作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类


| 第一轮 | 中心 | 12 | 4 | 7 |
| 总和/个数 | 103/9 | 44/16 | 78/10 | |
| 新中心 | 11.44 | 2.75 | 7.8 | |
| 第二轮 | 总和/个数 | 103/9 | 44/16 | 78/10 |
| 新中心 | 11.44 | 2.75 | 7.8 |
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
1 import matplotlib.pyplot as plt 2 from sklearn.datasets import load_iris 3 import numpy as np 4 #导入数据 5 iris = load_iris() 6 data = iris.data # 数据值 7 data.shape # 可知数据的总数和属性个数 8 n = len(data) # 数据集样本个数 9 m = data.shape[1] # 数据的属性个数 10 # 类中心个数(1-5) 11 k = 3 12 dist = np.zeros([n, k+1]) # k+1是最后一列要归类 13 # 选中心 14 center = data[:k, :] # k为3所以是前三行所有属性 15 centerNew = np.zeros([k, m]) # 初始化新的类中心 16 while True: 17 # 求距离 18 for i in range(n): 19 for j in range(k): 20 dist[i, j] = np.sqrt(sum((data[i, :]-center[j, :])**2)) # 求欧式距离 21 # 归类 22 dist[i, k] = np.argmin(dist[i, :k]) 23 for i in range(k): 24 index = dist[:, k] == i 25 centerNew[i, :] = data[index, :].mean(axis=0) 26 # 判定结果 27 if np.all((center == centerNew)): 28 break 29 else: 30 center = centerNew 31 print("聚类结果:\n", dist[:, k]) 32 # print(data[:,k]) 33 plt.scatter(data[:,2], data[:,2], c=dist[:,2], s=50, cmap='rainbow') 34 plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体 35 plt.title("鸢尾花花瓣长度做聚类的散点图") 36 plt.show()
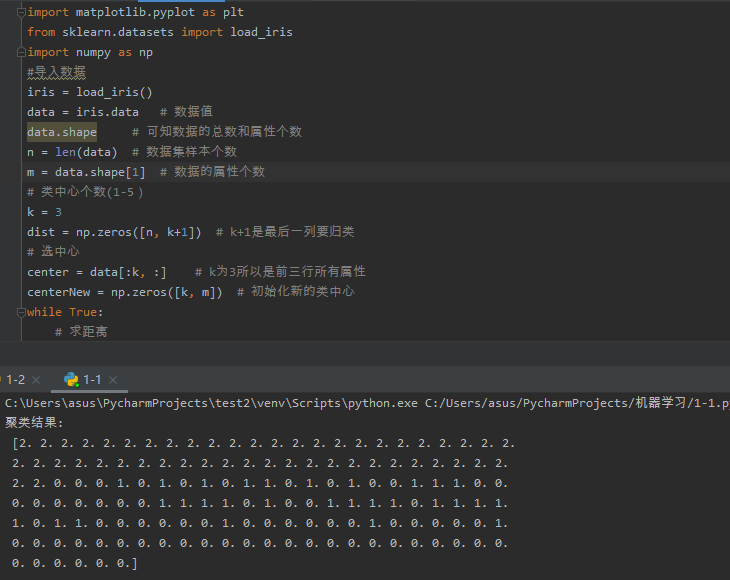
图2-1 运行结果
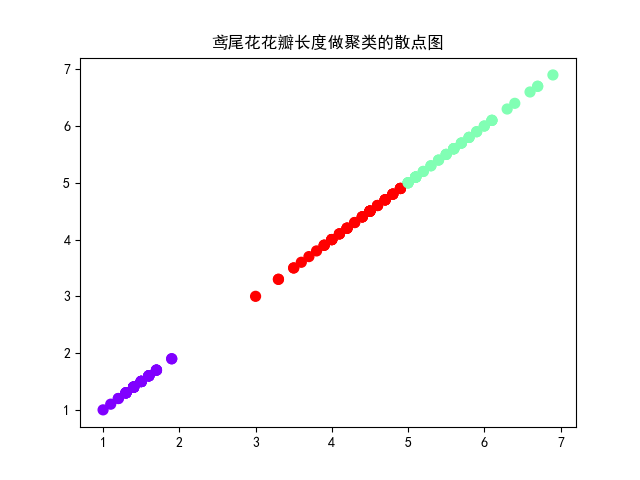
图2-2 散点图
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
源代码如下:
1 # 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示. 2 import matplotlib.pyplot as plt 3 from sklearn.datasets import load_iris 4 from sklearn.cluster import KMeans 5 6 iris = load_iris() # 导入鸢尾花数据 7 # print(iris) 8 X = iris.data[:, 2] # 第三列为花瓣长度 9 X = X.reshape(-1, 1) # 令新数组列为1 10 # print(X) 11 y = KMeans(n_clusters=3) # 模型构建(类中心数为3) 12 y.fit(X) # 模型训练 13 kc = y.cluster_centers_ # 聚类中心 14 y_kmeans = y.predict(X) # 预测每个样本的聚类索引 15 print("聚类结果:\n", y_kmeans) 16 print("聚类中心:\n", kc) 17 plt.scatter(X[:, 0], X[:, 0], c=y_kmeans, s=50, cmap='rainbow') # 画散点图 18 plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体 19 plt.title("鸢尾花花瓣长度做聚类的散点图") 20 plt.show()
运行结果如下:
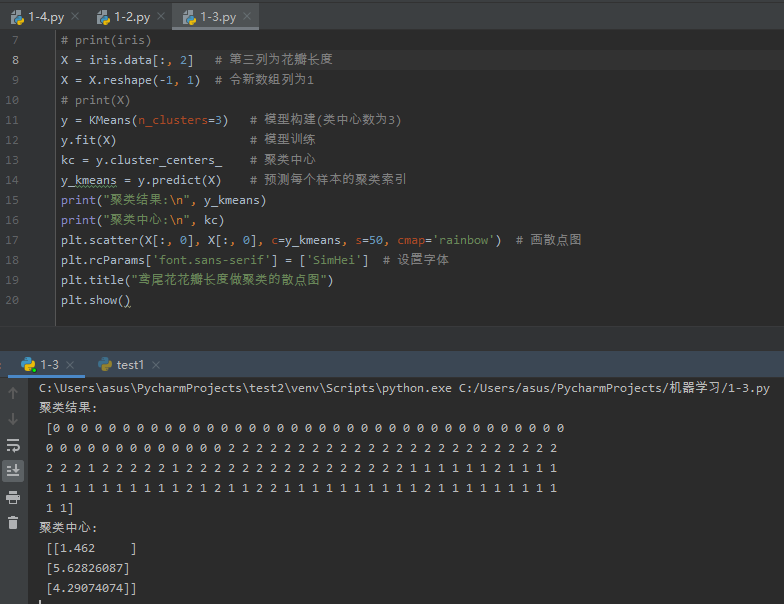
图3-1 运行结果
图3-2 散点图
4). 鸢尾花完整数据做聚类并用散点图显示.
源代码如下:
1 # 鸢尾花完整数据做聚类并用散点图显示. 2 import matplotlib.pyplot as plt 3 from sklearn.datasets import load_iris 4 from sklearn.cluster import KMeans 5 6 iris = load_iris() # 导入鸢尾花数据 7 X = iris.data # 鸢尾花完整数据 8 # print(X) 9 y = KMeans(n_clusters=3) # 模型构建(类中心数为3) 10 y.fit(X) # 模型训练 11 kc = y.cluster_centers_ # 聚类中心 12 y_kmeans = y.predict(X) # 预测每个样本的聚类索引 13 print("聚类结果:\n", y_kmeans) 14 print("聚类中心:\n", kc) 15 plt.scatter(X[:, 2], X[:, 3], c=y_kmeans, s=50, cmap='rainbow') # 画散点图 16 plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体 17 plt.title("鸢尾花完整数据做聚类的散点图") 18 plt.show()
运行结果如下:
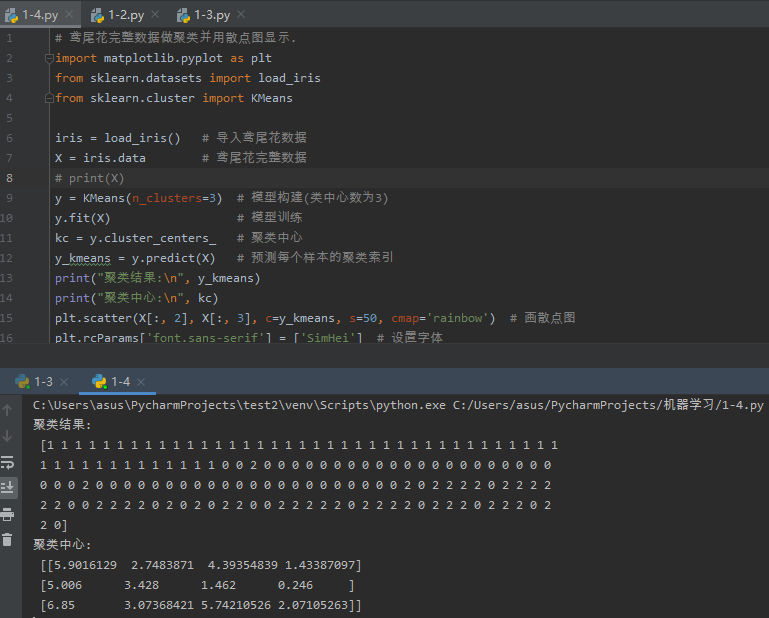
图4-1 运行结果
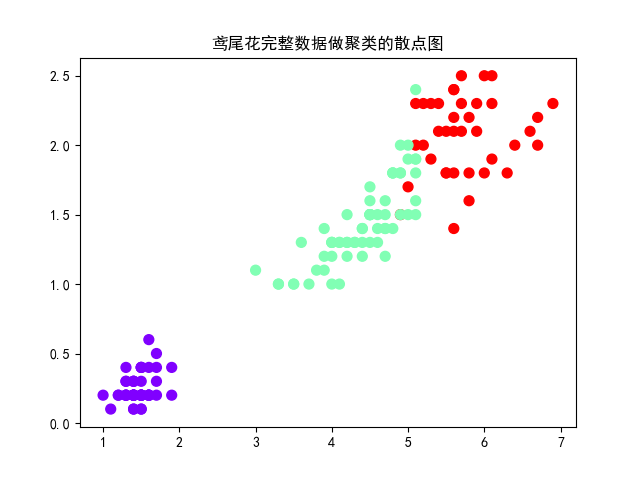
图4-2 散点图
5).想想k均值算法中以用来做什么?
K-均值聚类法是聚类分析中常用的一种方法。聚类分析的目的是将依据观测值将样本或变量进行分组,K-均值聚类法要求事先指定类的个数。
K均值算法可以应用到企业信息管理中,例如:在进行客户管理时,通常将客户分为VIP,A,B,C等不同等级。可以使用K均值算法,根据客户的订单总量,订单频率,订单总额,信用等对客户进行分类,使每个客户得到一个等级。
K均值算法还可以应用到员工的评级,例如:根据员工的业绩,考勤等进行分类,使得每个员工都得到一个等级。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号