
算法笔记常见问题及记录
- 接受了考试后:购买了专栏真题,邮件里有写是哪个卷子
- cout输出浮点数后几位:保留小数点可以使用printf("%.2f",a),也可以使用iomanip库的fixed函数设定固定小数点格式,使用setprecision(设置保留小数点位数)
cout<<(a/b)<<endl<<fixed<<setprecision(2)<<(double(a)/double(b));fixed<<setprecision(0)<<d - 对于基本数据类型和字符数组,
printf函数通常直接传递变量的值或数组名,无需使用&符号 - 两个整型变量的四则运算结果仍然是整型,因此它的除法是整除的,也即只取了除法的整数部分(即商),于是
a/b就是一个整数。如果希望使用浮点除法的话,需要先将a或b强制转换成浮点型,然后再进行除法操作,因此(double)a / b、a / (double)b、(double)a / (double b)、1.0 * a / b等操作都是可行的,但(double)(a / b)是不行的,因为这样做是把a / b的结果转成浮点型,也即将整除后的结果(整数)转成浮点型,就达不到我们想要的效果了 - cin不支持格式化输入比如输入yyyy-mm-dd,需要使用scanf格式化输入
int num; scanf("%d", &num); float value; scanf("%f", &value); char ch; scanf("%c", &ch); char str[100]; scanf("%s", str); 限制读取的长度: char str[10]; scanf("%5s", str); // 最多读取4个字符(留一个位置给字符串结束符'\0') 匹配特定的字符: char str[10]; scanf("%[abcd]", str); // 只读取字符a、b、c、d,遇到其他字符停止 不匹配某些字符: char str[10]; scanf("%[^0-9]", str); // 读取除数字之外的所有字符 丢弃某些字符: char str[10]; scanf("%*[a-z]"); // 丢弃所有小写字母,不往变量中存放 scanf("%s", str); // 接着读取字符串 - string拼接字符串:“a”+“b” 转换字符串类型 to_string()
- c++写的函数必须在主函数之前,或者在主函数之前声明
#include <iostream> // 函数原型声明 void myFunction(); int main() { myFunction(); // 调用函数 return 0; } // 函数定义 void myFunction() { std::cout << "Hello, World!" << std::endl; } -
getchar()返回输入流的asc2码值,因此可以直接和字符比较,也可以和asc2码比较
char a = ' '; // 空格字符 if (a == 32) { // 这是正确的,因为' '的ASCII码值是32 // 但是通常我们更习惯直接与字符比较 } // 或者更直接地与字符比较 if (a == ' ') { // 这是更常见和直观的方式 } - 遇到换行输入的数据时,需要使用getchar()来读取换行符,否则会将换行符读取到第二个输入的字符变量中
使用cin进行输入时,并不会因为输入整数而多一个换行符。实际上,cin会忽略输入中的空格、制表符和换行符,只提取有效的数据部分。
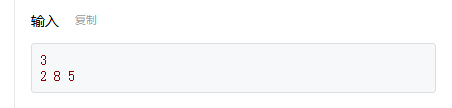
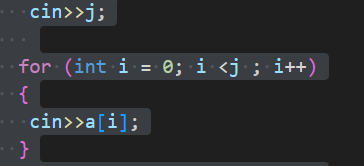
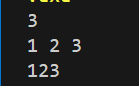
在使用scanf进行输入时,需要注意输入数据的格式和字符之间的分隔符,以避免出现意外的输入行为。特别是在处理多组数据时,可能需要使用额外的字符变量来吸收换行符或空格符,以正确分隔各组数据。 - cin除了可以用回车分割输入,使用空格也能分开多个变量如图:
-
数学函数都在
cmath头文件下,以下是本题涉及的常见数学函数,它们都接收浮点型,返回的也是浮点型。fabs(a):a的绝对值floor(a):a的向下取整,会保留原有的小数点后位数ceil(a):a的向上取整round(a):a的四舍五入(需要注意%.0f使用的是四舍六入五成双规则(为5时根据前一位数字的奇数偶数来判断进位),与round函数不同)pow(a, b):a的b次方,其中b也可以是浮点型,数学中的“幂运算”(次方)英文是 power(如 23 读作 “2 to the power of 3”)。sqrt(a):a的算术平方根(即开根号)log(a):a的以自然对数e为底的对数
- float单精度是浮点数,double是双精度浮点数,单精度float的高次幂可能会损失精度,需要使用double进行
- %取余:
除数不能为0:如果尝试用0作为除数进行取余操作,程序将会抛出运行时错误(例如,在C++中通常是抛出
std::overflow_error异常)。因此,在使用%运算符之前,应该确保除数不为0。正负数的取余:取余操作的结果的正负性与被除数的正负性相同。例如,
-7 % 4的结果是-3,因为-7除以4的余数是-3。如果需要得到非负的余数,可以通过调整表达式来实现,例如使用(a % b + b) % b来确保结果总是非负的。 -
switch语句相当于是特殊情况下的连续if-else,即根据给定的值是不同的情况下应该分别执行哪些代码。在本题中,需要根据
n是0、1、2、3、4、5、大于5这些不同情况,去输出不同的结果。注意每个case结束后需要使用break语句结束整个switch,不然会一直往下执行其他的case部分。 - vscode 编译带中文的文件或者路径会乱码,导致debug错误,修改为字母
- 在使用
continue语句时,要确保它不会导致程序陷入死循环或产生其他不期望的行为。 continue语句通常与条件语句(如if)一起使用,以根据特定条件跳过某些循环迭代。在循环语句中,当遇到continue语句时,程序会跳过当前循环体中continue语句之后的所有语句,直接进行下一次循环的条件判断。
- 在使用
- 数据类型 数组名[数组长度];
int arr[5];
其中,数据类型表示数组中元素的类型,数组名是你给数组起的名字,数组长度是一个常量表达式,表示数组中元素的数量。 - 指针是一个变量,但它存储的不是普通数据,而是内存地址(类似快递单号记录包裹的位置)。通过指针,可以直接操作内存中的数据。
-
全局数组。
当我们试图在函数中开一个大数组时,很容易使程序报错退出,这是因为在函数(包括主函数)中定义变量时,变量会存放在“栈”区,栈区可以分配的内存较小,所以在开大数组的时候会因为申请不到内存而报错退出。而如果我们把数组开在函数外面,那么将会存放在“堆”区,堆区可以分配的内存较大,适合开大数组。
-
memset是一个用于批量设置内存内容的函数。cstring库
你可以把它想象成一个“批量填充工具”,比如:-
把一块内存全部填成
0(清空)。 -
把字符数组的每个字节都设为某个字符(比如
*)。 -
快速初始化结构体或数组。
函数原型#include <cstring> // 必须包含头文件void* memset(void* ptr, int value, size_t num);
-
- const修饰的全局数组必须显式初始化并且内容不可更改
const int a[maxln]; // ❌ 错误 cin.getline:仅C++可用,C语言不可用。需要添加#include <iostream>头文件,并且在头文件后增加一行using namespace std;。然后我们可以像下面这样使用,其中第一个参数是字符数组,第二个参数是最大允许读入的字符个数,设置为字符数组的长度即可。-
特性 getlinegetchar输入单位 整行(含空格) 单个字符 终止符处理 自动清除 保留在缓冲区 返回值类型 输入流对象 ASCII码值( int类型)内存管理 自动( string)或手动(字符数组)需手动分配 典型用途 读取句子、多行文本 逐字符处理、清理缓冲区
// getline读取整行(含空格) string line; getline(cin, line); // 输入"Hello World",line="Hello World" // getchar逐字符读取 char ch; while ((ch = getchar()) != '\n') { // 输入"Hello World" cout << ch; // 逐个输出字符,直到遇到回车 } -
cin.getline的第一个参数必须是 字符数组(char[]),而a是std::string数组,类型不匹配。改用
std::getline读取std::string对象:getline(cin, a[i]); // ✅ 正确(无需指定长度,自动处理内存) -
当使用
cout << str输出字符数组时:(也可以使用puts(str))-
从数组首地址开始逐个输出字符。
-
遇到
\0停止输出(不会继续输出后面的内存内容)。 -
最终效果是输出完整的字符串,无需手动循环。
- 字符数组以\0结尾,
cin.getline会自动在输入的字符串末尾添加\0
-
-
strlen函数的实现原理是,从头开始扫描字符数组,直到碰到结束符\0时结束扫描。由于这个遍历的过程,使得strlen函数的时间复杂度是O(len),其中len表示字符数组的长度。因此,当我们需要遍历字符串时,尽可能提前使用strlen函数计算好长度,而不要在for循环中写类似for (int i = 0; i < strlen(str); i++)的语句,因为这会导致每次循环都要重新执行strlen函数来计算一次长度,使整体时间复杂度上升一个级别。<string.h> -
假设我们使用字符数组来存储字符串,那么可以使用
strcmp函数来比较两个字符串的字典序大小:- 如果
strcmp(s1, s2) == 0,那么两个字符串相同 - 如果
strcmp(s1, s2) < 0,那么s1的字典序小于s2 - 如果
strcmp(s1, s2) > 0,那么s1的字典序大于s2
需要注意,
strcmp函数返回的结果并不一定是 1 或者 −1,所以不能使用等于 1 或 −1 的方式来进行判断。 - 如果
- 字典序(Lexicographical Order) 是指按照字符的ASCII值逐个比较字符串的顺序,类似于字典中单词的排列方式。
-
假定我们使用字符数组来存储字符串,那么可以使用
strcat函数来拼接字符串,其中strcat(s1, s2)表示把s2拼接到s1后面。注意,
strcat函数会将原字符串修改,而不是产生一个新的字符串,因此直接输出拼接后的s1即可。
或者string类型可以直接用+好连接两个字符串,string类型也可以使用><=进行比较 sscanf可以将字符数组按某个格式匹配提取出其中的某些部分,并将这些部分赋值到变量中。使用的方式和scanf类似,我们可以把scanf(格式串, &变量)视为从程序输入中按格式字符串的格式提取出变量,那么sscanf(字符数组, 格式串, &变量)就是从字符数组中按格式字符串的格式提取出变量。并且sscanf和scanf的返回内容都是成功读取的变量个数。
String Scan formatted字符扫描格式sscanf
其函数原型通常如下:
int sscanf(const char *str, const char *format, ...);str是要解析的字符串。format是格式控制字符串,指定了要提取的数据的类型和方式。- 后面的省略号表示一系列的指针参数,用来接收解析后的数据。
在C 语言标准库中sscanf函数返回成功匹配和赋值的个数,如果发生错误或到达字符串末尾,则返回EOF。- c++,else if有空格不是elseif
sprintf是 “string print formatted” 的缩写,意思是 “格式化地打印到字符串中”。从名字上可以直观地理解其功能,即像printf函数一样进行格式化输出,但输出的目标是一个字符串而不是标准输出设备。- sprintf和sscanf和scanf和printf类似,scanf都是通过&对变量赋值,print直接读取变量值不用&
在 C++ 中,当函数按值传递参数、进行简单变量赋值与操作时不用 `&` 直接传变量;而函数使用引用或指针参数、进行动态内存分配、调用要求传地址的标准库函数(如 `scanf`)时,需要用 `&` 传递变量地址。 - 格式控制
%02用于格式化输出,指定宽度为 2 且不足时用 0 填充;常见格式控制如%d输出十进制有符号整数、%u输出无符号整数、%x/%X输出十六进制、%o输出八进制、%f输出浮点数、%c输出字符、%s输出字符串、%%输出%字符,还可通过.n指定小数位数等。
示例代码如下:
#include <cstdio> int main() { int num = 5; double f = 3.14; const char* str = "abc"; char result[50]; std::sprintf(result, "Int:%02d, Float:%.2f, String:%s", num, f, str); std::printf("%s\n", result); return 0; } -
函数的局部变量作用域。
在函数中改变局部变量的值并不会影响到函数外面,因此函数中加 1 后原先的变量还是原值。
- 指针变量是一种特殊的变量,它存储的不是普通的数据值,而是内存地址。这个地址指向计算机内存中的某个位置,该位置可能存放着其他变量、数组、对象或者函数等。借助指针,程序能够直接对内存中的数据进行访问和操作,这极大地提升了编程的灵活性与效率,但同时也增加了编程的复杂度和出错的风险。
-
引用。
如果我们希望将函数内变量的修改影响到函数外,那么可以使用指针变量。除此之外,我们还可以使用引用(
&)。具体来说,可以在函数的参数中将可能修改值的参数名的前面加上&,这样在函数内关于该变量的修改就会影响到函数外。使用引用作为函数参数时,并没有修改内存地址,而是利用引用和原变量共享内存的特性,直接在原变量的内存地址上进行数据修改,使得函数内的修改能够影响到函数外的变量。引用提供了一种更简洁、更安全的方式来实现函数内外数据的同步修改,避免了指针使用时可能出现的空指针、野指针等问题。 -
结构体可以将多个相同或不同类型的变量组合在一起,语法如下:
struct Point { int x, y; }; - 构造函数是在结构体内部定义的一种特殊函数,可以用来构造结构体变量,它的 函数名和结构体名相同,并且 没有返回类型。
构造函数的核心作用之一就是对结构体(或类)的成员变量进行初始化。在创建结构体(或类)对象时,构造函数会自动被调用,确保对象的成员变量拥有合适的初始值,避免使用未初始化的变量引发的未定义行为。 - strcpy(name,_name)复制字符串,前者复制给后者
- 在结构体内部声明指向自身类型的指针是合法且实用的
struct Node { int id; Node *left; Node *right; // 默认构造函数 Node() : id(0), left(nullptr), right(nullptr) {} // 带参数的构造函数 Node(int _id, Node *_left = nullptr, Node *_right = nullptr) : id(_id), left(_left), right(_right) {} };解引用操作符 ->:当结构体变量p是普通类型时,我们用.来访问它的内部变量;而当结构体变量p是指针类型时,我们除了可以用(*p).id的方式以外,还可以使用p -> id的方式。->是用于指针类型的对象访问其成员变量或调用其成员函数的操作符。
取指针所指向对象的成员变量的值:node3.left->id当你使用 node3.left->id 时,实际上是先让程序找到 node3.left 所指向的内存地址处的对象,然后再访问该对象里名为 id 的成员变量。 - nullptr,对指针赋空值
-
由于浮点数的计算容易产生精度误差,因此对浮点数之间的比较需要特殊处理。
- 当 a−b 大于一个正的很小的数(例如 10−8)时,可以认为 a>b
- 当 a−b 小于一个负的绝对值很小的数(例如 −10−8)时,可以认为a<b
- 可以借助
std::cin的状态来实现类似while(scanf(...) != EOF)的效果。std::cin在读取数据失败或者遇到文件结束符时,会进入错误状态,你可以利用这个特性来构建循环。
do-while循环的特点是先执行循环体,再判断循环条件。这就意味着,即使还没有从输入读取到有效的a和b值,循环体也会执行一次,从而导致第一次输出可能是错误的结果。
41中使用while合适,使用dowhile会先执行以此计算break语句本身只能跳出它所在的那一层循环,无法直接跳出两层嵌套循环。
可以借助一个标志变量赋值并跳出-
使用
goto语句
-
swap() - 选择排序的思路是将序列分为已排序和未排序两个部分,每次从未排序部分中选择一个最小的元素,将它加入到已排序部分的最后,这样已排序部分最终就会形成一个从小到大的顺序。
定义两重循环,先选出数组第一个值准备在二重循环中开始比较,并且使用k标记未分类与分类的边界
在二重循环根据k,之前循环标记的起始值,开始挑出最小值,具体过程就是,如果遇到更小的,就将分类的起始点下标移到它身上,继续向后遍历,最后取到的k就是最小的数组下标
使用最小的数组下标,和一重循环标记的a[i]交换位置,并将未分类边界向后移动一位
void swaparr() { for (int i = 0; i < n; i++) { // a[i] // 从i开始都是没分类的,将j赋给k,记录未分类的下标 k = i; for (int j = k; j < n; j++) { //在本轮循环中选出最小的值a[k] if (a[k]>a[j]) { //如果有最小的就去拿最小的向后继续遍历比较 k = j; } } swap(a[i], a[k]); } } - 插入排序的思路是将序列分为已排序和未排序两个部分,每次将未排序部分的第一个元素在已排序部分中找到一个位置,使得将该元素插入到该位置时已排序部分仍然有序。
将第一个元素标记为已排序
对于每一个未排序的元素 X
“提取” 元素 X
i = 最后排序过元素的索引 到 0 的遍历
如果当前元素 j > X
将排序过的元素向右移一格
跳出循环并在此插入 X
void insertarr() { for (int i = 0; i < n; i++) {//外层循环是挑选比较元素的过程 //选择比较的元素拿出来 maxmin=a[i]; j=i; //j-1>0保证前面还有数据推 //同时j是准备分类的元素的下标,取出来那个位置就空了,j-1就是空的前一位已分类的最后一位,在循环结束时要确保未分类的最后一位是最大的 while (j-1>=0&&a[j-1]>maxmin) {//内层循环是将外层挑选元素取出来比较的过程,从i比到已排序的数组头 //如果被比较的元素比拿出来的元素值小,将被比较的元素右移, //j--逐一一直比到b[j-1]不存在即j-1<0 a[j]=a[j-1]; j--; } //将的拿出来的元素放到计算出的位置j a[j]=maxmin; } } sort函数(#include <algorithm>)的主要功能是对指定范围内的元素进行排序,使其按照特定的顺序排列。默认情况下,它会按照元素的升序进行排序,但通过提供自定义的比较函数,也可以实现降序排序或者根据其他规则进行排序。默认顺序排序,如需逆序则定义了一个自定义的比较函数compare,该函数接受两个整数参数a和b,并返回a > b的结果。在调用std::sort函数时,我们将这个自定义比较函数作为第三个参数传递给sort函数,从而实现了降序排序。#include <iostream> #include <algorithm> #include <vector> // 自定义比较函数,实现降序排序 bool compare(int a, int b) { return a > b; } int main() { std::vector<int> vec = {5, 2, 8, 1, 9}; // 使用自定义比较函数进行排序 std::sort(vec.begin(), vec.end(), compare); // 输出排序后的结果 for (int num : vec) { std::cout << num << " "; } std::cout << std::endl; return 0; }
sort函数主要是快排,选择混合排序,不稳定,可以使用stable_sort排序
这个函数可以对数组或容器中的元素进行排序,字符按照字典序,默认情况下是按字典序(lexicographical order)从小到大排序。sort(arr, arr + n)中,arr是数组的起始地址,arr + n是数组结束位置的下一个地址- 定义sort中较为复杂的比较规则
int comparesc1(Student x, Student y) { if (x.chscore == y.chscore) { //按姓名升序排列 return x.name < y.name; } else { //按分数降序排列 return x.chscore > y.chscore; } } - 构造函数的名字必须和结构体名一致,且没有返回类型。还要记得定义一个默认构造函数
struct Student { string name; int chscore; int mascore; int totalscore; Student(string str, int sc1, int sc2) { name = str; chscore = sc1; mascore = sc2; totalscore = sc1 + sc2; } }; - 调用构造函数的时机导致初始化错误,导致输出的总分异常
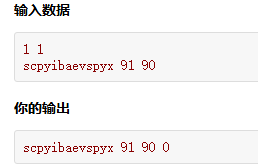
struct Student { string name; int chscore; int mascore; int totalscore; //默认构造函数 Student(){ totalscore=0; } Student(string str, int sc1, int sc2) { name = str; chscore = sc1; mascore = sc2; totalscore = sc1 + sc2; } }; Student stu[n]; for (int i = 0; i < n; i++) { //在循环里给默认构造函数赋值时,不会调用构造函数,所以导致总分一直没有赋值为空 cin >> stu[i].name >> stu[i].chscore >> stu[i].mascore; }初始化stu数组时,如果在构造函数中处理总分,是不会相加的,因为调用的是默认的构造函数,此时调用的是默认构造函数,为了避免这种情况,在循环输入无法调用构造函数时应该重新给stu数组赋值或使用构造函数给数组赋值
类似如下:
Student stu[n]; for (int i = 0; i < n; i++) { //在循环里给默认构造函数赋值时,不会调用构造函数,所以导致总分一直没有赋值为空 cin >> stu[i].name >> stu[i].chscore >> stu[i].mascore; stu[i].totalscore=stu[i].chscore+stu[i].mascore; } -
逻辑与运算符
&&有短路特性,也就是当i > 0这个条件为false时,就不会再计算后面的a[i - 1] == a[i]。所以当i为0时,i > 0为false,就不会去访问a[-1],从而避免了数组越界的问题。
- 逻辑与运算符
&&有短路特性,也就是当i > 0这个条件为false时,就不会再计算后面的a[i - 1] == a[i]。所以当i为0时,i > 0为false,就不会去访问a[-1],从而避免了数组越界的问题。
-
哈希映射(Hash Map),也称为散列映射,是一种重要的数据结构,它提供了一种高效的方式来存储和检索键值对。
- 哈希表(Hash Table)是一种重要的数据结构,它通过哈希函数来实现快速的数据插入、查找和删除操作。
哈希表利用哈希函数将键(Key)映射到一个固定大小的数组索引上,这个数组被称为哈希表。当需要存储或查找一个键值对时,先通过哈希函数计算键对应的索引,然后在该索引位置进行操作。理想情况下,每个键都能被唯一地映射到一个索引,这样可以实现 \(O(1)\) 时间复杂度的插入、查找和删除操作。但在实际应用中,可能会出现多个键映射到同一个索引的情况,这被称为哈希冲突,需要通过一些方法(如链地址法、开放寻址法)来解决。
C++ 标准库在<unordered_map>和<unordered_set>头文件中插入元素
插入元素
return c - 'a';的作用是将小写字母字符c转换为一个 0 到 25 的整数,对应字母表中的位置(a→0,b→1,...,z→25)。其核心逻辑基于 ASCII 码的数值计算。
核心思想是利用 ASCII 码的连续性,将字符的偏移量转换为整数索引。- 将数组中的所有元素都设置为0:
int hashTable[maxln] = {0};
或者使用memset(hashtable,0,maxln) - 从a-z遍历字母
for (char c = 'a'; c <= 'z'; c++) { //如果该字符在hashtable中的值大于0,输出 if (hashTable[getHashKey(c)]) { cout << i <<" "<<hashTable[getHashKey(c)]<<endl; /* code */ } -
cin在读取字符串时,会在遇到空白字符(如空格、制表符、换行符)时停止读取。例如,如果你输入Hello World,cin只会将Hello存储到字符数组中,World部分会留在输入缓冲区等待下一次读取。可以直接写入字符数组,cin>>str;
在使用cin写入字符数组时,cin.get(ch)逐个字符地读取输入并写入字符数组,直到读取到换行符'\n'或者数组已满(i < MAX_LENGTH - 1)。
cin>>str; int n = strlen(str); for (int i = 0; i < n; i++) { hashTable[getHashKey(str[n])]++; } -
string适合处理动态长度、需要进行复杂操作的字符串,而char数组在与 C 语言交互、对内存和性能有特殊要求或处理固定长度字符串时更有优势。 -
在 C++ 里,
char本质上是一种整数类型(有signed char和unsigned char之分),它能够像整数一样参与算术运算和作为数组索引使用。字符在计算机中是以 ASCII 码(或者其他字符编码)形式存储的,每个字符对应一个整数值。例如,字符'a'的 ASCII 码值是 97,'b'的 ASCII 码值是 98 。 - 字符串到整数的映射:将每个字符串映射到一个唯一的整数。由于字符串由三个大写字母组成,我们可以将其视为一个26进制的数,并转换为十进制数。
对于字符串s2s1s0,我们将其转换为整数的方式是:a2×26^2+a1×26+a0,其中ai是字符si减去'A'后的值。
int getHashkey(char s[]) { return (s[0] - 'A') * 26 * 26 + (s[1] - 'A') * 26 + (s[2] - 'A'); } -
函数接受一个字符数组作为参数。在 C 和 C++ 中,当把数组作为参数传递给函数时,实际上传递的是数组首元素的地址,也就是一个指针。所以
char s[]这种写法等同于char* s,它们是完全等价的。
int getHashKey(char s[]) { return (s[0] - 'A') * 26 * 26 + (s[1] - 'A') * 26 + (s[2] - 'A'); } -
-
string类型的计算字符长度需要使用str.length()
size() 和 length():返回 std::string 对象中字符的数量。
substr(size_t pos = 0, size_t len = npos):返回 std::string 对象中从位置 pos 开始长度为 len 的子字符串。compare(const std::string& str):将 std::string 对象与另一个 std::string 对象进行字典序比较,根据结果返回负数、零或正数。在 C++ 中,std::string类型是可以相加的。std::string类对+和+=运算符进行了重载,通过这些重载运算符,能够很方便地实现字符串的拼接操作。下面为你详细介绍相关内容。 - 动态规划(DP)是一种通过将复杂问题分解为更小的子问题来解决的技术。
比如数塔问题:
int getMax(int i, int j) { //i代表当前塔顶在哪一行,n表示塔的当前行数 if (i == n)//如果是最下面一行,数塔只有一个元素 { return a[n][j];//返回它本身 } else//如果不是最后一行 { //分别计算左下角节点和右下角节点作为塔顶时的结果,挑选最大的那个返回 return max(getMax(i + 1, j), getMax(i + 1, j + 1))+a[i][j]; } } -
string类型可以使用str[i]这种形式来访问字符串中的字符
bool isPalindrome(int i, int j) { if (i >= j) { // 边界条件 return true; } else { return (s[i] == s[j]) && isPalindrome(i + 1, j - 1); // 递归调用 } } - 贪心算法(Greedy Algorithm)是一种在每一步选择中采取当前状态下最优决策,以期望最终得到全局最优解的算法策略。其核心思想是“局部最优,全局最优”,但并非所有问题都适用。
活动选择问题
-
问题描述:选择最多数量的互不重叠活动。
-
贪心策略:每次选结束时间最早的活动。
-
代码示例:
#include <algorithm> #include <vector> using namespace std; struct Activity { int start, end; }; bool compare(Activity a1, Activity a2) { return a1.end < a2.end; } int maxActivities(vector<Activity> activities) { sort(activities.begin(), activities.end(), compare); int count = 1; int lastEnd = activities[0].end; for (int i = 1; i < activities.size(); i++) { if (activities[i].start >= lastEnd) { count++; lastEnd = activities[i].end; } } return count; }
霍夫曼编码(Huffman Coding)
-
问题描述:构造最优前缀编码以最小化总编码长度。
-
贪心策略:合并频率最小的两个节点。
-
代码示例:
// 优先队列(最小堆)存储节点 priority_queue<Node*, vector<Node*>, Compare> minHeap; while (heap.size() > 1) { Node* left = heap.top(); heap.pop(); Node* right = heap.top(); heap.pop(); Node* merged = new Node('$', left->freq + right->freq); merged->left = left; merged->right = right; heap.push(merged); }
最小生成树(Prim算法)
-
问题描述:在连通图中找到边权和最小的生成树。
-
贪心策略:每次选择与当前树连接的权重最小的边。
-
代码示例:
void primMST(vector<vector<int>> graph) { int V = graph.size(); vector<int> parent(V); // 存储父节点 vector<int> key(V, INT_MAX); // 存储最小权重 vector<bool> inMST(V, false); // 标记是否加入MST key[0] = 0; parent[0] = -1; for (int count = 0; count < V - 1; count++) { int u = minKey(key, inMST); // 找到未加入MST的最小key节点 inMST[u] = true; for (int v = 0; v < V; v++) { if (graph[u][v] && !inMST[v] && graph[u][v] < key[v]) { parent[v] = u; key[v] = graph[u][v]; } } } printMST(parent, graph); }
贪心算法的优缺点
优点 缺点 实现简单,代码清晰 可能无法得到全局最优解 时间复杂度通常较低(如O(n)) 需要严格证明正确性 适用于实时或大规模问题 对问题特性要求严格
贪心 vs 动态规划
特性 贪心算法 动态规划 决策性质 每步选择不可逆 保存子问题解,可能回溯 时间复杂度 通常更低 通常较高(如O(n²)) 适用问题 具有贪心选择性质的问题 具有重叠子问题和最优子结构的问题 典型问题 活动选择、霍夫曼编码 背包问题、最长公共子序列
应用场景
-
调度问题:任务调度、会议安排。
-
图论问题:最短路径(Dijkstra)、最小生成树(Prim/Kruskal)。
-
数据压缩:霍夫曼编码。
-
组合优化:部分背包问题、找零钱问题(硬币无限)。
贪心算法正确性证明方法
-
数学归纳法:证明每个步骤的贪心选择最终导向全局最优。
-
交换论证:假设存在更优解,通过交换步骤证明矛盾。
-
权重分析:如霍夫曼编码中,证明合并频率最低的节点最优。
-
-
vector<int> v(n, k);是 构造函数语法,只能在定义vector时初始化。如果先声明空vector(vector<int> v;),后续再试图通过v(n, k);初始化,会被编译器误认为是调用名为v的成员函数,而vector类没有这样的成员函数。- 迭代器的类型需严格匹配容器类型和元素类型,但并非必须为
vector<int>。灵活使用auto或const_iterator可简化代码并增强安全性。
vector<string> v_str; for (auto it = v_str.begin(); it != v_str.end(); ++it) { cout << *it << endl; // 正确:it 类型为 vector<string>::iterator } vector不能直接通过下标运算符v[i]进行赋值操作 除非已经提前分配了足够的空间。需要先初始化v(n,x);- C++中的
vector类重载了比较运算符,可以直接使用<、>等运算符进行比较。。在C++中,向量的比较是基于字典序的,即从第一个元素开始逐个比较,直到找到不相等的元素为止。如果所有元素都相等,但v1的长度小于v2,则v1 < v2也为真。- 二维
vector本质上是“容器的容器”,即外层vector的每个元素本身是一个vector<int>。
当初始化外层vector时,需要指定每个元素的初始值。在二维vector初始化中,内层的vector<int>()或vector<int>(cols)是匿名对象,用于定义外层vector每个元素的初始化规则。这种写法符合C++语法,且能明确传递构造逻辑
vector<vector<int>>vs(n,vector<int>());-
当声明vector<vector<int>>
vec(5, vector<int>(3))时:- 外层
vector的元素类型是vector<int>(即每个元素本身是一个一维vector) vector<int>(3)是匿名对象,用于定义内层vector的默认构造方式(长度为3,元素默认初始化为0)- 外层
vector会复制这个匿名对象5次,形成5行3列的二维结构
- 外层
vector<int>()在初始化时仅作为模板传递给外层容器,外层容器会根据模板批量生成内层vector实例。这些实例在内存中通过外层vector的索引(如vec[0]、vec[1])访问,无需单独命名 -
- 二维
-
[]的优先级高于*,因此等价于*(iw[i]) = temp; set是一个有序集合,它内部实现了红黑树(一种平衡二叉搜索树),因此插入元素时会自动排序,并且每个元素都是唯一的,不会重复。set的迭代器是 双向迭代器,不支持+或-操作(只有随机访问迭代器如vector允许此操作)。set基于平衡二叉搜索树(如红黑树),内存地址并未连续,无法+操作下一个地址,但是支持++代表访问下一个节点- 所有标准容器的遍历均以
it != s.end()为终止条件,确保安全访问所有有效元素。s.end() 指向容器最后一个元素的下一个位置**,而不是最后一个元素本身。 s.begin()确实指向容器的第一个元素,而s.end()指向最后一个元素的下一个位置。这种设计遵循 C++ 标准库的半开区间(Half-Open Range)规范
元素布局: [1] → [2] → [3] → [哨兵] 迭代器: ↑ ↑ ↑ begin() end()-1 end()- find 方法的作用
功能:在 set 中查找指定键值(key)的元素。
返回值:
如果找到该键值,返回一个迭代器,指向找到的元素。
如果未找到,返回 set::end()(即指向容器末尾之后的位置的迭代器)。 std::set没有push_back
因为其元素位置由排序规则自动管理。
正确方法:使用insert或emplace插入元素。
适用场景:当需要维护有序且唯一的集合时,优先选择std::set;若需要手动控制插入位置,应使用序列容器(如std::vector、std::list)。set的erase方法不仅支持通过值删除元素,还支持通过迭代器删除。这是std::set的灵活性设计之一。以下是详细说明:
用法 功能 时间复杂度 erase(iterator pos)删除迭代器指向的元素 O(1) erase(const key_type& key)删除指定值的元素(若存在) O(log n) erase(iterator first, iterator last)删除迭代器范围 [first, last)内的所有元素O(k)(k为删除元素的数量) - 使用
s.clear()函数清空s; - 使用
s.size()函数输出s中当前的元素个数。 map是一个关联容器,它存储键值对,并根据键自动排序。
容器 数据结构 有序性 键的要求 std::map红黑树 键按升序排列 必须支持 <运算符(或自定义比较器)std::unordered_map哈希表 无序 必须支持哈希函数( std::hash)和==运算符- 使用迭代器遍历
map。迭代器it从mp.begin()开始,到mp.end()结束。在每次循环中,使用it -> first和it -> second分别访问键和值,并输出它们。 -
std::map的find()函数用于查找容器中是否存在指定的键,并返回指向该键值对的迭代器。以下是详细介绍:1. 函数原型
iterator find(const Key& key); // 查找键为key的元素 const_iterator find(const Key& key) const; // const版本2. 参数
key:要查找的键,类型必须与map的键类型匹配。
3. 返回值
- 找到键:返回指向该键值对的迭代器(类型为
std::map<Key, Value>::iterator)。 - 未找到键:返回
map.end()。
-
queue容器简介std::queue 是 C++ 标准库中的一种 容器适配器(Container Adapter),遵循 先进先出(FIFO) 原则。它基于其他底层容器(如deque或list)实现,提供受限的接口以强制 FIFO 操作。
它允许我们在一端(队尾)添加元素,在另一端(队首)移除元素。核心操作
- **
push()**:在队尾插入元素。 - **
pop()**:移除队首元素(不返回元素值)。 - **
front()**:访问队首元素。 - **
back()**:访问队尾元素。 - **
empty()**:判断队列是否为空。 - **
size()**:返回队列元素数量。
- **
- 优先队列(
priority_queue)。优先队列是一种特殊的队列,其中每个元素都有一个优先级,优先级最高的元素总是位于队列的前端。
priority_queue默认使用vector作为底层存储
优先队列(如 C++ 中的
priority_queue)是 单端队列,其操作特性如下:1. 单端操作
- 插入(push):元素从队列的“尾部”插入(底层容器的尾部,如
vector::push_back)。 - 删除(pop):只能从队列的头部删除元素(即移除优先级最高的元素,如堆顶)。
- 访问(top):只能访问队列头部的元素(即堆顶元素)。
- 插入(push):元素从队列的“尾部”插入(底层容器的尾部,如
- 类成员函数是类的一个成员,它可以操作类的任意对象,可以访问对象中的所有成员。
成员函数可以定义在类定义内部,或者单独使用范围解析运算符 :: 来定义。
double Box::getVolume(void) { return length * breadth * height; } - 优先队列是单端的:仅支持从头部删除元素(优先级最高),尾部插入元素。
双端队列是线性的:支持两端操作,但无法按优先级动态排序。
双端优先队列需自定义实现:若需同时操作最大/最小值,需结合堆或平衡树。 -
如何定义重载函数
当
f1.price > f2.price时认为f1 < f2成立,具体实现如下:struct Fruit { int price; // 其他成员变量... // 重载 < 操作符 bool operator<(const Fruit &x) const { return this->price > x.price; // 当当前对象的 price > x 的 price 时返回 true } };关键点解释
-
函数签名
operator<:表示重载的是<操作符。const Fruit &x:传入的另一个对象,类型为const引用。- 末尾的
const:保证该函数不会修改调用对象(*this)的成员变量
-
比较逻辑
- 当
this->price > x.price时返回true,即f1 < f2成立的条件是f1.price > f2.price
- 当
-
priority_queue默认是最大堆,内部通过std::less<T>比较元素(即默认使用operator<判断元素的优先级,)。如果需要自定义类型的排序方式,重载该类的<运算符即可
bool operator<(const Fruit &other) const { return this->price > other.price; }
- C++标准库中的
pair对象支持直接比较操作。比较的规则是先比较第一个元素,如果第一个元素相等,则比较第二个元素。根据比较结果,输出相应的字符串。 - 全排列是指将n个不同的元素按照所有可能的顺序进行排列。为了实现这一目标,我们可以利用C++标准库中的
next_permutation函数,该函数能够生成给定序列的下一个排列。
序列需可修改:操作范围必须是可变的双向迭代器(如数组或
vector)。next_permutation按字典序重新排列给定范围内的元素,生成当前序列的下一个更大的排列。若当前排列已是最大(降序),则返回false并将序列调整为最小排列(升序)输出结果为所有6种排列组合,如int a[] = {1, 2, 3}; do { // 输出所有排列 } while (next_permutation(a, a+3));1 2 3→1 3 2→ ... →3 2 1反向函数
prev_permutation
与next_permutation对应,prev_permutation生成上一个更小的排列,适用于降序字典序操作 - 使用
fill(a, a + n, k)函数,将数组a从开始位置到第n个位置的元素全部设置为k。这里的a是数组的起始地址,a + n是数组的第n个元素的地址。 - 一维数组的字符名代表第一个元素的指针,二维数组的字符名代表第一行整行的指针,
若需获取首元素地址,需通过以下方式:
a[0]或&a[0][0](类型为int*)。*a解引用后得到首行首元素的地址.
- sort()函数也可以排序字符穿,需要起始地址与结束地址
lower_bound是 C++ 标准库中用于在有序序列中高效查找元素的算法函数,其核心功能是返回第一个不小于(即大于或等于)目标值的元素位置。-
定义指针变量时必须加
*,*在定义指针变量时是类型标识符,用于表明这是一个指针类型。操作地址时无需加
*,对指针进行地址运算或赋值时,直接使用指针变量名(不带*),因为此时操作的是地址本身解引用时必须加
*,*在非定义场景下是解引用运算符,用于访问指针指向的数据,解引用的本质:*p等价于访问指针变量p保存的地址对应的内存单元 - getline(cin, s) 的返回值是 cin,相当于再写一个 cin >> c
在需要处理完整行输入、包含空格或混合输入场景下,getline是更安全、健壮的选择,而cin仅适用于简单、无空格的输入。 -
在C++程序中,键盘输入内容进入缓冲区的条件与流的工作机制密切相关。以下是具体场景的总结:
一、用户按下回车键时触发行缓冲
键盘输入属于标准输入流(
std::cin),默认采用行缓冲模式。这意味着:- 用户在键盘输入数据时,字符会暂时存储在输入缓冲区中,但不会立即提交给程序。
- 只有当用户按下回车键(换行符
\n)时,输入缓冲区中的当前行数据才会被刷新,并传递给程序处理。
例如:
int num; std::cin >> num; // 输入 "123\n",回车后缓冲区内容被读取
二、缓冲区未满时的暂存
输入缓冲区有固定容量(通常为4096或8192字节),在以下情况下数据会暂存缓冲区:
- 未达到缓冲区容量上限:输入的数据量不足以填满缓冲区,且用户未按回车键。
- 程序未主动读取:即使缓冲区中有数据,如果程序未调用
std::cin或相关函数读取,数据仍保留在缓冲区中。
三、全缓冲模式下的数据累积
若通过
std::cin.rdbuf()自定义缓冲区为全缓冲模式:- 数据会持续累积到缓冲区中,直到缓冲区填满才会触发刷新。
- 例如:
std::string buffer(1024, '\0'); std::cin.rdbuf(buffer.data()); // 设置自定义全缓冲区
四、程序主动刷新缓冲区
以下操作会强制刷新输入缓冲区,使数据进入程序:
- 调用
std::cin.get()或std::getline():这些函数会直接读取缓冲区内容(包括未按回车的情况)。 - 使用
std::cin.ignore()或std::cin.clear():手动清空或重置缓冲区状态。 - 程序终止或流关闭:缓冲区内容自动刷新。
五、特殊场景:无缓冲模式
若将输入流设置为无缓冲模式(如
std::cin.sync_with_stdio(false)):- 键盘输入的字符会立即传递给程序,无需等待回车或缓冲区填满。
- 此模式通常用于实时交互场景,但会牺牲性能。
总结
场景 触发条件 典型示例 行缓冲(默认) 用户按下回车键 std::cin读取整行输入全缓冲(自定义) 缓冲区填满 文件输入流或自定义缓冲区 程序主动刷新 调用读取函数或清空操作 std::cin.ignore(1000, '\n')无缓冲模式 手动设置同步禁用 std::cin.sync_with_stdio(false)键盘输入通常采用行缓冲,理解缓冲区机制可避免常见问题(如残留换行符干扰后续输入)。实际开发中,建议优先使用
std::getline逐行读取并手动处理解析逻辑 size_t是C++中处理内存相关操作的核心类型,其无符号特性和平台自适应性使其成为表示大小、索引的首选。在涉及内存分配、容器操作或跨平台开发时,优先使用size_t而非int可显著减少潜在错误。size_t是一种无符号整数类型,专门用于表示对象大小、内存容量、数组索引等与内存空间相关的非负整数值v1.end()指向容器最后一个元素的下一个位置(尾后迭代器),直接解引用*it会导致未定义行为(如程序崩溃或输出乱码)。
-
正向迭代器的定义与功能
迭代器是一种泛化的指针,用于顺序访问容器中的元素,隐藏了不同容器的底层实现差异(如数组、链表等)。通过统一的接口(如
++、*操作符),迭代器实现了对容器的遍历、修改和算法操作。 -
**
begin()和end()的指向**- **
begin():指向容器的第一个有效元素**。例如,对于vector<int> vec = {1,2,3},vec.begin()指向元素1 - **
end():指向容器最后一个元素的下一个位置(称为“尾后迭代器”),不可解引用**。例如,vec.end()指向元素3之后的位置 - 特殊场景:若容器为空,
begin() == end(),均指向尾后位置
- **
-
-
反向迭代器的定义与功能
反向迭代器(reverse_iterator)用于逆序遍历容器,其操作方向与正向迭代器相反。例如,++操作符实际使迭代器向前移动(指向更早的元素)rbegin()和rend()的指向- **
rbegin():指向容器的最后一个有效元素。例如,vec.rbegin()指向元素3 - **
rend():指向容器第一个元素的前一个位置(称为“首前迭代器”),不可解引用**。例如,vec.rend()指向元素1之前的位置
- **
-
//倒叙遍历字符串,string的end()是换行,所以-1
for (auto it = s16.end()-1; it!=s16.begin()-1; it--) - 随机访问迭代器,它允许以常数时间复杂度直接跳转到容器中的任意位置,并支持类似指针的算术运算。
迭代器的随机访问是C++ STL中迭代器的最高级功能类别,它允许以常数时间复杂度直接跳转到容器中的任意位置,并支持类似指针的算术运算。以下是其核心特性与实现原理的详细说明:
一、随机访问的定义与核心功能
-
直接定位任意元素
随机访问迭代器支持通过算术运算符(如it + n、it - n)直接跳转到目标位置,无需逐一遍历。例如:std::vector<int> vec = {10, 20, 30, 40}; auto it = vec.begin() + 2; // 直接定位到第三个元素(30)这种能力依赖于容器底层连续内存的特性(如
vector、deque) -
算术运算与关系比较
支持加减整数(+=、-=)、比较运算符(<、>、<=、>=)和下标访问(it[n])。例如:if (it1 < it2) { /* 比较位置关系 */ } int val = it[3]; // 直接访问第4个元素这使得算法(如
std::sort)能高效操作容器元素 -
时间复杂度与性能优势
所有随机访问操作的时间复杂度均为 O(1),适用于大数据量场景(如排序、二分查找)。例如,std::sort算法依赖随机访问迭代器实现快速元素交换
二、与其他迭代器的区别
迭代器类型 支持操作 典型容器 随机访问迭代器 所有双向迭代器操作 + 算术运算、比较、下标访问 vector、deque、数组双向迭代器 支持前后移动( ++、--),但不支持跳跃访问list、map、set前向迭代器 仅支持单向移动( ++),不可后退forward_list输入/输出迭代器 仅支持读取或写入操作,且只能单向遍历一次 流迭代器(如 istream_iterator)示例对比:
- 双向迭代器需通过循环访问第n个元素:
std::list<int> lst = {1, 2, 3, 4}; auto it = lst.begin(); std::advance(it, 2); // 需遍历两次,时间复杂度O(n) - 随机访问迭代器直接跳转:
std::vector<int> vec = {1, 2, 3, 4}; auto it = vec.begin() + 2; // 直接定位,时间复杂度O(1)
三、适用场景与容器支持
-
高频随机访问操作
如快速排序、二分查找、矩阵运算等算法,依赖随机访问迭代器实现高效元素定位 -
支持的容器类型
- 连续内存容器:
vector、deque、string、原生数组 - 不支持的容器:
list(双向迭代器)、map/set(双向迭代器)、forward_list(前向迭代器)
- 连续内存容器:
-
扩展应用
通过std::next、std::prev等适配器函数,可为非随机访问容器(如map)模拟随机访问行为,但性能仍为O(n)std::map<int, int> m; auto it = std::next(m.begin(), 3); // 遍历三次,时间复杂度O(n)
四、注意事项
-
迭代器失效
在vector中插入/删除元素可能导致所有迭代器失效(因内存重分配) -
性能权衡
随机访问迭代器虽高效,但要求容器内存连续;非连续结构(如链表)需权衡功能与存储灵活性
-
- 删除链表节点
在数组模拟链表的场景中,通过
nodes4[last].next = nodes4[i].next;实现节点删除需要精准定位前驱节点并正确调整指针。以下是具体实现逻辑与注意事项:一、删除节点的核心逻辑
1. 前驱节点的定位
- 关键变量:
last表示当前节点i的前驱节点,nodes4[i].next是当前节点的后继节点。 - 操作步骤:
// 遍历链表时维护前驱节点 last int last = -1; // 初始化为无效值 for (int i = first; i != -1; last = i, i = nodes4[i].next) { if (nodes4[i].data == k) { // 找到要删除的节点 if (last == -1) { // 删除头节点 first = nodes4[i].next; // 头指针指向下一个节点 } else { // 删除中间或尾节点 nodes4[last].next = nodes4[i].next; // 前驱节点跳过当前节点[2,5](@ref) } } } - 作用:通过
last记录前驱节点,直接修改其next指针以跳过当前节点i
- 关键变量:
- 对链表的操作,头插法,删除元素,最好使用一个while循环使用两个指针进行修改,current当前执政与last上一个指针
链表节点的删除本质上是 “逻辑断链”,即通过调整指针的指向,将被删除节点从链表的逻辑连接中移除。该操作不直接销毁物理存储的节点数据,但后续遍历时无法再访问到该节点 -
在C++中,std::
reverse是一个常用的算法函数,用于反转序列容器或数组中元素的顺序。以下是其核心用法和特性的综合介绍:1. 基本用法
头文件:需包含 <algorithm>。
函数原型:template <class BidirectionalIterator>void reverse(BidirectionalIterator first, BidirectionalIterator last);
参数 first 和 last 表示反转范围的起始和结束迭代器,范围为 左闭右开区间 [first, last)。
作用:将指定区间内的元素顺序完全颠倒,如 [1,2,3,4] 反转为 [4,3,2,1]。 - 滑窗算法
-
正则表达式<regex>
regex_search
https://zhuanlan.zhihu.com/p/562283567
普通字符
直接匹配字符本身,如 a 匹配字母 "a",123 匹配字符串 "123"。元字符(特殊符号)
具有特殊含义的符号,需转义(如 \* 匹配字符 "*"):.:匹配任意单个字符(除换行符)。^ 和 $:分别匹配字符串的开头和结尾。
|:逻辑“或”,如 a|b 匹配 "a" 或 "b"。
预定义字符类
简化常见字符集的匹配:\d:匹配数字(等价于 [0-9])。
\w:匹配字母、数字或下划线(等价于 [a-zA-Z0-9_])。
\s:匹配空白符(如空格、换行符)。
量词(限定符)
控制字符重复次数:*:匹配前一个字符 0 次或多次(贪婪匹配)。
+:匹配前一个字符 1 次或多次。
?:匹配前一个字符 0 次或 1 次。
{n,m}:匹配前一个字符至少 n 次,至多 m 次。
分组与捕获():将部分模式分组,如 (ab)+ 匹配 "abab" 等。
(?:):非捕获分组,仅分组不保存匹配结果。 - 在代码中,字符串内的反斜杠 \ 需要根据语言规则转义,否则会被解释为普通字符。
std::regex pattern("\\d+"); - 在C++中,函数参数传递有两种主要方式:传值(by value)和传引用(by reference)。传值会创建参数的副本,而传引用则直接使用原始变量,不会复制。
int minTotalDifference(int n, int d, vector& skills)这里,vector& skills中的&符号表示skills是一个引用参数。这意味着函数内部对skills的任何修改都会影响到传入的原始vector,而不是操作它的副本。如果没有&符号,参数会通过传值方式传递,函数内部处理的是原vector的一个副本,修改不会影响原数据。引用参数可以直接使用原始数据的引用,不拷贝数组,适合传递大型对象(如 vector、string 等)。如果参数写成 vector<int> skills(不带 &),调用函数时会拷贝整个 skills 数组。如果数组很大,会浪费时间和内存。 - 在代码
vector<vector<int>> dp(n+1, vector<int>(n+1, INT_MAX))中,INT_MAX 的作用是为二维动态规划数组 dp 的所有元素设置初始值为最大可能整数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号