

云大数据实战记录-大数据推荐
前言
WHY 云:为什么我们须要云。大数据时代我们面对两个问题,一个是大数据的存储。一个是大数据的计算。
由于数据量过大,在单个终端上运行效率过差,所以人们用云来解决这两个问题。
WHAT IS 云:云得益于分布式计算的思想。举个简单的样例。运行一千万个数据每一个数据都乘以10并输出,在个人pc上须要大概20分钟。假设是100台电脑做这个工作。可能仅仅用几十秒就能够完毕。云就是我们将复杂的工作通过一定的算法分配给云端的n个server,这样能够大大提高运算效率。
How 云:云的实现也就是分步式计算的过程。分布式的思想起源于MapReduce,是google最先发表的一篇论文中提到的。如今非常多的分布式计算方法都是从中演变过来的。大体的思路是。将任务通过map分离——计算——合并——reduce——输出。
云的价值不光是存储数据。更是用来分析和处理数据,得益于云。很多其它的算法能够快捷的实现。所以说云计算和大数据倔是不可切割的,可能大家在平时的学习过程中还没有机会在云端接触大数据运算。以下就分享一下本人的一次云计算的经历。
1.背景
这次是真正接触到TB集的数据。并且全然是在云端处理。以下就把这次的经历简单分享一下。
2.工具的简单说明
sql玩的溜的大神们都能够用sql语句实现非常多的算法,当然博主仅仅能用sql合并表、简单查询之类的。比方我们实现一个简单的查询去重的功能,odps能够通过分布式计算将任务量分不给非常多云端server,然后高速的运行大数据的查询工作。差点儿相同三百多万的数据查询仅仅用一分钟就解决的,假设要是离线測试,预计得几十分钟。这就是云的魅力。
select distinct * from table_name;
我们使用mr实现算法,能够通过配置文件设置一些分布式的规则,然后将jar文件post到云端就实现了云计算。
上一张mr的图片。

3.TRY

如今的问题关键就是,当我们有非常多特征值时。哪些特征值作为父类写在二叉树的上面的节点,哪下写在以下。我们能够直观的看出上面的特征值节点应该是对目标指数影响较大的一些特征值。那么怎样来比較哪些特征值对目标指数影响较大呢。
这里引出一个概念,就是信息熵。
信息理论的鼻祖之中的一个Claude E. Shannon把信息(熵)定义为离散随机事件的出现概率。说白了就是信息熵的值越大就表明这个信息集越混乱。
信息熵的计算公式,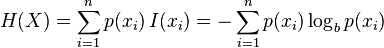 (建议去wiki学习一下)
(建议去wiki学习一下)
这里我们通过计算目标指数的熵和特征值得熵的差。也就是熵的增益来确定哪些特征值对于目标指数的影响最大。
第一部分-计算熵:函数主要是找出有几种目标指数。依据他们出现的频率计算其信息熵。
- def calcShannonEnt(dataSet):
- numEntries=len(dataSet)
- labelCounts={}
- for featVec in dataSet:
- currentLabel=featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel]=0
- labelCounts[currentLabel]+=1
- shannonEnt=0.0
- for key in labelCounts:
- prob =float(labelCounts[key])/numEntries
- shannonEnt-=prob*math.log(prob,2)
- return shannonEnt
第二部分-切割数据 由于要每一个特征值都计算对应的信息熵,所以要对数据集切割。将所计算的特征值单独拿出来。
- def splitDataSet(dataSet, axis, value):
- retDataSet = []
- for featVec in dataSet:
- if featVec[axis] == value:
- reducedFeatVec = featVec[:axis] #chop out axis used for splitting
- reducedFeatVec.extend(featVec[axis+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
第三部分-找出信息熵增益最大的特征值
- def chooseBestFeatureToSplit(dataSet):
- numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
- baseEntropy = calcShannonEnt(dataSet)
- bestInfoGain = 0.0; bestFeature = -1
- for i in range(numFeatures): #iterate over all the features
- featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
- uniqueVals = set(featList) #get a set of unique values
- newEntropy = 0.0
- for value in uniqueVals:
- subDataSet = splitDataSet(dataSet, i, value)
- prob = len(subDataSet)/float(len(dataSet))
- newEntropy += prob * calcShannonEnt(subDataSet)
- infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
- if (infoGain > bestInfoGain): #compare this to the best gain so far
- bestInfoGain = infoGain #if better than current best, set to best
- bestFeature = i
- return bestFeature #returns an integer
- def createTree(dataSet,labels):
- #把全部目标指数放在这个list里
- classList = [example[-1] for example in dataSet]
- #以下两个if是递归停止条件,各自是list中都是同样的指标或者指标就剩一个。
- if classList.count(classList[0]) == len(classList):
- return classList[0]
- if len(dataSet[0]) == 1:
- return majorityCnt(classList)
- #获得信息熵增益最大的特征值
- bestFeat = chooseBestFeatureToSplit(dataSet)
- bestFeatLabel = labels[bestFeat]
- #将决策树存在字典中
- myTree = {bestFeatLabel:{}}
- #labels删除当前使用完的特征值的label
- del(labels[bestFeat])
- featValues = [example[bestFeat] for example in dataSet]
- uniqueVals = set(featValues)
- #递归输出决策树
- for value in uniqueVals:
- subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
- myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
- return myTree
4.详细实现
(1)特征提取
 ,就会变为一条曲线。更easy实现拟合。
,就会变为一条曲线。更easy实现拟合。(2)随机森林參数调试
深度是指每棵决策树的深度,这个特征值假设多就多设置一些。我是有15个特征值,深度设为4。秀一下我的决策树:

5.总结
 (github.com/jimenbian,里面有非常多算法的实现。
(github.com/jimenbian,里面有非常多算法的实现。/********************************
* 本文来自博客 “李博Garvin“
* 转载请标明出处:http://blog.csdn.net/buptgshengod
******************************************/
版权声明:本文博客原创文章,博客,未经同意,不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号