

Scrapy终端(Scrapy shell)
1.介绍文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html#
2.终端的启用方式:scrapy shell url
url 即为你要爬取的网站
3.使用scrapy shell遇到的问题

当用scrapy shell访问如上图的链接时,报出如下错误:
DEBUG: Crawled (504) <GET http://wz.sun0769.com/index.php/question/questionType?type=4> (referer: None) ['partial']
最终发现问题的根源是user-agent:我们在使用scrapy shell进行爬虫调试的时候,user-agent的配置在默认的全局设置中
全局默认值位于scrapy.settings.default_settings 模块中,如下图:

解决方案1:将default_settings.py中的USER_AGENT修改为任意一个浏览器的user-agent
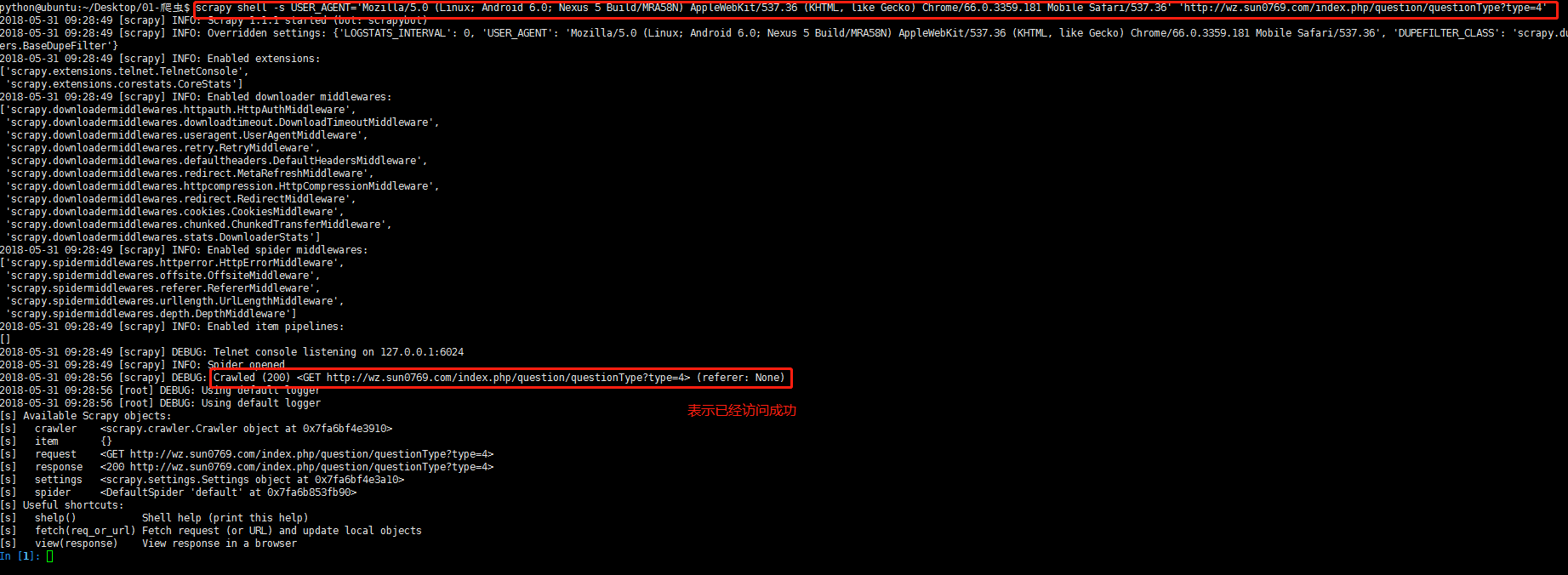
解决方案2:我们在终端输入scrapy shell --help有可以看到有一个选项为-s即为在启动爬虫的时候对默认的default_settings文件
中的设置项进行覆盖;
在终端键入:scrapy shell -s USER_AGENT='Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36' 'http://wz.sun0769.com/index.php/question/questionType?type=4',问题即看得到解决。
应该注意的是 USER_AGENT的等号不能有空格

 浙公网安备 33010602011771号
浙公网安备 33010602011771号