询,使用索引可以提高查询的性能,减少查询的时间。
- 大表:当表的数据量较大时,使用索引可以快速定位到所需的数据,提高查询效率。
- 需要排序或者分组的字段:在对字段进行排序或者分组操作时,索引可以减少排序或者分组的时间。
- 外键关联的字段:在进行表之间的关联查询时,使用索引可以加快关联查询的速度。
什么时候不建议使用索引
- 频繁执行更新操作的表:如果表经常被更新数据,使用索引可能会降低更新操作的性能,因为每次更新都需要维护索引。
- 小表:对于数据量较小的表,使用索引可能并不会带来明显的性能提升,反而会占用额外的存储空间。
- 对于唯一性很差的字段,一般不建议添加索引。当一个字段的唯一性很差时,查询操作基本上需要扫描整个表的大部分数据。如果为这样的字段创建索引,索引的大小可能会比数据本身还大,导致索引的存储空间占用过高,同时也会导致查询操作的性能下降。
本文来自博客园,作者:huangSir-devops,转载请注明原文链接:https://www.cnblogs.com/huangSir-devops/p/19297863,微信Vac6666666,欢迎交流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号