|
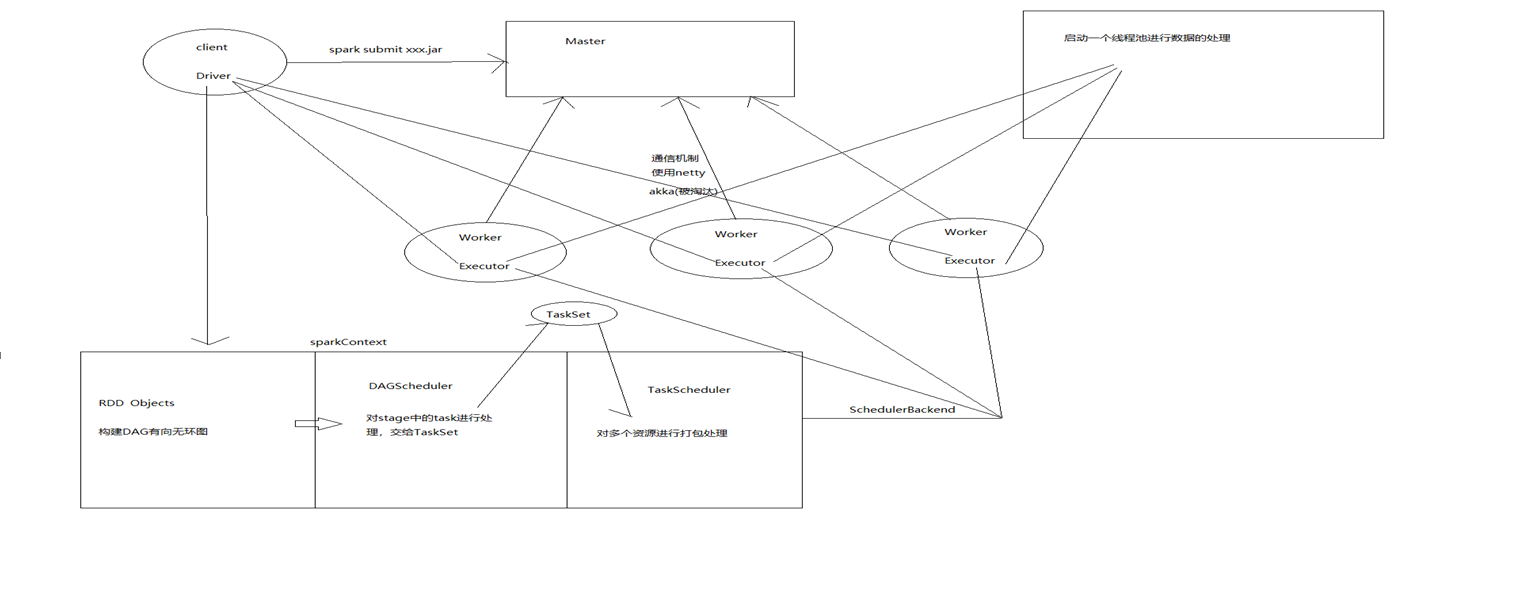
Spark流程总结:
1、构建spark application的运行环境,启动sparkContext(上下文)
2、sparkcontext向资源管理器注册并申请运行executor资源
3、资源管理器master分配executor资源并启动StandaloneExecutorBackend
4、executor的运行情况随心跳机制发送到master上
5、master返回资源到client,初始化dirver上的组件
6、RDD Object:根据sparkContext,遇到action算子构建DAG有向无环图,
把图提交到DAGScheduler
7、DAGScheduler:根据shuffle切分stage,根据stage找到task任务,将tasks加载到taskSet中,把结果提交到TeskScheduler
8、TeskScheduler:将任务提交到集群中,可以进行任务的资源调配和管理
9、exector:负责运行任务,保存数据和管理数据(blocks)
10、TeskRunnerexector是一个Thread Pool线程池,将task任务进行封装为TeskRunner,
放入线程池,调用Run方法进行执行
11、运行完毕释放资源
![]()
master:管理集合和节点,不参与计算
worker:计算节点,进程本身不参与计算,负责与 master 交流
client:客户端,用户提交程序的入口
driver:程序运行 main 方法,创建 SparkContext 对象
Sparkcontext:控制 App 程序的生命周期,包括 DAGScheduler 和 TaskScheduler 等组件
executor:负责执行方法、算子(是一个线程池)
blockManager:管理 spark 中的数据的位置
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号