

1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
① 增加样本量,若样本量少,但特征过多,则容易发生过拟合
② 通过特征选择,剔除一些不重要的特征,从而降低模型的复杂度
③ 将样本数据进行离散化处理,所有特征都进行离散化处理
④ 使用正则化:所有特征都对预测结果有重要作用,若是舍弃特征,便会舍弃有用的信息,因此我们考虑正则化。
⑤ 交叉验证
过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
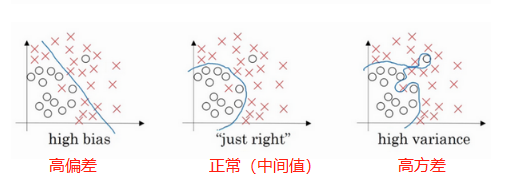
正则项会使权重趋于0,就意味着大量权重就和0没什么差别了,此时网络就变得很简单,拟合能力变弱,从高方差往高偏差的方向移动,而移动过程中存在一个中间值,到达中间值时,该模型的就不会过拟合。
通俗来讲,过拟合时,拟合函数的系数往往非常大,而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
2.用logiftic回归来进行实践操作,数据不限。
使用logiftich回归算法根据学生前两次考试成绩预测这次的考试成绩是否达标(即大于60)
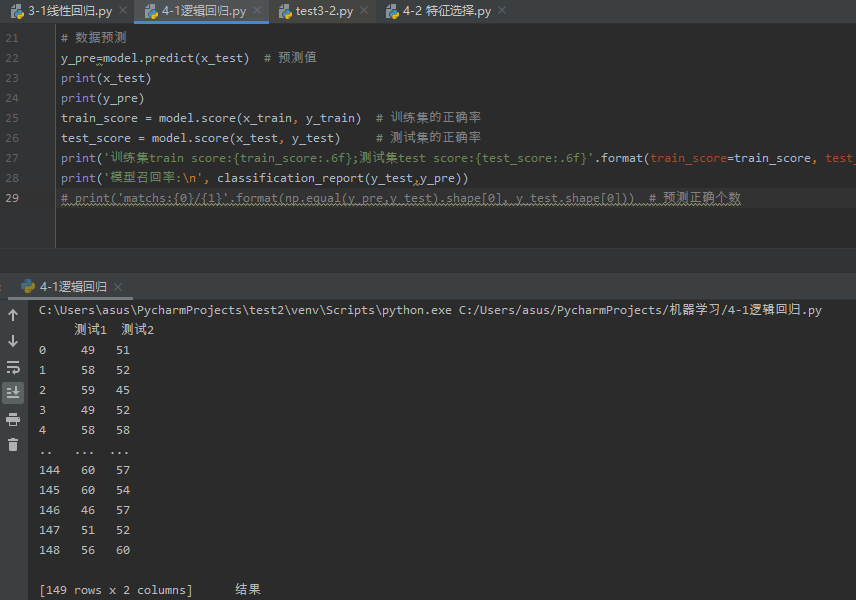
源代码如下:
1 # 用logiftic回归来进行实践操作,数据不限 2 import pandas as pd 3 import numpy as np 4 from sklearn.linear_model import LogisticRegression 5 from sklearn.model_selection import train_test_split 6 from sklearn.metrics import classification_report 7 # 读取数据 8 data = pd.read_csv("逻辑回归数据.csv") 9 x = data.iloc[:,0:2] 10 y = data.iloc[:,2:3] 11 print(x,y) 12 13 # 划分训练集和测试集 14 x_train, x_test, y_train, y_test=train_test_split(x, y, test_size=0.2) 15 16 # 逻辑回归模型的构建 17 model = LogisticRegression() 18 # 逻辑回归模型的训练 19 model.fit(x_train, y_train) 20 21 # 数据预测以及模型评估 22 y_pre=model.predict(x_test) # 预测值 23 print(x_test) 24 print("预测结果为:",y_pre) 25 train_score = model.score(x_train, y_train) # 训练集的正确率 26 test_score = model.score(x_test, y_test) # 测试集的正确率 27 print('训练集train score:{train_score:.6f};\n测试集test score:{test_score:.6f}'.format(train_score=train_score, test_score=test_score)) 28 print('模型召回率:\n', classification_report(y_test,y_pre)) 29 # print('matchs:{0}/{1}'.format(np.equal(y_pre,y_test).shape[0], y_test.shape[0])) # 预测正确个数
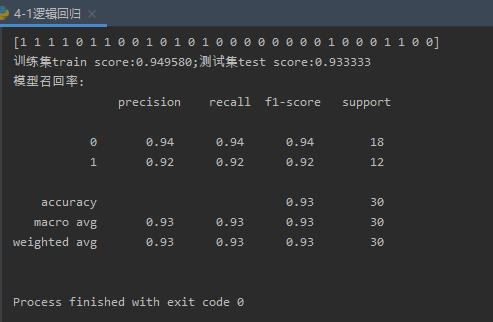
运行截图如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号