nodejs 快要变成爬虫界的王者
nodejs 快要变成爬虫界的王者
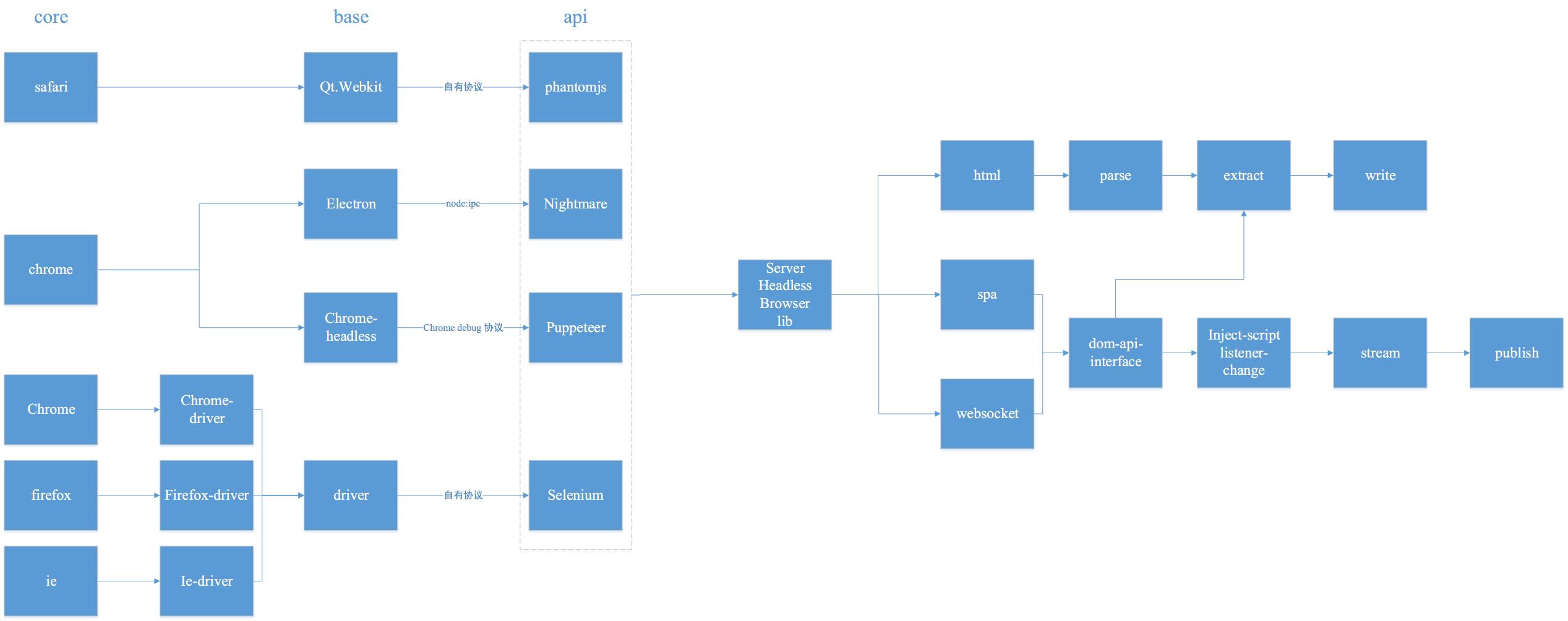
爬虫这东西是很多数据采集必须要的东西。 但是现在随着网页不断发展,已经出现了出单纯的网页,到 ajax 网页, 再到 spa , 再到 websocket 应用,一直在变化,爬虫不变化怎么能行呢。爬虫从只爬网页,到ajax,一直工作的很好。而对于现在的 spa和websocket 网页传统的爬虫基本上没有很好的办法进行处理,怎么办。
最新的技术手段进行分析如下:
-
数据直接从浏览器端拿到,通过 server browser 和 注入脚本。直接在浏览器端执行脚本,这样就可以 spa 和 websocket 都可以。
-
Json 处理:JsonPath, alasql
-
html 处理:xpath, cheerio
-
直接在浏览器端注入脚本,socket.io 和 监听 dom 的变化,把变化的流发表出去到服务器 (wechaty ) 就是这么做的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号