Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎。
概要
之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码的实时交互式执行,这是为什么呢?
既然scala已经提供了repl,为什么spark还要自己单独搞一套spark repl,这其中的缘由到底何在?
显然,这些都是问题,要解开这些谜团,只有再次开启一段源码分析之旅了。
全局视图
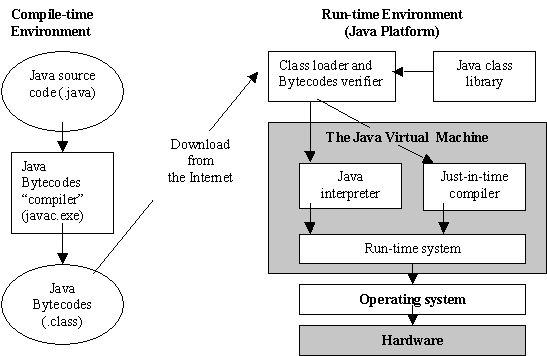
上图显示了java源文件从编译到加载执行的全局视图,整个过程中最主要的步骤是
- 编译成过程,由编译器对java源文件进行编译整理,生成java bytecodes
- 类的加载和初始化,主要由classloader参与
- 执行引擎 将字节码翻译成机器码,然后调度执行
这一部分的内容,解释的非常详细的某过于《深入理解jvm》和撒迦的JVM分享,这里就不班门弄斧了。
那么讲上述这些内容的目的又何在呢,我们知道scala也是需要编译执行的,那么编译的结果是什么样呢,要符合什么标准?在哪里执行。
答案比较明显,scala源文件也需要编译成java bytecodes,和java的编译结果必须符合同一份标准,生成的bytecode都是由jvm的执行引擎转换成为机器码之后调度执行。
也就是说尽管scala和java源文件的编译器不同,但它们生成的结果必须符合同一标准,否则jvm无法正确理解,执行也就无从谈起。至于scala的编译器是如何实现的,文中后续章节会涉及。
ELF可执行文件的加载和运行
”CPU是很傻的,加电后,它就会一直不断的读取指令,执行指令,不能停的哦。“ 如果有了这个意识,看源码的时候你就会有无穷的疑惑,无数想不通的地方,这也能让你不断的进步。
再继续讲scala源文件的编译细节之前,我们还是来温习一下基础的内容,即一个EFL可执行文件是如何加载到内存真正运行起来的。(本篇博客的内容相对比较底层,很费脑子的,:)
Linux平台上基本采用ELF作为可执行文件的格式,java可执行文件本身也是ELF格式的,使用file指令来作检验。
file /opt/java/bin/java
下面是输出的结果,从结果中可以证实java也是ELF格式。
/opt/java/bin/java: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.9, BuildID[sha1]=bd74b7294ebbdd93e9ef3b729e5aab228a3f681b, stripped
ELF文件的执行过程大致如下
- fork创建一个进程
- 调用execve来执行ELF
- ELF的加载过程中会有动态加载和链接发生
- 全局变量的初始化,这一部分和glibc相关
- 执行main函数
第一步:每一种二进制格式,必须先注册自己的处理句柄。
在文件$KERNEL_HOME/fs/binfmt_elf.c中,init_elf_binfmt函数就实现了注册任务
static int __init init_elf_binfmt(void)
{
register_binfmt(&elf_format);
return 0;
}
来看一看elf_format的定义是什么
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
第二步:搜索处理句柄,fs/exec.c
execve是一个系统调用,内核中对应的函数是do_execve,具体代码不再列出。
do_execve->do_execve_common->search_binary_hander
注意search_binary_handler会找到上一步中注册的binary_handler即elf_format,找到了对应的handler之后,关键的一步就是load_binary了。动态链接过程调用的是load_shlib,这一部分的内容细细展开的话,够写几本书了。
search_binary_handler的部分代码
retry:
read_lock(&binfmt_lock);
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
retval = fmt->load_binary(bprm);
bprm->recursion_depth--;
if (retval >= 0 || retval != -ENOEXEC ||
bprm->mm == NULL || bprm->file == NULL) {
put_binfmt(fmt);
return retval;
}
read_lock(&binfmt_lock);
put_binfmt(fmt);
}
read_unlock(&binfmt_lock);
要想对这一部分内容有个比较清楚的了解,建议看一下台湾黄敬群先生的《深入浅出Helloworld》和国内出版的《程序员的自我修养》。
源码走读其实只是个形式,重要的是能理清楚其执行流程,以到达指令级的理解为最佳。
Java类的加载和执行
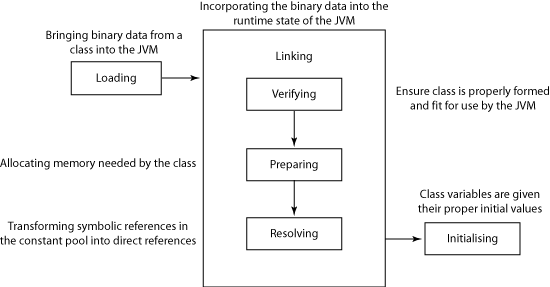
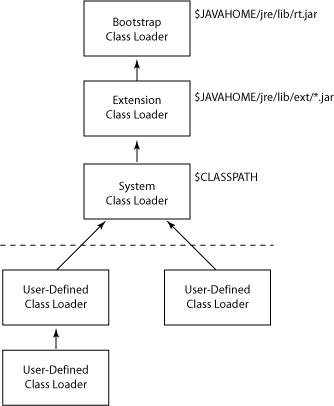
在各位java达人面前,我就不显示自己java水平有多烂了。只是将两幅最基本的图搬出来,展示一下java类的加载过程,以及classloader的层次关系。记住这些东东会为我们在后头讨论scala repl奠定良好基础。
序列化和反序列化
Java体系中,另一个重要的基石就是类的序列化和反序列化。这里要注意的就是当有继承体系时,类的序列化和反序列化顺序,以及类中有静态成员变量的时候,如何处理序列化。诸如此类的文章,一搜一大把,我再多加解释实在是画蛇添足,列出来只是说明其重要性罢了。
spark-shell的执行路径
前面进行了这么多的铺垫之后,我想可以进入正题了。即spark-shell的执行调用路径到底怎样。
首次使用Spark一般都是从执行spark-shell开始的,当在键盘上敲入spark-shell并回车时,后面究竟发生了哪些事情呢?
export SPARK_SUBMIT_OPTS
$FWDIR /bin/spark - submit spark -shell "$@" --class org.apache.spark.repl.Main
可以看出spark-shell其实是对spark-submit的一层封装,但事情到这还没有结束,毕竟还没有找到调用java的地方,继续往下搜索看看spark-submit脚本的内容。
exec $SPARK_HOME /bin/spark -class org. apache .spark.
deploy . SparkSubmit "${ ORIG_ARGS [@]}"
离目标越来越近了,spark-class中会调用到java程序,与java相关部分的代码摘录如下
# Find the java binary
if [ -n "${ JAVA_HOME }" ]; then
RUNNER ="${ JAVA_HOME }/ bin/java"
else
if [ `command -v java ` ]; then
RUNNER ="java"
else
echo " JAVA_HOME is not set" >&2
exit 1
fi
fi
exec " $RUNNER " -cp " $CLASSPATH " $JAVA_OPTS "$@"
SparkSubmit当中定义了Main函数,在它的处理中会将spark repl运行起来,spark repl能够接收用户的输入,通过编译与运行,返回结果给用户。这就是为什么spark具有交互处理能力的原因所在。调用顺序如下
- SparkSubmit
- repl.Main
- SparkILoop
利用jvisualvm验证
修改spark-class,使得JAVA_OPTS看起来如下图所示
JMX_OPTS="-Dcom.sun.management.jmxremote.port=8300 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
# Set JAVA_OPTS to be able to load native libraries and to set heap size
JAVA_OPTS="-XX:MaxPermSize=128m $OUR_JAVA_OPTS $JMX_OPTS"
JAVA_OPTS="$JAVA_OPTS -Xms$OUR_JAVA_MEM -Xmx$OUR_JAVA_MEM"
修改完上述脚本之后先启动spark-shell,然后再启动jvisualvm
bin/spark-shell
jvisualvm
在Java VisualVM中选择进程org.apache.spark.deploy.SparkSubmit,如果已经为jvisualvm安装了插件Threads Inspector,其界面将会与下图很类似
在右侧选择“线程”这一tab页,选择线程main,然后可以看到该线程的thread dump信息
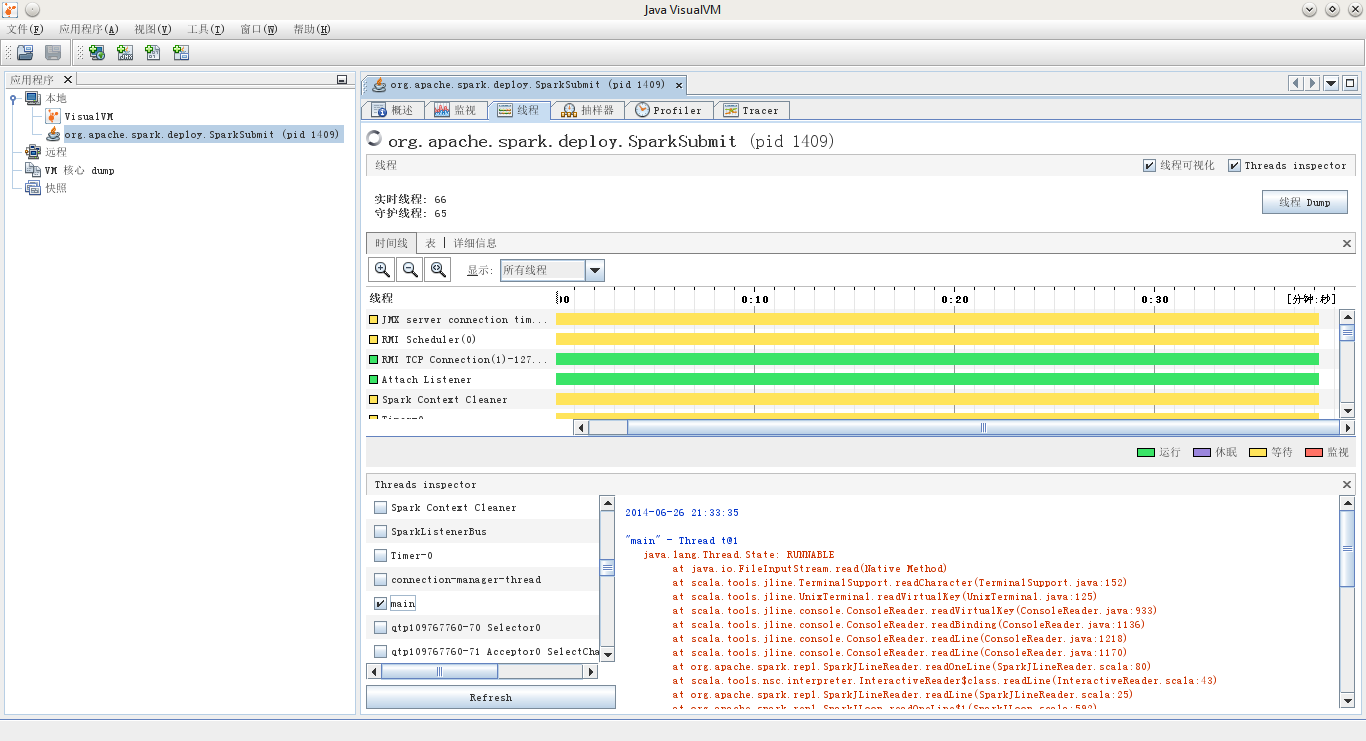
spark repl vs. scala repl
既然scala已经提供了repl, spark还是要自己去实现一个repl,你不觉着事有可疑么?我谷歌了好长时间,终于找到了大神的讨论帖子,不容易啊,原文摘录如下。
Thanks for looping me in! Just FYI, I would also be okay if instead of making the wrapper code pluggable, the REPL just changed to one based on classes, as in Prashant's example, rather than singleton objects.
To give you background on this, the problem with the "object" wrappers is that initialization code goes into a static initializer that will have to run on all worker nodes, making the REPL unusable with distributed applications. As an example, consider this:// file.txt is a local file on just the masterval data = scala.io.Source.fromFile("file.txt").mkString// now we use the derived string, "data", in a closure that runs on the clusterspark.textFile.map(line => doStuff(line, data))The current Scala REPL creates an object Line1 whose static initializer sets data with the code above, then does import Line1.data in the closure, which will cause the static initializer to run *again* on the remote node and fail. This issue definitely affects Spark, but it could also affect other interesting projects that could be built on Scala's REPL, so it may be an interesting thing to consider supporting in the standard interpreter.Matei
上述内容估计第一次看了之后,除了一头雾水还是一头雾水。翻译成为白话就是利用scala原生的repl,是使用object来封装输入的代码的,这有什么不妥,“序列化和反序列化”的问题啊。反序列化的过程中,对象的构造函数会被再次调用,而这并不是我们所期望的。我们希望生成class而不是object,如果你不知道object和class的区别,没关系,看一下scala的简明手册,马上就明白了。
最重要的一点:Scala Repl默认输入的代码都是在本地执行,故使用objectbasedwraper是没有问题的。但在spark环境下,输入的内容有可能需要在远程执行,这样objectbasedwrapper的源码生成方式经序列化反序列化会有相应的副作用,导致出错不可用。
讨论详情,请参考该Link https://groups.google.com/forum/#!msg/scala-internals/h27CFLoJXjE/JoobM6NiUMQJ
scala repl执行过程
再啰嗦一次,scala是需要编译执行的,而repl给我们的错觉是scala是解释执行的。那我们在repl中输入的语句是如何被真正执行的呢?
简要的步骤是这样的
- 在repl中输入的每一行语句,都会被封装为一个object, 这一工作主要由interpreter完成
- 对该object进行编译
- 由classloader加载编译后的java bytecode
- 执行引擎负责真正执行加载入内存的bytecode
interpreter in scala repl
那么怎么证明我说的是对的呢?很简单,做个实验,利用下述语句了启动scala repl
scala -Dscala.repl.debug=true
如果我们输入这样一条语句 val c = 10,由interpreter生成的scala源码会如下所列
object $read extends scala.AnyRef {
def () = {
super.;
()
};
object $iw extends scala.AnyRef {
def () = {
super.;
()
};
object $iw extends scala.AnyRef {
def () = {
super.;
()
};
val c = 10
}
}
}
注意啰,是object哦,不是class。
interpreter in spark repl
那我们再看看spark repl生成的scala源码是什么样子的?
启动spark-shell之前,修改一下spark-class,在JAVA_OPTS中加入如下内容
-Dscala.repl.debug=true
启动spark-shell,输入val b = 10,生成的scala源码如下所示
class $read extends AnyRef with Serializable {
def (): $line10.$read = {
$read.super.();
()
};
class $iwC extends AnyRef with Serializable {
def (): $read.this.$iwC = {
$iwC.super.();
()
};
class $iwC extends AnyRef with Serializable {
def (): $iwC = {
$iwC.super.();
()
};
import org.apache.spark.SparkContext._;
class $iwC extends AnyRef with Serializable {
def (): $iwC = {
$iwC.super.();
()
};
class $iwC extends AnyRef with Serializable {
def (): $iwC = {
$iwC.super.();
()
};
private[this] val b: Int = 100;
def b: Int = $iwC.this.b
};
private[this] val $iw: $iwC = new $iwC.this.$iwC();
def $iw: $iwC = $iwC.this.$iw
};
private[this] val $iw: $iwC = new $iwC.this.$iwC();
def $iw: $iwC = $iwC.this.$iw
};
private[this] val $iw: $iwC = new $iwC.this.$iwC();
def $iw: $iwC = $iwC.this.$iw
};
private[this] val $iw: $read.this.$iwC = new $read.this.$iwC();
def $iw: $read.this.$iwC = $read.this.$iw
};
object $read extends scala.AnyRef with Serializable {
def (): $line10.$read.type = {
$read.super.();
()
};
private[this] val INSTANCE: $line10.$read = new $read();
def INSTANCE: $line10.$read = $read.this.INSTANCE;
private def readResolve(): Object = $line10.this.$read
}
}
注意到与scala repl中的差异了么,此处是class而非object
IMain.scala vs. SparkIMain.scala
是什么导致有上述的差异的呢?我们可以下载scala的源码,对是scala本身的源码在github上可以找到。interpreter中代码生成部分的处理逻辑主要是在IMain.scala,在spark中是SparkIMain.scala。
比较两个文件的异同。
gvimdiff IMain.scala SparkIMain.scala
gvimdiff是个好工具,两个文件的差异一目了然,emacs和vim总要有一样玩的转才行啊。来个屏幕截图吧,比较炫吧。
注:spark开发团队似乎给scala的开发小组提了一个case,在最新的scala中似乎已经支持classbasedwrapper,可以通过现应的选项来设置来选择classbasedwraper和objectbasedwrapper.
下述代码见最新版scala,scala-2.12.x中的IMain.scala
private lazy val ObjectSourceCode: Wrapper =
if (settings.Yreplclassbased) new ClassBasedWrapper else new ObjectBasedWrapper
compiler
scala实现了自己的编译器,处理逻辑的代码实现见scala源码中的src/compiler目录下的源文件。有关其处理步骤不再赘述,请参考ref3,ref4中的描述。
有一点想要作个小小提醒的时,当你看到SparkIMain.scala中有new Run的语句却不知道这个Run在哪的时候,兄弟跟你讲在scala中的Global.scala里可以找到, :)
小结
编译和加载是一个非常有意思的话题,即可以说是很基础也可以说很冷门,有无动力就这部分进行深究,就看个人的兴趣了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号