

mysql窗口函数
窗口函数
窗口函数的引入是为了解决想要显示聚集前的数据,又要显示聚集后的数据;窗口数对一组值进行操作,不需要使用group by子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
基本语法:
函数名(列) over(选项) 选项为partition by 列 order by 列
解释:
over(partition by XXX) 将所有行按XXX进行分组
over(partition by XXX order by aaa) 按XXX分组,按aaa排序
注意:
聚合函数类似数据透视表,原有表结构已发生变化,
窗口函数不会改变原表结构,
聚合窗口函数
需求:计算每个学生的及格科目数
--使用聚合函数
select student_id,count(sid) from score where num>=60 group by student_id;
--使用窗口函数
select student_id,count(sid) over(partition by student_id order by student_id) from score where num>=60;
排序窗口函数
1、row_number()
---仅仅根据行号进行排序,相同结果则排序按照顺序依次排
2、rank()
---排名,与row_number()不同的是,rank函数考虑到了over子句中排序字段值相同的情况,over子句中排序字段值相同的排序结果是一样的,例如:11335
3、dense_rank()
---密集排名,与rank类似,唯一不同的是当排序结果相同时,它的排序不跳跃,而是紧跟排下一个。例如:11223
4、ntile(n)
---桶排名,常用于提取前百分之多少的应用场景。
首先,ntile会先根据分组依据,然后把每个组的总记录数按照n进行均分,这个数字就是桶数;
例如,一个组内共12条记录,若n=6,则等划分为6桶,然后按照num的排序等级划分,12/6=2,也就是112233445566。
//计算每门课程前三,考虑排名相同的情况
select * from (SELECT s.sid, s1.sname, s1.gender, c.cname, s.num, dense_rank () over ( PARTITION BY c.cname ORDER BY num DESC ) AS dense_rank FROM score s JOIN student s1 ON s.student_id = s1.sid LEFT JOIN course c ON s.course_id = c.cid) as a where dense_rank<=3;
位置移动窗口函数
1、lag(col,n):用于统计窗口内往上第n行值
2、lead(col,n):用于统计窗口内往下第n行值
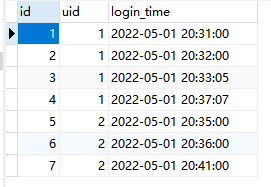
---计算作弊次数,如果相邻登陆时间小于两分钟即认为作弊:
首先:将相邻两次登录时间使用两个字段存储
select uid,login_time,lead(login_time,1) over(partition by uid order by login_time) lead_time from lag_table;
第二步:
其他窗口函数
1、first_value()
//查询每个课程的第一名成绩 SELECT s.sid, s1.sname, s1.gender, c.cname, s.num, first_value (num) over ( PARTITION BY c.cname ORDER BY num DESC ) AS first_value用法 FROM score s JOIN student s1 ON s.student_id = s1.sid LEFT JOIN course c ON s.course_id = c.cid;
2、last_value()
//取每门课程的最后一名成绩,这样写为什么不对呢 SELECT s.sid, s1.sname, s1.gender, c.cname, s.num, last_value (num) over ( PARTITION BY c.cname ORDER BY num DESC ) AS last_value用法 FROM score s JOIN student s1 ON s.student_id = s1.sid LEFT JOIN course c ON s.course_id = c.cid;
窗口函数默认统计范围是rows between unbounded preceding and current now,也就是取当前行数据与当前行之前的数据的比较。
在order by 条件后面加上语句:rows between unbounded preceding and unbounded following
可以理解为:当前分组数据中的所有数据进行比较,取最后一条记录
修改后sql:
SELECT s.sid, s1.sname, s1.gender, c.cname, s.num, last_value (num) over ( PARTITION BY c.cname ORDER BY num DESC rows BETWEEN unbounded preceding AND unbounded following ) AS last_value用法 FROM score s JOIN student s1 ON s.student_id = s1.sid LEFT JOIN course c ON s.course_id = c.cid;
详细介绍
rows between XXX and XXX
unbounded 无限制的
preceding 分区的当前记录的向前偏移量
current 当前的
following 分区的当前记录的向后偏移量
//比如,需要查询每个月份的累计销售额 CREATE TABLE sale ( id INT PRIMARY KEY auto_increment, YEAR INT, MONTH INT, money FLOAT (10, 2) ); INSERT INTO sale (YEAR, MONTH, money) VALUES (2020, 1, 5840), (2020, 2, 5780), (2020, 3, 4300), (2020, 4, 4760), (2020, 5, 3630), (2020, 6, 4130), (2020, 7, 4350); select * from sale; SELECT MONTH, sum(money) over(ORDER BY MONTH rows BETWEEN unbounded preceding AND current ROW //不写默认就是这个 ) AS 累计销售额 FROM sale;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号